临近年末,国内各大AI厂商进入了密集的成果发布期。在HuggingFace等主流开源社区的热门榜上,国产模型占据了半壁江山,包括Qwen3-TTS、GLM-4.7-Flash、GLM-Image、LongCat-Flash-Thinking-2601、Baichuan-M3、Youtu-LLM、STEP3-VL-10B等一系列新面孔,展现出一波新的技术活力。
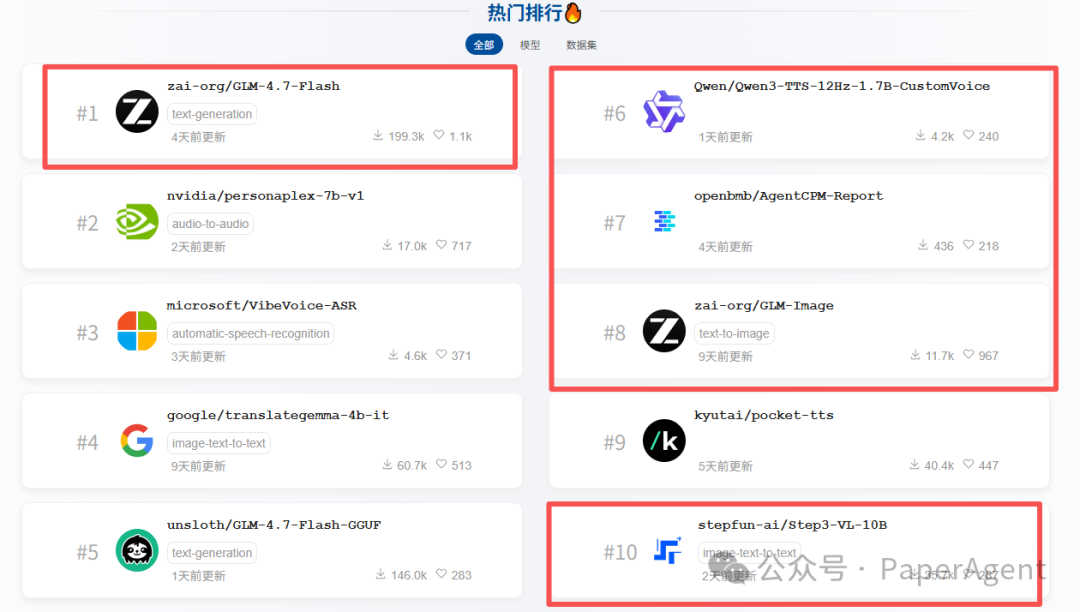
下面,我们来逐一梳理这些近期备受关注的国产开源大模型及其核心亮点。
1. Qwen3-TTS:面向全球的端到端语音合成
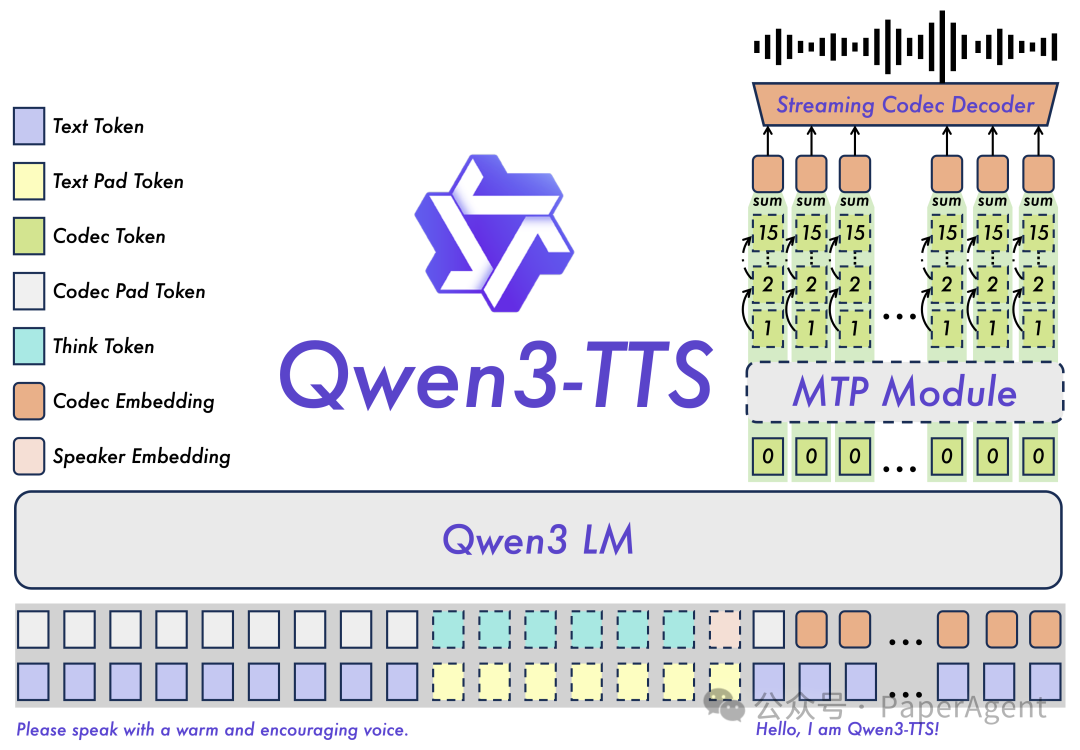
通义千问团队开源的Qwen3-TTS模型,旨在提供高质量的语音合成服务。它覆盖了中文、英文、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语、意大利语等十大语种,并支持多种方言声线,以满足全球化的落地需求。
