在分布式系统的世界里,服务调用失败几乎是无法避免的宿命。网络抖动、服务器宕机、瞬间的流量高峰……任何一点风吹草动都可能导致某个服务实例暂时“失联”。想象一下,在一个电商平台的购物高峰期,用户点击查询商品却迟迟得不到响应,这种体验有多糟糕。因此,一个健壮的分布式服务框架,必须有能力妥善处理这些异常情况,确保核心业务逻辑的连续性和用户体验,这便是集群容错机制存在的意义。
作为一款广泛使用的 分布式系统 服务框架,Dubbo 提供了一套强大而灵活的集群容错机制。它如同一个经验丰富的调度中心,在服务调用出现问题时,能根据预设的策略做出不同反应,或重试,或快速失败,或默默记录,从而在复杂多变的网络环境中保障服务的整体高可用性。那么,Dubbo 到底是如何实现这些策略的?不同策略又适用于哪些业务场景?让我们结合源码,一探究竟。
核心概念与策略全景
在深入代码之前,我们先对Dubbo的容错机制建立一个整体的认识。
容错策略概览
Dubbo 内置了多种容错策略,以适应不同的业务场景和可靠性要求:
- Failover:失败自动切换。这是默认策略。调用失败后,会自动重试其他服务器。
- Failfast:快速失败。只发起一次调用,失败立即抛出异常,不进行任何重试。
- Failsafe:失败安全。出现异常时,直接忽略,仅记录错误日志,返回一个空结果。
- Failback:失败自动恢复。调用失败后,将失败请求放入队列,由后台定时任务进行重试。
- Forking:并行调用。同时调用多个服务器,只要有一个成功就立即返回。
- Broadcast:广播调用。逐个调用所有提供者,任意一个报错则报错。
策略选择的关键
没有放之四海而皆准的策略,只有最适合场景的策略。例如:
- 对于读操作或幂等性操作(如查询、统计),允许重试的
Failover 策略能有效提升成功率。
- 对于非幂等性写操作(如创建订单、扣减库存),重试可能导致数据不一致,此时
Failfast 快速失败更为合适。
选择的核心依据在于业务场景对一致性、可用性、实时性的不同权衡。下文我们将通过源码,剖析前五种策略的具体实现。
容错策略源码深度解析
所有集群容错策略的核心逻辑,都封装在继承自 AbstractClusterInvoker 的各个 XXXClusterInvoker 类的 doInvoke 方法中。下面我们来逐一解读。
Failover:失败自动切换
适用场景:读操作或幂等性操作。
特点:通过 retries 参数控制重试次数(不含首次调用),默认为2,即最多调用3次。
这是最常用的一种策略。其核心思想是:当调用某个服务提供者失败时,自动切换到列表中的下一个提供者进行重试。
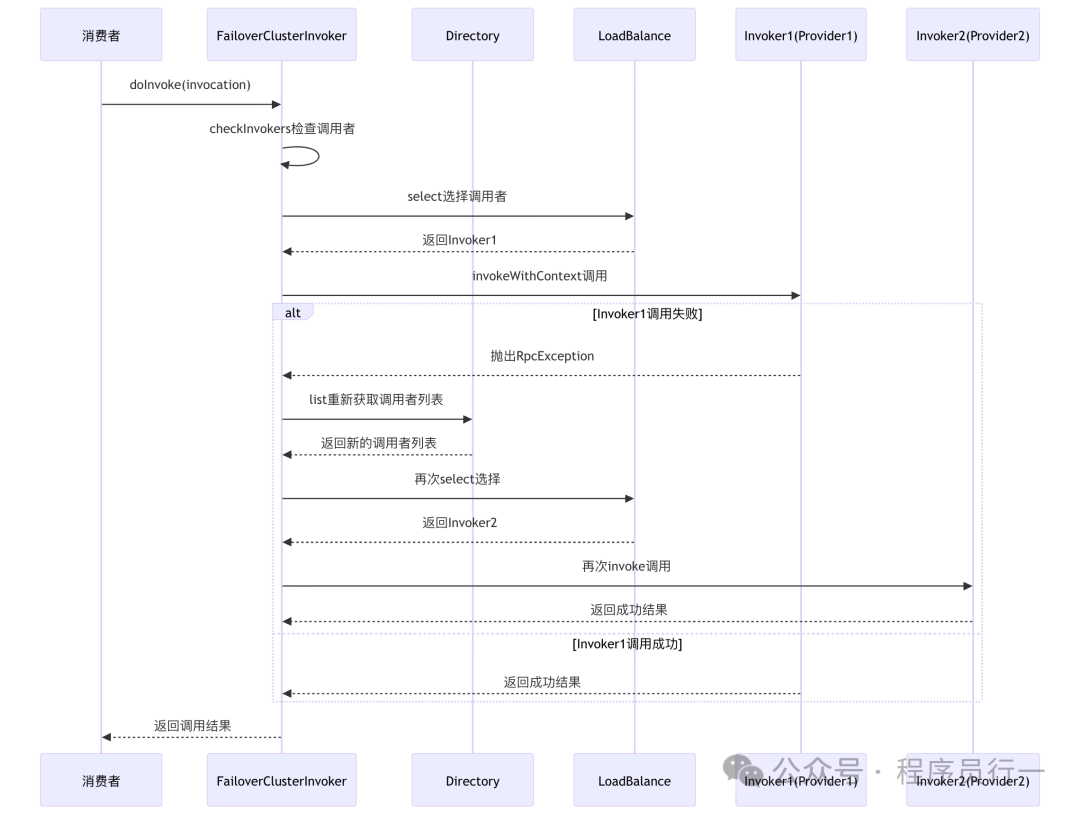
上图的序列图清晰展示了其流程:消费者通过 FailoverClusterInvoker 发起调用,经过目录服务和负载均衡选择后,调用 Provider1。如果失败,会重新获取可用列表,再次选择并调用 Provider2,直至成功或达到重试上限。
源码分析 (FailoverClusterInvoker):
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
List<Invoker<T>> copyInvokers = invokers;
checkInvokers(copyInvokers, invocation);
// 获取重试次数,len = retries + 1
