
自 2024 年 LiteRT 问世以来,其目标就很明确:将机器学习技术栈从 TensorFlow Lite (TFLite) 的基础演进为一个真正现代化的端侧 AI 框架。TFLite 为传统移动端机器学习铺平了道路,而我们的使命是让开发者能够同样轻松地在设备上部署当下最前沿的 AI,例如大语言模型。
在 2025 Google I/O 大会上,我们初步展示了这一演进的成果:一个为先进硬件加速设计的高性能运行时。现在,我们正式宣布,这些强大的加速能力已全面融入 LiteRT 的生产级技术栈中,对所有开发者开放。
这一里程碑标志着 LiteRT 作为 AI 时代的通用端侧推理框架,相比于 TFLite 实现了质的飞跃。具体优势体现在:
- 更快:提供比 TFLite 快 1.4 倍的 GPU 性能,并首次引入了最先进的 NPU 加速支持。
- 更简单:为跨平台的 GPU 和 NPU 加速提供了统一、简化的工作流程。
- 更强大:支持热门的开放模型(如 Gemma),实现了卓越的跨平台生成式 AI 部署能力。
- 更灵活:通过无缝的模型转换,提供一流的 PyTorch/JAX 支持。
在交付所有这些创新功能的同时,我们依然延续了自 TFLite 时代起就备受信赖的可靠性与跨平台部署体验。继续阅读,深入了解 LiteRT 将如何帮你构建下一代端侧 AI 应用。
高性能跨平台 GPU 加速
除了在 Google I/O 上宣布的 Android GPU 加速初步支持,我们现在很高兴地宣布,LiteRT 已在 Android、iOS、macOS、Windows、Linux 和 Web 上提供了全面、综合的 GPU 支持。这一扩展为开发者提供了一个可靠的高性能加速选项,其性能潜力远超传统的 CPU 推理。
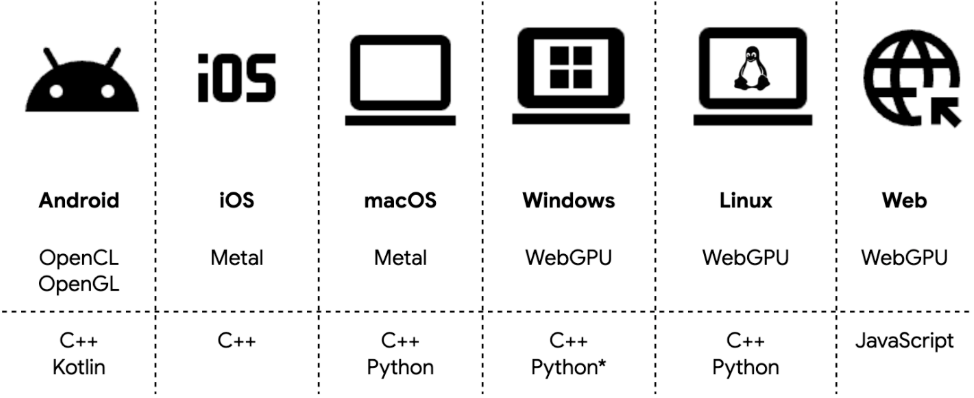
Python 上的 Windows WebGPU 即将推出。
LiteRT 通过 ML Drift 引入了对 OpenCL、OpenGL、Metal 和 WebGPU 的强大支持,最大限度地扩展了硬件覆盖范围,让你能在移动端、桌面端和 Web 端高效部署模型。在 Android 上,LiteRT 会智能地优先使用可用的 OpenCL 以达到峰值性能,同时保留 OpenGL 支持以确保更广泛的设备兼容性。
在 ML Drift 的加持下,LiteRT GPU 在效率上实现了显著提升,相比传统的 TFLite GPU 委托,平均带来了 1.4 倍 的性能提升,显著降低了各种模型的延迟。
为了实现高性能 AI 应用,我们还引入了关键的技术升级来优化端到端延迟,特别是异步执行和零拷贝缓冲区互操作性。这些功能大幅减少了不必要的 CPU 开销,提升了整体性能,满足了背景分割、语音识别等实时应用的严苛要求。正如我们的分割示例应用所展示的,这些优化可以带来高达 2 倍 的性能提升。
以下示例演示了如何在 C++ 中使用新的 CompiledModel API 轻松利用 GPU 加速:
// 1. Create a compiled model targeting GPU in C++.