该模型的核心能力在于强大的上下文理解。它可以根据用户的指令和文本本身的语义,自适应地调整语调、语速和情感表达。同时,模型对含有噪声的输入文本也表现出更强的鲁棒性。其主要技术亮点包括:
- 强大的语音表征能力
- 通用的端到端架构
- 支持极致低延迟的流式合成
- 智能的文本理解与声纹控制
模型地址:
https://hf-mirror.com/collections/Qwen/qwen3-tts
2. LongCat-Flash-Thinking-2601:开源的“重思考”智能体
这是首个完整开源并支持在线免费体验 “重思考模式(Heavy Thinking Mode)” 的模型。该模式能够同时启动 8个“大脑”并行运转,旨在通过更周全的思考过程来确保决策的可靠性。
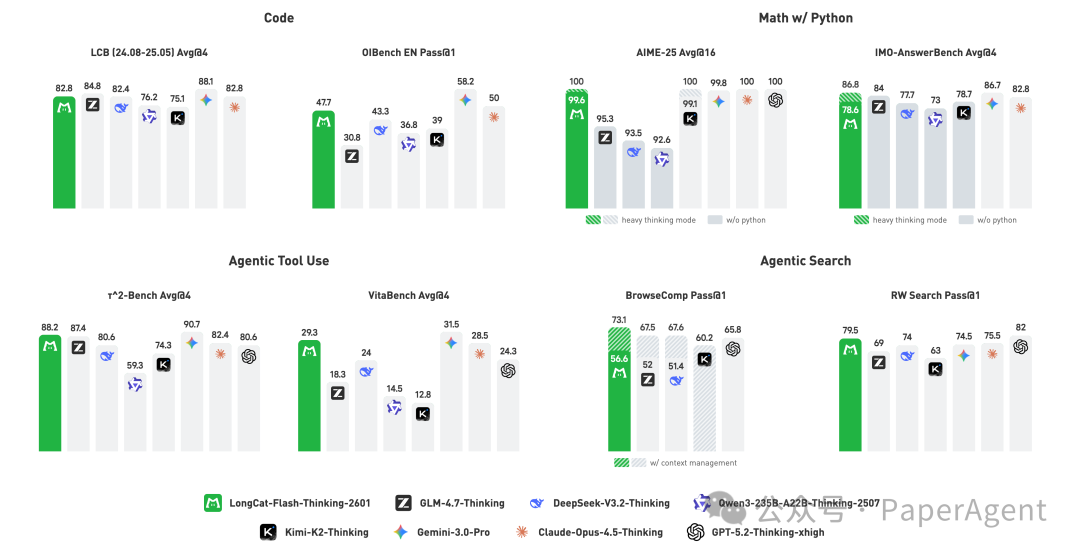
新版本在继承上一代“领域并行”训练方法、保持传统推理基准顶尖表现的同时,通过 “环境扩展 → 任务合成 → 大规模多环境强化学习” 这一精密流水线,系统性地强化了模型的智能体思维能力。
