AI 对内存带宽的极度依赖正在从根本上重构存储行业的定价与供应逻辑。这种由技术瓶颈驱动的成本传导效应,已经深度波及全球消费电子市场,直接影响着各类终端产品的利润结构与配置策略。
1. 核心驱动力:从“摩尔定律”到“内存墙”
- 范式转型:AI时代遵循的是“规模定律”(Scaling Law)。这意味着,提升系统性能的焦点,已经从单纯追求晶体管密度的提升,转向了优化整个系统的数据吞吐能力。
- 性能瓶颈:当前,计算芯片的算力增长速度(约每2年增长3倍)显著领先于内存带宽的增长(约每2年增长1.6倍)。运用 Roofline模型 进行分析会发现,由于算力的持续扩张,越来越多的 AI工作负载 正加速滑入“内存受限区”。
- 技术对策:HBM(高带宽内存)通过TSV(硅通孔)垂直堆叠与超宽接口技术,大幅缩短了数据在处理器与内存之间的物理传输路径,成为了突破“内存墙”这一核心瓶颈的关键技术路径。
2. 市场联动:训练与推理的双向需求拉动
- HBM的战略地位:在 AI模型训练 以及推理的Decode阶段(需要高频访问KV Cache),HBM不仅是性能核心,更是刚性成本项。预计2025年,市场对HBM的需求同比增速将超过130%。
- DDR5的配置升级:在推理的Prefill阶段,DDR5凭借其出色的成本效益成为了主流配置。随着云服务商加速部署AI基础设施,预计到2026年底,HBM与DDR5之间的价格差距将显著收窄,这实际上反映了高端DRAM价格的整体上移趋势。
3. 供应结构:产能向高性能产品倾斜
- 产能配置转向:为了应对HBM及高端服务器DRAM(如DDR5)的旺盛需求,存储巨头(三星、SK海力士、美光)持续将最先进的工艺产能向这类高毛利产品倾斜。
- 结构性短缺:这种产能置换的“挤出效应”直接导致了标准消费级DRAM的供应规模被压缩。由于晶圆厂总产能的扩张周期较长,整个存储市场已进入一个由供应侧主导的“卖方市场”。
4. 终端影响:消费电子的成本压力与配置回调
- BOM成本上升:存储组件在智能手机、PC、游戏主机等产品的物料成本(BOM)中的占比大幅提升。例如,新一代游戏主机的存储成本占比已从传统的15%左右飙升至23%-42%。
- 规格演进放缓:迫于成本压力,消费级设备出现了明显的“减配”趋势:
- 智能手机:中低端机型面临严峻的毛利挑战,部分型号的内存配置可能被迫回调至4GB。
- PC/笔记本:虽然头部品牌具备一定的成本转嫁能力,但中低端产品因无法有效消化上涨的成本,其出货量正面临下行风险。
5. 周期研判:长期趋势与价格展望
- 周期特征:本轮“超级周期”主要由“突破硬件带宽瓶颈”这一底层技术需求所驱动,其影响的广度和持续性均超过了2016-2018年的上一轮周期。
- 走势预测:预计2026年全行业DRAM的均价涨幅将超过70%。由于有效产能增量有限,此轮价格上涨周期预计将贯穿整个2026年,市场定价权目前高度集中于上游供应侧手中。
AI引发的“内存墙”问题,正在驱动HBM与DDR5需求激增,并在2025年第三季度彻底点燃了存储市场的超级周期。产能的全面短缺迫使终端设备制造商不得不通过涨价或削减规格来应对。那么,这一轮由技术瓶颈驱动的周期,究竟会在何时迎来转折点?
