在云计算和物联网快速发展的今天,越来越多的业务场景将计算和数据采集能力推向了边缘侧。从智能制造的产线设备、新能源汽车的车载系统,到遍布各地的零售终端和智能家居设备,这些终端设备产生的可观测数据(日志、指标、追踪)对于业务运营、故障诊断和用户体验优化至关重要。
然而,终端设备的运行环境远比数据中心复杂,为数据采集带来了严峻挑战:
- 网络环境不稳定:终端设备常常运行在弱网、间歇性断网的环境中。移动网络信号波动、WiFi连接不稳定、跨地域网络延迟高等问题普遍存在。
- 电源供应不保障:许多终端设备依赖电池供电或面临意外断电风险。
- 资源极度受限:边缘设备的 CPU、内存、存储、网络带宽都极为有限。
在这种极限条件下的可观测数据采集面临极大的挑战。比如车辆在偏远地区行驶时,可能长时间处于弱网或断网状态;车辆熄火断电时,内存中缓存的监控数据可能全部丢失;在隧道、地下停车场等场景下,数据采集中断,关键的故障诊断数据无法回传。
本文将深入剖析边缘场景下的采集难题,并详细介绍阿里云开源的 LoongCollector 如何针对弱网、断电等极限环境,提供一套完整、可靠的边缘可观测数据采集解决方案。
边缘终端可观测数据采集的三大挑战
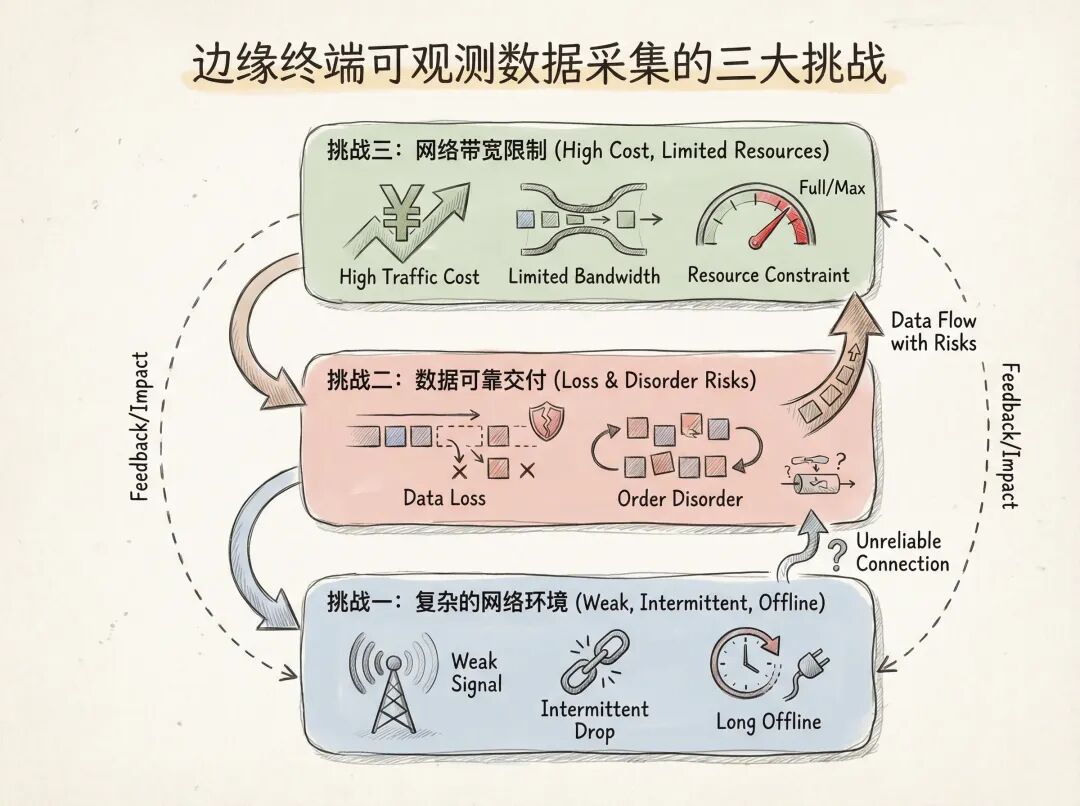
挑战一:复杂的网络环境
终端设备运行环境的网络条件远比数据中心复杂:
- 弱网场景:移动网络信号不稳定、WiFi信号弱、跨地域长链路等导致网络带宽低、延迟高、丢包率高。
- 间歇性断网:设备移动、网络切换、临时性网络故障导致周期性网络中断。
- 长时间离线:某些场景下设备需要长时间离线工作,积累大量待上传数据。
例如,车载终端设备在偏远地区运输途中,可能很长时间都处于弱网或断网状态;在车辆熄火或者维修的情况下,车载终端设备也会断电。
挑战二:可观测数据可靠交付
在弱网、断电等不稳定环境下,保证数据的可靠交付和一致性是最大的挑战:
