💡 你花了三天时间,终于在一个开源模型仓库里找到了那篇顶会论文的代码。克隆、安装依赖、解决版本冲突、下载预训练权重……一通操作下来,报错信息却比论文还长。你看着屏幕上“CUDA版本不匹配”的提示,陷入了沉思:为什么用个现成的AI模型,比从头训练一个还难?
这正是全球医学影像AI研究者面临的共同困境。无数优秀的模型因“难以部署”而被束之高阁,无法在临床或研究中发挥价值。但今天,一个名为 MHub.ai 的平台正在彻底改变这一现状。
开源平台已放出:https://github.com/MHubAI
在线模型库:https://mhub.ai/
它通过一套极简的标准化接口,将30多个经过同行评审的顶级医学影像AI模型(涵盖分割、预测、特征提取)打包成“即开即用”的容器。更重要的是,它让你能用完全相同的命令,在相同的临床DICOM数据上,并行运行并横向比较不同模型的性能。
读完本文,你将彻底掌握:
- MHub.ai如何用四层架构解决模型部署的“最后一公里”难题
- 其标准化容器与统一API的设计哲学与实现细节
- 如何利用该平台,对三个顶尖肺部分割模型进行一键式公平对比
- 这一范式对推动AI模型临床转化与可重复性研究的革命性意义
核心痛点:为什么99%的AI模型无法走出论文?
AI在医学影像领域展现出巨大潜力,但现实却异常骨感。研究表明,尽管大量模型以开源形式发布,但极少被外部研究者成功复现,更别提融入临床工作流。
问题出在哪?根源在于惊人的 “实现异构性” :
- 环境依赖地狱:每个模型都有独特的Python包、CUDA、系统库依赖。版本冲突是家常便饭,“在我机器上能跑”成为终极玄学。
- 数据格式鸿沟:医院标准是DICOM,但模型训练多用NIfTI、PNG等格式。手动转换耗时耗力,且极易出错。
- 接口五花八门:有的模型用命令行参数,有的需要配置文件,有的则必须通过Python脚本调用。没有统一标准。
- 输出杂乱无章:分割结果可能是NIfTI文件、NumPy数组,或是自定义的二进制格式,语义标签定义也各不相同。
- 文档严重缺失:近半数开源模型没有完整的使用文档,安装步骤、参数说明全靠猜。
这些碎片化问题叠加,导致研究者评估或比较不同模型时,需要为每个模型重复搭建环境、转换数据、理解接口,绝大部分精力耗费在工程而非科学问题上。最终,模型之间无法进行公平、高效的基准测试,研究的可重复性更是无从谈起。
但为什么这些看似基础的问题长期得不到解决?关键在于缺乏一个系统级的、强制性的标准化框架。 MHub.ai的诞生,正是为了填补从“模型代码”到“临床可用”之间的巨大鸿沟。
为了帮你快速把握其如何系统性解决上述痛点,我们先看这张核心架构思维导图——
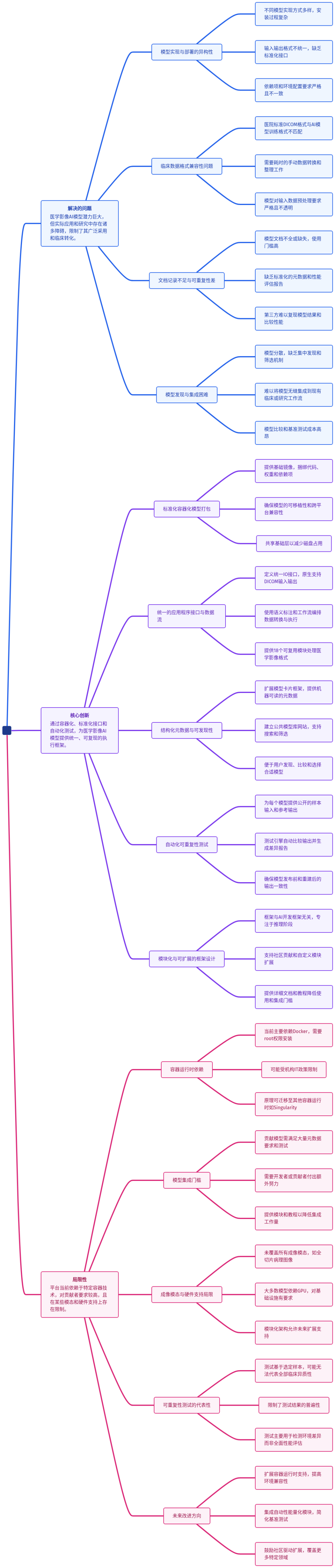
接下来,我们逐层拆解这张图中的每个关键模块,看它如何将复杂变为简单。
原理拆解:四层架构,化繁为简
MHub.ai的核心是一个高度模块化的四层架构,它将模型部署的复杂性层层抽象,最终为用户提供一个极其简单的统一接口。
第一层:容器化环境(隔离与便携)
这是所有模型的运行基石。MHub.ai为每个模型创建一个基于Docker的容器镜像。
关键设计:
- 统一基础镜像 (
mhubai/base:latest):所有模型镜像都从此镜像开始构建。它预装了MHub.ai框架、常用医学图像处理工具(如dcm2niix, plastimatch)和Python科学计算栈。这确保了环境一致性,并大幅减少了镜像的磁盘占用(共享基础层)。
- 离线打包:模型权重、源代码、所有依赖项在构建时就下载并打包进镜像。这意味着运行时无需网络连接,避免了因网络问题或源地址失效导致的失败。
- 标准化入口:所有容器的入口点都统一设置为MHub.ai的运行引擎 (
mhub.run),并默认指向一个名为 default 的工作流。
这相当于为每个模型提供了一个自带所有“家具”和“水电”的标准化精装房,用户只需“拎包入住”(运行容器),无需关心装修(环境配置)。
第二层:统一API(一致的交互)
容器化解决了环境问题,但如何与容器内的模型交互?MHub.ai通过其框架定义了一套统一的应用程序接口。
核心是IO模块(Input/Output Module)和工作流:
- IO模块:将数据处理流程拆解为原子任务,如“导入DICOM”、“转换为NIfTI”、“运行AI推理”、“导出为DICOM-SEG”。每个模块都是一个Python类,通过装饰器声明其需要的输入、产生的输出以及可配置参数。
# 示例:一个简化版的推理模块声明
@Configurable() # 声明可配置参数
@Input('image', type='nifti', description='输入CT图像') # 声明输入
@Output('segmentation', type='nifti', description='分割结果') # 声明输出
class LungSegmentationModule(BaseModule):
def task(self):
image_path = self.inputData['image'].path
# 调用原始模型代码进行推理
seg_path = run_model(image_path, self.config)
self.outputData['segmentation'].path = seg_path
- 工作流:一个YAML文件,定义了IO模块的执行顺序和配置。默认工作流实现了从“原始DICOM输入”到“标准化DICOM-SEG输出”的完整Pipeline。
对用户的价值:无论模型内部多复杂,用户与所有MHub.ai模型的交互方式都一模一样——一个标准的Docker运行命令。
# 运行TotalSegmentator模型
docker run -v /本地/输入目录:/input -v /本地/输出目录:/output mhubai/totalsegmentator
# 运行LungMask模型(仅模型名不同)
docker run -v /本地/输入目录:/input -v /本地/输出目录:/output mhubai/lungmask
这种一致性是进行模型并行比较的基础。
💡 实战思考:这个设计是否让你想起了手机App商店?每个App内部实现千差万别,但安装和启动方式却高度统一。MHub.ai正是在为AI模型打造一个“医学影像AI应用商店”。
第三层:结构化元数据(模型“说明书”)
如何知道一个模型适合处理胸部CT还是脑部MRI?MHub.ai为每个模型配备了一个结构化的 meta.json 文件。
内容涵盖:
- 模型卡片:基于业界倡议,描述预期用途、训练数据、性能评估、已知局限。
- 技术规格:支持的成像模态(CT、MR、PET等)、兼容的对比剂增强类型、推荐的图像切片厚度。
- 溯源信息:原始论文引用、源代码仓库链接、许可证。
- 示例图像:提供代表性输入和输出的可视化,让用户一目了然。
这些元数据不仅方便人类阅读,更是机器可读的。MHub.ai官网的模型库利用这些数据实现了强大的筛选和搜索功能。你可以轻松找到“所有能分割左肺上叶的CT模型”。
第四层:可复现性测试(信任的基石)
这是MHub.ai最具创新性的设计之一。每个模型都必须附带一个公开的、真实的样本输入数据集(通常来自公共数据库)和对应的参考输出。
自动化测试流程:
- 平台下载样本输入数据。
- 在容器中运行模型。
- 将生成的输出与参考输出进行自动化比对。
- 生成一份详细报告,包括文件差异、分割区域的Dice系数(低于0.99会标记)等。
这意味着什么? 任何用户在任何时间、任何系统上运行该模型,只要通过这个测试,就能确信模型的执行与作者发布时完全一致。这从根本上解决了AI研究中的可复现性危机,建立了技术信任。
这四层架构环环相扣,共同构建了一个坚固的标准化堡垒。那么,用它来实际解决问题,体验如何?我们来看一个精彩的实战案例。
实验验证:一键横向对比三大肺部分割模型
肺部分割是CT影像分析的基础任务。MHub.ai集成了三个知名的开源模型:TotalSegmentator, LungMask, 和 LungLobes。它们各自独立开发,架构和训练数据不同。传统上,比较它们需要巨大的工程开销。现在,利用MHub.ai,这一切变得轻而易举。
标准化执行与公平对比
作者选取了公开的NSCLC-Radiomics数据集中的422例胸部CT扫描,其中303例带有专家手动标注的左右肺分割结果,作为金标准。
