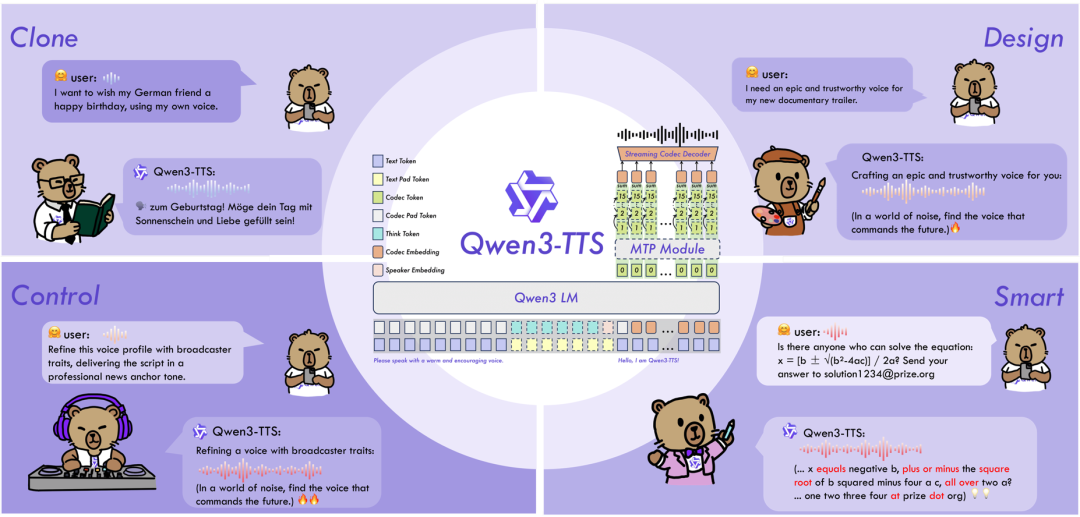
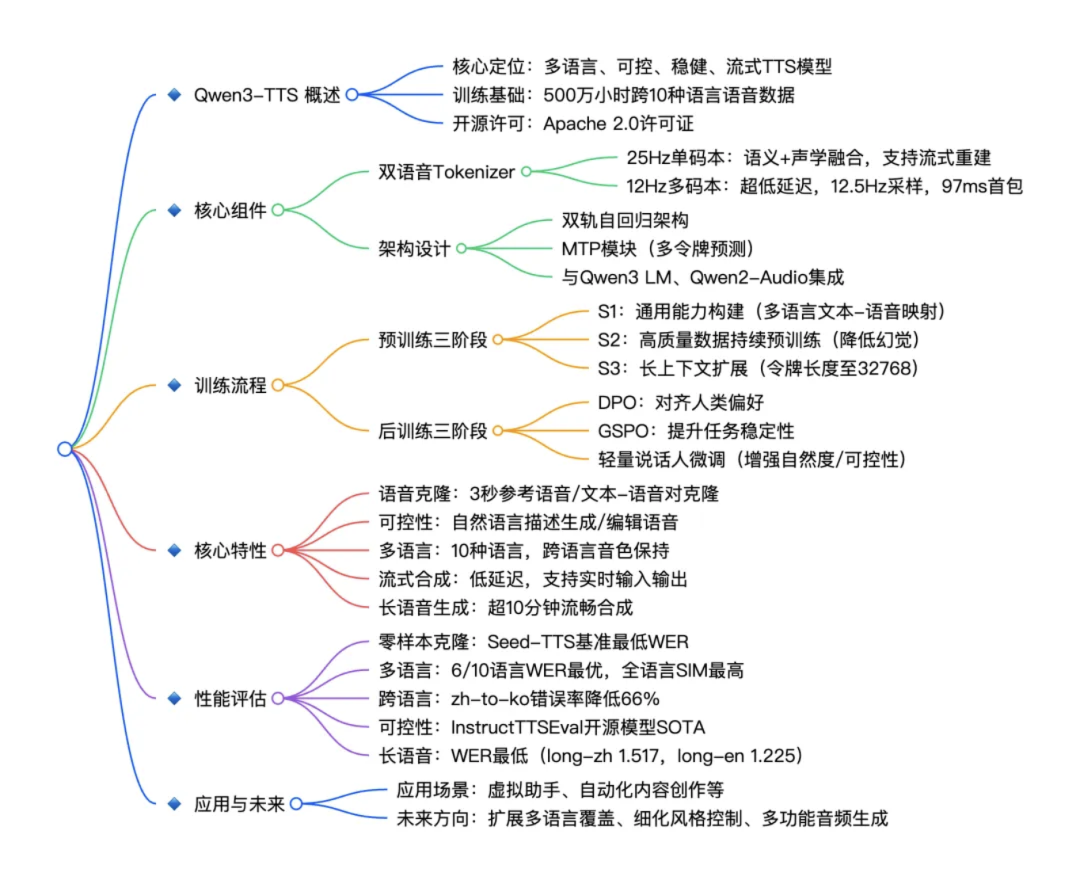
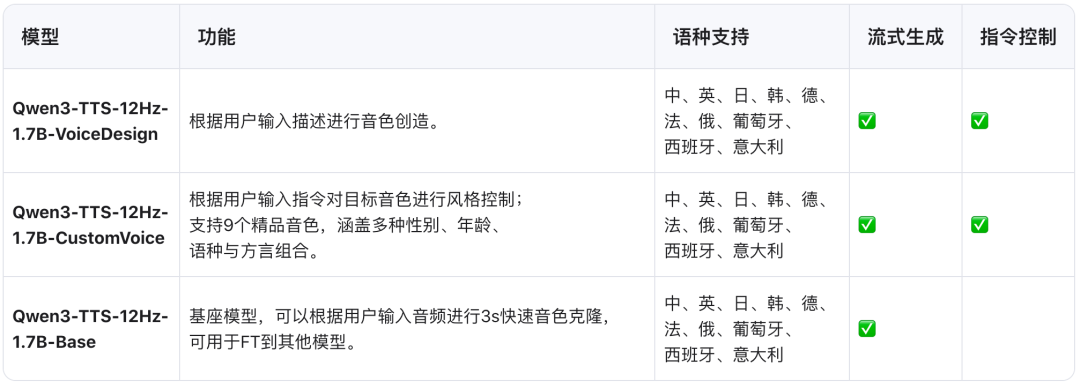
Qwen3-TTS 是由阿里巴巴 Qwen 大模型团队开源的一系列功能强大的语音生成模型,全面支持音色克隆、音色创造、超高质量拟人化语音生成,以及基于自然语言描述的语音控制。依托创新的 Qwen3-TTS-Tokenizer-12Hz 多码本语音编码器,模型实现了对语音信号的高效压缩与强表征能力,不仅完整保留副语言信息和声学环境特征,还能通过轻量级架构实现高速、高保真的语音还原。
Qwen3-TTS 采用 Dual-Track 双轨建模,达成了极致的双向流式生成速度,首包音频仅需等待一个字符。模型多码本全系列均已开源,包含1.7B和0.6B两种尺寸,1.7B版本追求极致性能与控制能力,0.6B版本则在性能与效率间取得平衡。
该模型覆盖 10 种主流语言(中文、英文、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语、意大利语)及多种方言音色,满足全球化应用需求。同时,模型具备强大的上下文理解能力,可根据指令和文本语义自适应调整语气、节奏与情感表达,并对输入文本噪声的鲁棒性有显著提升。
其核心特点包括:
- 强大的语音表征:基于自研 Qwen3-TTS-Tokenizer-12Hz,实现语音信号的高效声学压缩与高维语义建模,完整保留副语言信息及声学环境特征,并可通过轻量级的非 DiT 架构实现高效、高保真语音还原。
- 通用的端到端架构:采用离散多码本 LM 架构,实现语音全信息端到端建模,彻底规避传统 LM+DiT 方案的信息瓶颈与级联误差,显著提升模型的通用性、生成效率与效果上限。
- 极致的低延迟流式生成:基于创新的 Dual-Track 混合流式生成架构,单模型同时兼容流式与非流式生成,最快可在输入单字后即刻输出音频首包,端到端合成延迟低至 97ms,满足实时交互场景的严苛需求。
- 智能的文本理解与语音控制:支持自然语言指令驱动的语音生成,灵活调控音色、情感、韵律等多维声学属性;同时深度融合文本语义理解,自适应调节语气、节奏、情感与韵律,实现“所想即所听”的拟人化表达。
Qwen3-TTS 性能优势
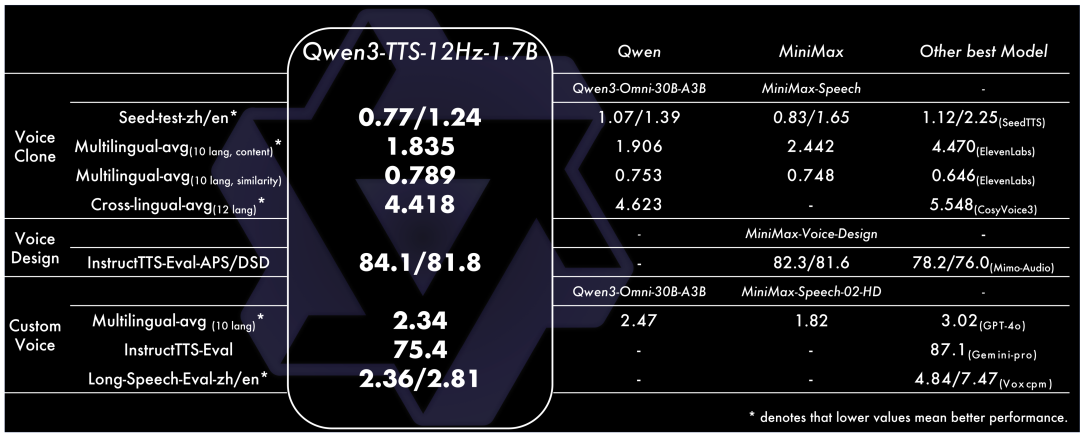
Qwen3-TTS 在音色克隆、创造、控制等方面都达到了SOTA性能。具体来说:
- 音色创造任务上,Qwen3-TTS-VoiceDesign 在 InstructTTS-Eval 中指令遵循能力和生成表现力都整体超越 MiniMax-Voice-Design 闭源模型,并大幅领先其余开源模型。