在过去几十年里,半导体行业一直将摩尔定律奉为圭臬,通过不断提高晶体管密度来提升芯片性能、降低单位计算成本。而随着行业全面进入AI时代,“规模定律”(Scaling law)成为了新的北极星。开发者们试图通过扩展AI模型规模、训练数据量和计算资源,来实现模型性能的可预测提升。因此,整个行业的焦点,已从单个芯片的峰值算力,转向了整体系统级的性能表现。
在这种背景下,内存带宽和数据传输效率的限制就变得前所未有的突出。近年来,HBM的战略重要性急剧上升。同时,随着AI工作负载的重心逐渐从训练转向推理,云服务商正在加速投资AI基础设施和服务器部署,这进一步加大了对服务器级DRAM(如DDR5)的需求。
因此,三大DRAM制造商持续将先进工艺产能分配给高端服务器DRAM和HBM,这直接限制了消费级DRAM的供应,从而引爆了新一轮内存价格的超级周期,并将其影响力扩展至整个消费电子市场。
AI计算趋势正面临“内存墙”挑战
当前主流的大语言模型(LLM)基于 Transformer架构 进行深度学习,其计算性能高度依赖于内存访问。在训练过程中,需要反复访问海量的数据集、权重和参数;而在推理过程中,则涉及对KV Cache的访问,每次生成一个新的Token(词元)时都会重复这一过程。
当处理器的计算能力增长显著超过内存带宽和数据传输能力时,大部分处理时间将花费在等待数据从内存中读出或写入,而不是执行实际的计算。当系统性能受限于数据传输速度时,就出现了典型的“内存墙”(Memory Wall)问题。
近年来,AI芯片(如GPU)的计算能力增长速度,远快于其内存带宽和数据传输效率的提升。根据研究论文《AI and the Memory Wall》(https://www.semanticscholar.org/paper/AI-and-Memory-Wall-Gholami-Yao/4c14b1c41cb0aaa68f5d3f4a432f55e7199657ea)的分析,AI模型的计算能力每两年增长约3倍,而内存带宽仅增长约1.6倍,芯片间的互连带宽增长约1.4倍。因此,大多数计算任务实际上是受限于内存访问和通信效率,而非芯片的原始处理能力。