- 数据丢失风险:网络中断、设备断电、进程异常等都可能导致数据丢失。
- 顺序性保障:时序数据(如指标、追踪)需要保持采集时的时间顺序。
挑战三:网络带宽限制
终端设备的网络带宽通常受到严格限制:
- 流量成本高:4G/5G移动网络的流量费用远高于数据中心专线。
- 带宽竞争:采集数据上传需要与业务数据传输竞争有限的带宽资源。
- 上传速率限制:某些运营商或网络环境会对上传带宽进行限制。
在这样的环境下,如何高效压缩数据、智能控制发送速率、避免带宽被采集流量占满,成为必须解决的问题。
LoongCollector:为边缘场景优化的可靠采集方案
LoongCollector是阿里云开源的高性能、高可靠可观测性数据采集器,在支撑阿里云内部千万级规模部署的同时,针对边缘场景进行了深度优化。
核心能力概览
统一的可观测数据采集
LoongCollector提供了完整的可观测数据采集能力:
- 主机监控:实时采集CPU、内存、磁盘、网络等系统指标,支持100+系统指标项。
- Prometheus协议:完全兼容Prometheus生态,可采集所有支持Prometheus采集的应用指标。
- 日志采集:高效的文本日志采集能力,支持多种日志格式和解析方式。
超低资源消耗
针对资源受限的终端设备,LoongCollector进行了极致的性能优化。在与主流开源采集器(Fluent Bit, Vector, Filebeat)的性能基准测试中,LoongCollector在CPU和内存消耗上展现出显著优势。
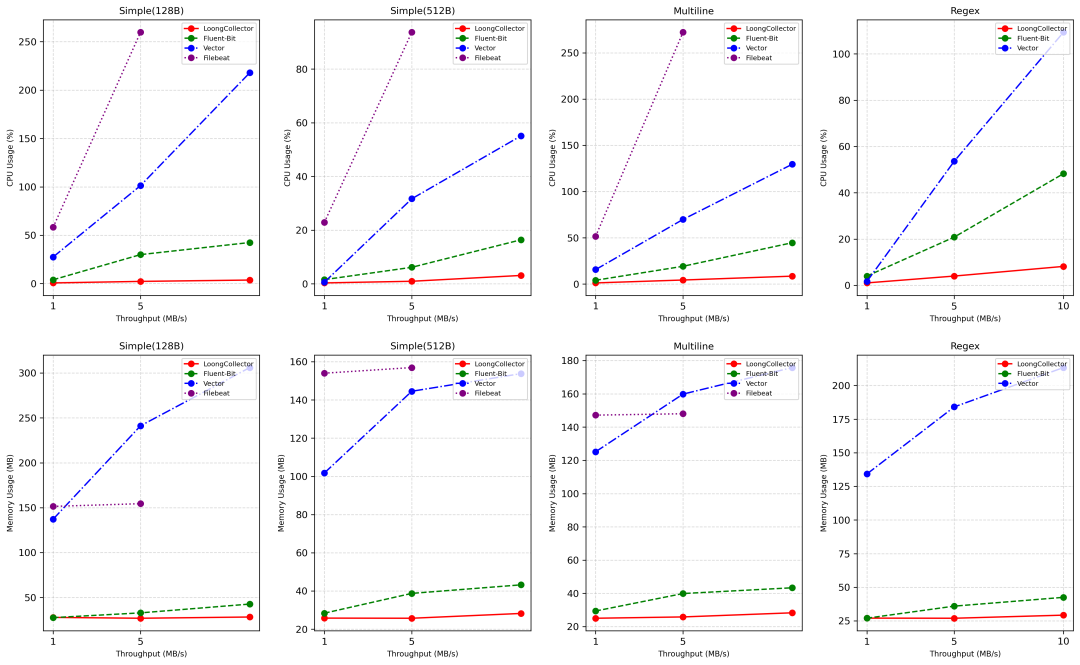
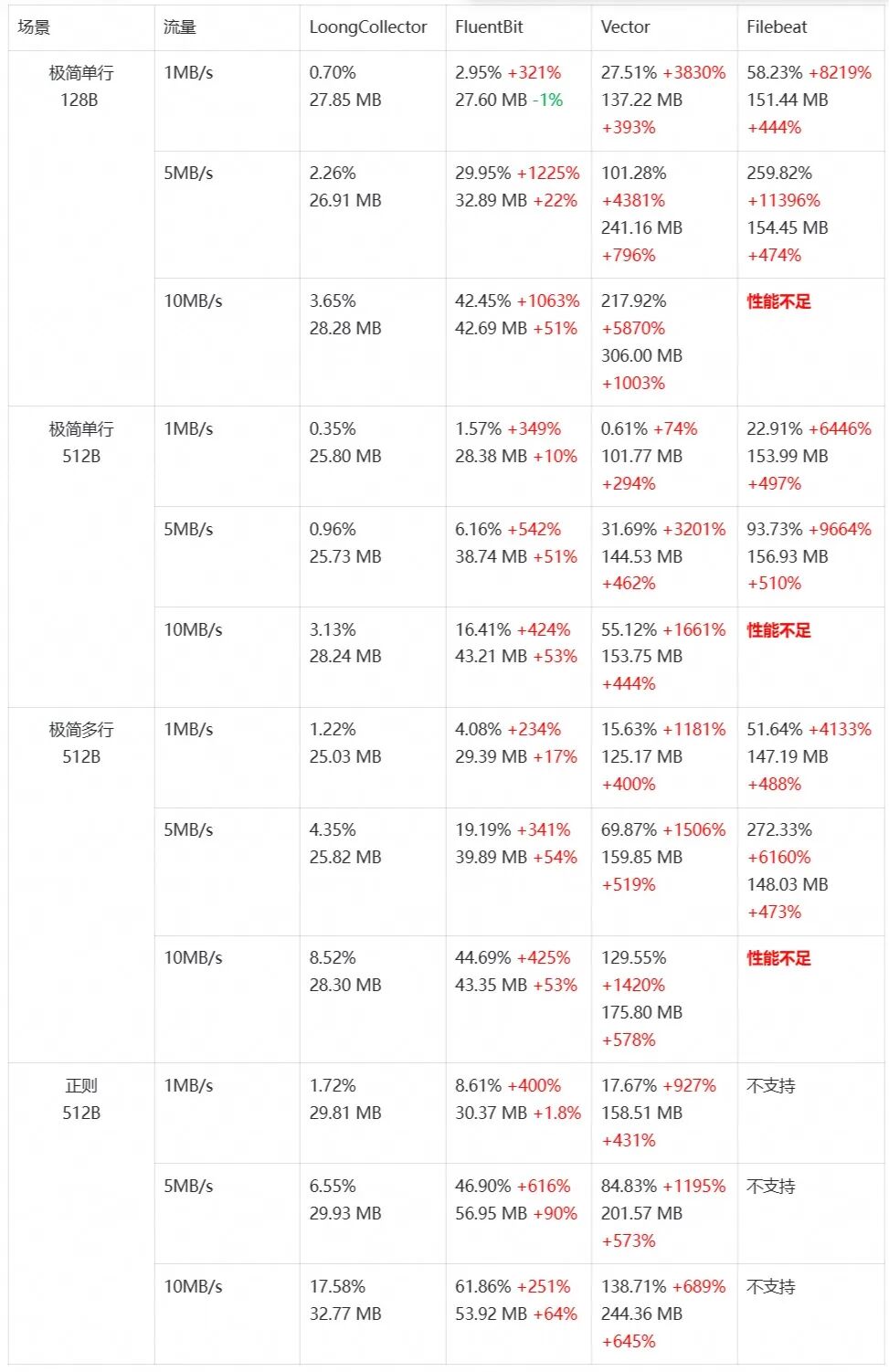
这意味着在相同的硬件条件下,LoongCollector可以支持更多的采集任务,或者在资源更受限的设备上稳定运行。这对于追求稳定与效率的 运维 工作至关重要。
