在Linux系统中,进程的内存空间被划分为不同的区域,其中堆(Heap)和栈(Stack)是程序员最常打交道的两个部分。理解它们的底层实现机制,是编写高效、稳定程序的关键,也是排查内存泄漏、性能瓶颈等问题的基石。
一、初识Linux内存布局
1.1 内存布局初探
当程序运行起来成为进程后,Linux内核会为其分配一块虚拟内存空间。这块空间并非杂乱无章,而是像精心规划的城市,被有序地划分为用户空间和内核空间两大区域,以及内部的多个功能段。
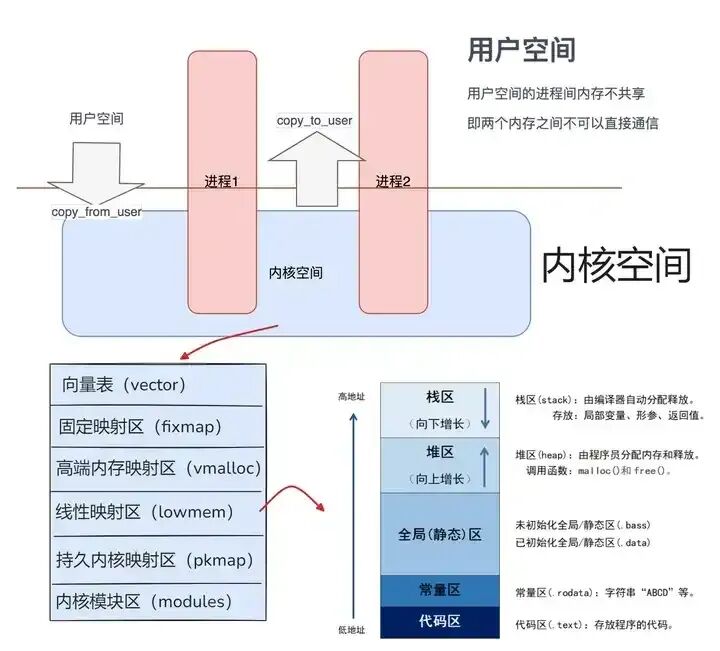
从这张图可以看到清晰的划分:用户空间是应用程序运行的“独立房间”,每个进程都拥有一份,互不干扰;内核空间则是系统核心的“公共设施”,所有进程共享。
我们可以将内存布局类比为一个大型商场的规划:
- 内核空间 如同商场的公共大厅和基础设施,为所有商铺(进程)提供基础支持。
- 用户空间 则是各个商铺的独立经营区域。
- 代码段 好比店铺的经营手册和操作规程(只读)。
- 数据段 是已经上架(已初始化)和待上架(未初始化)的货品仓库。
- 堆区 像是可以随时扩建或调整的临时储物区,用来存放大小不确定的货物。
- 栈区 则像前台处理顾客订单(函数调用)的临时工作台,订单处理完,工作台就清空。
1.2 整体架构剖析
Linux进程的内存布局主要包含以下几个核心部分:
内核空间:这是操作系统内核运行的区域,拥有最高权限,负责管理硬件、调度进程等核心功能。用户进程无法直接访问,必须通过系统调用的“窗口”来请求服务。
用户空间:这是用户程序的活动区域,进一步细分为:
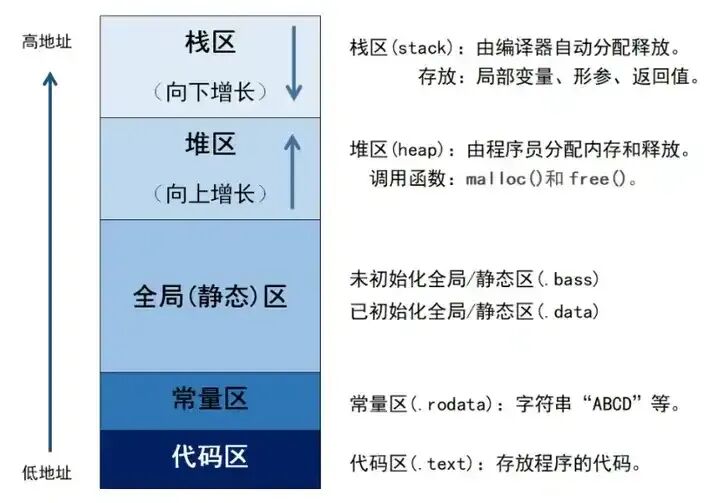
- 代码段:存放可执行指令,只读,确保程序逻辑不被篡改。
- 数据段:
- .data段:存放已初始化的全局变量和静态变量。
- .bss段:存放未初始化的全局变量和静态变量,程序加载时会被系统初始化为0。
- 堆:用于动态内存分配的区域。当程序运行时需要创建生命周期不确定或大小可变的对象时(例如,根据用户输入读取不定长的数据),就从这里申请内存。堆的大小可以动态增长(向高地址方向)。
- 栈:主要用于管理函数调用。每当函数被调用,系统就在栈上为其创建一个“栈帧”,用来存放该函数的局部变量、参数、返回地址等信息。栈遵循“后进先出”原则,生长方向是从高地址向低地址。
1.3 内存布局查看命令
在Linux中,我们可以通过命令直观地查看一个进程的内存布局。
(1)pmap 命令
pmap 命令可以显示进程的详细内存映射。
pmap -p 1234
假设进程ID为1234,输出可能如下:
1234: /usr/bin/bash
00400000 - 00409000 r-xp 00000000 08:01 13451234 /usr/bin/bash
00608000 - 00609000 r--p 00008000 08:01 13451234 /usr/bin/bash
00609000 - 0060a000 rw-p 00009000 08:01 13451234 /usr/bin/bash
01697000 - 016b8000 rw-p 00000000 00:00 0 [heap]
7ffc9103d000 - 7ffc9105e000 rw-p 00000000 00:00 0 [stack]