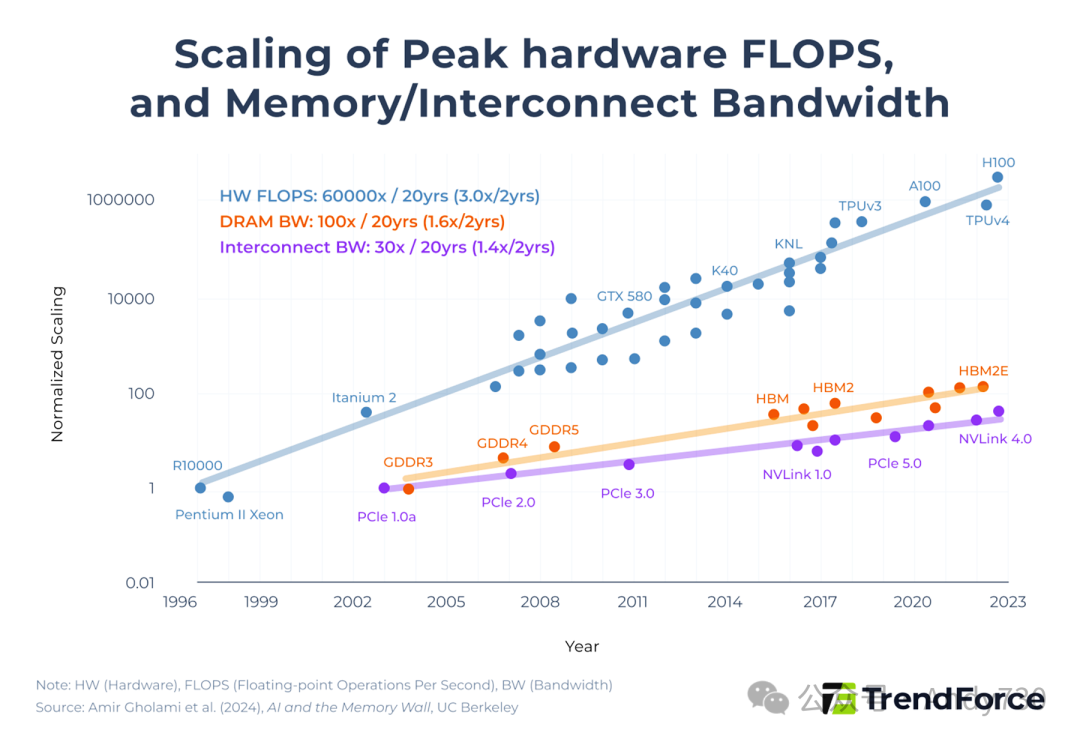
图1. 硬件峰值算力(FLOPS)与内存/互连带宽的增长曲线对比(数据来源:Amir Gholami et al., 2024)
从理论建模的角度来看,这种结构性的失衡可以用Roofline模型来解释。深度学习模型主要由矩阵乘法构成,其总计算工作负载以FLOPs(浮点运算次数)来衡量。
Roofline模型:由加州大学伯克利分校于2009年提出的高性能计算分析框架,用于量化系统性能瓶颈及其物理上限。该模型通过两个维度确立性能边界:一是算力峰值(Roofline),即硬件单位时间内能执行的最大浮点运算次数(FLOPS);二是内存带宽(Slope),即硬件单位时间内交换数据的能力(Byte/s)。通过将软件算法的“计算强度”(Operational Intensity,单位 FLOP/Byte)映射至此模型中,可以直观地判断该程序是受限于处理器的原始算力(Compute-Bound),还是受限于数据的传输速率(Memory-Bound)。
Roofline模型提供了一个计算理论上可达成性能的框架,用以下公式表示:
P = min(π, β × I)
其中,P代表可达成的性能(FLOP/s),π是硬件峰值算力,β是内存峰值带宽,I是计算强度(FLOP/Byte)。
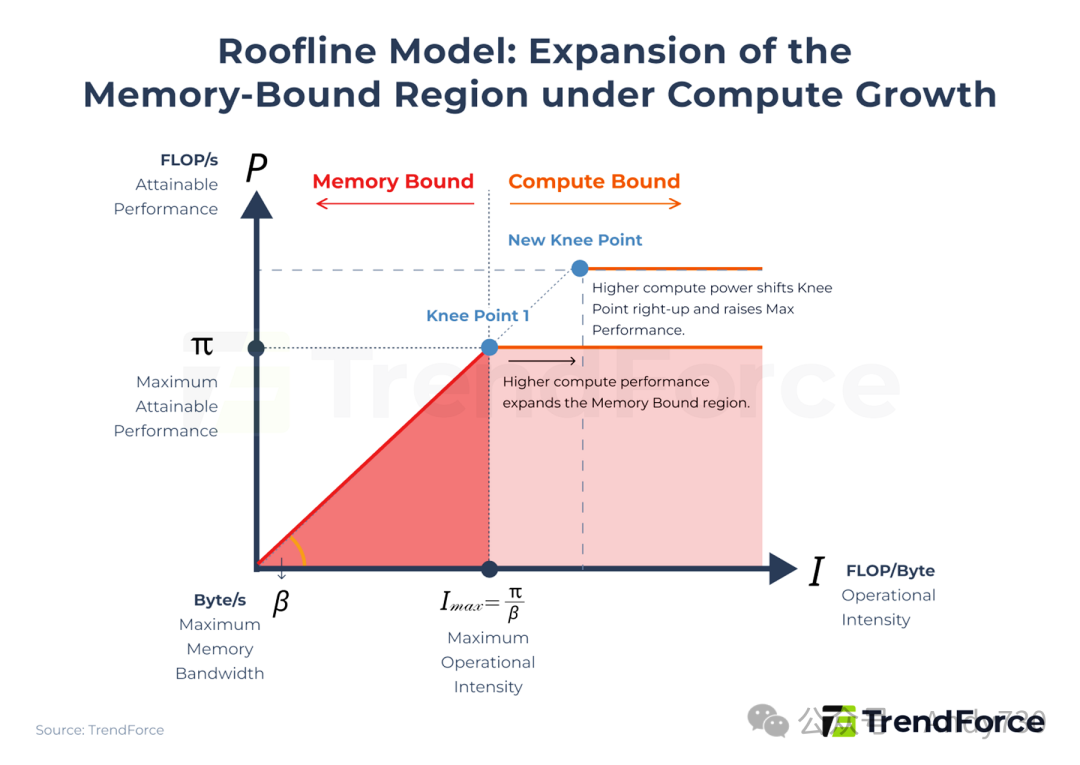
图2. Roofline模型:算力增长下内存受限区域的扩张趋势
该模型表明,系统性能受最大可实现性能(π)和最大内存带宽(β)的约束,而“膝点”(Knee Point,即 π = β × I 的点)标记了达到最大可实现性能所需的最小运算强度。
随着AI芯片计算能力持续增加(π上升),如果内存带宽斜率未相应提升(β增长缓慢),膝点就会向右上方移动,从而将更大比例的计算工作负载置于内存受限区域。换言之,计算能力的单方面增长,反而会加剧内存对最终可实现性能的限制。这就是为什么在AI时代,巨头们的竞争焦点正从单纯比拼FLOPS,转向参与一场激烈的“内存军备竞赛”。
