把 Git 当作一个数据库来用,这个念头对很多工程师来说都颇具吸引力,因为它看起来优点多多:
- 天然具备版本历史
- 自带 Pull Request 与代码审核流程
- 分布式架构,托管成本相对较低
- 工具链成熟,几乎人人都会用
因此,在设计新的包管理器时,采用 Git 作为底层索引存储,似乎是一条非常“合理”的技术路线。
但从长期运行和维护的结果来看,这种方案往往难以持续,最终要么被放弃,要么变得效率低下。问题出在哪里?让我们通过几个主流的包管理器案例,看看它们是如何“踩坑”和“填坑”的。
Cargo 的“甜蜜负担”
Rust 的包管理器 Cargo 在早期采用了这样的方案:让所有客户端都去克隆(clone)整个 crates.io 索引仓库。
初期生态规模较小时,这没什么问题。但随着 Rust 生态的飞速发展,crates.io 上的库数量激增,问题便暴露出来:
- 索引仓库持续膨胀,体积越来越大。
- 每次执行
git fetch 时,经常卡在“Resolving deltas”这个阶段,耗费大量时间。
- 在 CI/CD 环境中,为了构建项目频繁进行全量 Git 操作,但实际上只使用了其中极少一部分数据。
本质上,这是用 Git 的全量同步协议,去处理高频、小粒度查询的工作负载,好比用卡车去送快递,既不高效也不经济。
Cargo 团队的解决方案是引入 Sparse HTTP Index(稀疏 HTTP 索引):
- 客户端不再需要克隆整个巨型索引仓库。
- 转而通过 HTTPS 协议,按需拉取指定依赖包的元数据文件。
效果立竿见影。到 2025 年 4 月,已有 99% 的 crates.io 请求来自默认启用了稀疏索引模式的 Cargo 客户端。虽然 Git 索引仓库依然存在,但已不再是客户端获取数据的主流路径。
Homebrew 的规模之痛
macOS(和 Linux)上著名的包管理器 Homebrew 也面临过类似的规模问题:
- 其核心公式仓库(Homebrew/homebrew-core)的
.git 目录曾一度接近 1GB。
- 从浅克隆(shallow clone)恢复到完整历史(unshallow)需要下载数百 MB 数据。
- 用户执行
brew update 时,大量时间消耗在 Git 的差分计算上,而不是实际获取更新。
情况严重到 GitHub 都曾明确建议 Homebrew 团队:避免继续使用浅克隆。
在 Homebrew 4.0(2023年) 中,官方做出了重大调整:
- 放弃通过 Git 来更新“tap”(第三方软件源)。
- 改用 JSON over HTTP 的方式分发软件包元数据。
- 同时,自动检查更新的频率从 5 分钟一次调整为 24 小时一次。
官方给出的理由非常直接:git fetch 成本高、速度慢,对用户体验不友好。这一改变对 Homebrew 的长期可维护性和用户体验至关重要。
CocoaPods 的 CI 困境
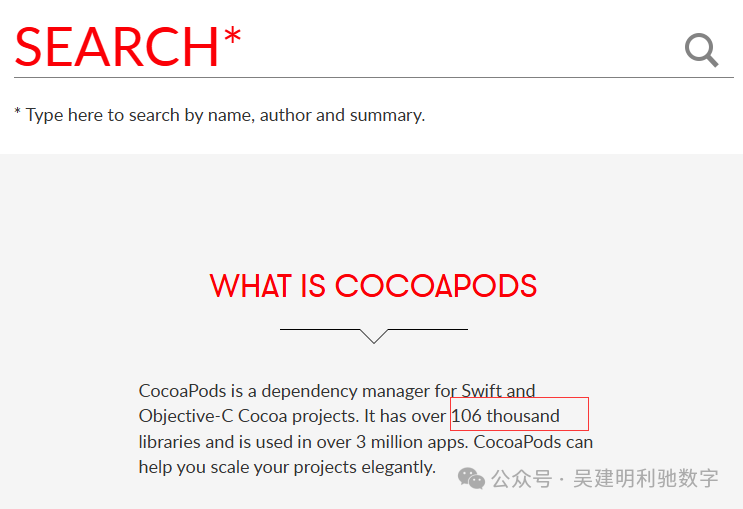
iOS/macOS 开发的依赖管理器 CocoaPods,其所有库的规格定义(podspec)曾经都存放在一个名为 Specs 的 Git 仓库中。
- 初次克隆这个包含数十万条 podspec 的仓库,通常需要数分钟。
- 在 CI 环境中,大量构建时间被消耗在 Git 操作上,而不是编译代码。
- 由于其庞大的规模和频繁的访问,GitHub 一度开始对该仓库进行 CPU 资源限制。
团队最终得出的结论是:Git 的设计初衷,并未考虑“海量、短生命周期的 CI 构建”这一特定场景。
最终的解决方案是转向 CDN 分发:
- podspec 文件改为通过 HTTP 协议获取。
- 这一转变直接为每个开发环境节省了接近 1GB 的本地磁盘空间。