- 音色控制任务上,Qwen3-TTS-Instruct 不仅具备单人多语言的泛化能力,平均词错率 2.34%;同时具备保持音色的风格控制能力,InstructTTS-Eval 取得了 75.4% 的分数;此外,也展现出卓越的长语音生成能力,一次性合成 10 分钟语音的中英词错率为 2.36/2.81%。
- 音色克隆任务上,Qwen3-TTS-VoiceClone 在 Seed-tts-eval 上中英文克隆的语音稳定性表现上均超越 MiniMax 和 SeedTTS;在 TTS multilingual test set 上 10 个语项上取得了 1.835% 的平均词错误率和 0.789 的说话人相似度,超越 MiniMax 和 ElevenLabs;跨语种音色克隆也超越 CosyVoice3 位居 SOTA。
Qwen3-TTS 模型架构
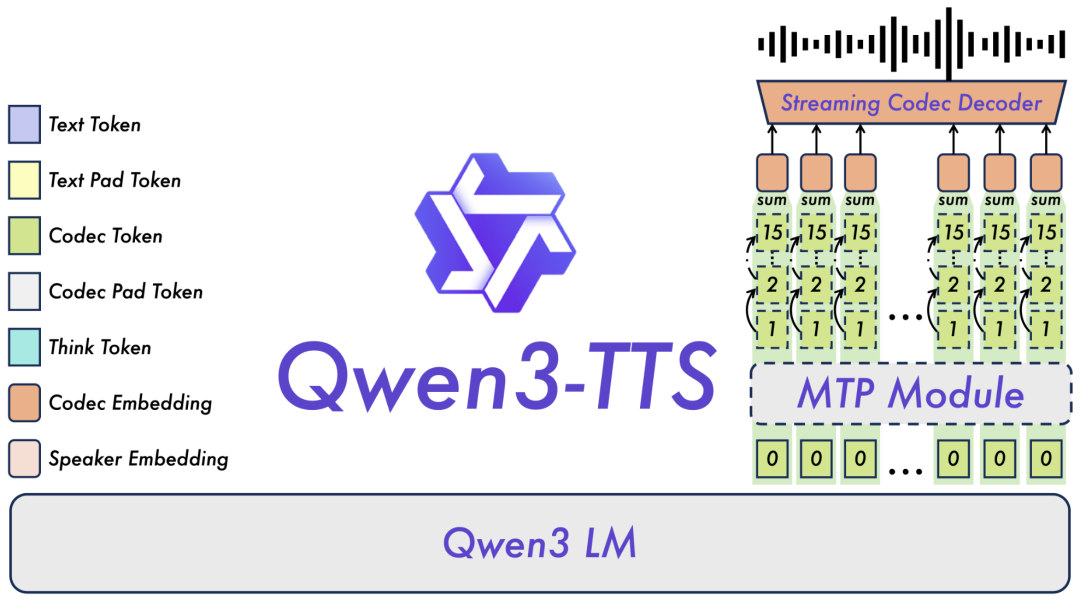
Dual-Track 双轨架构
区别于传统 TTS 模型采用「单轨串行处理」,Qwen3-TTS 创新采用双轨架构,将「文本处理」和「声学生成」拆分为两条并行轨道,一条轨道实时处理输入文本,提取语义和韵律信息;另一条轨道基于这些信息同步生成音频,无需等待全部文本处理完成。再配合 MTP(Multi-Token Prediction)模块,实现了单帧即时解码,最终达成 97ms 的超低延迟。这种先进的架构设计也体现了当前 人工智能 领域对模型效率的极致追求。
双 Tokenizer 设计