HBM成为加速AI计算的破局方案
随着LLMs的规模持续扩展,甚至超过万亿参数(T)级别,单个芯片已无法处理完整的模型计算,因此演变为由多个AI加速器组成的集群。集群中包含的AI加速器越多,每个加速器内部以及芯片之间每秒需要传输的数据量就呈指数级增长。
在这种分布式架构中,数据传输的挑战进一步扩展到芯片之间(Scale Out),乃至跨数据中心级别(Scale Across)。这不仅造成了严重的“内存墙”瓶颈,还使得芯片间的互联带宽变得日益关键。除了InfiniBand和以太网之间的竞争,HBM 已成为AI加速器事实上的最佳内存选择。
HBM通过硅通孔(TSV)和先进封装技术,将多个DRAM芯片垂直堆叠,并与GPU/TPU等计算芯片集成在同一个封装内。相比传统的平面DRAM(如GDDR),HBM大幅缩短了数据传输的物理路径,并采用1024位的超宽接口,提供了远超传统方案的内存带宽。
预计在2026年进入正式发布的HBM4,其总带宽将达到惊人的2TB/s。它将接口宽度翻倍至2048位,同时保持数据传输速率超过8.0Gbps。这使得HBM4能够在不显著提高时钟速度的情况下,将数据吞吐量再翻一倍,从而进一步提升AI芯片在处理高并行度和数据密集型工作负载时的性能。
AI巨头规格军备竞赛,引发HBM需求激增
在历代产品迭代中,HBM在性能、I/O数量(即带宽)和容量方面不断进步,已成为AI加速器规格升级的核心支柱。近年来,NVIDIA、AMD和Google稳步将旗下AI芯片迁移至更新的HBM世代,每个芯片所搭载的HBM堆叠数量和大容量内存显著增加,直接拉动了HBM的市场需求。
根据TrendForce基于2025年AI芯片出货量的估算,HBM需求预计同比增长超过130%。进入2026年,HBM的消耗量预计将继续攀升,增长率仍将超过70%。主要的驱动力来自下一代平台(如NVIDIA的B300/GB300/R100/R200/VR100/VR200)的更广泛采用,以及Google TPU和AWS Trainium等加速器向HBM3e的转型。
