云原生架构的核心之一是高效的资源调度与流量管理,而 Kubernetes(简称K8S)中的负载均衡机制正是实现这一目标的关键。本文将深入解析K8S实现负载均衡的原理,并详细探讨其支持的三种核心调度算法。

Kubernetes 是一个开源的容器编排平台,旨在自动化容器化应用的部署、扩展与管理。通过将应用封装为Pod并在集群中调度运行,K8S实现了高可用、可伸缩与自愈能力,成为构建现代云原生应用的基础设施。
K8S 负载均衡的实现原理
需要明确的是,K8s 自身并不直接处理负载均衡的流量转发,这项任务主要由一个名为 kube-proxy 的组件在每个节点(Node)上完成。它的核心工作是将对 Service 的访问流量,智能地分发到后端的 Endpoint,也就是实际的 Pod。
Service 是 K8S 中一个重要的抽象概念,它为具有相同标签(Label)的一组 Pod 提供了一个稳定的访问入口。这个入口体现为一个固定的虚拟 IP 地址(称为 ClusterIP)和端口。这样一来,客户端无需关心后端具体有多少个 Pod、它们的 IP 地址是什么,只需访问 Service 的虚拟 IP,kube-proxy 就会帮忙完成服务发现和负载均衡。
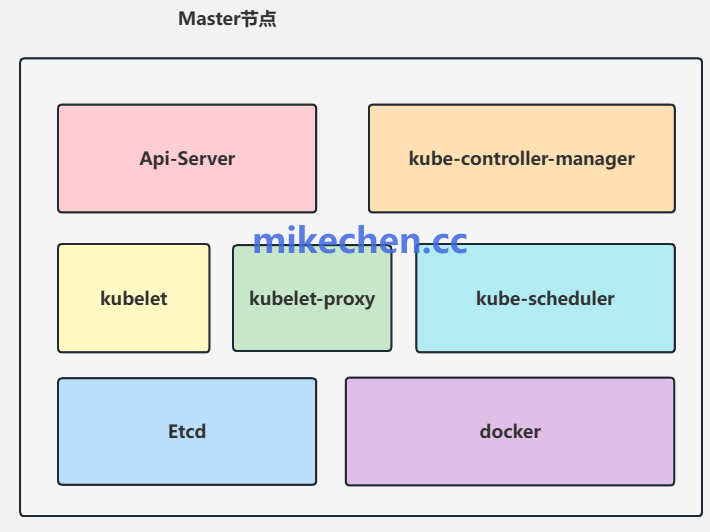
kube-proxy 运行在每个节点上,持续监听 Kubernetes API 服务器上 Service 和 Endpoint 对象的变化。根据这些信息,它会在操作系统内核层面(通过 iptables 或 IPVS)编程设置网络规则。当流量到达节点并指向某个 Service 的 ClusterIP 时,这些预置的规则会自动将流量重定向或转发到后端一个健康的 Pod 上。
目前,kube-proxy 主要支持两种工作模式:iptables 和 IPVS。在 IPVS 模式下,kube-proxy 会利用 Linux 内核的 IPVS(IP Virtual Server)模块。IPVS 是一个工作在内核态的、高性能的负载均衡器,它支持多种流量调度算法,这也是我们接下来要重点讨论的内容。
三种核心负载均衡算法
在 IPVS 模式下,你可以根据业务特性为 Service 选择不同的调度算法。以下是三种最经典和常用的算法。
1. 轮询 (Round Robin)
这是最简单直观的算法。负载均衡器将请求按顺序依次分配给后端的所有服务器,循环往复。
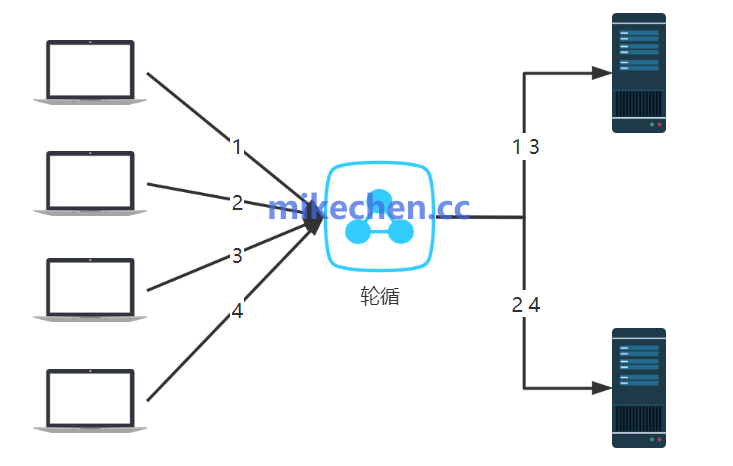
算法优势:
- 实现简单:负载均衡器无需记录任何连接状态,计算开销极低。
- 绝对公平:在后端服务器处理能力完全对等的无状态场景下,能做到请求的均匀分配。
算法劣势:
- 忽略服务器差异:如果后端服务器配置不均(例如,有的 4 核,有的 8 核),性能强的服务器可能会被闲置,造成资源浪费。
