当AI大模型训练需要TB级显存带宽、HPC集群追求微秒级延迟、OCP开放架构不断突破硬件整合边界时,I/O连接技术早已成为制约性能天花板的关键。PCIe 7.0技术方案,不仅带来了翻倍的传输速率,更以Unordered IO(UIO)为核心突破了传统PCIe的排序桎梏,为下一代服务器基础设施注入了关键动力。

一、PCIe 7.0的核心升级:不止是速率翻倍
PCIe作为服务器、显卡、存储等硬件的“数据高速公路”,每一代升级都遵循“性能迭代+兼容性延续”的原则,PCIe 7.0也不例外。它并非颠覆性重构,而是在PCIe 6.0基础上的精准增强,核心亮点可概括为“速率跃升+效率优化+生态兼容”三大关键词:
1. 速率与带宽:128 GT/s的硬核实力
PCIe 7.0将单lane(通道)数据速率提升至 128 GT/s(原始比特率),通过x16通道配置,双向带宽可达 512 GB/s——这个数字是什么概念?相当于每秒能传输512GB数据,足以支撑20路4K视频的实时传输,或在1秒内完成100部高清电影的拷贝。
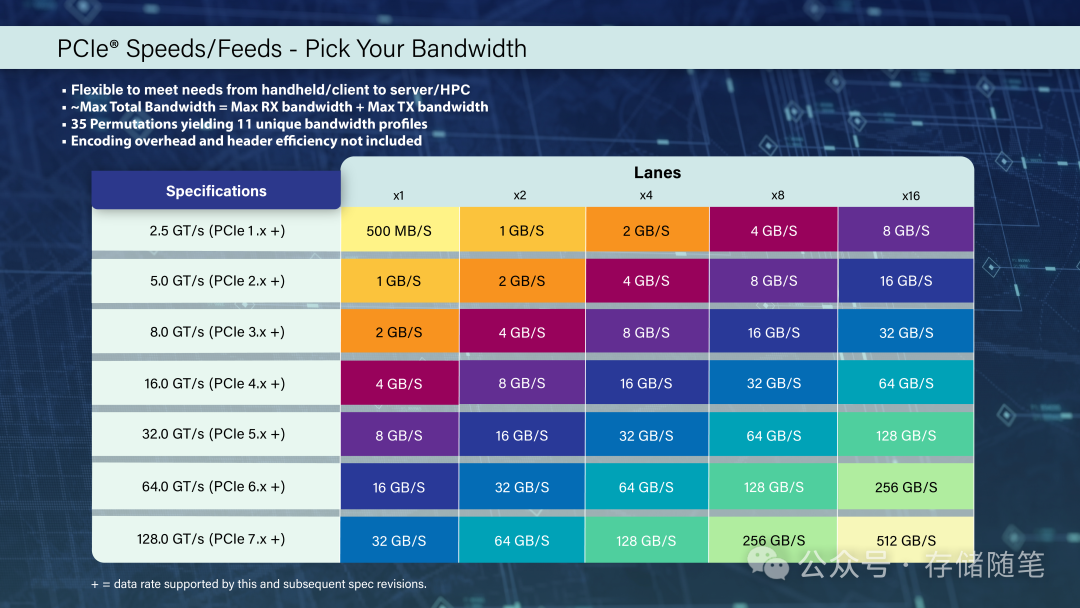
更关键的是,它沿用了PCIe 6.0的PAM4 signaling技术,没有引入全新信号机制,既降低了硬件升级成本,也保证了与前五代PCIe技术的 完全向后兼容——这意味着老设备可无缝接入新平台,企业无需一次性替换全部硬件。
2. 核心特性增强:不止于“快”,更在于“灵”
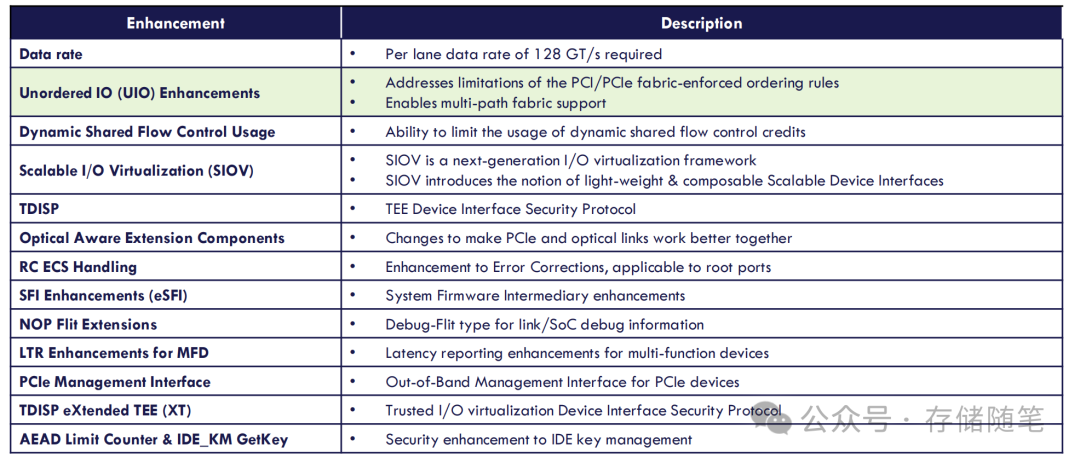
