在Linux运维与DevOps的日常工作中,我们时常需要应对各种突发的系统状态变化:CPU负载飙升、内存使用率持续上涨、磁盘IO异常波动等。要第一时间发现并响应这些问题,离不开高效的实时监控。watch命令正是Linux系统中一款轻量级却功能强大的实时监控工具,熟练掌握其用法是每位运维工程师的必备技能,在技术面试中也常常被问及相关技巧。
一、认识watch命令
watch命令的核心功能非常直观:它以固定的时间周期,重复执行你指定的命令,并将每次的执行结果全屏显示出来。通过持续刷新输出,你可以直观地观察到命令结果的动态变化趋势。
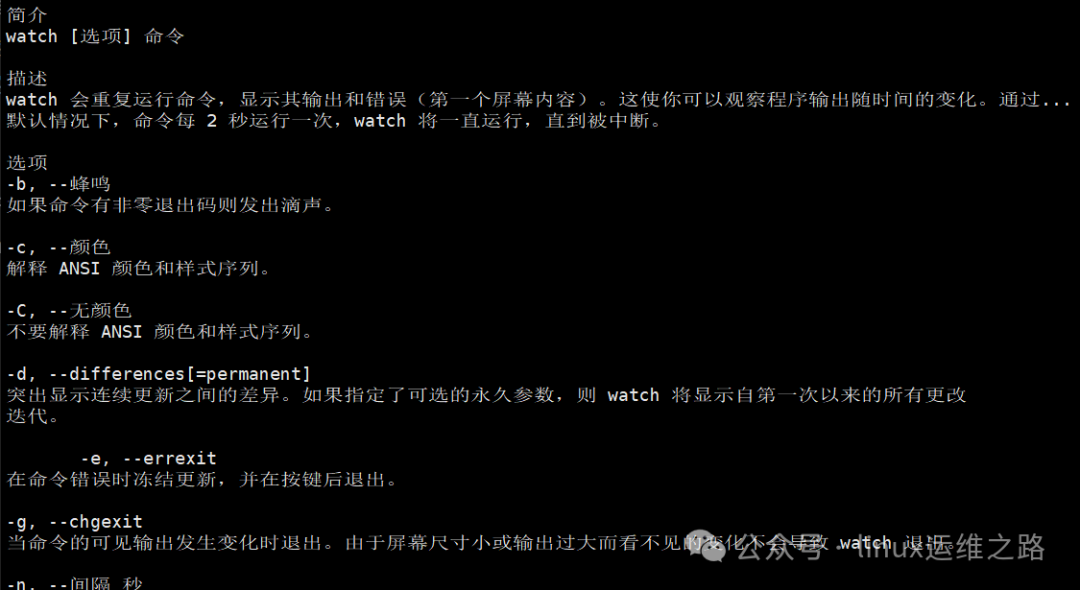
默认情况下,watch的刷新间隔为2秒,并且会以高亮形式显示前后两次输出之间的差异。这一特性在监控配置文件修改或跟踪数值变化时尤为实用。其基础语法如下:
watch [选项] 命令
二、核心操作与实践
对于日常运维监控,掌握watch的基础用法已能应对大部分场景。以下是一些高频操作示例:
-
默认监控
最简洁的用法是直接在watch后跟上要执行的命令。例如,监控系统负载:
watch uptime
 执行后,终端会进入全屏监控界面,每2秒刷新一次系统负载信息。界面顶部会显示被监控的命令、刷新间隔和当前时间。按
执行后,终端会进入全屏监控界面,每2秒刷新一次系统负载信息。界面顶部会显示被监控的命令、刷新间隔和当前时间。按 Ctrl+C 即可退出。其他常用场景:
监控内存使用:watch free -h
监控磁盘空间:watch df -h
监控进程数量:watch ‘wc -l /proc/processes‘
-
自定义刷新间隔
默认的2秒间隔并非适用于所有场景。监控高频变化指标(如网络流量)可能需要更短间隔,而观察缓慢变化的指标(如磁盘占用)则适合拉长间隔以节省资源。使用 -n 选项(代表interval)可以自定义秒数。
例如,每0.5秒监控一次CPU使用率:
watch -n 0.5 ‘top -b -n 1 | grep Cpu‘
-
控制输出与高亮
默认的差异高亮(红色)在查看数值变化时很直观,但在监控日志滚动等场景下可能造成干扰。
三、高阶用法:让监控更精准高效
掌握基础后,通过结合Linux系统的管道、过滤等特性,watch能实现更复杂的监控逻辑,解决实际运维难题。
-
过滤关键信息
实际工作中,我们往往只关心输出中的核心数据。这时可以将watch与grep、awk等命令结合。
- 监控80端口的连接数:
watch “netstat -an | grep :80 | wc -l“
(注意:组合命令需用双引号包裹,以确保watch能正确解析整个命令逻辑。)
- 监控特定进程(如
java)的CPU和内存使用:
watch “top -b -n 1 | grep java | awk ‘{print \$1, \$9, \$12, \$10}’“
其中 top -b -n 1 表示以非交互模式仅执行一次,避免干扰watch。
-
监控文件变化
虽然tail -f常用于追日志,但watch能更灵活地监控文件属性变化或内容篡改。
-
批量监控与指标聚合
通过echo命令组合多个命令的输出,可以在一个界面同时监控多个关键指标。
示例:同时查看CPU负载、内存使用率和根分区占用。
watch “echo -n ‘CPU负载: ‘; uptime | awk -F‘load average:‘ ‘{print \$2}‘ | tr -d ‘,‘; echo -n ‘ | 内存使用率: ‘; free | awk ‘/Mem/{printf \”%.2f%%\”, \$3/\$2*100}‘; echo -n ‘ | 根分区占用: ‘; df -h | grep ‘^/dev/‘ | grep -v ‘/boot‘ | awk ‘{print \$5}‘ | head -n1“

-
实现简易阈值告警
watch本身不支持告警,但结合Shell条件判断和ANSI颜色码,可实现“可视化告警”。
示例:监控根分区占用,超过80%时用红色高亮显示。
watch “df -h | grep ‘^/dev/‘ | grep -v ‘/boot‘ | awk ‘{p=\$5; sub(/%/, \”\“, p); if(p>80){printf \”\\033[31m警告:根分区占用%s,已超阈值!\\033[0m\\n\”, \$5}else{printf \”根分区占用:%s\\n\”, \$5}}’“