企业级稳定性保障
- 生产级验证:支撑阿里云内部1000万+实例的可观测数据采集。
- 高可用性:单实例高可用性,支持故障自恢复。
- 久经考验:经历多年双11大促、突发流量等极端场景验证。
解决方案架构:数据持久化 + 异步发送 + 智能重试
针对弱网、断电、断网等边缘场景,LoongCollector采用了“数据持久化 + 异步发送 + 智能重试”的核心架构设计。
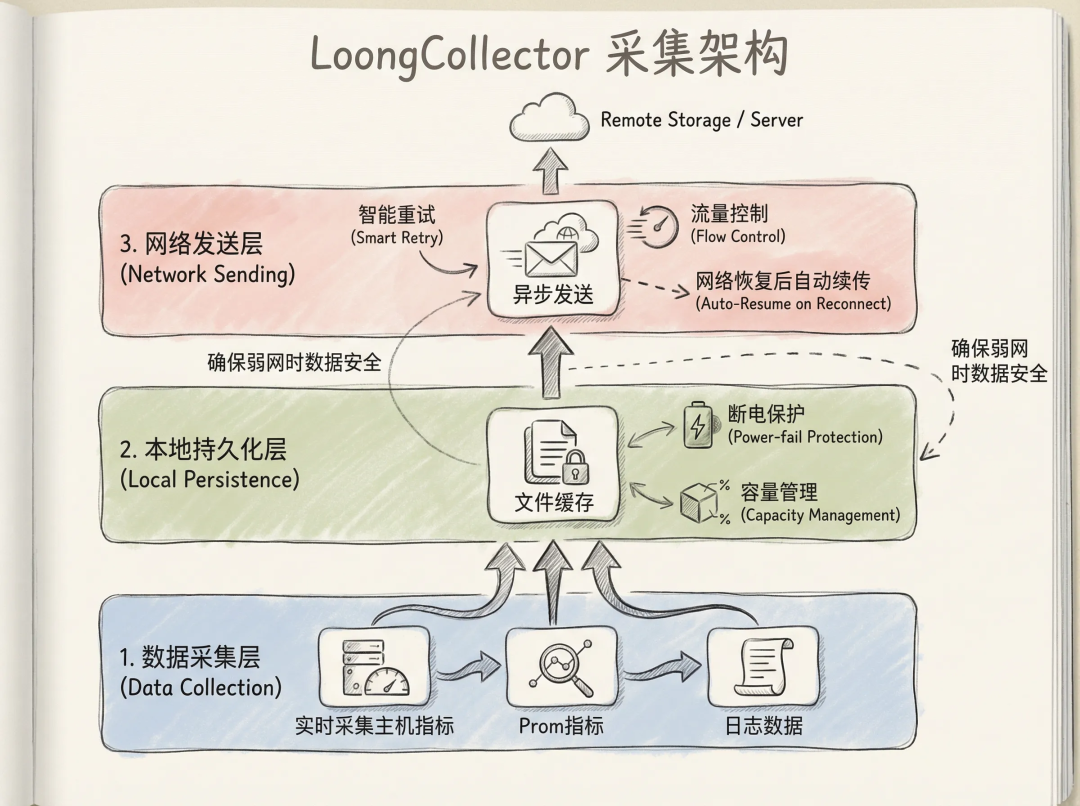
- 分离采集与发送:将数据采集和网络发送完全解耦,采集过程不受网络状态影响。
- 本地持久化:日志数据天然具备本地持久化的能力。此处主要指指标等无持久化能力的数据,此方案会将所有采集到的指标,先写入本地文件,确保断电、重启也不丢失。
- 异步消费:独立的发送线程从持久化文件中读取数据并发送,失败时自动重试。
- 智能反压:网络异常时,自动控制数据读取速度,避免内存占用过高。
指标数据落盘持久化
传统的指标采集方案(如Telegraf、Prometheus Pushgateway)通常将采集到的指标数据直接发送到服务端。这种架构在稳定网络环境下工作良好,但在边缘场景下存在致命缺陷:
- 断网丢数据:网络中断时,新采集的指标数据无法发送,只能丢弃或缓存在内存中。
- 断电丢数据:设备意外断电时,内存中缓存的数据全部丢失。
- 内存压力大:长时间断网时,内存缓存会迅速膨胀,最终导致OOM。
LoongCollector创新性地将主机监控指标和Prometheus指标进行本地文件持久化,实现了指标数据的可靠存储:
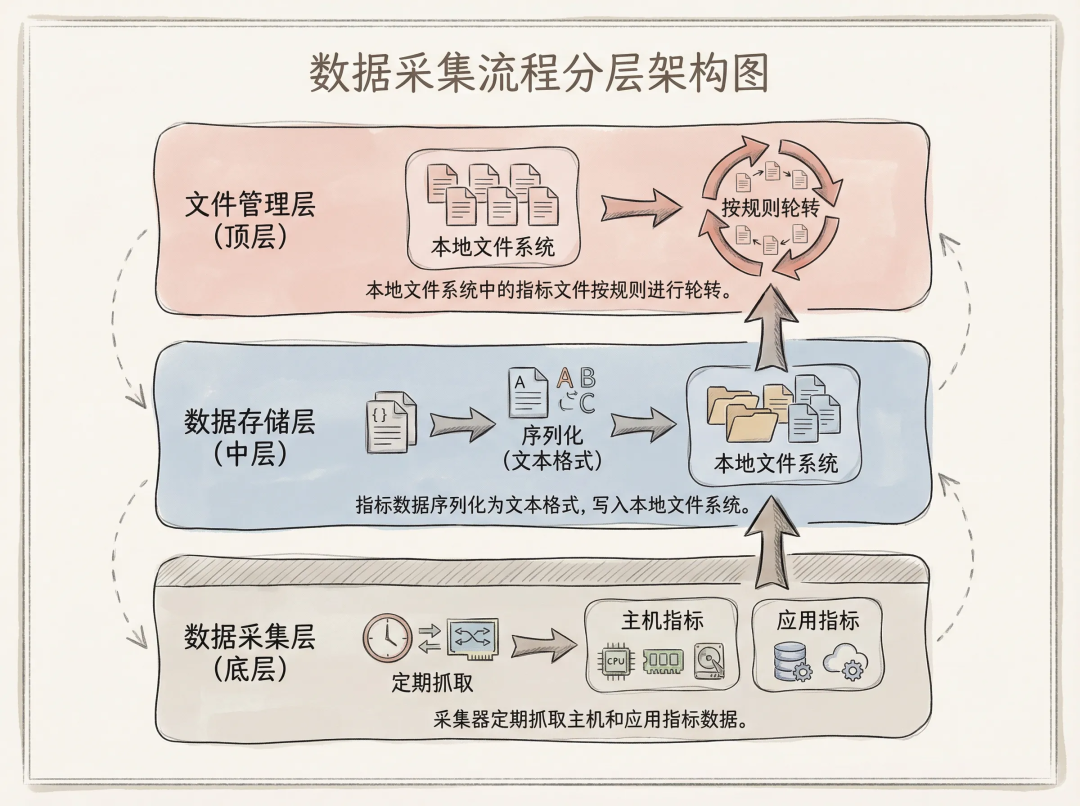
- 定时抓取主机和应用指标数据。
- 文本格式落盘到本地文件系统。
