近日,X平台(原推特)宣布将其全新的推荐算法完全开源,并将其置于 GitHub 上供所有开发者研究与学习。特别值得注意的是,这套新算法采用了与xAI的Grok模型相同的Transformer架构。

核心的算法代码仓库地址为:https://github.com/xai-org/x-algorithm
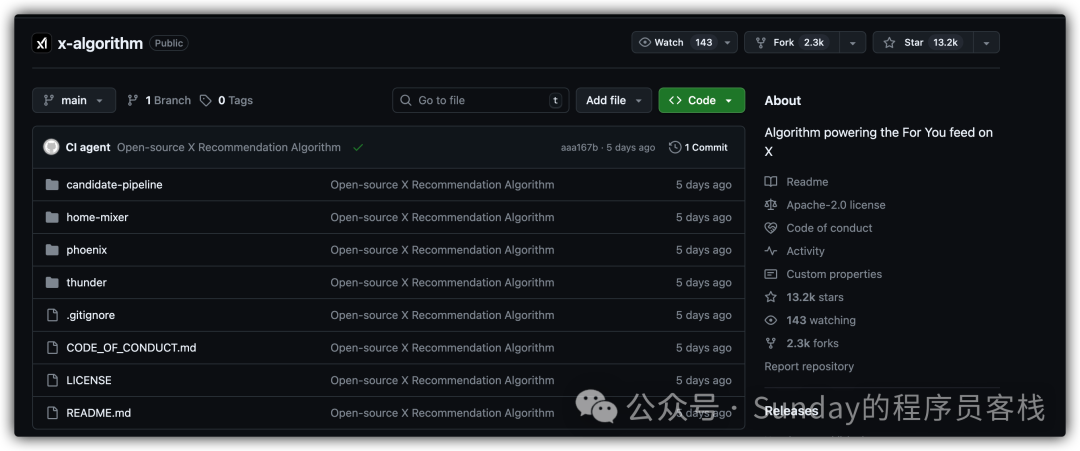
对大多数开发者而言,大型社交平台的推荐算法往往披着神秘面纱。此次X选择开源,无疑为技术社区提供了一个绝佳的、可深度剖析的实战案例。整个仓库的代码结构比较清晰,主要分为四个核心模块:
- home‑mixer:主控制器,负责汇总候选内容并执行整个推荐流水线。
- thunder:负责从用户关注的账户中实时获取帖子。
- phoenix:负责机器学习驱动的候选内容检索和打分。
- candidate‑pipeline:通用流水线框架,用于集成内容源、过滤器和评分器。
我们无需深入每一行代码,但理解其整体推荐机制颇为有趣。根据代码逻辑,其推荐流程大致可分为以下7个步骤:
1. 判断交互率
系统首先会评估用户的历史行为,例如帖子的点赞、回复、转发和评论等互动数据。这些显性行为在推荐权重中占据重要地位。
同时,算法还会分析用户的关注列表,通过统计所关注博主的类型分布,来推测用户可能偏好的内容方向。
2. 抓取候选内容
基于对用户的理解,算法会从两个渠道并行抓取潜在的推荐内容:
- 站内内容:由 Thunder 模块负责,抓取用户已关注账号发布的近期帖子,这是用户信息流的核心组成部分。
- 站外内容:由 Phoenix 召回模块通过机器学习技术,从平台的全网内容库中挖掘出用户未关注但可能感兴趣的帖子,旨在发现“新内容”。
3. 补全内容完整信息
为了后续打分的准确性,系统会对所有候选内容进行信息补全。这包括补充帖子的文本、图片/视频素材、作者信息(用户名、认证状态)、视频时长以及内容的访问权限等,确保每条内容的信息维度完整、一致。
4. 过滤无效内容
在进入核心打分环节前,算法会执行一次“前置过滤”,直接剔除不符合硬性要求的内容,例如:
- 重复的帖子
- 过期的内容
- 用户自己发布的帖子
- 来自已被屏蔽或拉黑账号的内容
- 包含用户拉黑关键词的内容
- 用户已经看过或近期刚被推送过的内容
- 用户无权限访问的付费内容
5. 对文章(帖子)进行多维度打分
