1. 程咬金三板斧:要解决一个什么问题
用户故事:
作为性能测试工程师,
我想要快速定位并解决存储系统带宽不达标的紧急问题,
以便于系统能够满足预定的性能基准,保障项目交付进度。
一天,测试同事急匆匆地提了一个Bug:“我在性能测试存储系统时发现带宽过低、性能不够,这是个紧急问题需要马上解决。”
面对突如其来的性能问题,你可能会感到束手无策:Linux内核跟踪还没学会,分布式系统的核心代码也不清楚,甚至连客户端测试场景也了解不深。心急火燎地看日志、敲命令,忙活了半天,问题依旧。
这时,经验丰富的领导端起茶杯,慢悠悠地问了几个关键问题:
- 衡量的“不达标”,具体标准是什么?
- 你如何判断问题出在操作系统本身?
- 还是我们的后端分布式系统有问题?
- 抑或是客户端的压测方式有问题?
他还追问了一个细节:“客户端采用创建100个VMware虚拟机来模拟写大文件,是单线程写吗?”
“要有大局观,先把基本边界分清楚。”领导强调,“这个定位如果搞不清楚,后续所有工作都无法解决问题。”
2. 程咬金三板斧:后端存储如何自证清白
2.1 利用操作系统自身提供工具
面对“带宽跑不满”的指控,后端存储系统首先要能自证清白。最直接的方法就是利用操作系统自带的性能观测工具。这好比是给系统做一次“体检”,通过各项指标判断其健康状况。
一个清晰的排查路径至关重要。这里我们参考《Linux性能优化实战》中的思路,当服务响应慢时,可以从CPU、内存、I/O、网络等多个维度入手。
对于存储系统,I/O(尤其是磁盘I/O)和网络通常是性能瓶颈的高发区。
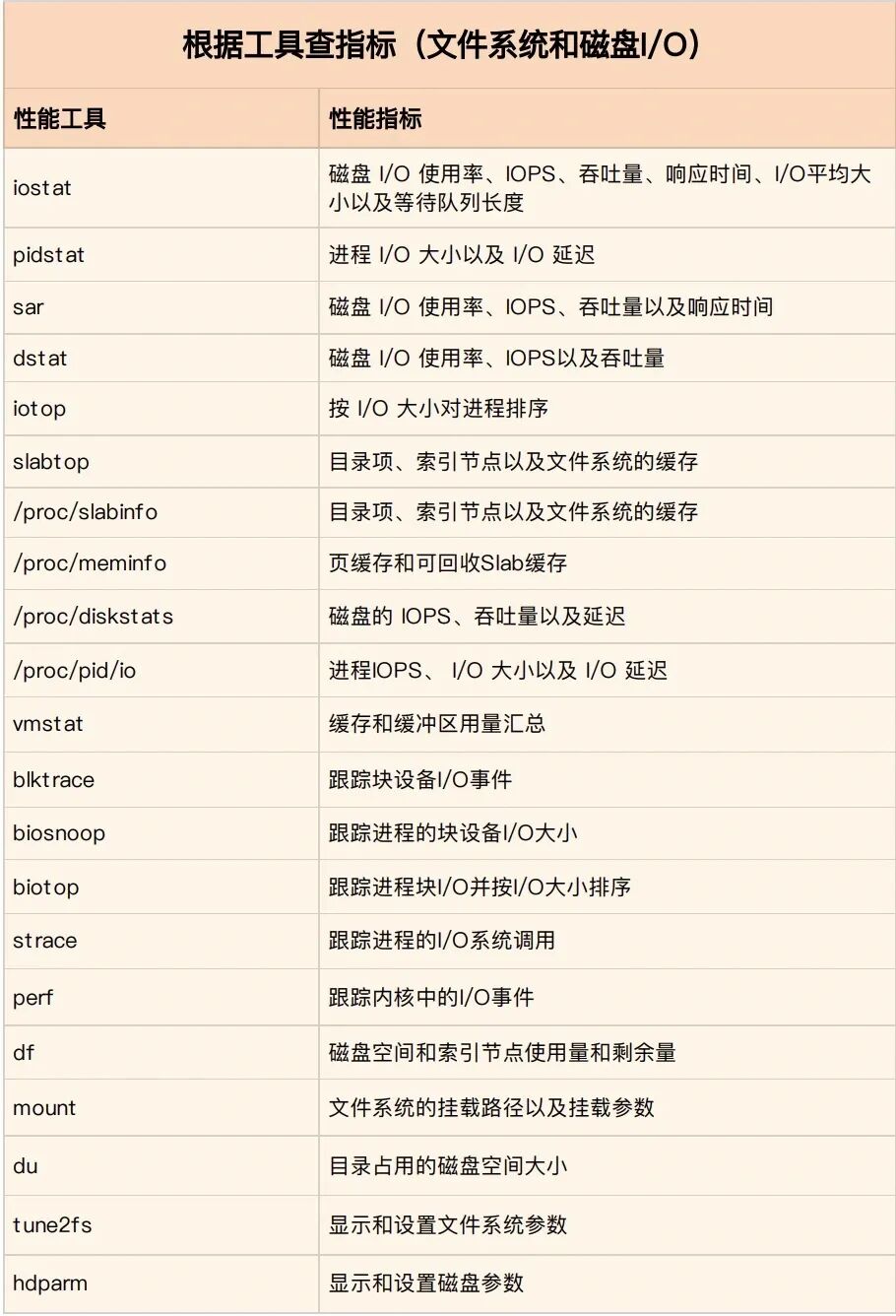
文件与磁盘 I/O 排查工具
在面对文件系统和磁盘I/O性能问题时,一套完整的工具链可以帮助我们快速定位。下表汇总了常用的性能工具及其可监控的关键指标:
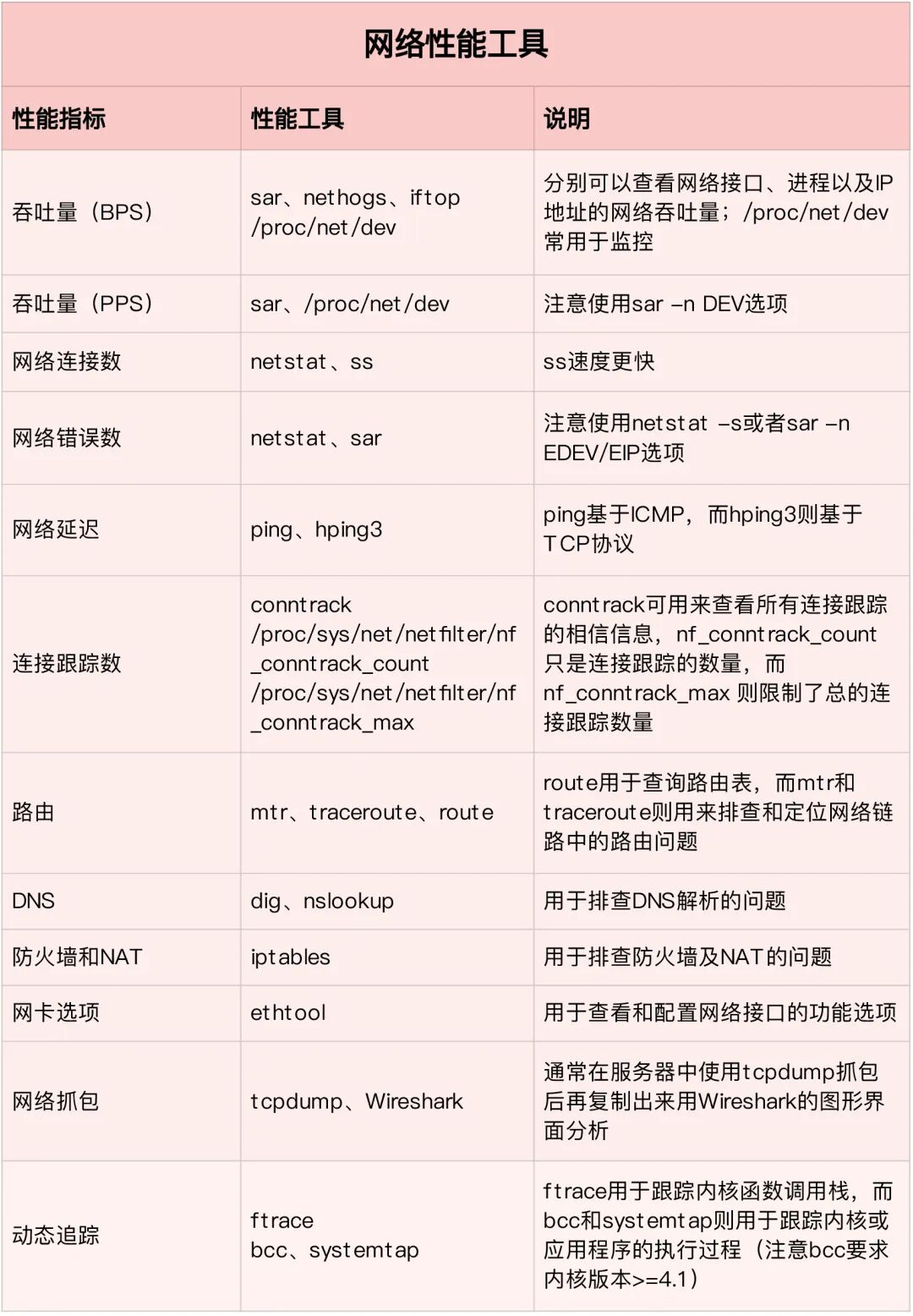
网络性能排查工具
网络瓶颈是分布式存储的另一个常见问题。吞吐量、延迟、连接数等都是需要关注的核心指标。
sar:历史性能分析利器
sar(System Activity Reporter)是一个强大的系统活动历史数据收集和报告工具。它由cron定期运行,数据默认保存在/var/log/sa/目录下。
/var/log/sa/ # 默认数据目录
├── sa01 # 1号的历史二进制数据
├── sa02 # 2号的
├── sar01 # 1号的可读文本格式
└── sar02
案例剖析:CPU负载高,但使用率不高
现象:上午10点系统响应变慢,监控显示CPU使用率约60%,但平均负载(Load Average)却高达15(系统为4核CPU)。
排查步骤:
首先,使用sar查看问题时间段的CPU使用情况:
# 1. 查看问题时间段的CPU统计
sar -u -f /var/log/sa/sa$(date +%d) -s 09:30:00 -e 10:30:00