auto compiled_model = CompiledModel::Create(env, "mymodel.tflite",
kLiteRtHwAcceleratorGpu);
// 2. Create an input TensorBuffer that wraps the OpenGL buffer (i.e. from
image pre-processing) with zero-copy.
auto input_buffer = TensorBuffer::CreateFromGlBuffer(env, tensor_type,
opengl_buffer);
std::vector<TensorBuffer> input_buffers{input_buffer};
auto output_buffers = compiled_model.CreateOutputBuffers();
// 3. Execute the model.
compiled_model.Run(inputs, outputs);
// 4. Access model output, i.e. AHardwareBuffer.
auto ahwb = output_buffer[0]->GetAhwb();
简化 NPU 集成,释放峰值性能
虽然 CPU 和 GPU 为 AI 任务提供了通用性,但 NPU 才是实现现代应用所需流畅、高速 AI 体验的关键。然而,数百种 NPU SoC 变体带来的碎片化问题,常常迫使开发者陷入由不同编译器和运行时组成的“迷宫”。传统的机器学习基础设施也缺乏与专用 NPU SDK 的深度集成,导致部署流程复杂且难以管理。
LiteRT 通过提供统一、简化的 NPU 部署工作流程来应对这些挑战。它抽象了底层的、供应商专用的 SDK,并处理了不同 SoC 变体间的碎片化问题。我们将整个流程简化为三个步骤:
- 针对目标 SoC 进行 AOT 编译(可选):使用 LiteRT Python 库为目标 SoC 预编译你的
.tflite 模型。
- 通过 Google Play for On-device AI (PODAI) 部署(Android 专用):借助 PODAI 服务,自动将模型文件及运行时环境分发至兼容设备。
- 使用 LiteRT 运行时进行推理:LiteRT 自动处理 NPU 委托,并在需要时提供到 GPU 或 CPU 的稳健回退机制。
为了满足不同部署需求,LiteRT 提供了提前编译 (AOT) 和端侧即时编译 (JIT) 两种灵活的集成选项:
- AOT 编译:最适合在已知目标 SoC 上部署复杂模型。它能最大限度地降低启动时的初始化耗时和内存占用,实现“即时启动”的体验。