如果说速率翻倍是基础操作,PCIe 7.0的真正突破在于针对AI/HPC场景的特性优化,其中13项核心增强里,以下几项对服务器最具实战价值:

这些特性并非孤立存在,而是围绕“AI/HPC场景的高带宽、低延迟、高安全、高虚拟化”需求精准设计,尤其 UIO技术,堪称解决PCIe 7.0性能瓶颈的“点睛之笔”。
二、排序难题:PCIe高速传输的隐形枷锁
要理解UIO的价值,首先要搞懂传统PCIe的“排序困境”。PCIe协议为了保证数据一致性,制定了四大硬性排序规则(WAW、RAW、CAW、CAC),简单来说就是:
- WAW:后发的写操作不能超过先发的写操作;
- RAW:读操作必须等前面的写操作完成才能执行;
- CAW:数据完成信号(completions)要等对应的写操作完成;
- CAC:完成信号之间也要按发送顺序传输。

这些规则在低速时代不成问题,但到了PCIe 7.0的14 TLP/ns(x16通道)速率下,就成了严重的性能桎梏:
- 延迟增加:哪怕是无关的读/写操作,也要排队等待前序操作完成,比如“写一个小文件”后,“读一个大文件”必须等写操作结束,造成无效等待;
- 缓冲压力:为了遵守排序规则,设备需要更大的缓冲区存储待处理数据,PCIe 7.0带宽翻倍但延迟不变,导致缓冲需求直接翻倍;
- 复杂度飙升:相干互联(Coherent Interconnect)需要在256GB/s的单向速率下维持排序,还要处理P2P和内存绑定流量的交织,硬件设计难度指数级上升。
