有时候,我们真的会过于乐观——以为在 Prompt 里写好了“不许乱编参数”,模型就会乖乖照做。实测几个例子没出问题,一上线就崩的例子太多了。比如一个查询天气的任务,输入只有 city 和 date。我们精心设计了一段系统提示:
你只能调用 get_weather,参数 city 必须是标准城市名,date 必须是今天或明天。不可以自己编城市和日期。
然后用户来了一句:“北京后天天气怎么样?”
模型的常见瞎编行为马上暴露出来:
- 直接不调工具,张口就来:“北京后天晴,15~25℃”
- 调用了,但传参
date="后天"(工具根本不支持)
- 或者自作聪明把“后天”转成
2026-04-29,即便工具没要求任何日期转换
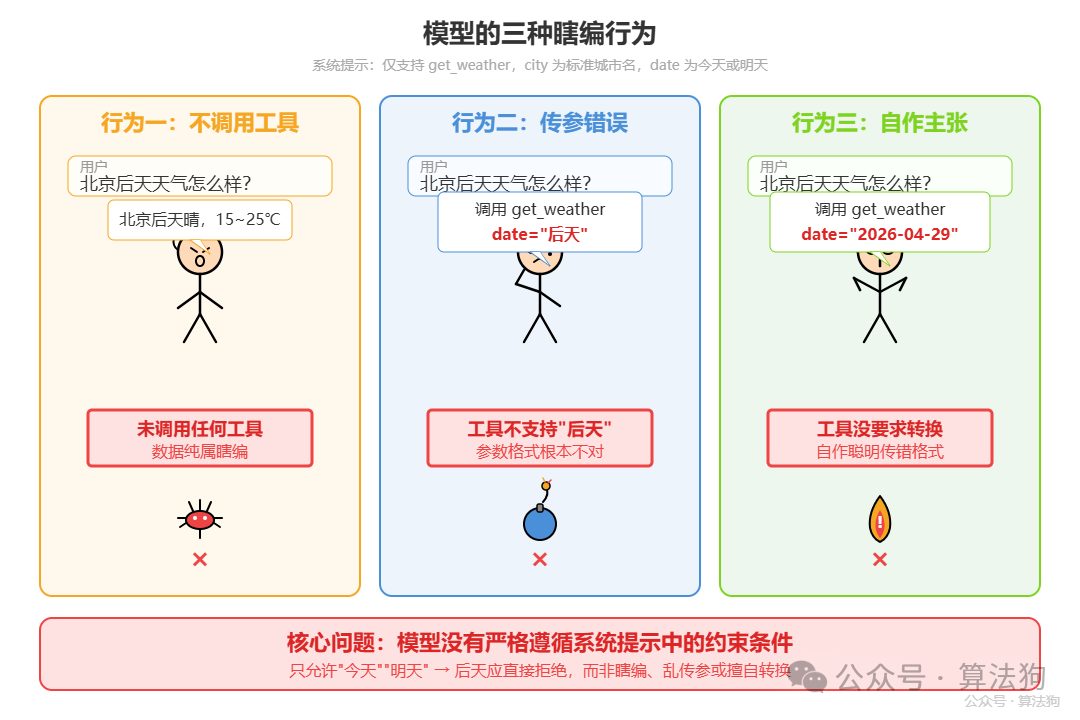
问题的根源往往不是模型不够聪明,而是我们对于“模型会完全照章办事”这件事过于自信了。
一个普遍的误解:好好说话就够了
很多人遇到类似问题,第一反应就是改提示词——包括我自己在内。写上一句“你是一个专业的工具调用助手,不要编造参数”,听起来很合理,在简单场景里也确实能顶一阵。但这背后藏着一个根本性的认知错位:大语言模型的输出本质是概率采样,它并没有“遵守规则”的强制机制。提示词只是在概率分布上推了一把,而不是上了锁。
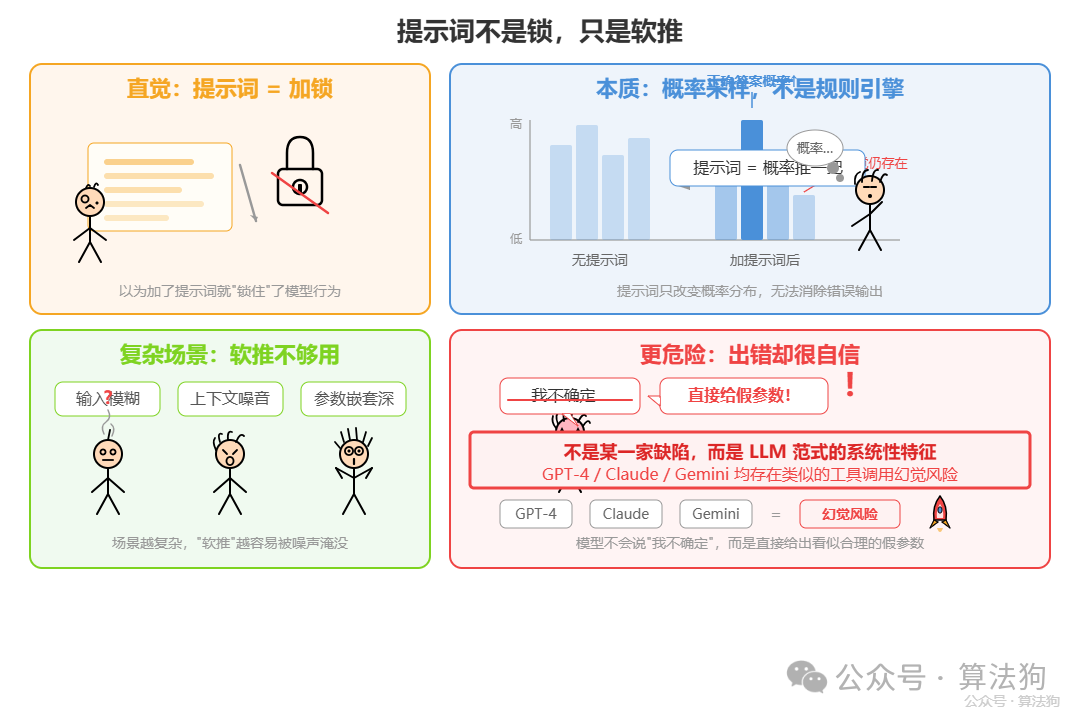
在复杂场景下——用户输入模糊、上下文噪声大、工具参数嵌套深——这把“软推”根本不够用。更危险的是,模型出错时往往表现得极度自信:它不会说“我不确定”,而是直接给出一个看起来合情合理的假参数。这并不是某一家模型的缺陷,而是当前 LLM 范式的系统性特征。GPT-4、Claude、Gemini 在工具调用上都面临类似的幻觉风险,只是程度和触发条件不同。
