本文深入剖析大模型工具调用(Function Calling)的底层运作机制,从理论到实战,带你彻底掌握如何让 AI 突破赛博空间的限制,拥有操作真实世界业务系统的能力。
最近 AI 圈最热的莫过于“养小龙虾(OpenClaw)”了,甚至有人为了能用上它,在线下排起了长队。

为什么一个开源项目能引发如此规模的线下活动?
因为大家发现,OpenClaw 并不是又一个只会『陪聊』的窗口,它是一个真正的『数字员工』。
当你对它说“分析一下本地销售数据并把总结发给主管”时,它能自主翻找你电脑里的文件、运行统计脚本、最后登录你的企业飞书发出消息。
这种从动口到动手的质变,源于它将原本封闭的大模型接入了现实世界。而支撑这种跨维度操作的核心技术,正是我们今天要介绍的 Function Calling(工具调用)。
一、为什么需要 Function Calling?
很多人在体验过各种神奇的智能体后,会产生一种技术错觉:以为大语言模型(LLM)真的具备了直接操作电脑、查询数据库或者调用接口的能力。
实际上,从底层逻辑看,LLM 本质上是一个运行在受限计算环境中的『概率预测引擎』 。无论它表现得多么像真人,其核心工作只有一个:根据已有的输入,预测下一个最可能的 Token(即『文字接龙』)。
这种生成式的本质,决定了它在处理真实业务时,存在以下问题:
- 无法访问远程:大模型接龙的依据是训练阶段『背下来』的千亿级参数。它无法主动发起远程请求(如 HTTP、RPC等),对当下真实世界的股价、天气、新闻毫无感知。
- 无法操作本地: 大模型可以接龙出一段完美的 SQL 语句或 Python 自动化脚本,但它本身没有任何执行能力,并不能连接数据库执行查询操作或者运行代码。
那么,谁能解决这些问题呢?答案是我们的程序代码!作为开发者,我们可以很容易地写一段程序去发起 HTTP 请求、执行 SQL 查询。
但传统的程序代码又存在一个致命短板:无法解析用户复杂的自然语言意图。
此时就存在一个核心痛点:
- 应用程序: 拥有完整的执行权限和数据访问能力,但无法解析非结构化的自然语言意图。
- 大模型: 具备极强的意图识别和文本解析能力,但无法发起任何真实世界的执行调用。
聪明的你可能已经想到了,可以将二者结合起来!大模型负责识别用户意图并输出结构化内容,由应用程序解析后发起真实调用。
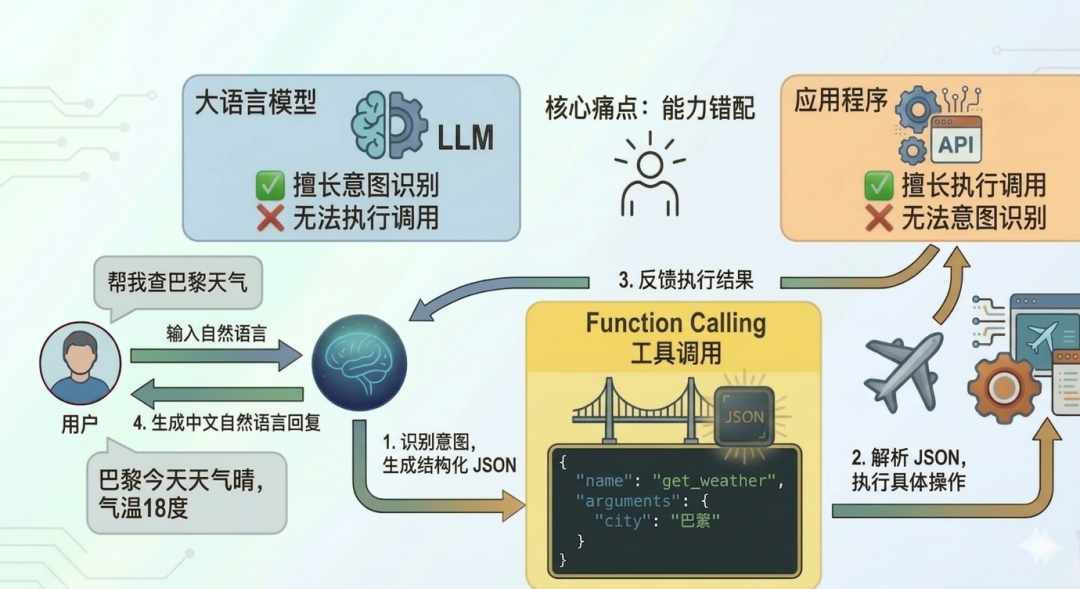
这就诞生了Function Calling(工具调用),它本质上是在『自然语言』与『机器代码』之间,强行建立了一套结构化的通信协议。
当模型发现自己无法直接回答问题(如需查实时数据或执行写操作)时,能够生成一段符合预定义 Schema 的 JSON 指令。
这相当于模型发出了一个显式的调用请求,告诉后端程序:“我需要调用函数 A,参数是 B,请程序执行后将结果反馈给我”。之后由程序去真正调用工具。
需要注意的是,输出这种严谨的结构化指令,并非大模型天生就会的。这需要大模型厂商在预训练和微调阶段,专门针对 Function Calling 能力进行大量的数据训练。只有经过专门训练的模型,才能在遇到能力边界时,准确输出符合规范的 Schema,而不是继续用自然语言“瞎编”。
二、Function Calling 的整体流程?