- 自动轮转机制,支持单文件大小和文件个数配置,保留最近固定格式的文件,自动删除过期文件,避免磁盘空间被历史数据占满。
文件采集异步消费机制
在持久化指标数据后,如何高效、可靠地将数据发送到服务端是下一个关键问题。传统方案面临的挑战包括:
- 发送阻塞采集:如果发送线程与采集线程耦合,网络慢会拖慢采集速度。
- 顺序性保证:指标数据通常有时间顺序要求,需要确保按采集时间顺序发送。
- 断点续传:网络恢复后,需要从断开位置继续发送,不能重复或遗漏。
LoongCollector采用了文件采集的方式来异步消费持久化的指标数据,关键技术点如下:
- Checkpoint机制:LoongCollector维护了细粒度的checkpoint,记录每个文件的读取位置,这确保了即使在文件读取过程中进程崩溃或断电,重启后也能从断开位置继续读取,不会丢失数据。
- 文件顺序保证:通过文件轮转顺序,确保按采集时间顺序发送数据:
- 优先处理时间早的文件
- 同一时间段的文件按序号递增处理
- 支持使用原始数据中的时间,避免时间戳乱序导致的数据可视化问题
智能反压与流量控制
在弱网环境下,如果不加控制地读取和发送数据,会导致:
- 内存占用激增:读取速度远大于发送速度,数据堆积在内存中。
- 发送队列溢出:队列满后数据被丢弃或进程崩溃。
- 带宽占满:采集流量占满带宽,影响业务正常通信。
LoongCollector实现了多层次的智能反压机制:
发送并发度自适应:借鉴TCP拥塞控制算法,LoongCollector根据网络状态动态调整发送并发度,这种自适应机制确保了:
- 快速响应:网络正常时充分利用带宽,快速发送数据。
- 快速收敛:网络异常时迅速降低发送频率,避免无效重试。
- 自动恢复:网络恢复后自动增加并发,无需人工干预。
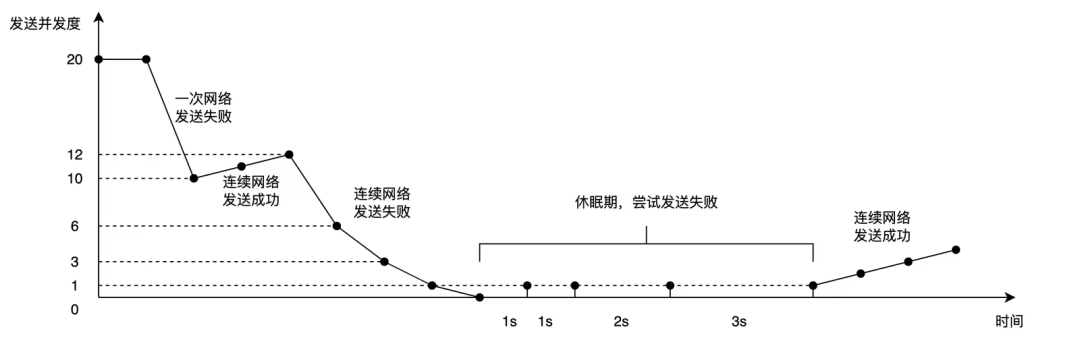