过滤后的内容将进入核心打分环节。系统会依次调用多个打分器计算综合得分:
- Phoenix 打分器:利用基于 Grok 的 Transformer 模型进行机器学习预测。
- 加权打分器:将多个预测结果整合,形成最终的相关性得分。
- 多样性打分器:刻意降低来自同一作者的内容得分,以确保信息流的内容多样性,避免信息茧房。
- 站外内容打分器:专门调整从全网挖掘的内容的得分,以平衡站内与站外内容的展示比例。
6. 筛选排名
所有候选内容根据上一步计算出的得分进行排序,得分最高的内容将进入最终候选池。
7. 最终验证后推送
作为最后一道保障,系统会对即将推送的内容进行最终合规性与有效性校验。确认无误后,内容才会正式呈现在用户的“For You”信息流中。
整个推荐逻辑清晰且符合我们对现代推荐系统的基本认知。有趣的是,埃隆·马斯克本人在宣布开源时坦言,“我们知道这个算法很笨拙,需要大幅改进”,但他强调开源带来的透明化过程是其他社交平台未曾做到的。
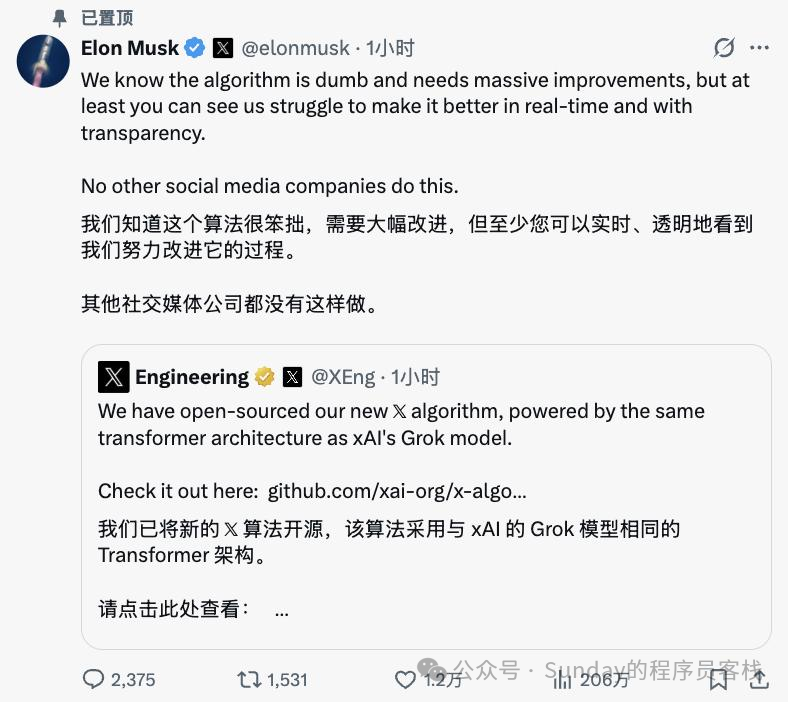
从技术社区和内容创作者的角度看,推荐算法的公开具有多重积极意义。首先,它打破了以往算法作为“商业黑箱”的状态,让算法的公平性、合理性得以被公众审视。更多开发者和研究者的参与,或许能催生出更优的推荐逻辑。
其次,对于创作者而言,算法的透明化提供了一种“确定性”。创作者不再需要依赖各种“玄学”经验(例如更换网络、设备,或猜测平台的隐形规则)来试图取悦算法,而是可以基于明确的规则来优化内容。这有助于让创作回归内容本身,而不是变成一场揣测机器心思的游戏。
推荐算法的初衷,本应是高效连接“优质内容”与“感兴趣的人”,而非让创作者沦为算法的投机者。 开源最大的价值或许不在于代码本身,而在于它将一部分“知情权”和“确定性”还给了生态的参与者。
此次X算法的开源,为业界提供了一个宝贵的开源实战样本。如果你对推荐系统、机器学习或大模型应用感兴趣,不妨去 GitHub 上深入研究一下这个项目。技术的进步离不开开放与交流,欢迎在云栈社区分享你的学习心得与见解。毕竟,在算法的世界里,比破解规则更重要的,是保持我们分享与探讨技术的初心。 |  发表于 2026-1-26 13:05:20
|
查看: 182|
回复: 0
发表于 2026-1-26 13:05:20
|
查看: 182|
回复: 0