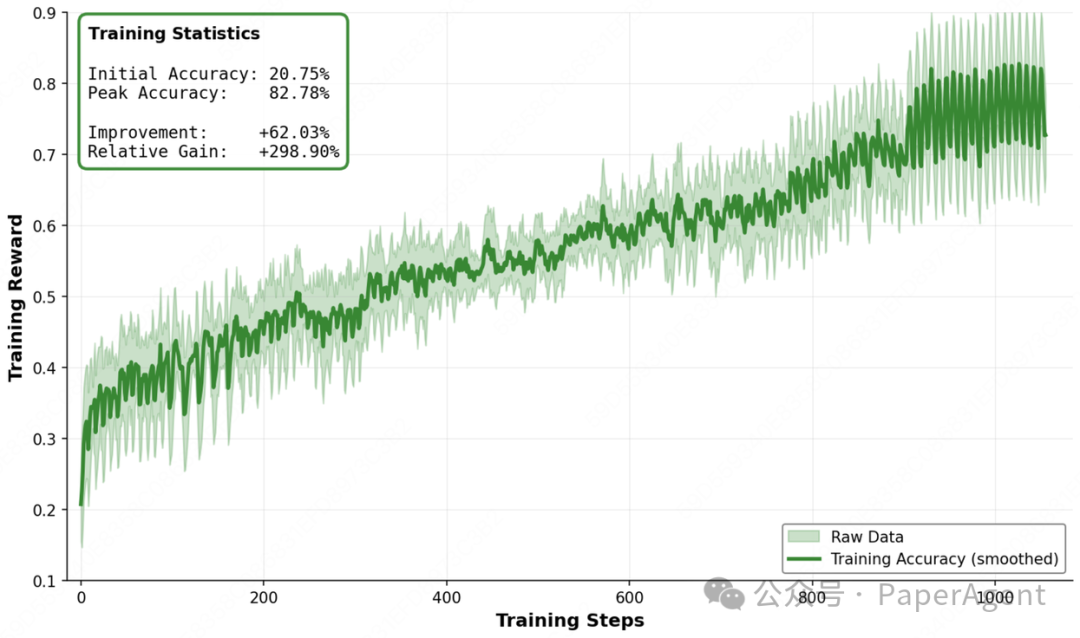
为了更好应对真实智能体任务中固有的噪声与不确定性,研发团队针对多种类型、多个层级的环境噪声展开了系统分析,并采用了课程式训练策略,使模型在信息不完美的条件下依然能保持稳健的输出。
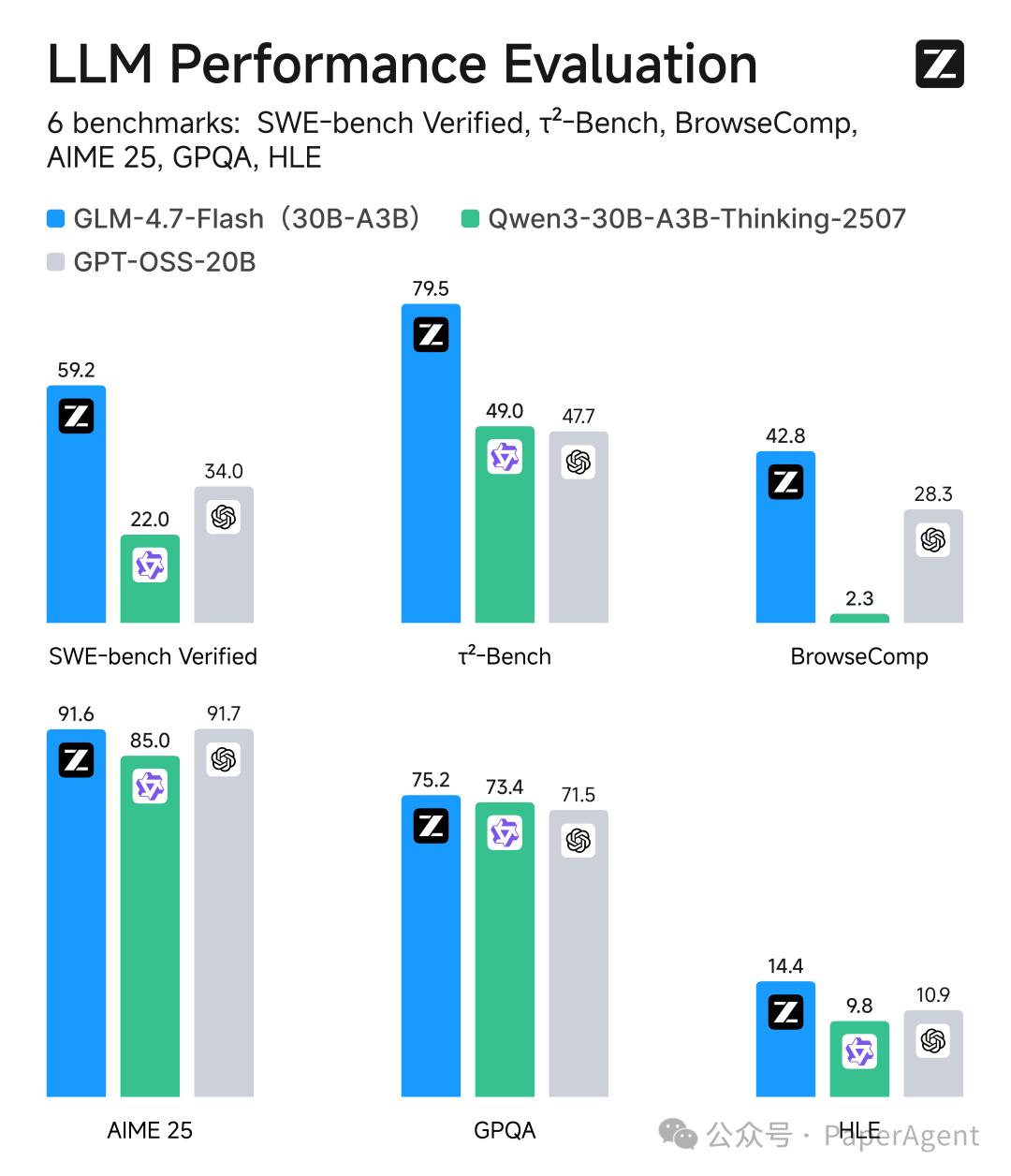
3. GLM-4.7-Flash:轻量部署的性能之选
智谱AI开源的GLM-4.7-Flash模型采用了30B-A3B的MoE(混合专家)架构。官方称其为30B参数规模中的性能最强模型,为需要在轻量级设备上部署的用户提供了一个兼顾性能与效率的新选择。
模型地址:
https://hf-mirror.com/zai-org/GLM-4.7-Flash
4. 阶跃星辰双料开源:视觉与语音的突破
阶跃星辰近期开源了两个重要模型,覆盖了视觉和语音两个关键模态。
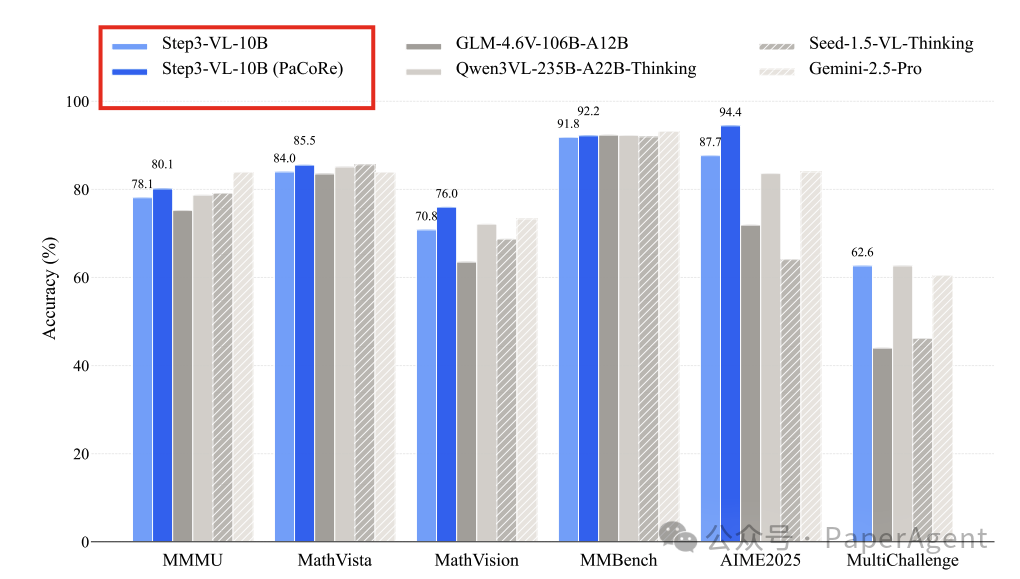