- 队列反压:当发送队列积压达到阈值时,LoongCollector会暂停文件读取,这避免了内存无限制增长,确保系统在长时间弱网环境下也能稳定运行。
- 流量限速:LoongCollector支持配置最大发送速率,避免采集流量影响业务。例如在
ilogtail_config.json中配置:
{
"max_bytes_per_sec": 1048576 # 限制最大发送速率为 10MB/s
}
LoongCollector终端部署最佳实践
这里以主机监控+一个应用的Prometheus采集为例,展示在边缘设备上的配置实践。
LoongCollector启动参数建议
在/usr/local/ilogtail目录下修改ilogtail_config.json。
a. 关闭丢弃旧数据discard_old_data。
b. 调大与服务端断开连接重启的间隔config_server_lost_connection_timeout,建议取604800秒,7天。
c. 调大读取阻塞重启的间隔force_quit_read_timeout,建议取604800秒,7天。
d. 限制最大发送速率max_bytes_per_sec。主机监控+一个Java应用的流量约为0.88KB/s,所以建议取1MB/s,避免异常使用流量。
e. working_ip,在移动终端场景,IP会不断变化,在机器上建议给固定IP。
ilogtail_config.json配置示例:
{
"discard_old_data": false,
"config_server_lost_connection_timeout": 604800,
"force_quit_read_timeout": 604800,
"max_bytes_per_sec": 1048576,
"cpu_usage_limit": 0.4,
"mem_usage_limit": 384,
"working_ip": "192.168.0.1"