Qwen3-TTS 配备了两款自主研发的语音 Tokenizer,让模型既能在追求音质时输出 24kHz 高采样率音频,又能在追求效率时实现极速生成,分别适配不同场景需求:
- Qwen-TTS-Tokenizer-25Hz:采用单码本架构,融合语义与声学线索,基于 Qwen2-Audio 编码器打造,配合块级 DiT 解码,适合对音质要求极高的场景(如有声书、精品配音);
- Qwen-TTS-Tokenizer-12Hz:采用 12.5Hz 多码本设计,语义与声学解耦,通过轻量级因果 ConvNet 解码,无需复杂扩散模型,主打高速响应,完美适配实时流式场景。
分阶段训练
Qwen3-TTS 的训练流程分为预训练和后训练两大阶段,每个阶段都有明确的优化目标,让 Qwen3-TTS 在零样本克隆、长文本生成、跨语言合成等场景中,均达到了 SOTA 水平。
- 预训练三阶段:S1 阶段基于 500 万小时多语言数据,构建文本与语音的映射关系;S2 阶段采用高质量数据持续预训练,降低噪声数据导致的幻觉;S3 阶段将最大 token 长度从 8192 扩展至 32768,提升长文本处理能力;
- 后训练三阶段:通过 DPO(直接偏好优化)对齐人类语音偏好,GSPO(规则奖励优化)增强任务稳定性,再经过轻量说话人微调,进一步提升自然度与可控性。
Qwen3-TTS 能力演示
秒级语音克隆
