拓扑及配置
我们先从一个简单的网络拓扑开始。图中展示了一个常见的家庭或小型办公网络场景:一台PC(PC1)位于局域网(LAN)内,通过一个路由器访问广域网(WAN)上的服务器(Server1)。
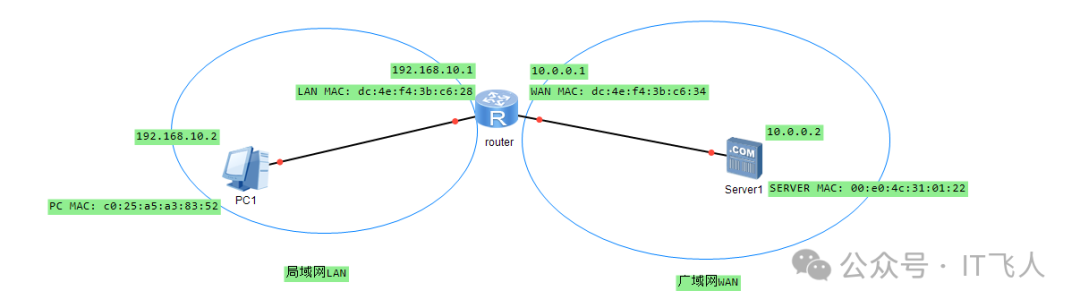
图中清晰标注了各设备的IP地址和MAC地址:
- PC1:
- IP:
192.168.10.2
- MAC:
c0:25:a5:a3:83:52
- 路由器:
- LAN口 IP:
192.168.10.1, MAC: dc:4e:f4:3b:c6:28
- WAN口 IP:
10.0.0.1, MAC: dc:4e:f4:3b:c6:34
- Server1:
- IP:
10.0.0.2
- MAC:
00:e0:4c:31:01:22
这个场景是理解后续封包逻辑的基础。
分析流程
现在我们来思考一个核心问题:当PC1去ping外网的Server1时,数据包在传输过程中,其二层(L2,MAC地址)和三层(L3,IP地址)地址会如何变化?
组包结果
根据网络协议栈的原理,我们可以推导出数据包在发送和接收过程中的封装结构。
PC发送封包
当PC1发起对10.0.0.2的ping请求时,它知道目标不在本地网络,因此会将数据包发给默认网关192.168.10.1。
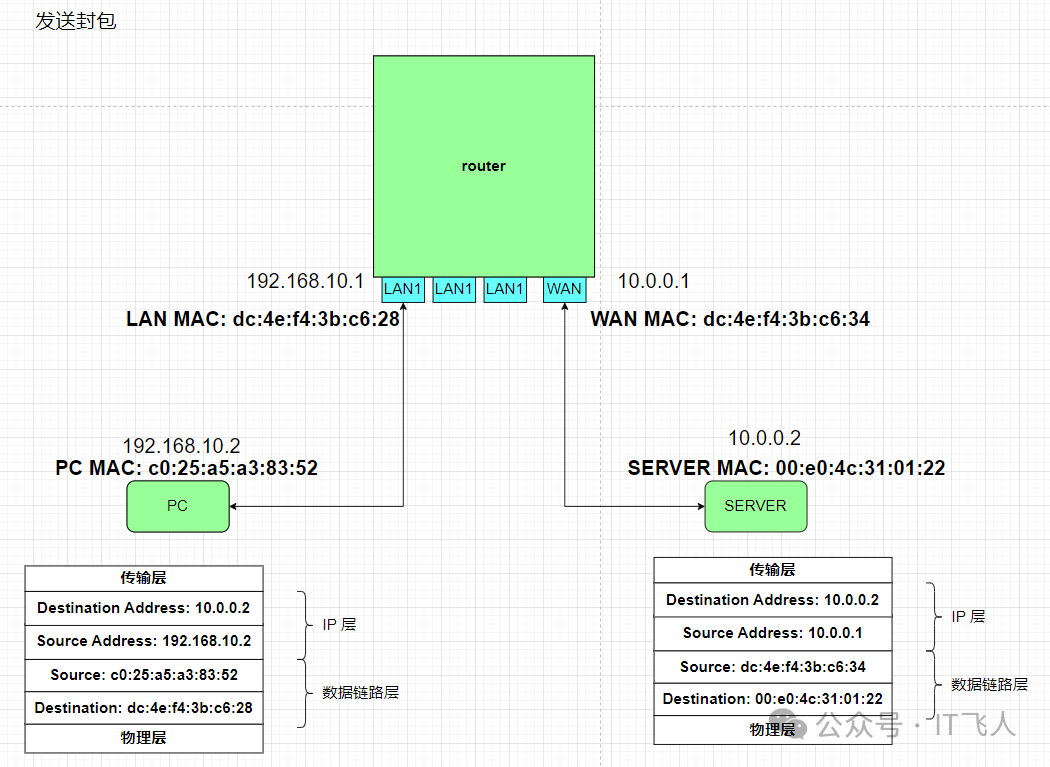
如图所示,在离开PC1网卡时,数据包的各层信息为:
- L3 (IP层): 源IP=
192.168.10.2, 目的IP=10.0.0.2
- L2 (数据链路层): 源MAC=