}
采集配置
本地配置-主机监控采集配置
在/etc/ilogtail/config/local目录下创建例如input_host_monitor.yaml文件,将主机指标首先采集到本地文件路径下,例如/usr/local/ilogtail/metrics/host.log。
enable: true
inputs:
- Type: input_host_monitor
Interval: 15
flushers:
- Type: flusher_file
MaxFileSize: 104857600
MaxFiles: 10
FilePath: /usr/local/ilogtail/metrics/host.log
本地配置-自定义指标采集配置
在/etc/ilogtail/config/local目录下创建例如input_prometheus.yaml文件,将Prometheus指标首先采集到本地文件路径下,例如/usr/local/ilogtail/metrics/metric.log。
input_prometheus.yaml配置示例:
enable: true
inputs:
- Type: input_prometheus
ScrapeConfig:
job_name: node
host_only_mode: true
scrape_interval: 15s
scrape_timeout: 10s
static_configs:
- targets: ["localhost:12345"]
flushers:
- Type: flusher_file
MaxFileSize: 524288000
MaxFiles: 10
FilePath: /usr/local/ilogtail/metrics/metric.log
服务端管控配置-文件采集配置
最后,需要配置一个服务端下发的Pipeline,用于读取并发送本地持久化的指标文件。
{
"aggregators": [],
"global": {},
"logSample": "",
"inputs": [
{
"Type": "input_file",
"FilePaths": [
"/usr/local/ilogtail/metrics/*.log"
],
"MaxDirSearchDepth": 0,
"FileEncoding": "utf8",
"EnableContainerDiscovery": false
}
],
"processors": [
{
"Type": "processor_parse_json_native",
"SourceKey": "content",
"KeepingSourceWhenParseFail": true
}
]
}
注意事项
- 处理插件不要使用拓展插件,因为拓展插件会拉起Golang模块,导致内存占用升高。
- 移动终端场景,IP会不断变化,机器组建议使用标识型机器组,而非依赖IP的机器组,这对于管理动态 网络 环境下的设备至关重要。
LoongCollector资源监控测试报告
在实际的边缘模拟场景中(主机监控+一个Java应用Prometheus采集),LoongCollector的资源消耗表现如下:
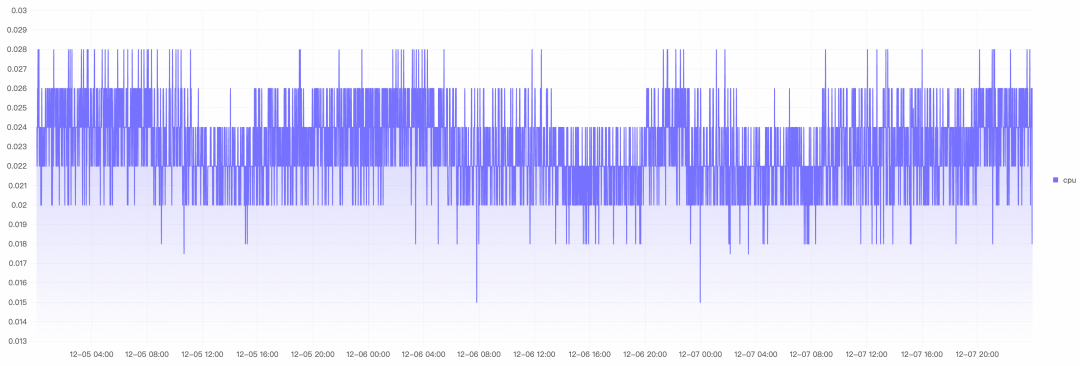
CPU:平均0.02核,峰值0.028核
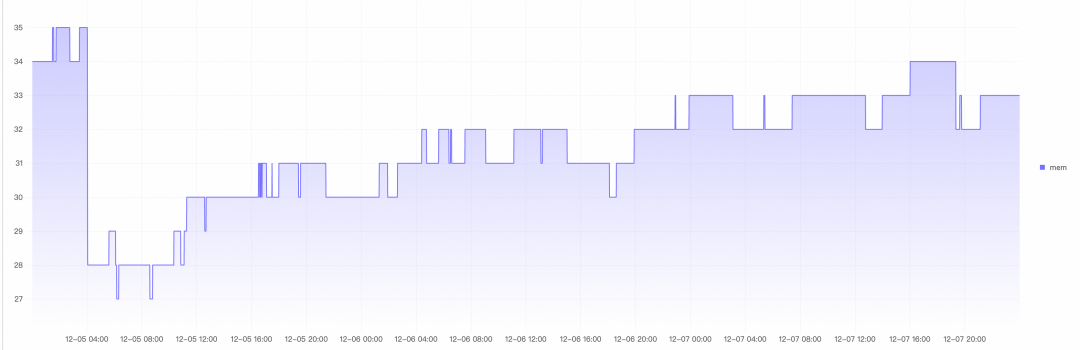
内存:平均31.5MB,峰值35MB
网络:
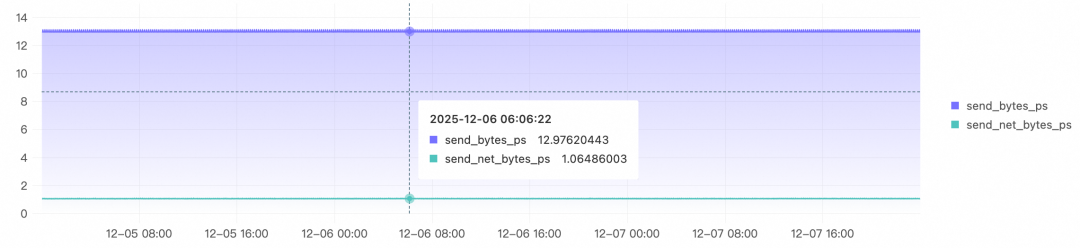
- 压缩前:平均12.99KB/s,峰值13.13KB/s
- 实际发送:平均1.07KB/s,峰值1.10KB/s(压缩效果显著)