批判“提示词万能论”之后,我们该怎么做
承认软约束的局限,并不等于否定提示词优化的价值。恰恰相反——它应该是整个约束体系的第一层,但绝不能是唯一层。
优化过的提示词应当像一份操作合同:不仅说明工具“用来干什么”,还要清楚标注每个参数的类型、边界、非法值的例子。比如,与其写“city 参数是城市名称”,不如写“city 必须是标准英文城市名,如 'Beijing',禁止传入自然语言短语如 '我所在的城市' 或空字符串”。
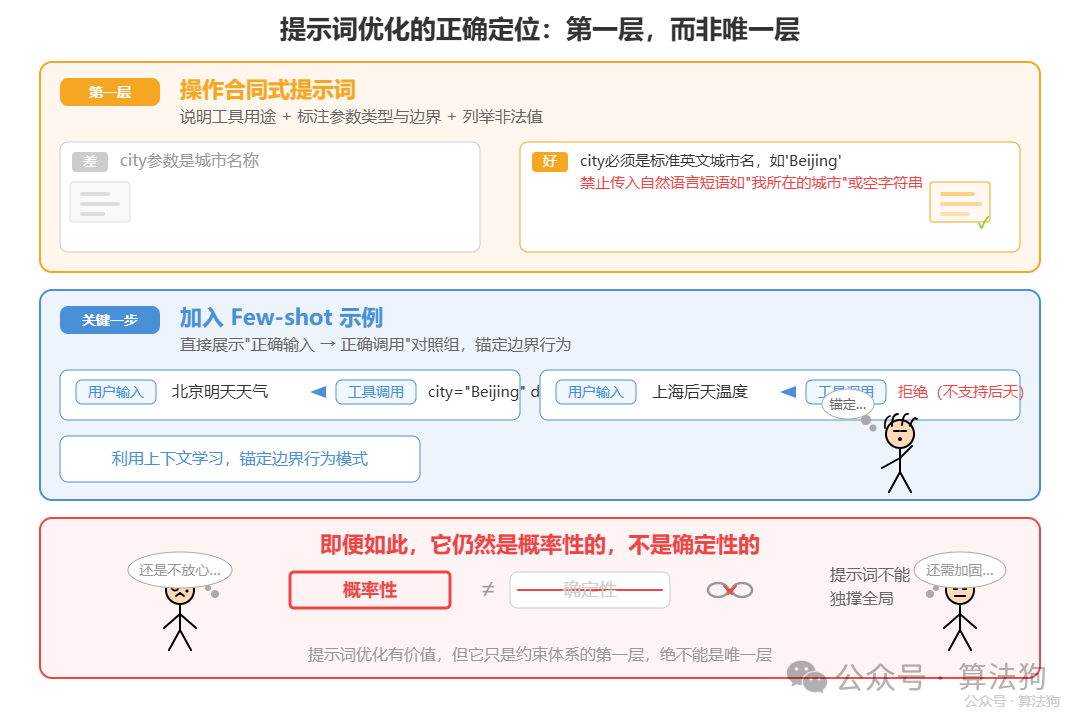
更关键的一步是加入 Few-shot 示例——直接给模型看几组“正确的用户输入 → 正确的工具调用”对照。这利用了模型的上下文学习能力,能够在边界模糊时锚定正确的行为模式。但即便如此,它仍然是概率性的,不是确定性的。
硬约束:从“讲道理”到“设栏杆”
要从根本上防止模型输出格式混乱,就必须引入机器可读的结构化约束。目前最主流的方式是 JSON Schema。
JSON Schema 的思路是:不再用自然语言描述参数,而是用机器能验证的结构来定义。例如,一个天气查询工具的 Schema 可以这样约束:city 字段类型为字符串且必填,unit 字段只允许枚举值 "celsius" 或 "fahrenheit",同时声明 additionalProperties: false——任何不在 Schema 里定义的字段都会被直接拒绝。