STEP3-VL-10B 是一个高效的多模态模型。它采用1.8B参数的语言优化感知编码器(据称优于空间优化版本)与Qwen3-8B解码器相结合。通过16倍空间下采样投影器和多裁剪策略(全局728×728 + 局部504×504),实现了高效的视觉-语言对齐。最终以100亿参数的紧凑规模,达到了前沿的多模态性能。
论文与模型地址:
https://arxiv.org/pdf/2601.09668
https://hf-mirror.com/stepfun-ai/Step3-VL-10B
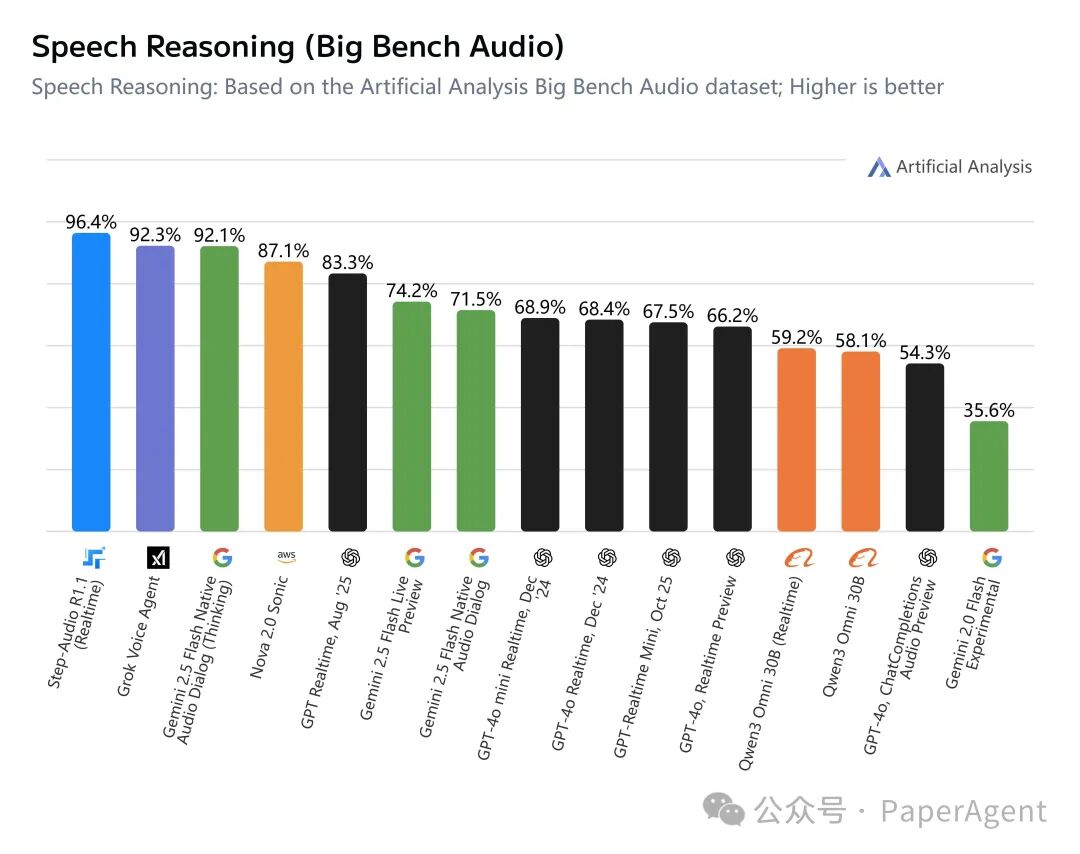
Step-Audio R1.1(实时版) 是Step-Audio-R1的重大升级版本,专为交互式语音对话场景设计。它既具备了实时响应能力,也拥有强大的语音推理能力。
模型地址:
https://hf-mirror.com/stepfun-ai/Step-Audio-R1.1
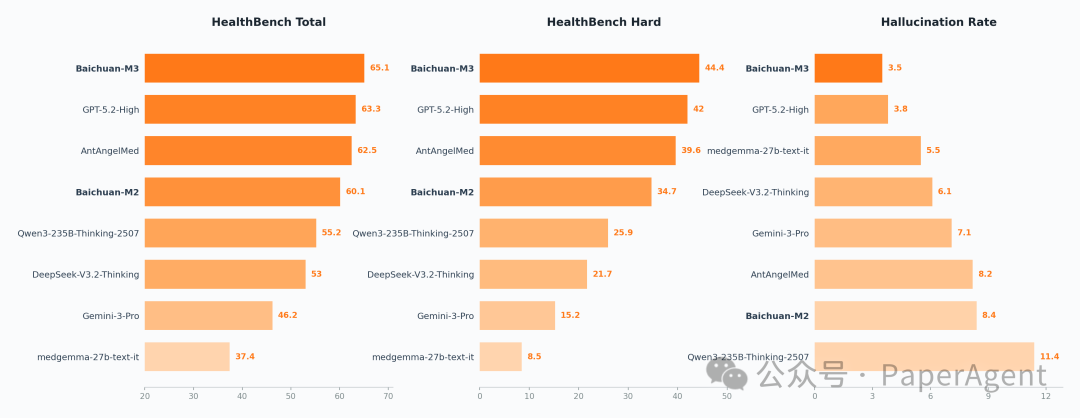