c0:25:a5:a3:83:52 (PC1自身MAC),目的MAC=dc:4e:f4:3b:c6:28 (路由器LAN口MAC)
PC接收封包
当Server1回复的ping响应包最终到达PC1时,封装信息又发生了变化。
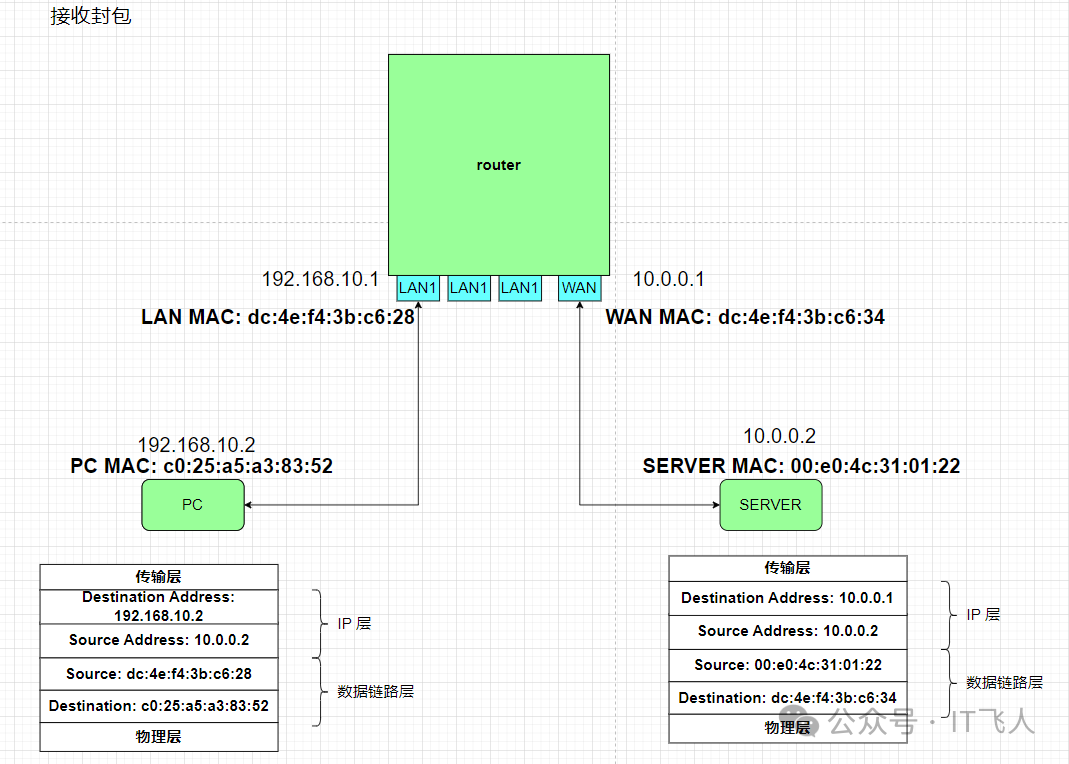
此时,数据包的各层信息为:
- L3 (IP层): 源IP=
10.0.0.2, 目的IP=192.168.10.2
- L2 (数据链路层): 源MAC=
dc:4e:f4:3b:c6:28 (路由器LAN口MAC),目的MAC=c0:25:a5:a3:83:52 (PC1自身MAC)
抓包验证
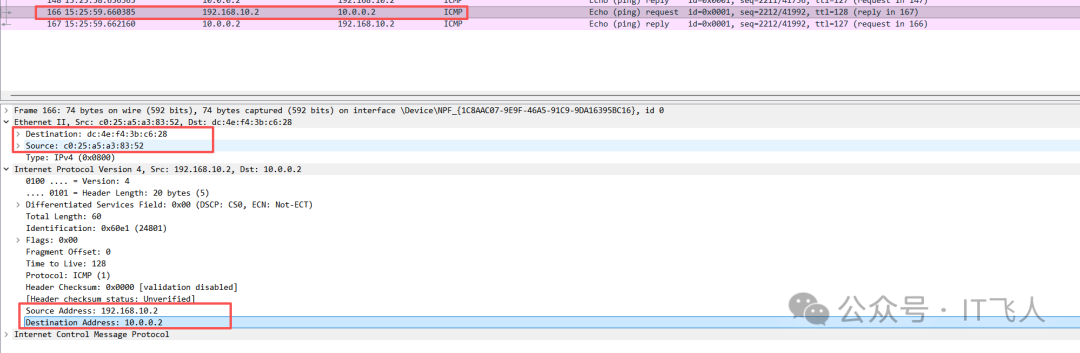
理论推导需要实际验证。我们分别在PC1和Server1上进行抓包,看看真实的数据包是否匹配我们的分析。
-
PC1 发送ping包
在PC1上抓包,可以看到它发出的ICMP请求包。L2目的地址是路由器的MAC,L3目的地址是Server1的IP。
-
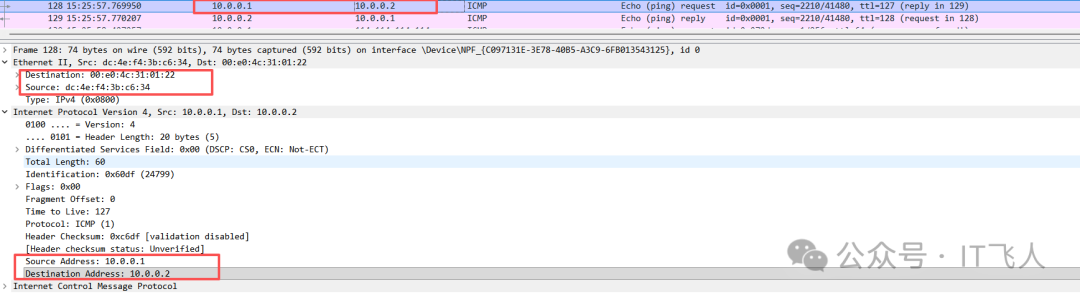
SERVER端接收包
在Server1上抓包,它收到的ICMP请求包L2源地址是路由器WAN口的MAC (dc:4e:f4:3b:c6:34),L3源地址是路由器WAN口的IP (10.0.0.1)。这里发生了网络地址转换(NAT)。
-
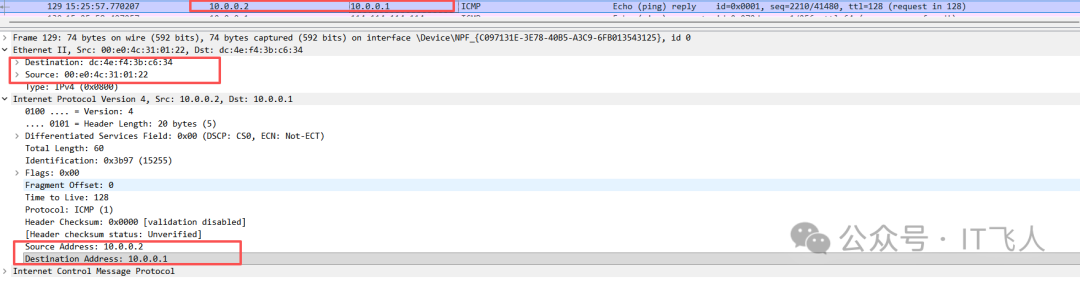
SERVER reply 包