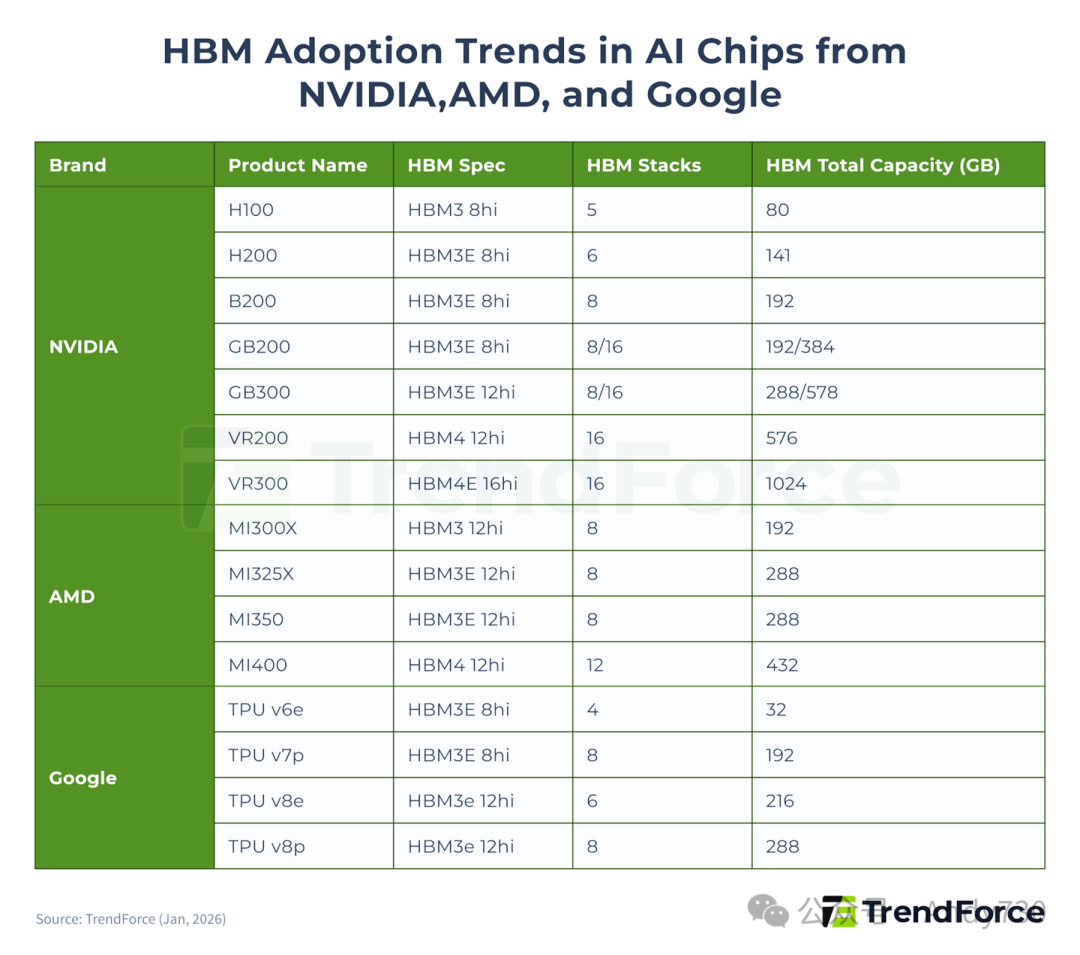
图3. NVIDIA、AMD及Google AI芯片的HBM采用趋势(来源:TrendForce, Jan 2026)
AI推理兴起,驱动DDR5需求
随着AI计算的重心逐渐从训练转向推理,它正越来越多地应用于直面终端用户的场景。预计到2029年,AI推理将成为AI服务器需求的主要驱动力。
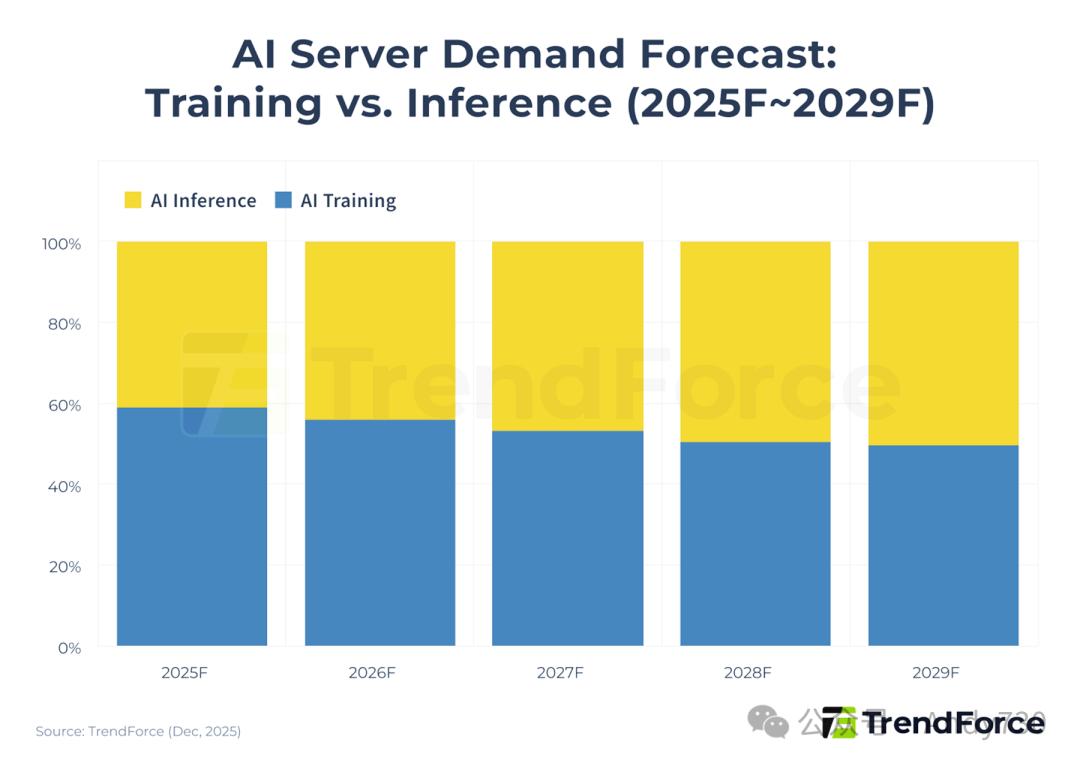
图4. AI服务器需求预测:训练与推理的趋势对比(来源:TrendForce, Dec 2025)
根据麦肯锡(McKinsey & Company)的报告,到2028年,AI推理预计将超过训练和非AI工作负载,成为数据中心最大的电力消耗来源。这一转变将驱动硬件架构和能源分配的全面变革。
针对这一趋势,行业正在重新评估计算各个阶段的硬件配置策略。这对超大规模数据中心运营商在电力供应和网络架构的长期规划具有重大意义。目标是在有效降低总拥有成本(TCO)的同时,优化性能与成本的平衡。这深刻反映了推理需求如何重塑整个数据中心的基础设施系统。
推理需求下的DDR5配置升级和价格趋势
训练和推理对内存的需求存在明显差异。在训练阶段,需要反复处理整个大型数据集,这对内存带宽提出了极高的要求。带宽不足会导致强大的计算单元闲置,无法发挥最佳性能。因此,通常使用配备HBM的AI加速器来规避内存瓶颈。
相比之下,推理阶段的内存需求更具阶段性特征,主要可分为两个部分:
- Prefill(预填充)阶段:系统一次性处理完整的用户输入提示,将文本分解为Token并执行大规模矩阵计算。这一阶段属于计算密集型,但对内存带宽相对不那么敏感。因此,可以使用成本效益更高的DDR或GDDR内存配置。
- Decode(解码)阶段:模型通过反复访问权重参数和KV Cache,来逐个Token生成响应。这一阶段计算需求降低,但内存访问频率和延迟敏感性显著上升。内存访问延迟直接决定了每个Token的生成速度。因此,大容量、高带宽的HBM配置仍是此阶段的最佳选择。