5. Baichuan-M3:专注于医疗领域的低幻觉模型
百川智能发布的 Baichuan-M3 是一个经过专门训练的医疗大模型。其目标是显式地建模临床决策过程,旨在提升模型在真实医疗场景中的实用性与可靠性。
其核心宣称是 “低幻觉、高可靠” :通过事实感知强化学习(Fact-Aware RL) 技术,实现了低于对比模型GPT-5.2的幻觉率,且无需依赖外部知识库或检索工具。
该模型采用的SPAR训练框架,将临床流程分解为四阶段独立奖励机制,结合事实感知强化学习实时验证医学声明的正确性。并通过三阶段多专家融合训练与推理优化,旨在解决长程临床对话交互中常见的奖励稀疏与信用分配难题。
模型地址:
https://hf-mirror.com/baichuan-inc/Baichuan-M3-235B
6. 腾讯优图Youtu-LLM:轻量级原生智能体
腾讯优图实验室开源的 Youtu-LLM-1.96B 是一个小巧但能力全面的模型。它采用MLA(Multi-head Latent Attention)架构与STEM专用词表,支持128K长上下文。
该模型通过总计11T token的 “常识-STEM-智能体”渐进式课程预训练,以及一套可扩展的智能体中训方案,让这个不足20亿参数的轻量级模型原生具备了推理与规划能力。
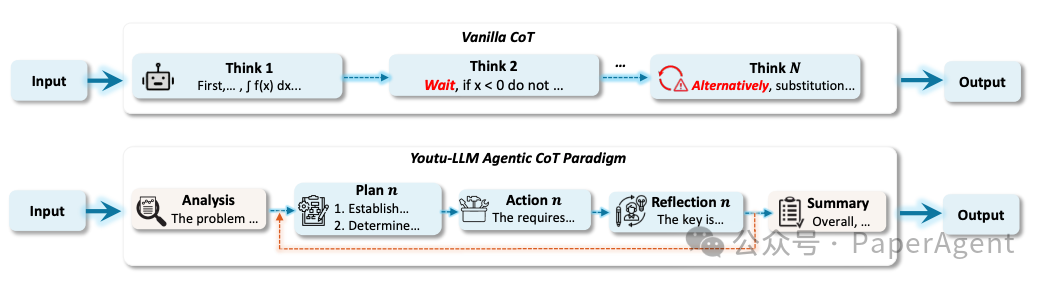
模型与论文地址:
https://hf-mirror.com/tencent/Youtu-LLM-2B
https://arxiv.org/abs/2512.24618
小结
从语音合成、复杂推理到多模态理解和垂直领域应用,这波年底的模型发布潮展示了国产开源大模型在技术纵深和应用广度上的持续探索。对于开发者和研究者而言,这些高质量的开源成果无疑提供了丰富的工具和新的研究起点。想了解更多AI前沿动态和技术实践,欢迎关注云栈社区的相关讨论。
 发表于 2026-1-28 08:56:07
|
查看: 163|
回复: 0
发表于 2026-1-28 08:56:07
|
查看: 163|
回复: 0