磁盘:平均6.07KB/s,峰值13.03KB/s

总结与展望
边缘场景的可观测数据采集,是一个长期被低估的技术挑战。网络的不稳定性、电源的不可靠性、数据一致性的复杂性,让传统的采集方案在边缘环境下频繁失效。LoongCollector通过“数据持久化 + 异步发送 + 智能重试”的创新架构,系统性地解决了这些问题:
- 保证了可观测数据可靠交付
- 本地持久化保证断网不丢数据
- 异步发送机制实现采集与发送解耦
- 智能重试和反压确保网络恢复后数据完整上传
- 有效地进行了流量控制
- 高效压缩减少传输数据量
- 智能流量控制避免带宽占满,影响业务
但是,LoongCollector的采集方案还有更多的优化空间:
- 配置简化:当前的持久化采集方案需要配置两个Pipeline(采集Pipeline + 文件读取Pipeline),虽然灵活但增加了用户的理解和配置成本。LoongCollector正在进行流水线优化,支持单流水线内部持久化能力,方便用户配置。
- 安全增强:终端设备对于STS鉴权是强需求,LoongCollector正在适配阿里云STS动态鉴权,支持临时凭证自动刷新,避免终端AccessKey泄露风险。
- 极致压缩:在流量成本敏感的场景,每一个百分点的压缩率提升都意味着显著的成本节省,LoongCollector也正在探索更加极致的压缩策略,进一步降低网络流量。
随着边缘计算的普及,可靠、轻量、智能的数据采集方案将成为基础设施的关键一环。希望本文分享的LoongCollector实践,能为面临类似挑战的开发者提供有价值的参考。更多关于系统稳定性与性能优化的讨论,欢迎访问 云栈社区。
 发表于 2026-1-26 10:47:18
|
查看: 303|
回复: 0
发表于 2026-1-26 10:47:18
|
查看: 303|
回复: 0