云服务商正在大规模扩展通用服务器部署,以满足日益增长的推理需求。DDR5因其在性能与成本间的出色平衡,成为了首选的内存方案。这一趋势导致北美云服务商从2025年下半年开始规划2026年服务器采购时,大幅提高了DDR5的部署比例,进一步推高了DDR5的需求和价格。
根据TrendForce分析,在2025年第四季度,服务器DDR5和HBM3e的合同价格迅速靠拢。HBM3e原本的定价是服务器DDR5的4到5倍,但预计到2026年底,这一差距将缩小至1到2倍。
随着标准DRAM(如DDR5)的盈利能力逐步提高,一些供应商正将部分产能转向DDR5的生产,这反过来为HBM3e等更尖端产品的价格增长创造了更多空间。
| 表1. HBM与DDR5:技术及应用场景对比 |
项目 |
HBM |
DDR5 |
| 设计架构 |
DRAM通过硅通孔(TSV)垂直堆叠,并与GPU/TPU共同集成在单个封装内 |
平面单芯片DRAM,通过标准DIMM插槽进行扩展 |
| 总线宽度 |
极宽(每堆叠1024位) |
较窄(32位 x2) |
| 带宽 |
极高(TB/s级别) |
高(GB/s级别) |
| 总内存容量 |
较低(由于与计算芯片共同集成,容量相对固定) |
高(可通过DIMM插槽灵活扩展) |
| 成本 |
极高 |
相对较低 |
| 功耗 |
较低(因传输路径短,能效高) |
较高 |
| 主要应用场景 |
AI模型训练与推理(Decode阶段)、高性能计算(HPC) |
AI模型推理(Prefill阶段)、通用服务器及PC |
内存超级周期来袭,消费电子首当其冲
AI服务器和通用服务器的内存需求在2025年第三季度彻底扭转了市场趋势,导致供应短缺。三大DRAM制造商优先将产能分配给高利润的HBM和高端服务器DRAM,但由于晶圆厂总产能有限,2026年的供应不太可能出现显著扩张。与此同时,这严重挤压了通用服务器和消费级DRAM的供应,推动整体DRAM价格上涨,标志着新一轮内存超级周期的到来。