- JIT 编译:最适合在各种平台上分发小型模型。它无需预先准备,尽管首次运行的初始化成本较高。
我们正与业界领先的芯片制造商紧密合作。目前,与联发科 (MediaTek) 和高通 (Qualcomm) 的首批生产就绪型集成方案已正式推出,能够实现业界领先的 NPU 性能,速度比 CPU 快 100 倍,比 GPU 快 10 倍。我们也在积极将 NPU 支持拓展至更广泛的硬件生态。
卓越的跨平台 GenAI 支持
开放模型提供了无与伦比的灵活性和定制能力,但部署它们的过程往往充满挑战。处理模型转换、推理和基准测试的复杂性通常需要大量工程工作。为了弥合这一差距,我们提供了以下集成技术栈:
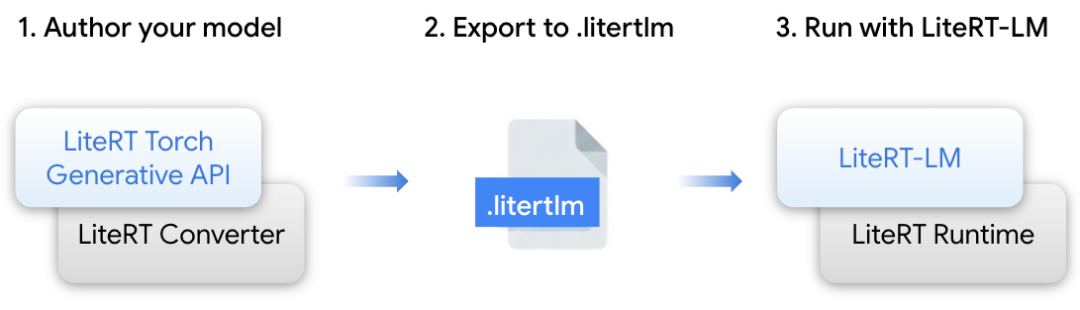
- LiteRT Torch Generative API:一个 Python 模块,旨在实现基于 Transformer 的 PyTorch 模型的创作和转换,使其适配 LiteRT/LiteRT-LM 格式。它提供了优化的构建模块,确保在边缘设备上的高性能执行。
- LiteRT-LM:一个构建在 LiteRT 之上的专用编排层,用于管理大语言模型特有的复杂性。它是为 Google 产品(包括 Chrome 和 Pixel Watch)提供 Gemini Nano 部署支持的、经过实战检验的基础设施。
- LiteRT 转换器与运行时:这一基础引擎提供了高效的模型转换、运行时执行和优化,为跨 CPU、GPU 和 NPU 的高级硬件加速赋能。
这些组件共同为运行热门开放模型提供了一条具有领先性能的生产级路径。我们在 Samsung Galaxy S25 Ultra 上对 Gemma 3 1B 进行了基准测试,并与 Llama.cpp 进行了对比。
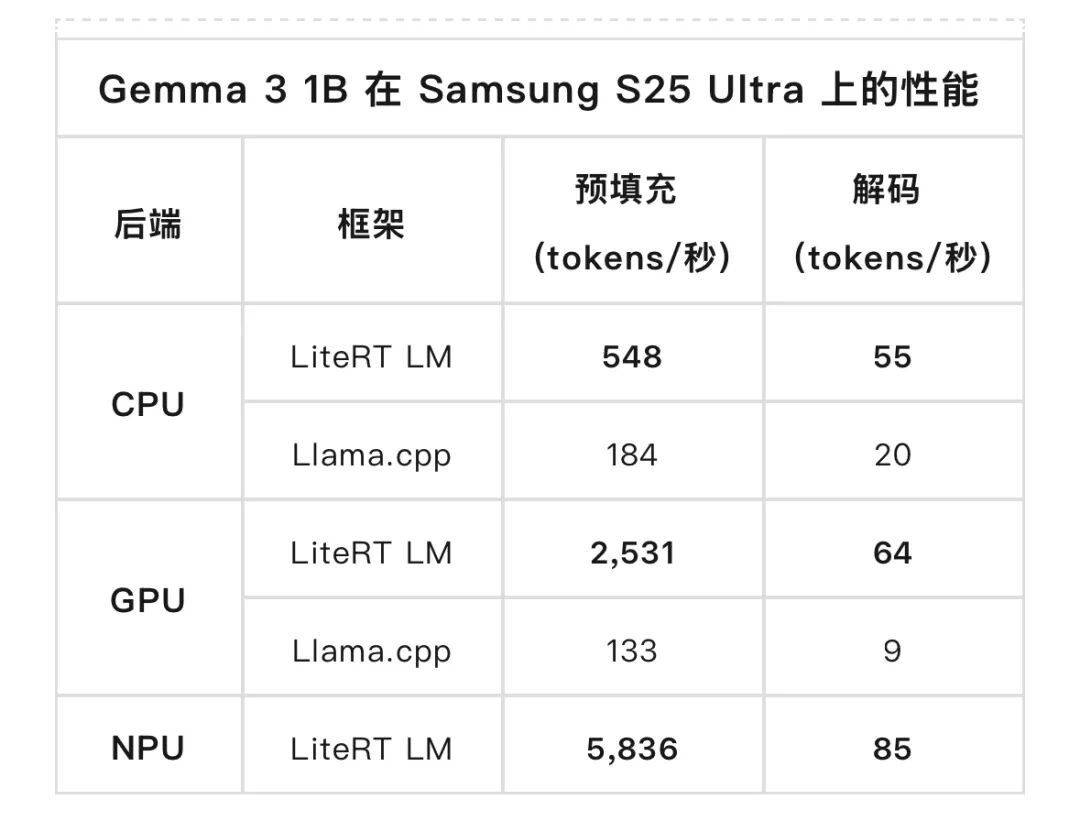
LiteRT 展现出了明显的性能优势。在解码阶段(内存密集型),它在 CPU 上比 llama.cpp 快 3 倍,在 GPU 上快 7 倍;在预填充阶段(计算密集型),它在 GPU 上快 19 倍。此外,LiteRT 的 NPU 加速在预填充阶段比 GPU 额外提升了 2 倍 性能。
LiteRT 支持广泛且持续增长的主流开放权重模型,这些模型经过精心优化和预转换,可立即部署,包括:
- Gemma 模型系列:Gemma 3 (270M、1B)、Gemma 3n、EmbeddingGemma 和 FunctionGemma。
- Qwen、Phi、FastVLM 等。
这些模型可以在 LiteRT Hugging Face 社区 获取,并通过 Android 和 iOS 上的 Google AI Edge Gallery 应用进行交互式探索。