# 输出示例:
# 10:00:01 AM CPU %user %nice %system %iowait %steal %idle
# 10:00:01 AM all 15.12 0.00 8.34 60.01 0.00 16.53
# 10:10:01 AM all 18.09 0.00 9.12 65.21 0.00 7.58
# 10:20:01 AM all 20.45 0.00 10.11 70.12 0.00 -1.68
分析:
%iowait 高达 60-70%,说明 CPU在大量等待磁盘I/O。- 空闲CPU (
%idle) 几乎为0,但用户态CPU使用率 (%user) 并不高。
- 结论:很可能是磁盘成为瓶颈,导致大量进程在等待I/O,CPU虽“闲”(无事可做),但负载很高(很多进程在排队)。
深入调查磁盘:
# 2. 查看同时间段磁盘I/O
sar -d -p -f /var/log/sa/sa$(date +%d) -s 09:30:00 -e 10:30:00
# 输出示例:
# 10:00:01 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
# 10:00:01 AM sda 1200.45 8000.12 15000.34 20.12 45.67 150.23 8.12 97.45
# 10:00:01 AM sdb 12.34 100.23 200.45 25.34 0.12 2.34 1.23 1.23
发现:
sda 的 %util 为97.45%,接近100%,表明磁盘已完全饱和。await 高达150ms,I/O等待时间非常长。avgqu-sz 为45.67,平均队列长度很长,大量请求在排队。
此时,问题根源已清晰指向磁盘sda。可以进一步通过pidstat或iotop定位是哪个进程导致了高I/O,并结合应用日志(如数据库连接超时错误)最终解决问题。
iostat:实时性能与延迟概览
sar用于历史回顾,而iostat则适合实时监控。命令iostat -d 1 -x可以每秒刷新一次磁盘统计数据。
其输出详解如下(关键指标已加粗):
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.23 45.67 89.01 5.12 12.34 128.12 2.34 10.12 8.34 11.23 7.12 95.67
- rMB/s, wMB/s:最重要的读写吞吐量指标(单位MB/s)。
- r/s, w/s:每秒读写操作次数,即IOPS。
- rrqm/s, wrqm/s:每秒合并的读写请求数。
- %util:设备利用率百分比,超过80%通常意味着可能成为瓶颈。
- await:平均I/O等待时间(毫秒),包含队列等待和服务时间。