- 无法感知负载:如果某台服务器上的某个请求处理特别慢(长事务、复杂查询),后续轮询到的请求仍然会堆积到该服务器,可能导致响应延迟升高。
改进版:加权轮询 (Weighted Round Robin)。通过为每台服务器配置一个权重值,性能强的服务器获得更高的权重,从而分配到更多请求,解决了硬件能力差异的问题。
2. 最少连接 (Least Connections)
这是一种动态调度算法。负载均衡器会实时统计各台服务器当前正在处理的活跃连接数,并将新的连接请求分配给当前连接数最少的服务器。
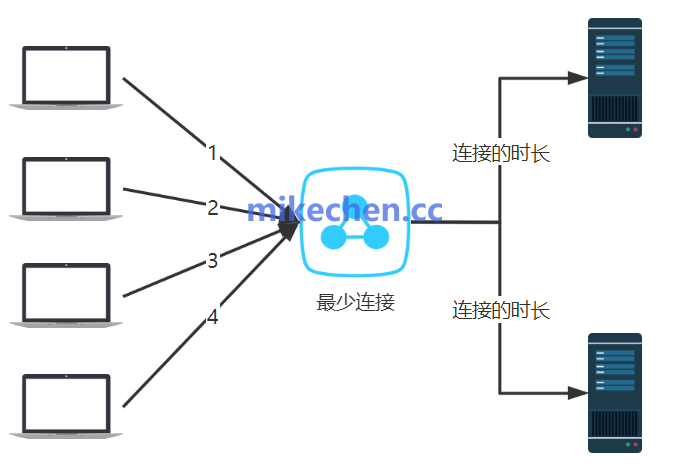
算法优势:
- 动态感知服务器状态:它能够自动避开那些处理缓慢或已经满载的服务器,将新请求导向相对空闲的节点,是较为“智能”的算法之一。
- 资源利用率高:特别适合处理时间长短不一的请求,或大量使用长连接(如 WebSocket、数据库连接池)的业务场景,能极大地提升后端资源的整体利用率。
算法劣势:
- 存在性能开销:负载均衡器需要维护和实时更新所有后端服务器的连接状态表,在高并发场景下会消耗额外的内存和 CPU 资源。
- 存在冷启动问题:当一个新的后端服务器节点加入集群时,由于其初始连接数为 0,所有新流量可能会瞬间涌向该新节点,可能导致它被“秒杀”。
3. 源地址哈希 (Source IP Hash)
此算法基于请求的某个特征进行哈希计算,并将同一特征的请求始终定向到同一台后端服务器。最常用的特征是客户端的源 IP 地址。
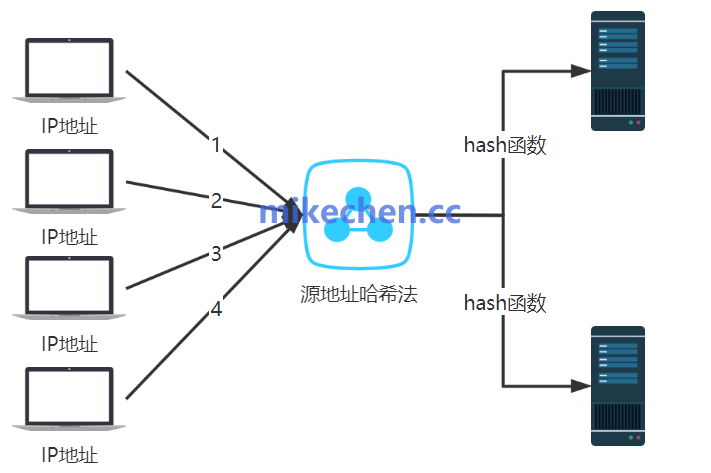
算法优势:
- 实现会话保持:无需引入分布式会话(Session)存储,就能保证来自同一个客户端 IP 的所有请求都落到同一台后端服务器上,非常适合需要状态保持的应用。
- 缓存友好:能显著提高后端服务器的本地缓存命中率。例如,在 CDN 或网关场景中,同一用户的请求固定访问某台服务器,其资源缓存无需在多台机器间同步。
算法劣势:
- 容易导致负载不均:如果某个源 IP(例如某个热门用户或爬虫)产生了海量请求,会导致其映射到的单台服务器压力过大,形成“热点”问题。
- 扩容/缩容时影响大:传统的取模哈希算法在增加或减少后端服务器节点时,会导致大量的请求映射关系失效,需要重新哈希,可能引起短暂的服务抖动或缓存雪崩。
总结
Kubernetes 通过 kube-proxy 和 Service 机制,在内核层面实现了高效、透明的负载均衡。理解轮询、最少连接和源地址哈希这三种核心算法的原理及适用场景,对于在 K8S 中进行微服务架构设计和运维调优至关重要。在实际生产环境中,应根据业务类型(如无状态 API、长连接业务、需要会话保持的应用)和后端服务器配置,灵活选用或组合这些算法,以达到最佳的性能与稳定性平衡。 |  发表于 2026-1-28 05:45:23
|
查看: 161|
回复: 0
发表于 2026-1-28 05:45:23
|
查看: 161|
回复: 0