TrendForce预计2026年第一季度内存价格将再次大幅上涨,内存成本在智能手机、PC和其他消费电子设备物料成本(BOM)中的占比正迅速攀升。消费电子制造商受冲击最大,这直接影响了他们的出货计划。智能手机和笔记本品牌不得不通过降低配置规格、延迟升级来控**制成本,其中DRAM受到的影响最大,因为它在总成本中占有相当大的比例。
总体而言,高、中端设备的DRAM容量预计将向市场最低标准靠拢,升级步伐明显放缓,而所有消费电子市场的低端细分领域预计将受到最严重的冲击。
消费电子盈利承压,出货量前景全面疲软
TrendForce在2025年11月首次下调了对2026年智能手机、笔记本和游戏主机的全球产量预测。然而,随着内存价格持续上涨,基于对供应链发展的最新判断,所有终端设备的估算在2025年12月底被再次下调。
2026年智能手机产量增长率最初预计为同比增长0.1%,随后被下调至下降2%,并在2025年12月底进一步下调至下降3.5%。到2026年1月中旬,预测又被调整至同比下降7%。TrendForce进一步分析指出,即使对于利润率相对可观的iPhone机型,2026年第一季度内存占其BOM成本的比例也将显著增加,这将迫使苹果重新考虑新设备的定价策略,并可能减少或取消对旧机型的计划折扣。对于主打中低端市场的安卓品牌而言,内存容量一直是关键卖点之一,其占BOM成本的比例本就较高。随着价格激增,2026年的低端智能手机将被迫回归4GB内存配置,促使品牌调整定价或供应周期以缓解亏损。
笔记本市场2026年的出货量预期,已从此前预计的年增长1.7%下调至-2.8%,并进一步调整至-5.4%。对于供应链高度集成且定价更灵活的品牌,如苹果和联想,它们有更多余地来应对内存价格上涨。然而,低端和消费级笔记本品牌难以将成本转嫁给消费者,同时又受到处理器和操作系统最低要求的限制,进一步降低配置的难度较大。如果内存价格上涨的趋势在第二季度得不到缓解,TrendForce预测2026年全球笔记本出货量可能进一步同比下降10.1%。