掌握这些工具,后端存储系统就有了为自己“辩护”的数据基础,能快速判断性能瓶颈是否由自身硬件或基础环境导致。
2.2 如何监控分布式存储系统:全链路I/O追踪
perf:深入内核的性能分析
当标准工具无法定位更深层的问题时,perf(Performance Event Counters)就派上用场了。它是Linux系统性能分析工具集,基于内核的perf_events子系统,提供硬件和软件层面的深度分析能力。
perf的主要功能包括:
- CPU性能分析
- 函数调用追踪
- 硬件事件统计(如缓存命中率、分支预测失败)
- 软件事件监控
- 系统调用跟踪
它能够追踪内核中的I/O事件,对于分析存储栈中从系统调用到底层驱动的全链路延迟非常有帮助。
系统自带监控:最重要的防线
然而,对于复杂的分布式存储系统而言,最重要的监控往往来自于系统自身。一套设计良好的监控 Dashboard 是运维和性能分析的“眼睛”。
- TiDB Dashboard:TiDB提供了功能强大的内置监控界面,可以清晰地查看集群各项性能指标。
- Ceph:拥有丰富的工具集,如
ceph osd perf可以查看OSD(对象存储守护进程)的性能数据,还有集群管理、性能分析等一系列命令。
这个最重要,但是结合各自系统说明。 当线上出问题时,现场临时敲iostat、sar命令往往是滞后的。一个预置的、全面的监控系统,能让你第一时间发现异常、定位根源。构建和完善这套监控体系,是保障分布式系统稳定性和可观测性的基石。
3. 程咬金三板斧:客户端如何自证清白
3.1 分布式数据库压测工具
通用型压测工具:Sysbench
Sysbench 是一款开源、模块化、跨平台的多线程性能测试工具。它支持CPU、内存、磁盘I/O、线程以及数据库的性能测试。在数据库领域,它被广泛用于对MySQL、PostgreSQL等数据库进行基准测试,同样也适用于TiDB和OceanBase这类分布式数据库。
TPC-C & TPC-H:标准化测试规范
- TPC-C:专门针对联机交易处理系统(OLTP)的测试规范。它模拟复杂的在线事务处理(如订单创建、支付、库存查询等),在极大压力下测试数据库的事务处理能力,结果以
tpmC(每分钟交易量)衡量。
- TPC-H:商业智能计算测试,用于模拟决策支持类应用(OLAP)。它包含22条复杂的分析查询,专门测试数据库在数据分析场景下的性能。
- Databench-C:这是一个混沌测试工具,用于模拟各种故障(如节点宕机、网络中断、资源耗尽),旨在测试分布式数据库在高可用和容错方面的韧性。
3.2 分布式存储主流压测工具优缺点
dd命令:简单粗暴,但场景单一
- 创建测试文件:
dd if=/dev/zero of=testfile bs=1M count=10240(创建10GB文件)。
- 支持直接I/O:通过