int len = getUrl().getMethodParameter(invocation.getMethodName(), Constants.RETRIES_KEY, Constants.DEFAULT_RETRIES) + 1;
if (len <= 0) {
len = 1;
}
RpcException le = null;
// 记录已调用过的Invoker,避免重复调用
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size());
Set<String> providers = new HashSet<String>(len);
// 重试循环
for (int i = 0; i < len; i++) {
// 非首次调用时,重新获取服务列表,检查可用性
if (i > 0) {
checkStickyInvoker(providers, copyInvokers);
copyInvokers = list(invocation);
checkInvokers(copyInvokers, invocation);
}
// 根据负载均衡选择invoker
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
invoked.add(invoker);
providers.add(invoker.getUrl().getAddress());
try {
// 发起调用
Result result = invoker.invoke(invocation);
// 如果之前有失败但本次成功,记录警告日志
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + invocation.getMethodName() + " in the service " + getInterface().getName() + " was successful by the provider " + invoker.getUrl().getAddress() + ", but there have been failed providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), le);
}
return result; // 调用成功,直接返回
} catch (RpcException e) {
// 业务异常直接抛出,不重试
if (e.isBiz()) {
throw e;
}
le = e; // 记录非业务异常,用于后续重试或最终抛错
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
}
}
// 所有重试都失败,抛出包含详细信息的异常
throw new RpcException(le.getCode(), "Failed to invoke the method " + invocation.getMethodName() + " in the service " + getInterface().getName() + ". Tried " + len + " times of the providers " + providers + " (" + providers.size() + "/" + copyInvokers.size() + ") from the registry " + directory.getUrl().getAddress() + " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version " + Version.getVersion() + ". Last error is: " + le.getMessage(), le);