7ffc910f2000 - 7ffc910f3000 r--p 00000000 00:00 0 [vvar]
7ffc910f3000 - 7ffc910f5000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000 - fffffffe601000 --xp 00000000 00:00 0 [vsyscall]
其中,[heap] 和 [stack] 明确标识了堆和栈的地址范围及读写权限。
(2)cat /proc/<pid>/maps 命令
/proc 文件系统也提供了同样的信息,格式略有不同。
cat /proc/1234/maps
二、栈的深度剖析
2.1 栈的物理与逻辑画像
栈在物理上是一段连续的内存,这种连续性带来了高效的访问速度。它的独特之处在于生长方向:从高地址向低地址生长。
逻辑上,栈是一个“后进先出”的数据结构,基本操作单元是 栈帧。每个函数调用都会对应一个栈帧,它像是一个收纳盒,里面整齐存放着这次函数调用所需的“行李”:局部变量、传入参数、返回地址以及需要保存的寄存器值等。函数调用链就像一摞叠起来的收纳盒,最上面的就是当前正在执行的函数。
2.2 栈帧:函数调用的舞台
让我们通过一段简单的C代码和其背后的操作系统原理,看看栈帧是如何工作的。
#include <stdio.h>
int Add(int x, int y){
int z = 0;
z = x + y;
return z;
}
int main(){
int a = 10;
int b = 20;
int c = 0;
c = Add(a, b);
printf("%d\n", c);
return 0;
}
当 main 函数调用 Add 函数时,会发生以下步骤:
- 保存现场:将
main函数的栈帧基址(ebp)压栈,然后将当前栈顶(esp)设为新的基址,标志着Add函数栈帧的开始。
- 分配空间:通过下移栈顶指针(
esp),为Add的局部变量z分配空间。
- 传递参数:调用前,实参
a和b的值已经被压入栈中(通常从右向左),Add函数可以通过偏移量访问它们。
函数执行完毕后,过程相反:
- 恢复现场:将栈顶指针
esp移回当前栈帧基址ebp,然后弹出之前保存的main函数的ebp,这样就回到了main的栈帧。
- 返回:从栈中弹出返回地址,CPU跳转到那里继续执行(即
printf语句)。
从汇编层面看,这个过程更加清晰。[函数调用](https://yunpan.plus/f/25-1)和栈帧操作通常涉及以下指令:
push ebp ; 保存调用者的栈帧基址
mov ebp, esp ; 建立当前函数的栈帧基址
sub esp, 0x10 ; 为局部变量分配16字节空间
... ; 函数体
mov esp, ebp ; 恢复栈顶指针,清理局部变量空间
pop ebp ; 恢复调用者的栈帧基址
ret ; 弹出返回地址并跳转
2.3 栈的大小与动态调整
栈空间并非无限。在大多数Linux系统上,进程的默认栈大小约为8MB。对于普通的函数调用,这绰绰有余。但在深度递归或定义超大局部数组时,就可能引发栈溢出。
我们可以调整栈的大小:
2.4 栈溢出:危险的信号
栈溢出是指栈的使用量超过了其分配的空间。常见原因有:
栈溢出的后果非常严重:
- 程序崩溃:最直接的结果,系统可能产生核心转储(core dump)。
- 安全漏洞:攻击者可以精心构造输入,让溢出的数据覆盖栈上的返回地址,从而劫持程序执行流,执行恶意代码。
2.5 栈的安全防线
现代系统和编译器提供了多种机制来防御栈溢出攻击:
- 栈金丝雀:编译器(如GCC的
-fstack-protector)会在栈帧的返回地址前插入一个随机值(金丝雀)。函数返回前检查该值,若被修改(可能因溢出导致),则立即终止程序。
- 栈不可执行:通过内核支持,将栈所在的内存页标记为不可执行。即使恶意代码被注入栈中,CPU也无法执行它。
- 地址空间布局随机化:在程序启动时,随机化栈、堆、库的加载地址,使攻击者难以预测关键数据的地址,大大增加攻击难度。可通过
/proc/sys/kernel/randomize_va_space 控制。
三、堆的深度剖析
3.1 堆的内存模型与分配器原理
与栈相反,堆是一块从低地址向高地址增长的动态内存区域,通常不要求连续。你可以把它想象成一个由程序员自己管理的大仓库。
堆的分配和释放不由系统自动完成,而是由 堆分配器 管理。当调用 malloc() 申请内存时,分配器在堆仓库中寻找合适的空闲“货位”;调用 free() 释放时,分配器将该货位标记为空闲,并可能合并相邻的空闲货位以减少碎片。
3.2 主流堆分配器大比拼
Linux环境下有多种堆分配器,各有侧重:
- ptmalloc:Glibc默认分配器,历史悠久,在通用性和性能间平衡较好,适用于大多数应用。
- tcmalloc:Google开发,特点是线程缓存。每个线程有自己的小缓存,分配小内存时无需全局锁,极大提升了多线程程序的性能。
- jemalloc:Facebook开发,注重减少内存碎片和提高并发性能,在长时间运行、频繁分配释放的应用(如Redis、RocksDB)中表现优异。
3.3 ptmalloc分配器深度探秘
以ptmalloc为例,其核心概念是 内存块。每个内存块包含元数据(如大小、状态)和用户数据。
malloc流程:申请内存时,ptmalloc会依次查找:
- 快速链表:存放刚释放的小内存块,分配速度极快。
- 普通链表:按大小分类的空闲块链表。
- 堆顶空间:从当前堆的末尾划分。
- 系统调用:如果堆空间不足,则通过
brk 或 mmap 向操作系统申请新内存。
free流程:释放内存块时,ptmalloc会将其标记为空闲,并尝试与物理相邻的前后空闲块合并,形成更大的空闲块,然后放入相应的链表。
3.4 堆内存管理的陷阱
手动管理堆内存,极易出错:
- 内存泄漏:分配了内存却忘记释放。
void leak() {
int *p = malloc(100);
// 忘记 free(p);
}
- 悬空指针:释放了内存,但指针仍指向该地址,后续使用导致未定义行为。
void dangling() {
int *p = malloc(100);
free(p);
*p = 10; // 危险!p已成为悬空指针
}
- 内存越界:读写操作超出了分配的内存边界,破坏相邻数据或元数据。
void overflow() {
int *p = malloc(5 * sizeof(int));
for(int i=0; i<=5; i++) { // 访问了p[5],越界!