广泛的机器学习框架支持
部署不应受限于你选用的训练框架。LiteRT 提供来自业界最主流机器学习框架的无缝模型转换:PyTorch、TensorFlow 和 JAX。

- PyTorch 支持:借助 AI Edge Torch 库,你可以通过一个简化的步骤将 PyTorch 模型直接转换为
.tflite 格式。这确保了基于 PyTorch 的架构能立即充分利用 LiteRT 的高级硬件加速,无需复杂的中间转换。
- TensorFlow 和 JAX:LiteRT 持续为 TensorFlow 生态系统提供强大的一流支持,并通过 jax2tf 桥接工具为 JAX 模型提供可靠的转换路径。
通过整合这些路径,无论你的开发环境如何,LiteRT 都能支持从研究到生产的快速实现。你可以在首选框架中构建模型,并依赖 LiteRT 在 CPU、GPU 和 NPU 后端上实现卓越的性能交付。
值得信赖的可靠性和兼容性
尽管 LiteRT 的能力已显著扩展,但我们对长期可靠性和跨平台一致性的承诺保持不变。LiteRT 继续建立在久经考验的 .tflite 模型格式之上,这是一种行业标准的单文件格式,确保了你现有的模型在 Android、iOS、macOS、Linux、Windows、Web 和 IoT 上保持可移植性和兼容性。
为了向开发者提供持续的体验,LiteRT 为现有和下一代推理路径提供了强大的支持:
- Interpreter API:你现有的生产模型将继续可靠运行,保持你所依赖的广泛设备覆盖范围和稳定性。
- 新的 CompiledModel API:这个现代化接口专为下一代 AI 设计,提供了无缝路径来释放 GPU 和 NPU 加速 的全部潜力,以满足日益演进的新 AI 需求。
开始使用 LiteRT
准备好构建端侧 AI 的未来了吗?你可以通过以下资源轻松上手:
- 探索 LiteRT 文档 以获取全面的开发指南。
- 查看 LiteRT GitHub 和 LiteRT 示例 GitHub 以获取示例代码和实现细节。
- 访问 LiteRT Hugging Face 社区 以获取 Gemma 等即用型开放模型,并在 Android 和 iOS 上试用 Google AI Edge Gallery 应用 来亲身体验。
- 也欢迎来 云栈社区 的技术板块与其他开发者交流端侧AI的实践经验。
我们迫不及待地想看到你用 LiteRT 创造出的精彩内容!
 发表于 2026-1-31 03:32:27
|
查看: 188|
回复: 0
发表于 2026-1-31 03:32:27
|
查看: 188|
回复: 0