Qwen3-TTS 仅需 3 秒即可生成清晰语音样本,无论是人声、方言,甚至特殊声线,都能实现精准复刻。 更令人惊艳的是克隆后的稳定性:用自己的声音克隆后,切换中文、英文、日语等不同语言朗读,音色始终保持一致,甚至能完美保留说话时的尾音、语气等细节特征。

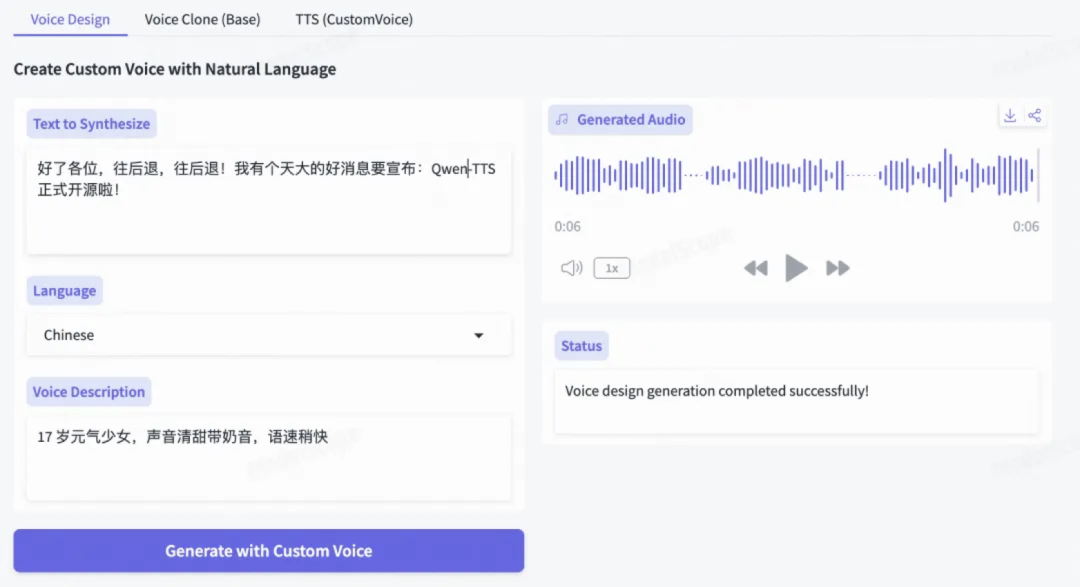
语音音色设计
Qwen3-TTS 支持通过自然语言描述直接创造全新音色。你只需输入一句音色详细描述,比如:「17 岁元气少女,声音清甜带奶音,语速稍快」
多语言 + 多方言
Qwen3-TTS 全面支持 10 种主流语言,以及四川话、北京话等多种中文方言。 最核心的突破在于「跨语言音色一致性」:用中文声音克隆后,切换到韩语、西班牙语朗读,音色依然是克隆的原声,不会出现「换语言就换嗓子」的问题。

Qwen3-TTS 开源项目
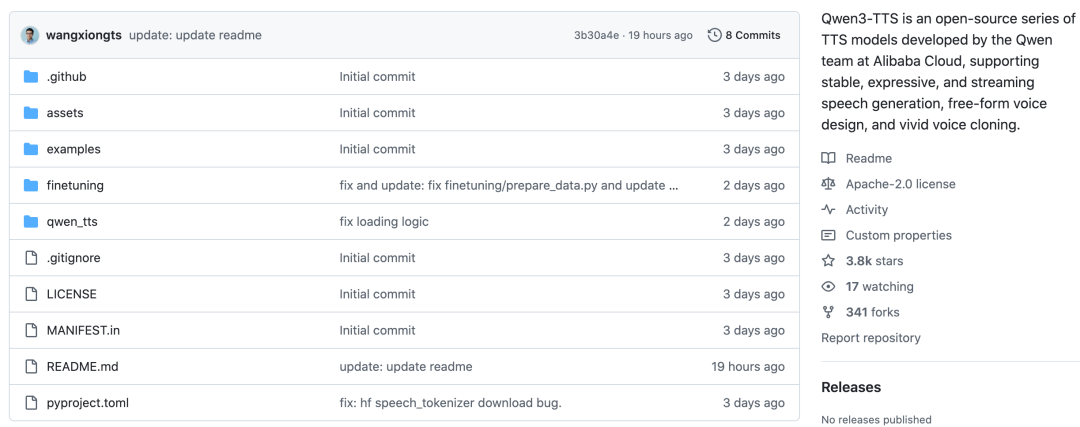
Qwen3-TTS 是个真正端到端、真正可控、真正能落地的开源 TTS 模型,开源后 GitHub 上直接斩获 4K+ Star,是 开源实战 领域的热门项目。对于希望深入研究的开发者,可以参考其详细的 技术文档 进行二次开发与应用。
你对这个强大的开源语音合成模型怎么看?欢迎在 云栈社区 分享你的见解或开发经验。 |  发表于 2026-1-26 05:55:11
|
查看: 155|
回复: 0
发表于 2026-1-26 05:55:11
|
查看: 155|
回复: 0