对于AI服务器的XPU(加速器)、HPC的分布式存储来说,这种“虚假排序依赖”(无关操作被迫排队)造成的性能损失,甚至能达到30%以上——这也是为什么PCIe 7.0必须突破排序规则的核心原因。
三、UIO技术:无序传输如何解锁性能上限?
UIO(Unordered IO)的本质,是PCIe 7.0引入的“无序传输通道”,它允许数据完全打破传统排序规则,任何TLP(事务层数据包)都能超越其他TLP传输,核心设计有三大亮点:
1. 技术原理:独立通道+全局可见性
- 专属VC通道:UIO流量通过独立的VC3通道传输,与传统有序传输的VC0通道并行工作,互不干扰——也就是说,UIO不是替代有序传输,而是提供“有序+无序”的双选项;
- 全局确认机制:每个UIO事务都会收到“全局可见性确认”,确保数据传输的一致性,避免无序传输导致的数据错乱;
- 可选能力:UIO是可选特性,设备可根据需求开启,兼顾兼容性与灵活性。
2. 核心价值:三大痛点一次性解决
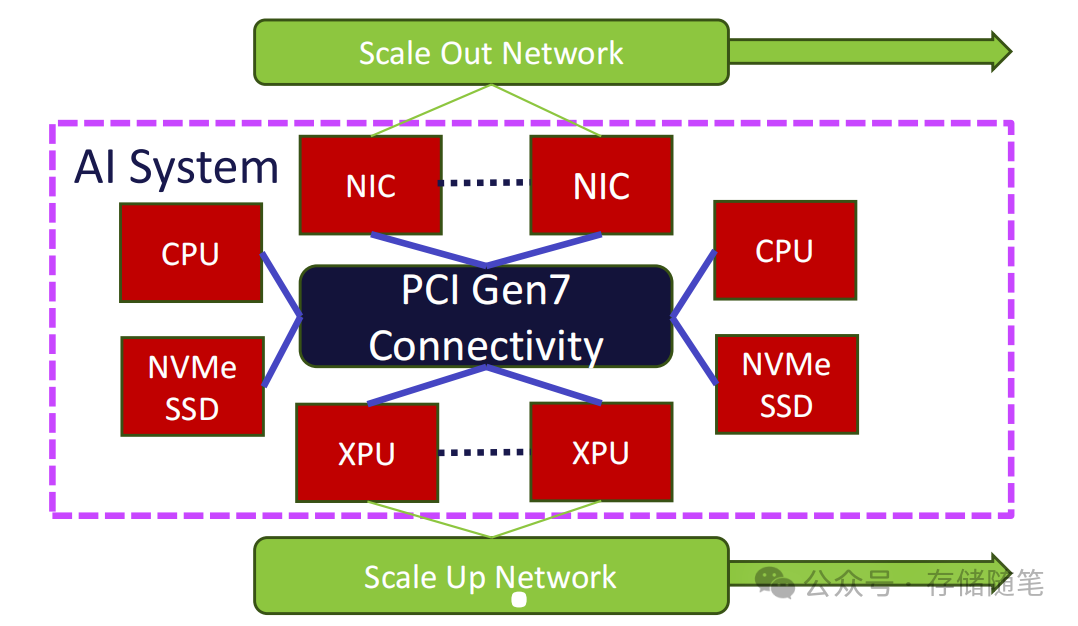
- 解锁多路径拓扑:传统PCIe受排序规则限制,只能支持树状拓扑,UIO允许数据通过多条路径传输(比如直接从XPU到存储,无需经过CPU转发),打破了硬件连接的物理限制;
- 消除虚假排序:无关的读/写操作无需排队,比如AI训练中的“模型参数读取”和“中间结果写入”可并行执行,彻底释放通道带宽;
- 转移复杂度:将排序逻辑从传输路径上的所有设备,集中到数据发送端(比如XPU、网卡),减少了中间节点的处理压力,降低了整体硬件复杂度。
