在上一节中,我们探讨了访存时间一致性问题,其根源在于多核或多线程之间缺乏有效的互信机制。那么,硬件层面提供了哪些功能来辅助实现线程或核心之间的互信呢?
互斥访问
一种直观的思路是:共享资源被访问时,先到先得,申请到权限后其他人就无法访问,这就是最基本的锁定机制。
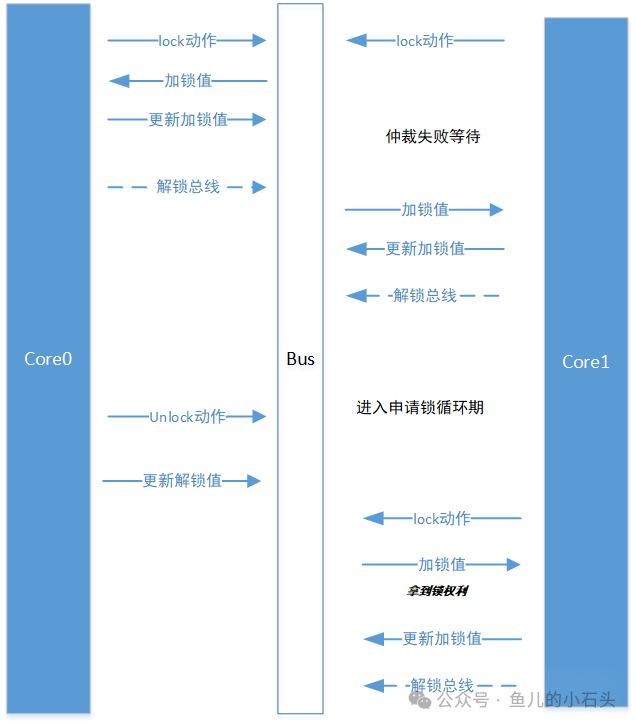
例如,通过一个带有 lock 属性或目的的操作指令 A 来申请总线。之后,总线将独占服务于 A,其他操作必须等待。A 完成操作后释放总线,总线才能处理其他访问。当多个操作同时竞争总线时,由总线仲裁器决定权限归属。
但这种做法会极大浪费总线带宽,即使是不访问共享区域的操作也无法被处理,显然不够高效。因此,经过优化,现代加锁机制变得更加精细,通常采用地址和长度范围结合的方式对特定区域加锁,从而释放总线资源。
有了加锁概念后,多个程序对共享变量的操作就可以用锁来控制。
以下图示说明了这一过程:
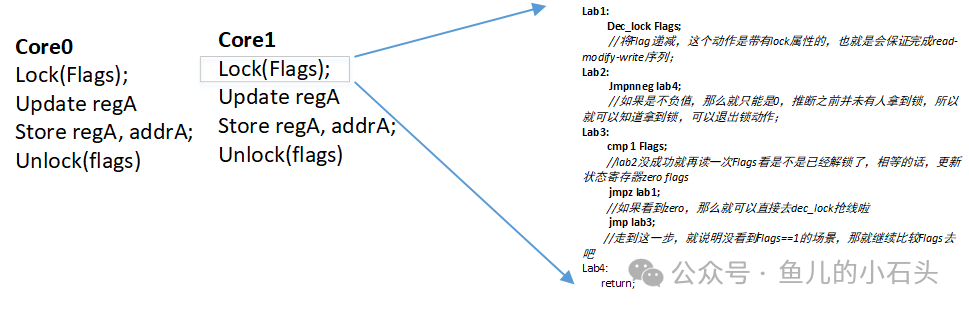
Core0 和 Core1 会共享部分资源,我们使用 flags 作为标记来检查哪个核心获得了资源的控制权。
- 当 Flags == 1 时,表示未上锁,两个核心都可以访问资源。
- 当 flags 为 0 或负值时,表示已上锁,只有当前持有锁的核心可以操作。
下面给出对应的伪代码。这里的 Lock() 程序在抢不到锁时会循环检测锁变量,等待机会抢锁,这种行为被称为自旋锁(spinlock)。
当多个访问者竞争资源,但只有一人能获得修改权限时,这种锁称为互斥锁。
持有锁的线程在解锁前执行的操作称为临界区。临界区内的操作无需额外加锁。
看起来我们完美解决了不同线程对同一资源访问的顺序控制问题,至少避免了冲突。但这样真的没问题了吗?
我们之前提到系统中不存在零延迟传输。假设 Core0 获得锁、修改共享变量、解锁后,Core1 获得锁,但由于某些原因(如缓存延迟),Core1 可能尚未看到最新值,从而使用旧值进行操作,导致程序结果仍然错误。
也就是说,加锁只能确保共享变量被单线程修改,但无法保证修改后的数据能被正确读取。
为了解决这个问题,我们还需要另一个机制:访存屏障。
访存屏障
我们引入一类指令,要求所有特定操作或所有操作在遇到它们时必须排队,确保前面的操作全部完成。这种能让核心执行到对应操作时暂停、等待之前操作完成的指令,称为访存屏障(memory barrier)。
X86 架构提供了以下指令:
- Mfence(memory Fence):无论读写,位于 mfence 之前的所有访存指令必须全部执行并同步完成后,才执行之后的访存指令。
- Lfence(load fence):仅针对加载指令排序。
- Sfence(Store fence):仅针对存储指令排序。
ARM 架构也提供了类似指令:
- DMB(data memory barrier):行为与 Mfence 类似。
- DSB(Data synchronous barrier):行为与 DMB 类似,但时序屏障要求更严格。
- ISB(Instruction synchronous barrier):仅当 ISB 之前的所有指令都执行且同步完成后,才操作后续指令,属于最严格的时序屏障。
此外,还有一些隐式的屏障指令,在指令行为中暗含了屏障动作,例如 X86 的 cpuid、msr 操作等。
这些是程序层面提供的手段,后续我们将探讨硬件层面的更多支持。对于更深入的计算机体系结构知识,可以参考云栈社区的相关讨论。 |  发表于 2026-1-27 06:54:02
|
查看: 168|
回复: 0
发表于 2026-1-27 06:54:02
|
查看: 168|
回复: 0