如果说 Prompt Engineering 是在教大模型『如何思考』,那么 Function Calling 就是在教大模型『如何求助』。
整个交互过程并不是大模型直接去调工具,而是由应用程序作为中间桥梁,完成信息的闭环流转。
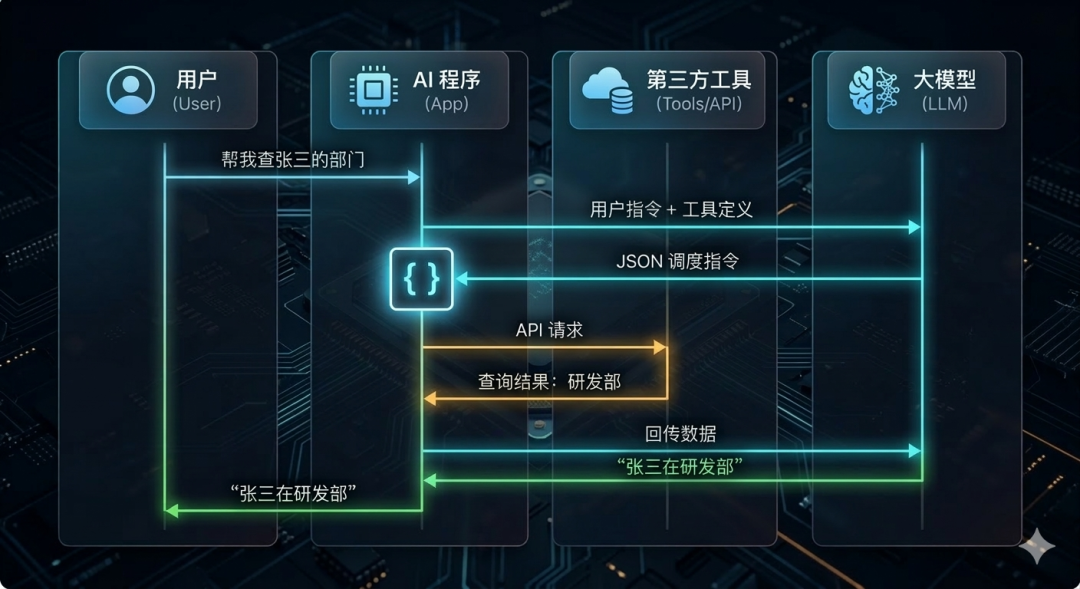
第一步:定义工具
在对话开始前,程序需要定义一份极其详细的『工具说明书』,这通常是一组符合 JSON Schema 规范的描述,包含:
- 函数名称: 唯一标识符。
- 功能描述: 告诉模型在什么场景下该使用此工具。
- 参数规范: 定义函数所需的参数类型、格式及是否必填。
这一步是让为了让大模型建立对工具的基础认知,它不需要知道这些工具怎么实现的,只需要记住这些工具的使用方式。
举个例子,你告诉它:“我这里有两把工具。一把叫 get_weather,可以查询天气,需要传入 city 参数;一把叫 get_department,可以查询“一枫公司”某个员工所在的部门,需要传入 name 参数。”
第二步:意图识别与参数提取
当用户输入请求(如:“帮我查查一枫公司中张三所在的部门”)后,程序将用户指令与工具定义发送给模型。模型会进行内部推理:
- 需求分析: 用户想知道员工所在部门。
- 匹配工具: 我的知识库里没有实时数据,开发者提供的工具说明书里有一个
get_department 可以使用。
- 参数对齐: 用户提到了“张三”,对应工具要求的
name 字段。
此时,大模型会输出一段标准的 JSON 数据块,告诉你的程序:“我申请调用 get_department,参数是 {"name": "张三"}。”
第三步:程序执行
此时模型进入等待状态,后端程序解析返回的 JSON 指令,拿着参数 {"name": "张三"},去真实地查询数据库,得到结果:{"department": "研发部"}。
第四步:结果回传与回复生成
程序将执行结果包装成一条消息(大意是:“刚才那个工具我帮你调完了,结果是:研发部”),再次发送给大模型。
大模型拿到这个补充的事实数据后,结合最初的问题,最终接龙出一句自然回复:“张三所在的部门是研发部!”