}
Failfast:快速失败
适用场景:非幂等性写操作,如支付、下单。
特点:性能高,但一次失败即告终,可靠性相对较低。
Failfast 策略非常“干脆”:它只进行一次调用,一旦失败(非业务异常)就立即抛出异常,不给任何重试的机会。这能有效避免因重试导致的重复执行等数据不一致问题。
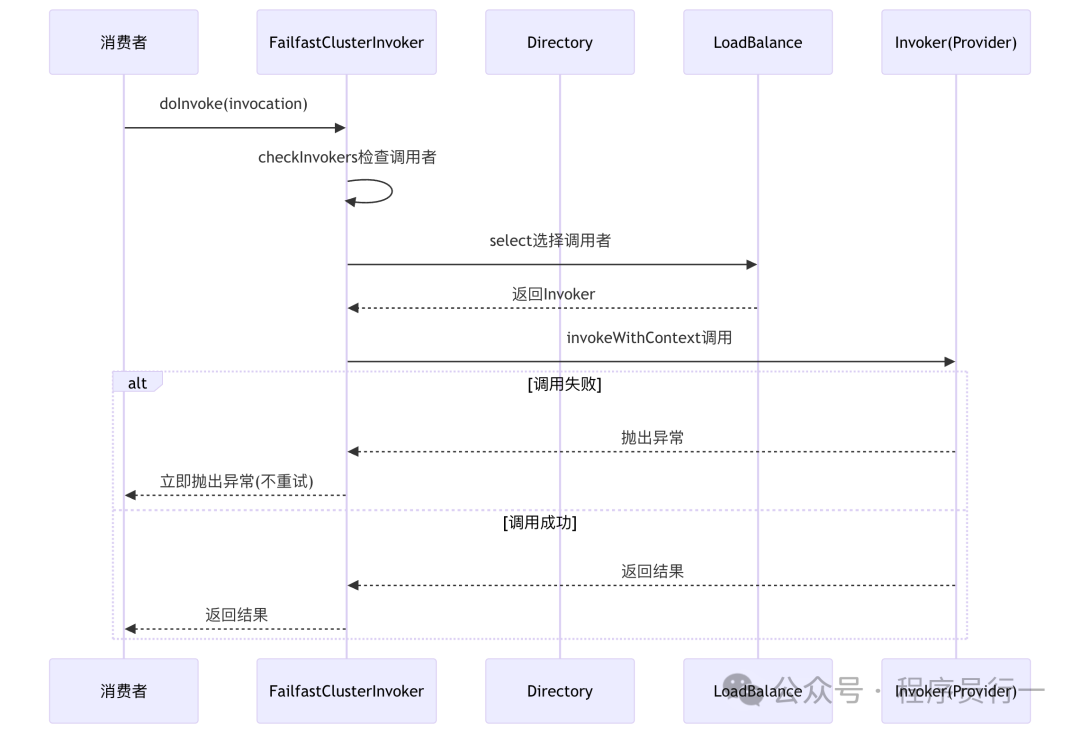
源码分析 (FailfastClusterInvoker):
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
checkInvokers(invokers, invocation);
// 选择一個Invoker
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
try {
// 发起调用,一锤子买卖
return invoker.invoke(invocation);
} catch (Throwable e) {
// 异常抛出
if (e instanceof RpcException && ((RpcException) e).isBiz()) {
throw (RpcException) e;
}
// 包装并抛出非业务异常
throw new RpcException(e instanceof RpcException ? ((RpcException) e).getCode() : 0, "Failfast invoke providers " + invoker.getUrl() + " " + loadbalance.getClass().getSimpleName() + " select from all providers " + invokers + " for service " + getInterface().getName() + " method " + invocation.getMethodName() + " on consumer " + NetUtils.getLocalHost() + " use dubbo version " + Version.getVersion() + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e);
}
}
Failsafe:失败安全
适用场景:写入审计日志、非核心的统计信息同步等。
特点:调用永远不会失败(从调用方视角),但可能 silently 丢失数据或操作。
Failsafe 的策略是“息事宁人”。当调用出现任何异常时,它不会将异常抛给上游,而是默默地记录一条错误日志,然后返回一个空结果 (RpcResult)。这保证了即使某个非核心服务挂掉,也不会影响主业务流程。
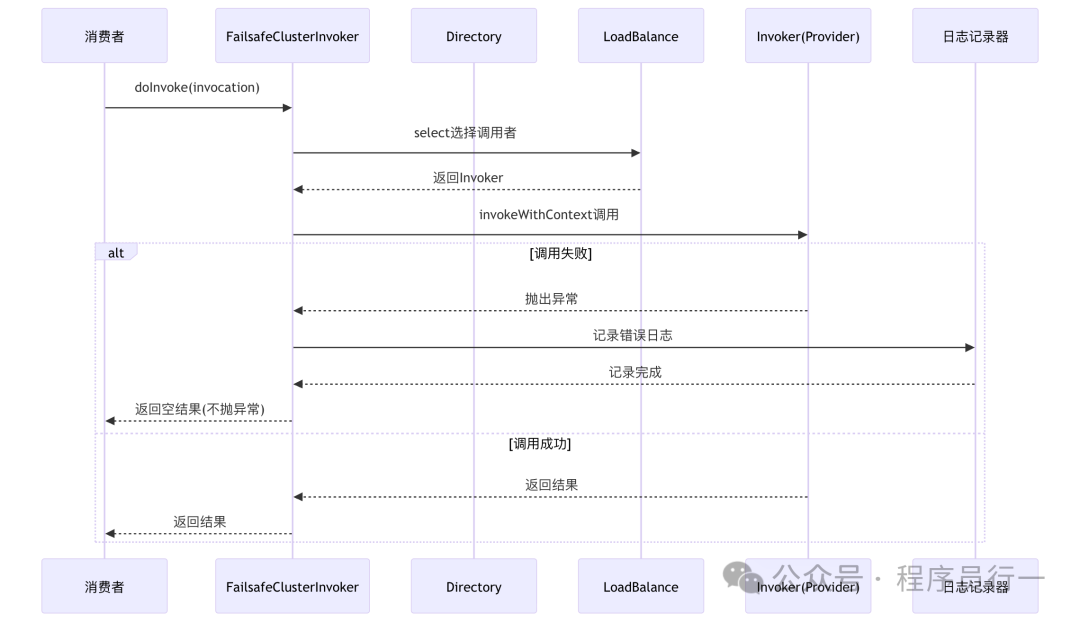
源码分析 (FailsafeClusterInvoker):