- 在新环境中安装依赖的时间显著缩短,达到了几乎“秒级”安装的速度。
vcpkg 的架构约束
微软的 C/C++ 包管理器 vcpkg 遇到的问题则更为深刻,触及了架构层面。
vcpkg 的版本控制机制深度依赖于 Git 的树哈希(git tree hash):
- 其基线(baseline)机制需要解析 Git 的完整历史。
- 这导致浅克隆(shallow clone)会直接失败。
然而,在现代 CI 环境(如 GitHub Actions)、开发容器(DevContainer)中,浅克隆恰恰是默认的、推荐的行为,以节省时间和带宽。
更关键的问题在于:一个 tree hash 无法反向推导出对应的 commit。这导致:
- 难以利用 CDN 进行高效分发。
- 无法通过简单的 HTTP 接口获取特定数据。
- 无法实现类似 Cargo 的“稀疏”获取模式。
在这里,Git 不仅仅是数据存储,更是被直接嵌入为系统的核心前提和设计约束,形成了一个后期很难解开的架构死结。
Go Modules 的清晰范式
Go 语言的 Go Modules 为这个问题提供了一个相对清晰、成功的反例。
最初,go get 命令为了读取一个仓库的 go.mod 文件,不得不先克隆整个仓库,效率低下。
Go 团队设计的解决方案非常明确:
- GOPROXY:通过 HTTP 代理服务器来分发模块,客户端只需按需拉取。
- sumdb:提供一个独立的、可验证的校验和数据库,保证模块的安全性。
实际效果堪称惊人:go get 获取大型依赖的时间从约 18 分钟,降低到了约 12 秒。Git 被完全移出了依赖获取和解析的关键路径,仅在需要源代码时作为载体存在。
核心症结:用文件系统模型做数据库
上述所有案例,最终都指向同一个根本结论:Git 继承的是文件系统的数据模型,而文件系统本身并不适合直接作为数据库来使用。
将 Git 用作“数据库”时会遇到的常见限制包括:
- 文件数量爆炸:单目录下文件数量过多(如数十万),会严重拖慢文件系统操作。
- 平台差异性:不同操作系统(Windows/Linux/macOS)对文件名大小写的处理规则不同,可能导致跨平台问题。
- 路径长度限制:文件系统有路径长度限制,而过深的嵌套或过长的包名可能触发此限制。
- 缺乏数据库特性:没有内置的索引、约束、事务和模式迁移机制,这些都需要在应用层重新实现。
因此,许多起初采用 Git 作为“数据库”的系统,最终都会经历一个相似的演化路径:
Git 存储 → 手动分片 → 增加规则约束 → 自建索引 → 最终转向 HTTP API 或专用数据库。
区别仅仅在于,这个转折点是来得早一些,还是晚一些。
小结
Git 是一个非常优秀的工具——但仅限于它被设计用来解决的问题域:源代码的分布式版本控制和协作。
而一个现代包管理器真正需要的是:
- 快速、可预测的点查询(根据包名立刻获取元数据)。
- 稳定的、版本化的元数据接口。
- 可被高效缓存、甚至通过 CDN 全球分发的数据格式。
Git 提供的核心能力则是:面向整个代码仓库的全量同步与历史追溯。这两种需求在根本上存在错位。
所以,如果你正在构思一个新的包管理器,或是被“用 Git 当索引”这种方案的简洁性所吸引,不妨停下来,认真参考一下 Cargo、Homebrew、CocoaPods、vcpkg 和 Go 这些前辈的经验与教训。
关于系统架构设计和工具选型中的这类“陷阱”,在 云栈社区 的后端与架构板块常有深入的讨论。这些已被反复验证过的问题,值得我们铭记在心,避免在未来的项目中重蹈覆辙。
 发表于 2026-1-28 05:22:46
|
查看: 218|
回复: 0
发表于 2026-1-28 05:22:46
|
查看: 218|
回复: 0