这最后一条additionalProperties: false至关重要。没有它,模型完全可能在输出里附带一个它“觉得有用”的额外字段,比如 "note": "用户没说清楚,我猜是摄氏度",下游系统很可能根本处理不了这种东西。
目前主流模型平台——OpenAI、Anthropic、Google——都支持在 API 层面直接传入 JSON Schema,某些平台甚至在模型解码阶段就做格式约束(即“结构化输出”或“Constrained Decoding”),从生成源头就杜绝格式违规。这才是真正的硬约束,是脱离了“祈祷模型听话”范式的工程化手段。
兜底不是保险丝,而是设计要求
即便有了 JSON Schema,依然存在极端情况:模型输出了语法合规但语义荒谬的参数,或者 Schema 验证时因为上游处理问题导致格式被破坏。
成熟的生产系统需要一个“校验‑修复‑重试”闭环。具体来说:拿到模型输出后先做语法校验,再做 Schema 验证;如果失败,可以尝试一轮自动清洗(比如去除多余的 Markdown 标记、修复非法的引号格式);如果清洗后仍不合规,则把原始输出和错误信息打包,作为新的上下文再次请求模型,并在新提示中明确指出上一次哪里出了问题。
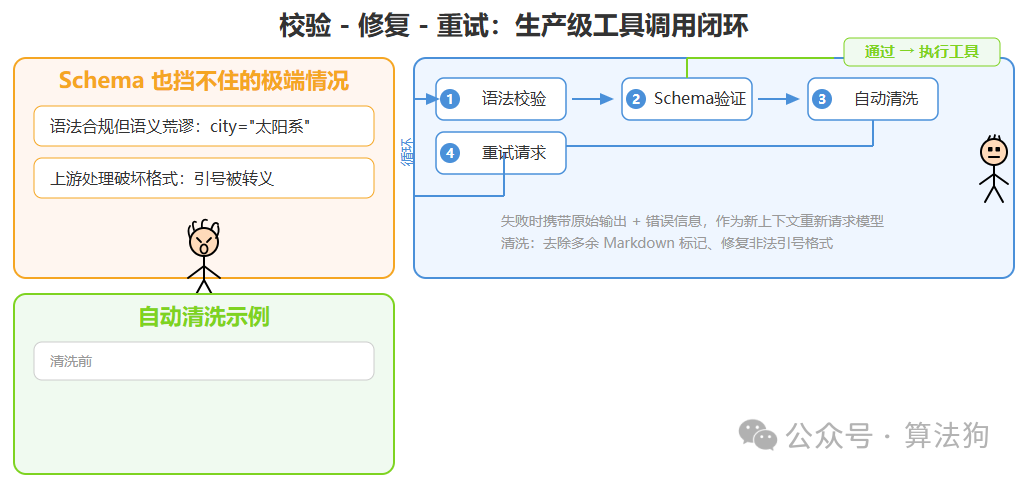
这个机制可以处理绝大多数极端情况,但有一个前提:重试次数必须有上限。超过阈值后应当走降级或人工兜底,否则一个死循环的重试链造成的破坏会比原始错误更大。
架构层面:让模型只做它该做的事
把前面三层措施——优化软约束、硬约束 Schema、校验修复闭环——放在一起,才构成一套可以落地的组合。但要让这套组合真正稳健,还需要一个架构层面的清醒认识:LLM 只应当承担“决策”职能,而不应当承担“执行”职能。