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
return invoker.invoke(invocation);
} catch (Throwable e) {
// 关键在这里:只记录日志,不抛出异常
logger.error("Failsafe ignore exception: " + e.getMessage(), e);
// 返回一个空结果,调用方感知不到失败
return new RpcResult();
}
}
Forking:并行调用
适用场景:对实时性要求极高的读操作,如金融产品的实时定价。
特点:用资源换时间,消耗大,但延迟低。
Forking 策略非常“豪横”。它一次性地并行调用多个服务提供者(数量由 forks 参数指定),只要其中任何一个调用成功,就立即返回结果。这类似于我们常说的“备份请求”模式,能有效对冲个别节点的慢请求或网络抖动。
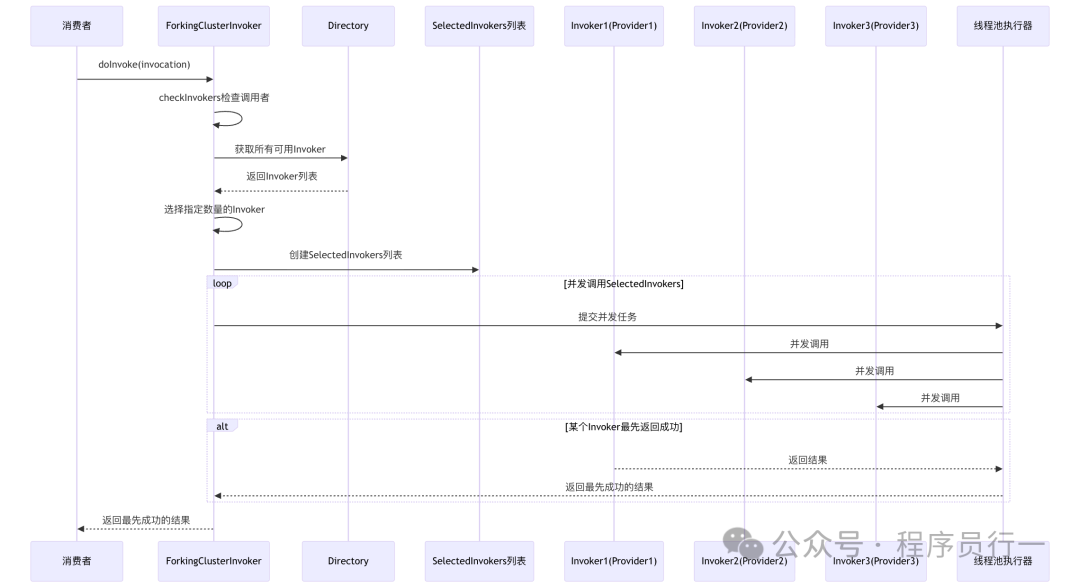
源码分析 (ForkingClusterInvoker):
public Result doInvoke(final Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
checkInvokers(invokers, invocation);
final int forks = getUrl().getParameter(Constants.FORKS_KEY, Constants.DEFAULT_FORKS);
final int timeout = getUrl().getParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
if (forks <= 0) {
return invokers.get(0).invoke(invocation);
}
// 1. 选择指定数量(forks)的Invoker
final List<Invoker<T>> selected = select(loadbalance, invocation, invokers, null);
final CountDownLatch latch = new CountDownLatch(selected.size());
final BlockingQueue<Result> results = new LinkedBlockingQueue<Result>();
// 2. 遍历选中的Invoker,提交并发任务
for (final Invoker<T> invoker : selected) {
executor.execute(new Runnable() {
@Override
public void run() {
try {
Result result = invoker.invoke(invocation);
results.add(result);
} catch (Throwable e) {
results.add(new RpcResult((Throwable) e));
} finally {
latch.countDown();
}
}
});
}
// 3. 等待第一个结果返回(超时控制)
try {
latch.await(timeout, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