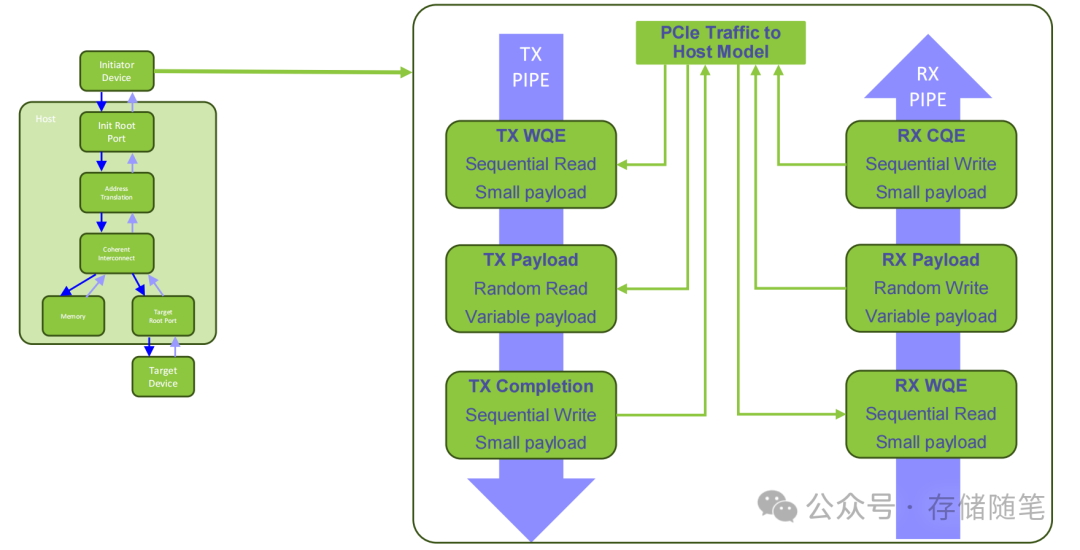
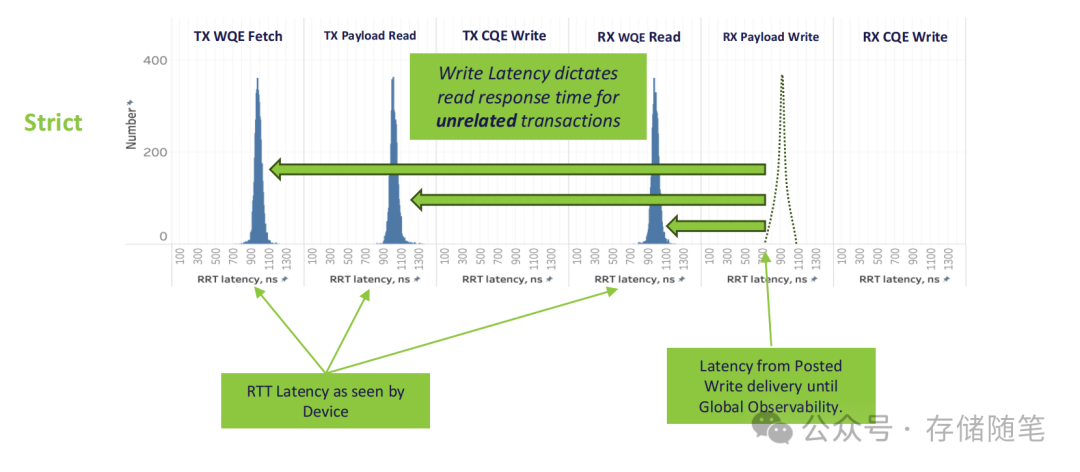
3. 实测数据:延迟与吞吐量的双重突破
Broadcom与Arm的建模测试数据,直观展现了UIO的性能优势:
- 延迟表现:在TX WQE获取、Payload读写、CQE写入等关键流程中,UIO将单操作延迟从“严格排序”的数900-1110ns,降低至 100-300ns级别——对于AI训练的高频小数据包传输,这个提升能直接缩短训练周期;
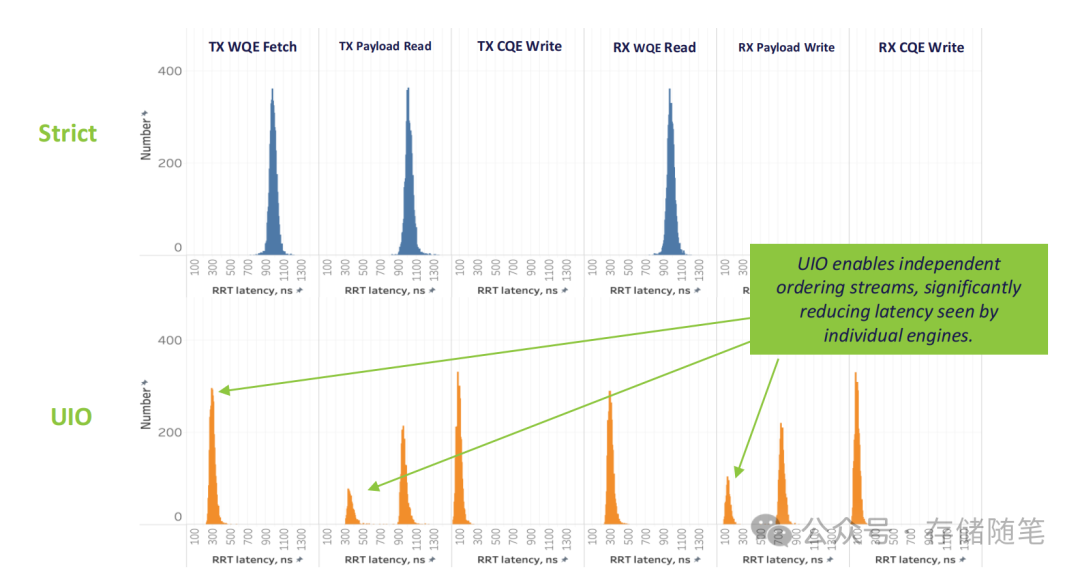
- 吞吐量表现:当缓冲区地址空间超过20GiB时,UIO的吞吐量稳定在90%以上,而严格排序模式仅能维持70%左右——意味着在大数据量传输场景下,UIO能更充分地利用PCIe 7.0的带宽。
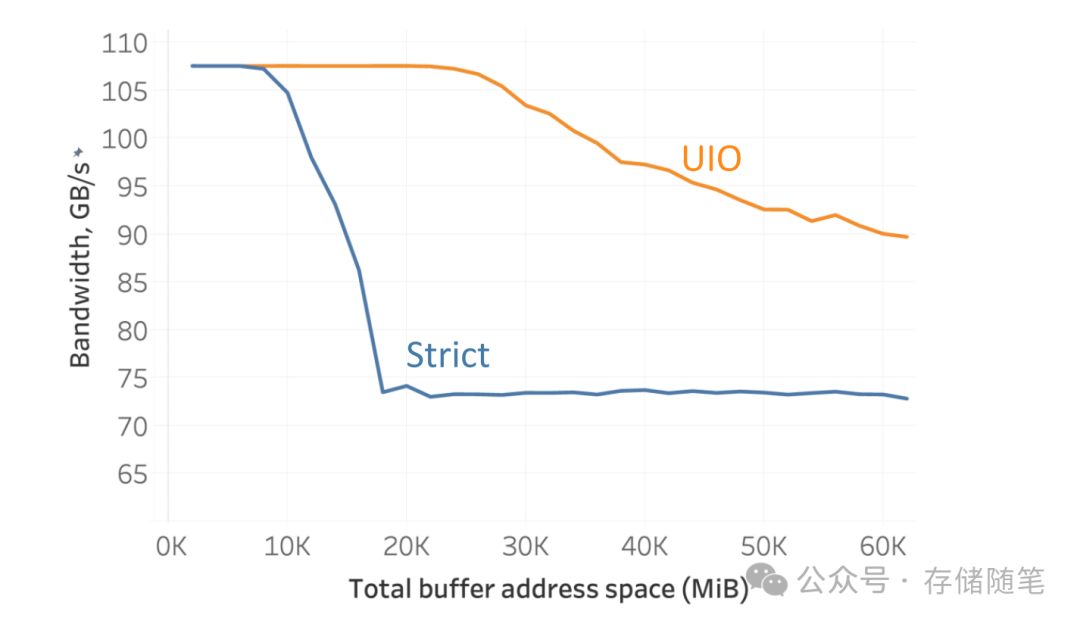
四、UIO的现实挑战:不是“万能”的,但值得投入
尽管UIO优势显著,但它并非完美解决方案,实际部署中仍面临三大挑战:
1. 设备复杂度提升
开启UIO后,终端设备(如网卡、XPU)需要自行跟踪读/写事务状态,内部pipeline必须覆盖写延迟——这对硬件设计提出了更高要求,芯片厂商需要重新优化固件逻辑。
2. 系统配置门槛
混合部署UIO设备和非UIO设备时,需要仔细分析网络拓扑结构和配置参数,避免有序/无序流量冲突;同时,混合TLP流量的排序一致性需要额外验证,增加了系统集成的工作量。
3. 性能依赖场景