Server1回复的ICMP响应包,L2目的地址是路由器WAN口MAC,L3目的地址是路由器WAN口IP。
-
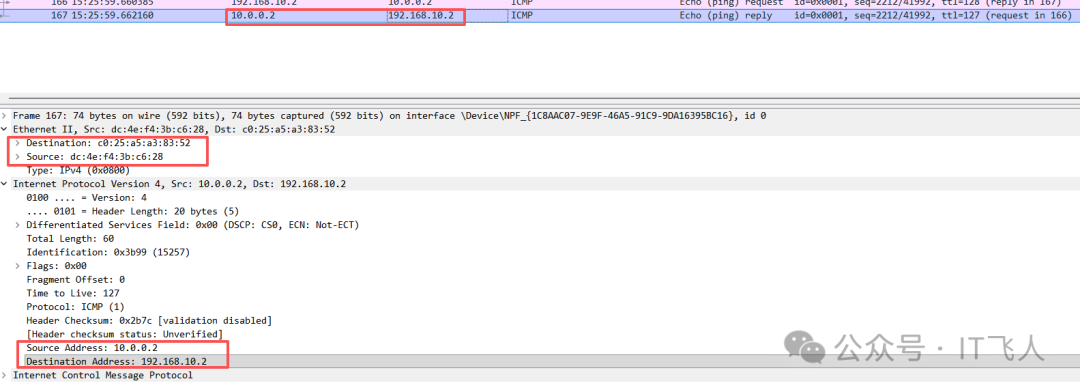
PC接收reply包
PC1最终收到的ICMP响应包,L2源地址是路由器LAN口MAC,L3源地址是Server1的IP (10.0.0.2)。
抓包结果完美验证了我们的理论分析。
封包逻辑的核心依据
上面的过程看似复杂,但遵循两个非常清晰的核心规则:
-
IP地址是端到端的
- 源IP:在通信全程中,代表数据发起者。从PC1发出时是
192.168.10.2,经过路由器NAT后变成公网IP 10.0.0.1,但对于Server1和PC1来说,它们看到的源IP分别是10.0.0.1和10.0.0.2,这是一个“端到端”的视角。
- 目的IP:在发送过程中,最终目标地址
10.0.0.2始终不变(接收过程同理,目的IP 192.168.10.2不变)。
-
MAC地址是逐跳的
- 每经过一个网络设备(如路由器),源和目的MAC地址都会被完全重写。过程是:拆开外层MAC头部 → 查询路由表确定下一跳 → 用新的MAC地址重新封装 → 转发。因此,MAC地址只在相邻设备间有效。
流程梳理
结合规则,从PC1 ping Server1的完整逻辑流程可以梳理如下:
ping命令触发。如果目标是域名,先触发DNS解析获得IP地址。- 主机判断目标IP地址是否属于本机子网。如果不属于,则查询路由表,确定下一跳的IP地址(这里是默认网关
192.168.10.1)。
- 查询ARP缓存,确定下一跳IP对应的MAC地址(即网关