throw new RpcException("Interrupted in forking invoke: " + e.getMessage(), e);
}
// 4. 从结果队列中取出第一个结果
Result result = results.poll();
if (result == null) {
result = new RpcResult(new MultipleException(results.toArray(new Throwable[results.size()])));
}
Throwable exception = result.getException();
if (exception == null) {
return result; // 成功返回
} else {
// 处理异常结果
if (exception instanceof RuntimeException) {
throw (RuntimeException) exception;
} else {
throw new RpcException("Failed to forking invoke provider " + selected + ", but no luck to perform the invocation. Last error is: " + exception.getMessage(), exception);
}
}
} catch (RpcException e) {
throw e;
} catch (Throwable e) {
throw new RpcException("Failed to forking invoke provider " + invokers + ", but no luck to perform the invocation. Last error is: " + e.getMessage(), e);
}
}
Failback:失败自动恢复
适用场景:可靠性要求特别高的通知类操作,如短信发送失败后的重发。
特点:保证最终成功,但实时性差,依赖后台重试机制。
Failback 策略颇有“锲而不舍”的精神。当调用失败时,它不会立即告诉调用方失败,而是将这次调用请求信息记录到一个失败队列中,然后立即返回一个空结果给调用方。与此同时,一个后台定时任务会周期性地扫描这个队列,取出失败的请求重新发起调用,直到成功为止。
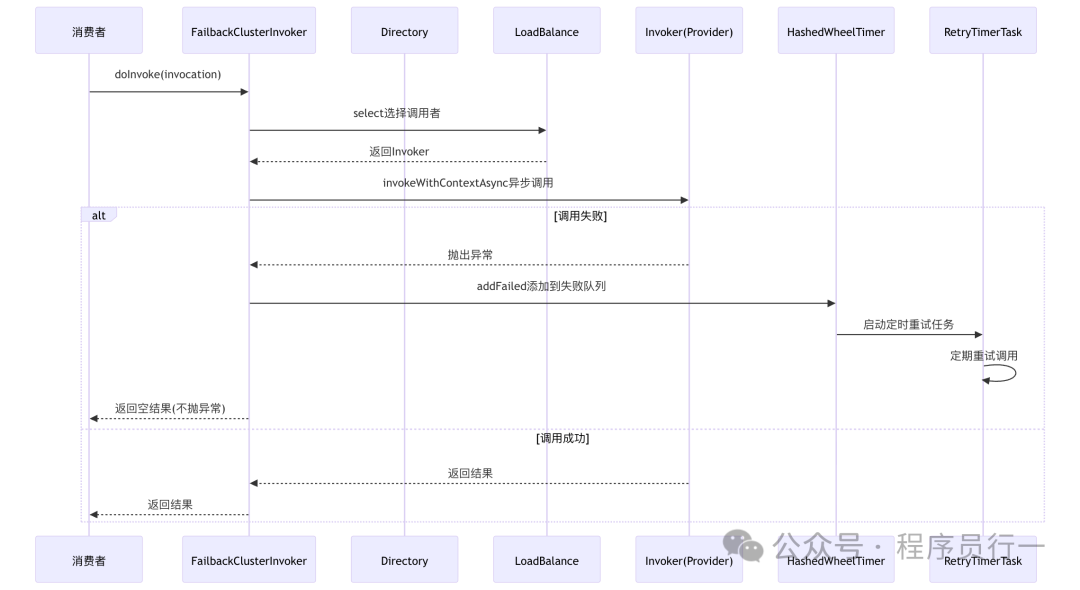
源码分析 (FailbackClusterInvoker 核心部分):
public Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
try {
Invoker<T> invoker = select(loadbalance, invocation, invokers, null);
return invoker.invoke(invocation);
} catch (Throwable e) {
// 调用失败,记录错误日志
logger.error("Failback to invoke method " + invocation.getMethodName() + ", wait for retry in background. Ignored exception: " + e.getMessage(), e);
// 关键步骤:将失败调用加入重试队列