2026年游戏主机出货量预测已从此前预计的同比下降3.5%下调至4.4%。对于任天堂Switch 2、索尼PS5和微软Xbox Series X等主要机型,内存成本占BOM的比例已从过去约15%的水平,大幅上升至23%到42%。因此,硬件毛利率被严重压缩。2026年,三大制造商将难以预留促销空间或遵循以往以销量驱动增长的策略,这可能会进一步抑制出货势头。如果内存市场状况未得到改善,全球游戏主机的市场渗透率预计将进入一个暂时的停滞阶段。
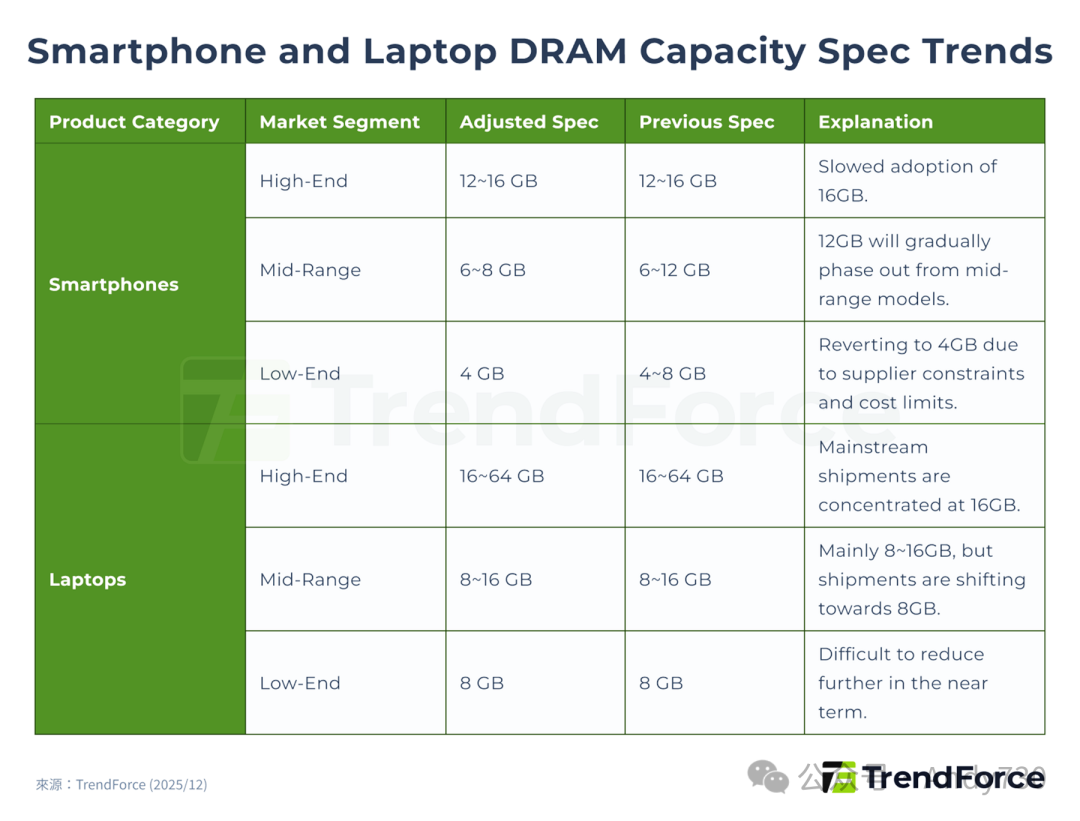
图5. 智能手机与笔记本DRAM容量规格演进趋势(来源:TrendForce, Dec 2025)
“打破内存墙”的军备竞赛:2026年内存超级周期与价格激增展望
与2016到2018年那场由通用服务器需求驱动、持续约九个季度的内存超级周期不同,本轮周期的关键驱动力是克服“内存墙”。随着AI芯片计算能力的增长速度远快于内存带宽,系统性能日益受到数据传输效率的制约,行业竞争的重点已从原始的算力比拼转向了内存带宽的军备竞赛。
本周期由AI服务器和通用服务器的需求共同驱动。为了应对内存墙瓶颈,供应商的产品组合已变得高度复杂,涵盖了HBM、DDR5、企业级SSD和其他高端内存产品,而这种产能分配策略也深刻影响了标准内存的可用性。
在生产产能保持相对有限的情况下,本轮内存超级周期预计将延续至2026年全年。市场已彻底转变为“卖方市场”,制造商将继续提高合同价格、谨慎管理产能扩展,并努力维持高定价水平。DRAM价格预计在2026年上涨超过70%,短缺和价格激增的趋势在年内预计将持续。
本文基于行业分析与市场数据,探讨了AI计算与内存技术交织下的市场动态。对于开发者与技术人员而言,理解底层硬件瓶颈(如内存墙)对计算机体系结构和模型部署的影响至关重要。想了解更多关于算力、模型训练与AI基础设施的深度讨论,可以关注云栈社区的技术板块。
 发表于 2026-1-28 02:50:56
|
查看: 268|
回复: 0
发表于 2026-1-28 02:50:56
|
查看: 268|
回复: 0