这个区分在架构上体现为三层分离:
- 模型层作为决策大脑,接收用户意图,判断调用哪个工具、生成哪些参数。
- 框架层作为执行骨架,负责接收模型决策、执行 Schema 校验、调用实际工具、处理重试逻辑,以及最终整合结果。
- 工具层则是各个具体的业务能力实现,与模型完全解耦。
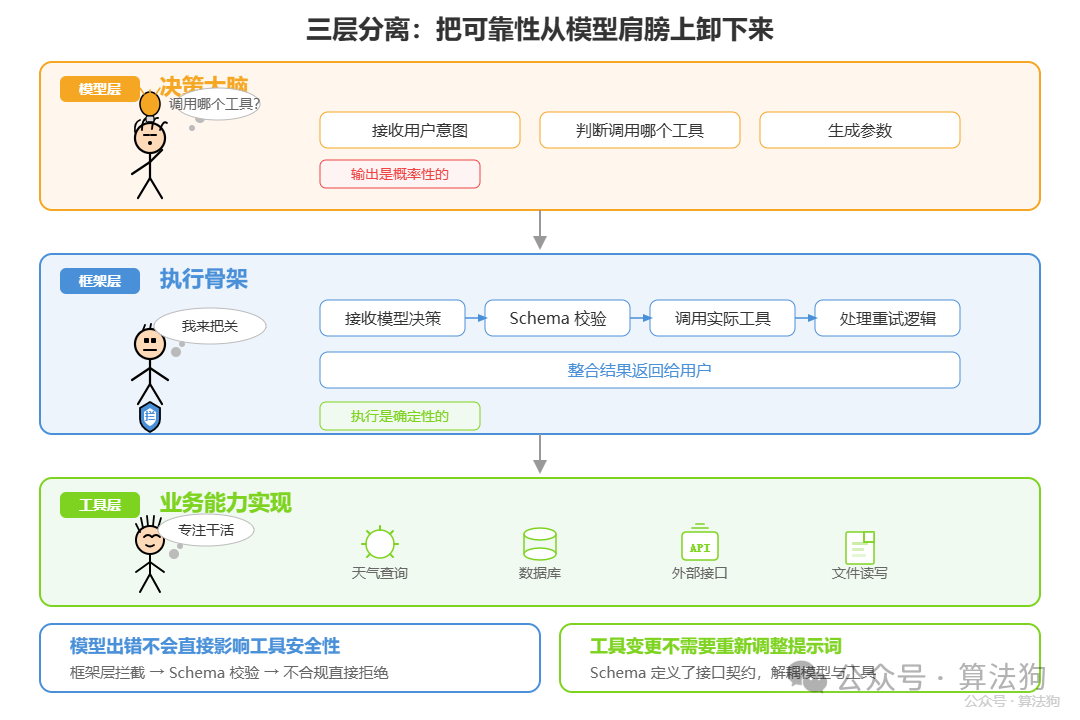
这种设计的好处在于:模型出错时不会直接影响工具调用的安全性,因为中间有框架层的拦截;工具逻辑的变更也不需要重新调整模型的提示词,因为 Schema 定义了它们之间的接口契约。
LangChain、LlamaIndex、AutoGen 等主流 AI 应用框架,本质上都在做这件事——把执行层的可靠性责任从模型肩膀上卸下来,交给成熟的软件工程实践。
一个还没被充分重视的问题
值得补充的是,以上所有方案在处理“参数格式”问题时效果良好,但对于“参数语义”问题的覆盖仍然有限。Schema 可以告诉模型 city 必须是字符串,却无法告诉它“上海”和“沪”在业务上等价。工具调用可靠性的下一个前沿,或许是语义层面的验证——比如用实体链接、知识图谱补全或领域特定的参数规范化模块来处理这类问题。这不是 2026 年的标配,但可能是 2027 年必须面对的工程挑战。
控制模型调用工具的问题,从来不是一个“优化提示词”的问题,而是一个软件工程问题。认清这一点,才算真正迈过了 LLM 应用开发的第一道门槛。
 发表于 2026-4-29 01:47:35
|
查看: 194|
回复: 0
发表于 2026-4-29 01:47:35
|
查看: 194|
回复: 0