当存在大量WAW排序依赖(比如连续写入同一块内存)时,UIO的无序传输优势会失效,甚至可能因频繁的确认机制导致性能下降——这意味着UIO更适合“多任务并行、低依赖”的AI/HPC场景,而非单一连续读写场景。
总结:PCIe 7.0的核心价值,是为AI时代“松绑”
PCIe 7.0的128 GT/s速率固然震撼,但真正的革命意义在于:通过UIO等特性打破了传统PCIe的排序枷锁,让I/O传输从“按序排队”升级为“按需并行”——这恰好匹配了AI/HPC场景的“多任务、高并发、低依赖”需求。
对于企业用户来说,无需盲目追求硬件升级,而是要结合自身场景:如果是AI训练、分布式计算等场景,PCIe 7.0+UIO的组合能带来显著的性能提升;如果是传统的单任务处理场景,现有PCIe 5.0/6.0仍能满足需求。
而对于整个行业来说,PCIe 7.0与OCP生态的结合,将加速开放架构在高端计算领域的渗透——当高速I/O不再是瓶颈,硬件创新的重心将转向“模块化整合”与“软件定义优化”,这或许正是下一代服务器基础设施的核心方向。关于PCIe等底层硬件协议与计算机基础的更多深度讨论,也欢迎在云栈社区继续交流。
参考文献:ARM/Broadcom-《PCIe 7.0 Enhancements for High-speed I/O Connectivity on OCP Server Infrastructure》
 发表于 2026-1-27 01:31:30
|
查看: 236|
回复: 0
发表于 2026-1-27 01:31:30
|
查看: 236|
回复: 0