addFailed(invocation);
// 向调用方返回空结果,不抛出异常
return new RpcResult();
}
}
private void addFailed(Invocation inv) {
// 通常用一个Map或Queue来存储失败请求和失败时间
failed.put(inv, System.currentTimeMillis());
}
// 定时任务调用的重试方法
private void retryFailed() {
if (failed.size() == 0) {
return;
}
List<Invocation> faileds = new ArrayList<Invocation>();
synchronized (failed) {
// 找出达到重试时间的失败请求
for (Map.Entry<Invocation, Long> entry : failed.entrySet()) {
long time = entry.getValue();
if ((System.currentTimeMillis() - time) >= retryPeriod) {
faileds.add(entry.getKey());
}
}
for (Invocation inv : faileds) {
failed.remove(inv);
}
}
// 遍历并重试
for (Invocation inv : faileds) {
try {
Invoker<T> invoker = select(loadbalance, inv, invokers, null);
invoker.invoke(inv);
logger.info("Retry to invoke method " + inv.getMethodName() + " success.");
} catch (Throwable e) {
logger.error("Retry to invoke method " + inv.getMethodName() + " fail, ignore this invocation.", e);
// 重试失败,再次加回队列,等待下次重试
addFailed(inv);
}
}
}
总结与展望
通过对 Dubbo 五种核心集群容错策略的源码分析,我们可以清晰地看到,每种策略都是为了解决特定场景下的高可用问题而设计的。Failover 通过重试提升成功率,Failfast 通过快速失败保障数据一致性,Failsafe 通过静默处理保证流程不中断,Forking 通过并行调用降低延迟,Failback 通过后台重试确保最终成功。
理解这些策略的底层实现,有助于我们在实际微服务架构中做出更精准的抉择。例如,在商品查询服务上配置 Failover,在创建订单服务上配置 Failfast,在发送营销短信服务上配置 Failback。同时,结合 RPC 框架的负载均衡、服务降级等功能,能够构建出弹性十足、韧性极高的分布式系统。
技术的选择永远服务于业务。希望这篇深入源码的解析,能帮助你更好地理解 Dubbo 集群容错这架精密“保险装置”的工作原理,从而在你的系统中更自如地运用它们,构建出真正可靠的服务。如果你想深入探讨更多微服务架构的实践,欢迎来 云栈社区 交流分享。
 发表于 2026-1-30 00:09:18
|
查看: 197|
回复: 0
发表于 2026-1-30 00:09:18
|
查看: 197|
回复: 0