192.168.10.1的MAC)。如果缓存中没有,则广播ARP请求。
- 将获取到的目的MAC地址填入L2帧头。
- 通过网络接口将数据帧发送出去。
深入内核代码
上面的步骤3和4,即“IP地址到MAC地址的转换与封装”,在Linux内核中主要由邻居子系统和ip_finish_output2函数完成。我们忽略复杂的路由选择过程,聚焦于IP层到链路层转换的关键路径。
下图简化展示了内核网络协议栈中,数据包从IP层到网卡驱动的关键函数调用关系,其中ip_finish_output2是通往链路层的门户。
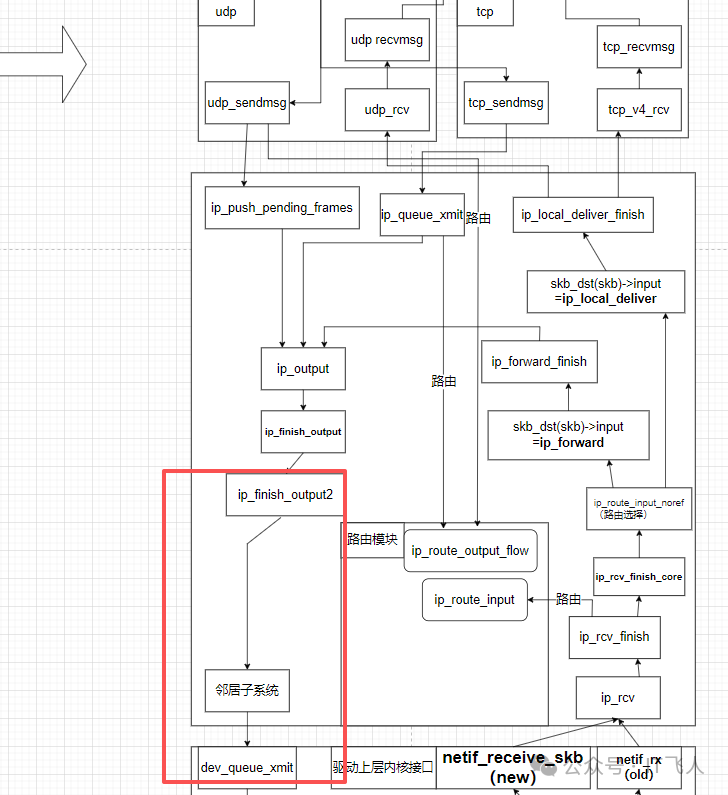
1. IP层到链路层的桥梁:ip_finish_output2
这个函数是L3到L2转换的核心,负责获取下一跳的MAC地址并通过邻居子系统发送数据包。
// ip_output.c (linux-5.10.x/net/ipv4)
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
struct neighbour *neigh;
bool is_v6gw = false;
// ... 省略统计和SKB头部空间检查代码 ...
// 关键步骤:获取下一跳的邻居信息(包含MAC地址)
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh)) {
// 发送数据,成功后更新邻居确认时间
int res = neigh_output(neigh, skb, is_v6gw);
// ...
return res;
}
// ... 错误处理 ...
}
2. 确定查找邻居的目标IP
函数ip_neigh_for_gw决定了该用哪个IP地址去查找或创建邻居表项。逻辑很简单:如果有网关,就用网关IP;如果是直连路由,就用目的IP本身。
static inline struct neighbour *ip_neigh_for_gw(struct rtable *rt, struct sk_buff *skb, bool *is_v6gw)
{
struct net_device *dev = rt->dst.dev;
struct neighbour *neigh;
if (likely(rt->rt_gw_family == AF_INET)) {
// 情况1:有IPv4网关,使用网关地址查找(本例中为192.168.10.1)
neigh = ip_neigh_gw4(dev, rt->rt_gw4);
} else if (rt->rt_gw_family == AF_INET6) {
// 情况2:有IPv6网关
neigh = ip_neigh_gw6(dev, rt->rt_gw6);
*is_v6gw = true;
} else {
// 情况3:直连路由,无网关,使用数据包目的IP查找
neigh = ip_neigh_gw4(dev, ip_hdr(skb)->daddr);
}
return neigh;
}
其中,rt_gw4等字段存储在路由表项rtable结构中:
// route.h
struct rtable {
// ...