关键步骤:
- 数据准备:直接使用原始的DICOM文件,无需任何格式转换。
- 模型执行:对三个模型使用完全相同的命令格式(仅镜像名不同)运行。
- 输出协调:MHub.ai自动将模型输出的肺叶级分割(如左上叶、右下叶)聚合为统一的左右肺Mask,以便与专家标注直接计算Dice相似系数。
数据驱动的深度洞察
所有模型都表现出色(Dice系数均很高),但MHub.ai提供的标准化流水线让研究者能洞察细微差异:
- 模型间细微差异:LungLobes模型在左肺的分割精度显著低于右肺。这可能是因为心脏占位导致左肺解剖结构更复杂。
- 年龄相关趋势:LungMask和TotalSegmentator的分割精度与患者年龄呈轻度负相关(相关系数约 -0.13),提示模型在老年患者群体中可能存在轻微的泛化能力下降。
这些发现虽然微小,但对于模型的选择和临床部署前的验证具有重要指导意义。更重要的是,整个分析过程可以被任何研究者一键复现。
极致透明:交互式仪表盘
论文不仅公布了聚合结果,更将所有422例患者的原始分割结果、计算的Dice系数及临床数据通过一个在线交互式仪表盘完全公开。
这意味着你可以:
- 复现论文中的每一个统计图表。
- 查看任意一个病例的CT图像、三个模型的自动分割结果与专家标注的叠加对比。
- 自己进行新的分层分析(例如,按肿瘤分期分析性能)。
这设定了AI医学影像研究可重复性的新标杆。
🤔 互动时间:你认为这种“模型即容器,比较如饮水”的范式,最可能首先在哪个场景大规模应用?是医院影像科的AI工具评估,还是高校的算法研究课程?
客观评价:优势、局限与未来
核心优势
- 极大降低使用门槛:从“几天配环境”到“一条命令出结果”,激活了大量沉睡的模型资产。
- 实现公平比较:为AI模型的基准测试提供了真正可控、一致的实验环境。
- 提升研究可重复性:自动化测试和完整的数据/代码公开,让研究从“可复现”走向“已复现”。
- 加速临床转化:标准化、DICOM原生支持的输出,使其能无缝集成到临床影像归档和通信系统(PACS)及三维可视化软件(如3D Slicer)中。
当前局限
- 依赖Docker:需要主机安装Docker,在某些受严格IT管控的医院环境中可能受限。但框架本身不绑定Docker,可迁移至Singularity等运行时。
- 贡献者负担:将模型转换为MHub.ai格式需要额外工作。平台通过提供丰富模板和自动化工具来减轻负担。
- 模态覆盖不全:目前对某些特殊模态(如全切片病理图像)的支持有限,但模块化架构允许后续扩展。
- GPU依赖:多数模型推理需要GPU,对部署硬件有要求。
未来展望
MHub.ai是一个活的平台。其开源、模块化的特质,预示着广阔的进化空间:
- 运行时扩展:支持更多容器技术。
- 自动化基准测试:内置性能指标计算,实现端到端评估流水线。
- 社区生态:通过GitHub吸引更多贡献者,扩展模型库和专用工具链(如病理、超声)。
价值升华:不止于工具,更是范式革命
MHub.ai不仅仅是一个好用的工具平台。它更代表了一种思维范式的转变:从关注模型的“峰值性能”,到同等重视模型的“可交付性”和“可比较性”。
它解决了AI模型从实验室到临床的 “最后一公里” 问题,通过标准化这把钥匙,打开了以下三把锁:
- 🔓 效率锁:让研究者宝贵的时间从繁琐的工程中解放出来,回归科学问题本身。
- 🔓 信任锁:通过可复现性测试和完整溯源,为AI模型的可靠应用建立信任基础。
- 🔓 协作锁:为全球医学影像AI社区提供了共同的语言和接口,极大促进了协作与创新。
对于临床医生,它意味着可以像在应用商店挑选App一样,快速试用和评估不同的AI工具。对于研究者,它意味着可以像做化学实验一样,在标准“器皿”中公平地比较不同“配方”的优劣。
这项技术最有可能率先在多中心临床研究和医院影像科AI工具院内评估中落地,因为它直接解决了模型统一部署和公平比较的核心痛点。如果你对这类标准化平台和开源实践感兴趣,可以持续关注我们后续的深度解析。
 发表于 2026-1-27 01:27:58
|
查看: 258|
回复: 0
发表于 2026-1-27 01:27:58
|
查看: 258|
回复: 0