 (说明:
(说明:\033[31m 为红色字体控制码,\033[0m 用于恢复默认颜色。)
-
结合定时任务留存历史记录
可以将watch的周期性执行逻辑与crontab结合,将监控结果输出到日志,便于追溯。
四、避坑指南与最佳实践
使用watch时,一些细节疏忽可能导致监控失效或输出混乱,以下是需要特别注意的地方:
- 组合命令必须加引号:当命令包含管道(
|)、重定向(>)、空格时,必须用双引号包裹整个命令。例如 watch “netstat -an | grep 80“。
- 避免监控交互式命令:不要直接用
watch监控默认模式的top、htop等命令,会导致界面混乱。应使用其非交互模式,如 watch “top -b -n 1“。
- 合理设置刷新频率:刷新间隔并非越短越好。高频刷新(如<1秒)会增加系统负载。应根据指标变化速度调整,例如磁盘占用监控可设置为30秒。
- 特殊字符需转义:在
awk、sed等命令中使用$、”等字符时,需用反斜杠\进行转义,如 awk ‘{print \$5}‘。
- 后台执行需用nohup:若需在关闭终端后继续监控,应使用
nohup watch -n 5 “free -h“ &,输出会保存到 nohup.out。
- 注意版本差异:不同Linux发行版或BusyBox中的
watch版本可能支持不同的选项,使用前可通过 watch --help 确认。
- 文件实时监控选对工具:如需在文件内容变化时立即触发动作,
watch的轮询方式效率不如基于inotify的inotifywait命令,后者更适合日志监控等场景。
- 避免监控输出过大的命令:如
watch ls -l /,频繁全屏刷新大量内容会导致终端卡顿,应先用grep等命令过滤。
五、实战场景命令速查
| 监控场景 |
命令示例 |
说明 |
| 系统负载 |
watch -n 2 uptime |
每2秒查看1/5/15分钟平均负载。 |
| 内存使用 |
watch -n 3 free -h |
每3秒刷新,以人类可读格式显示内存。 |
| Web连接数 |
watch “netstat -an \| grep :80 \| wc -l“ |
实时统计80端口TCP连接总数。 |
| 进程存活 |
watch “ps -ef \| grep java \| grep -v grep“ |
监控Java进程是否在运行。 |
| 网卡流量 |
watch -n 1 “ifstat -i eth0“ |
每1秒监控eth0网卡进出流量(需安装ifstat)。 |
| 磁盘IO |
watch -n 5 iostat -x 1 1 |
每5秒查看一次磁盘IO扩展统计信息。 |
| MySQL连接 |
watch “mysql -u root -p‘password‘ -e ‘show status like \“Threads_Connected\”‘“ |
实时查看MySQL当前连接数。 |
| 文件完整性 |
watch “md5sum /etc/sysctl.conf“ |
通过MD5值监控重要配置文件是否被篡改。 |
六、watch与专业监控工具的定位
或许有人会问,有了Zabbix、Prometheus等专业监控系统,为何还需要watch?事实上,二者的定位完全不同,形成互补。
watch命令更像一把轻量灵活的瑞士军刀:
- 开箱即用:Linux系统默认自带,无需安装部署。
- 资源消耗极低:临时监控不会给系统带来额外负担。
- 极度灵活:可与任何Shell命令组合,快速定制监控逻辑。
它非常适合临时性故障排查、突发异常时的快速指标聚焦,或者验证某个特定假设的场景。而专业监控工具则胜在自动化、集中化、历史数据存储、报警通知和可视化大盘。将
watch作为专业监控之外的一种即时、轻量的补充手段,能极大提升运维工作的效率和灵活性。
掌握watch命令的深度用法,能让运维工程师在应对系统问题时更加得心应手。希望本文介绍的方法与技巧,能帮助你在日常工作中更高效地利用这款利器。 |  发表于 2025-12-2 23:11:37
|
查看: 252|
回复: 0
发表于 2025-12-2 23:11:37
|
查看: 252|
回复: 0