p[i] = i;
}
}
- 双重释放:对同一块内存调用
free() 两次。
- 内存碎片:频繁分配释放不同大小的内存,导致堆中散布许多小空闲块,无法满足大块内存申请。
3.5 堆问题诊断与调试
幸好,我们有强大的工具来发现这些问题:
- Valgrind:重量级内存调试器,能检测泄漏、越界、使用未初始化内存等问题。
valgrind --leak-check=full ./your_program
- AddressSanitizer:编译时插桩工具,速度比Valgrind快,对性能影响小。
gcc -fsanitize=address -g -o prog prog.c
./prog
- GDB:经典调试器,可以检查内存内容、回溯调用栈,定位问题源头。
四、堆与栈的核心差异对比
| 特性 |
栈 |
堆 |
| 管理方式 |
系统自动分配/释放(编译器负责) |
程序员手动分配/释放(malloc/free, new/delete) |
| 生长方向 |
高地址 -> 低地址 |
低地址 -> 高地址 |
| 空间大小 |
较小(默认约8MB),固定或可调 |
很大,受限于系统虚拟内存大小,可动态扩展 |
| 分配效率 |
极高,仅需移动栈指针 |
较低,需在复杂数据结构中查找/合并空闲块 |
| 存放内容 |
函数参数、局部变量、返回地址等 |
动态分配的任何数据(大小、生命周期不定) |
| 主要问题 |
栈溢出 |
内存泄漏、碎片、悬空指针等 |
4.2 栈与堆的交互
在实际程序中,栈和堆协同工作。一个典型场景是:栈上的指针变量,指向堆上分配的内存。
void process() {
// 栈上变量 `arr` 本身(一个指针)在栈上
int *arr;
// 但 `arr` 指向的内存空间在堆上分配
arr = malloc(100 * sizeof(int));
// 使用堆内存...
for(int i=0; i<100; i++) {
arr[i] = i;
}
// 必须手动释放堆内存
free(arr);
// 函数结束,栈变量`arr`被自动回收
}
这种协作模式在复杂软件中无处不在,是理解内存管理的关键。
五、Linux内存优化与案例分析
5.1 内存优化技巧
- 减少分配次数:避免在循环内频繁分配释放小内存。可预先分配一块足够大的内存重复使用。
- 选择合适分配器:根据应用特点(多线程、碎片敏感)选择 tcmalloc 或 jemalloc。
- 使用内存池:对于固定大小的对象频繁申请释放,自定义内存池可以极大提升性能。
- 及时释放:遵循“谁分配,谁释放”的原则,确保逻辑清晰,避免泄漏。
5.2 栈溢出导致程序崩溃案例
#include <stdio.h>
void recursive(int depth) {
char buffer[1024]; // 每次递归消耗1KB栈空间
printf("Depth: %d\n", depth);
recursive(depth + 1); // 无终止条件的递归
}
int main() {
recursive(1);
return 0;
}
这段代码会快速耗尽栈空间,导致 Segmentation fault。解决方案:为递归设置合理的终止条件,或改用迭代算法。
5.3 堆内存泄漏问题案例
#include <stdlib.h>
void process_request() {
char *data = malloc(1024);
// ... 处理数据
// 忘记 free(data); // 每次调用都泄漏1KB
}
这种泄漏在短时间运行的程序中可能不明显,但在长期运行的服务器中会逐渐耗尽内存。解决方案:使用 Valgrind 等工具检测,并确保每处 malloc 都有对应的 free。
理解Linux内存布局中堆与栈的底层机制,不仅仅是理论知识,更是解决实际开发中性能调优、崩溃排查、安全加固等问题的利器。希望本文能帮助你构建起清晰的内存模型。如果你在实践中有更多心得或疑问,欢迎在云栈社区与广大开发者交流探讨。
 发表于 2026-1-27 00:26:23
|
查看: 217|
回复: 0
发表于 2026-1-27 00:26:23
|
查看: 217|
回复: 0