oflag=direct参数可以绕过操作系统缓存,测试真实的磁盘性能。
- 局限性:
- 仅支持单线程顺序I/O,无法模拟随机访问、并发访问等真实场景。
- 其同步阻塞模式(iodepth=1)无法体现现代NVMe硬盘多队列的优势。
FIO:灵活强大的I/O测试框架
FIO(Flexible I/O Tester)的核心设计哲学在于模块化与可扩展性,特别是通过其独特的I/O引擎(ioengine) 架构来支持多样化的I/O操作方式。
优点:
- 高度灵活:支持sync、mmap、libaio、posixaio、io_uring、spdk等十几种I/O引擎,可模拟多种真实负载场景。
- 并发模拟能力强:支持多线程、多进程并发测试,能够充分压测现代存储设备(如NVMe的多队列)的性能上限。
- 测试场景全面:可精细配置顺序/随机读写、混合读写比例、不同I/O大小、队列深度等关键参数,适用于块设备和文件系统测试。
- 实战验证:在滴滴的Ceph分布式存储系统优化实践中,使用Fio验证锁优化效果,使随机写平均延迟下降了53%。
Fio测试能有效帮助识别性能瓶颈:
- 网络瓶颈:对比本地存储和远程存储的测试结果。
- 存储节点瓶颈:在不同节点上运行Fio,识别性能短板。
- 软件栈瓶颈:对比不同I/O引擎(如libaio vs io_uring)的性能。
Vdbench:为集群而生的专业选手
优点:
- 集群测试能力强:专为测试整个存储集群性能设计,原生支持多主机、多客户端并发测试与统一管理,非常适合评估分布式存储系统。
- 参数配置丰富:提供存储定义(SD)、工作负载定义(WD)、运行定义(RD)等结构化参数,能精细控制复杂的测试过程。
- 兼顾文件与块设备:支持文件系统测试(FSD/FWD)和裸设备测试,配置灵活。
结论:
- 对于分布式存储系统压测,Vdbench是更专业、更便捷的选择。它提供了开箱即用的多节点管理、任务分发和统一报告生成,能更好地模拟真实生产环境中的多客户端并发负载。
- 测试单个裸盘的极限性能,FIO更轻量、灵活。
- 问:对于用100个客户端建立VMware虚拟机进行I/O压测合适吗?
- 不合适。Vdbench从设计之初就支持多主机联机测试,可轻松组织跨上百节点的测试。而Fio虽然也有client-server模式,但需要手动管理每个客户端的服务端,在超大规模测试时,Vdbench的集群管理优势更加明显。虚拟机方案则引入了额外的虚拟化层开销和复杂度,并非压测首选。
通过掌握这些工具和方法,无论是后端存储团队还是客户端测试团队,都能用数据和事实清晰地界定问题边界,从而高效协作,共同攻克性能难题。在云栈社区,你可以找到更多关于性能测试和系统调优的实战经验分享。
 发表于 2026-1-25 05:47:01
|
查看: 207|
回复: 0
发表于 2026-1-25 05:47:01
|
查看: 207|
回复: 0