最后,由程序将这个自然回复发送并展示给用户。整个 Function Calling 闭环完成。
三、从零手写一个 Function Calling
讲完了理论,下面我们开始上代码实战。假设业务场景:我们想要一个智能助理,当用户问起某个员工的所在部门时,它能自动去公司数据库里查出来并回答。这个场景非常典型,经常出现在企业内部的后端系统集成中。
1. 定义工具
在Python代码里,准备一个真正能查数据库的函数(这里为了演示,使用假数据代替真实的数据库连接):
# 这是真正的业务代码,负责执行动作
def get_department(name):
# 模拟查询数据库
database = {
"张三": "研发部",
"李四": "市场部"
}
return database.get(name, "查无此人")
将上面这个函数的信息,严格按照 JSON Schema 的格式描述出来,稍后连同用户的问题一起发给大模型。
# 工具说明书
tools = [
{
"type": "function",
"function": {
"name": "get_department",
"description": "当用户想要查询某个员工的所在部门时调用此函数。",
"parameters": {
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "员工的姓名,例如:张三、李四"
}
},
"required": ["name"] # 声明必填参数
}
}
}
]
2. 发起对话与解析意图
我们开始第一次调用大模型。
import json
from volcenginesdkarkruntime import Ark
# 示例使用方舟的豆包模型,大家也可以使用其他厂商的模型,代码都差不多
client = Ark(
base_url="https://ark.cn-beijing.volces.com/api/v3",
api_key="你的api key",
)
# 第一次请求大模型,带上 tools 数组
messages = [{"role": "user", "content": "帮我查查一枫公司中张三所在的部门"}]
model = "doubao-seed-1-8-251228"
response = client.chat.completions.create(
model=model,
messages = messages,
tools=tools,
)
# 获取模型的回复
response_message = response.choices[0].message
print("大模型的初步决策:", response_message)
此时,打印出来的 response_message 不会是“我帮你查查”,而是一个结构体!它大概长这样:
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_department",
"arguments": "{\"name\": \"张三\"}"
}
}
],
"reasoning_content": "用户现在需要查询一枫公司中张三的部门,根据提供的工具,应该调用get_department函数,参数是name为张三。首先确认用户的需求是查询员工部门,工具正好对应,参数也明确,所以直接调用这个函数,按照要求的格式来写。"
}
大模型返回的 content 为空,但它在 tool_calls 里明确告诉你:请去调用 get_department,并且参数是 {name": "张三"},它完美地理解了意图并提取了参数!
3. 本地执行与第二次请求大模型
接下来,代码接管执行逻辑,并将结果喂回给模型:
# 检查模型是否要求调用工具
if response_message.tool_calls:
# 必须把模型刚才的“调用意图”追加到对话历史中,否则模型会失忆
messages.append(response_message.model_dump())
for tool_call in response_message.tool_calls:
# 函数名称
function_name = tool_call.function.name
if function_name == "get_department":
# 提取参数
function_args = json.loads(tool_call.function.arguments)
name = function_args.get("name")
# 核心:由你的本地代码,真正执行业务函数
print(f"执行本地代码:查询{function_args.get('name')}的所在部门")
function_response = get_department(name)
# 将执行结果打包成特定格式,角色(role)必须是 "tool"
messages.append({
"tool_call_id": tool_call.id,
"role": "tool",
"content": function_response
})
# 带着工具返回的结果,发起第二次请求
second_response = client.chat.completions.create(
model=model,
messages=messages
)
print("大模型的最终回复:", second_response.choices[0].message.content)
运行结果打印:
- 执行本地代码:查询张三的所在部门
- 大模型的最终回复: 张三所在的部门是研发部。
基于以上代码,我们便实现了一次完整的 Function Calling 操作。
四、总结
Function Calling 完美地解决了大模型长期面临的两大核心瓶颈:
- 打破信息孤岛:通过工具调用,大模型得以访问实时数据,不再局限于训练时的静态知识。
- 获得执行能力:将自然语言意图转化为可执行的操作,实现了从“能说会道”到“能干实事”的跨越。
这使得大模型从一个封闭的文本生成器,进化成为能够与真实世界互动的智能体。无论是查询实时信息、操作数据库、调用第三方 API,还是执行本地脚本,都成为了可能。
如果说提示词工程、RAG等技术让大模型变得更聪明,那么 Function Calling 则是赋予其“手脚”的关键。它标志着我们向构建实用、可落地的AI应用迈出了坚实一步,是整个人工智能工程化拼图中不可或缺的一块。
从理解原理到动手编码,Function Calling 的门槛并没有想象中那么高。希望这篇实战指南能帮你快速上手,将这一强大的能力应用到你的项目中。如果你想了解更多关于AI工程化的前沿实践和深度讨论,欢迎来 云栈社区 和我们一起交流。
 发表于 2026-3-15 06:24:32
|
查看: 113|
回复: 0
发表于 2026-3-15 06:24:32
|
查看: 113|
回复: 0