__u16 rt_type; // 路由类型(单播、多播等)
u8 rt_gw_family; // 网关地址族
__be32 rt_gw4; // IPv4网关地址
struct in6_addr rt_gw6; // IPv6网关地址
// ...
};
3. 查询ARP缓存表
ip_neigh_gw4函数会首先尝试从ARP缓存中快速查找。
static inline struct neighbour *ip_neigh_gw4(struct net_device *dev, __be32 daddr)
{
// 尝试从ARP缓存查找
struct neighbour *neigh = ipv4_neigh_lookup_noref(dev, daddr);
if (unlikely(!neigh))
// 如果缓存没有,创建新的邻居项并触发ARP请求
neigh = __neigh_create(&arp_tbl, &daddr, dev, false);
return neigh;
}
ipv4_neigh_lookup_noref最终会调用__neigh_lookup_noref,在ARP哈希表中进行查找。其核心逻辑是计算哈希值,然后在对应的哈希桶中遍历链表,比对设备和IP地址。
// neighbour.c
static inline struct neighbour *__neigh_lookup_noref(
struct neigh_table *tbl, // 对于IPv4是 arp_tbl
bool (*key_eq)(const struct neighbour *n, const void *pkey),
__u32 (*hash)(const void *pkey, const struct net_device *dev, u32 hash_rnd),
const void *pkey, // 要查找的IP地址
const struct net_device *dev)
{
struct neigh_hash_table *nht = rcu_dereference_bh(tbl->nht);
struct neighbour *n;
u32 hash_val;
// 1. 计算哈希值
hash_val = hash(pkey, dev, nht->hash_rnd) >> (32 - nht->hash_shift);
// 2. 遍历哈希桶链表
for (n = rcu_dereference_bh(nht->hash_buckets[hash_val]); n != NULL;
n = rcu_dereference_bh(n->next)) {
// 3. 匹配设备和IP地址
if (n->dev == dev && key_eq(n, pkey))
return n; // 找到邻居信息
}
return NULL;
}
其中,用于比较IP地址的关键函数是neigh_key_eq32:
static inline bool neigh_key_eq32(const struct neighbour *n, const void *pkey)
{
// 比较邻居结构体中存储的IP(n->primary_key)和要查找的IP(pkey)
return *(const u32 *)n->primary_key == *(const u32 *)pkey;
}
哈希函数arp_hashfn则结合了IP地址和网络设备来生成哈希值:
static inline u32 arp_hashfn(const void *pkey, const struct net_device *dev, u32 hash_rnd)
{
u32 key = *(const u32 *)pkey;
u32 val = key * hash32_ptr(dev);
return val * hash_rnd[0];
}
如果缓存查找失败(unlikely(!neigh)),内核会调用__neigh_create创建一个新的邻居项,并触发ARP请求过程,这属于另一个复杂的分支,本文不再展开。
什么是邻居子系统?
通过上面的代码分析,我们可以给邻居子系统一个明确的定义:它是Linux内核网络协议栈中的一个核心组件,负责管理同一广播域内相邻网络节点之间的地址映射关系(主要是L3到L2的映射)。其核心功能就是将IP地址解析为对应的MAC地址,并维护这些映射关系的缓存(即ARP表),从而高效地完成数据包在链路层的封装。
这个过程是网络通信中不可或缺的一环,理解它有助于我们更深层次地调试网络问题,并洞悉数据包在内核中的旅程。欢迎在云栈社区继续探讨更多内核网络细节。
 发表于 2026-1-27 08:22:18
|
查看: 196|
回复: 0
发表于 2026-1-27 08:22:18
|
查看: 196|
回复: 0
