最近我们在持续优化一个需要处理10万Socket连接的项目。由于加密操作非常频繁,所以加密方案的性能优化一直是我们的重点。此前我们已经完成了几个优化版本,主要针对内存分配和整体性能。今天,我们将继续深挖,对CPU计算消耗进行更极致的优化。
今天的方案核心思路是:将原本逐字节(byte)操作的循环,改写为以 uint64 为单位的块操作。基准测试显示性能提升了约18%,但通过 perf 采样分析汇编代码时,却发现有近9%的CPU时间似乎“空转”在内存加载指令上。这篇文章将记录一次从Go代码到汇编指令级别的性能调优过程,并揭示隐藏在寄存器背后的性能杀手。
相关代码
上一个优化版本方案(CryptBlocks03)
这是我们之前使用的、相对常规的CBC模式加密实现。
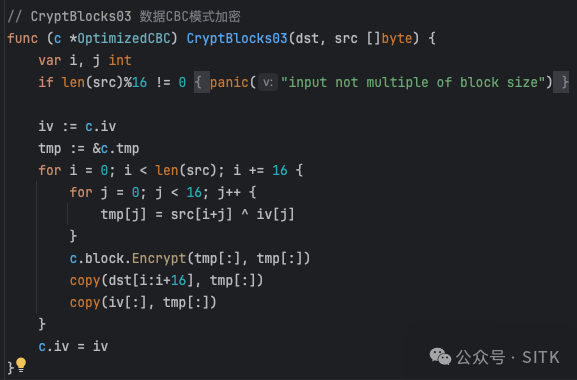
// CryptBlocks03 数据块CBC模式加密
func (c *OptimizedCBC) CryptBlocks03(dst, src []byte) {
var i, j int
if len(src)%16 != 0 {
panic("input not multiple of block size")
}
iv := c.iv
tmp := &c.tmp
for i = 0; i < len(src); i += 16 {
for j = 0; j < 16; j++ {
tmp[j] = src[i+j] ^ iv[j]
}
c.block.Encrypt(tmp[:], tmp[:])
copy(dst[i:i+16], tmp[:])
copy(iv[:], tmp[:])
}
c.iv = iv
}
本次优化的方案(CryptBlocks04)
这是我们本次尝试的优化版本,利用 unsafe.Pointer 进行指针操作和 uint64 块处理。
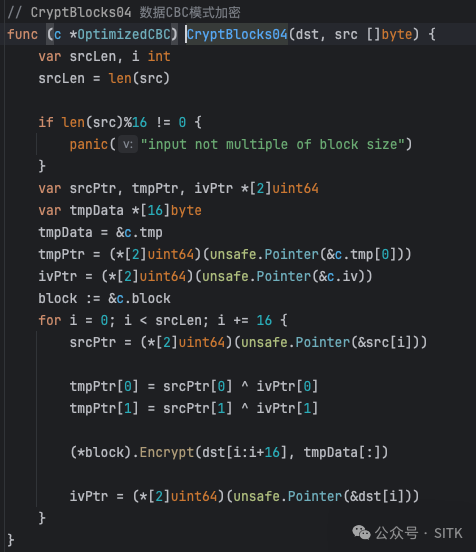
// CryptBlocks04 数据块CBC模式加密
func (c *OptimizedCBC) CryptBlocks04(dst, src []byte) {
var srcLen, i int
srcLen = len(src)
if len(src)%16 != 0 {
panic("input not multiple of block size")
}
var srcPtr, tmpPtr, ivPtr *[2]uint64
var tmpData *[16]byte
tmpData = &c.tmp
tmpPtr = (*[2]uint64)(unsafe.Pointer(&c.tmp[0]))
ivPtr = (*[2]uint64)(unsafe.Pointer(&c.iv))
block := &c.block
for i = 0; i < srcLen; i += 16 {
srcPtr = (*[2]uint64)(unsafe.Pointer(&src[i]))
tmpPtr[0] = srcPtr[0] ^ ivPtr[0]
tmpPtr[1] = srcPtr[1] ^ ivPtr[1]
(*block).Encrypt(dst[i:i+16], tmpData[:])
ivPtr = (*[2]uint64)(unsafe.Pointer(&dst[i]))
}
}
结果验证
为了验证新版本的功能正确性,我们编写了测试函数。
基本函数与测试调用
func main() { Test01() }
func Test01() {
var err error
var resultData []byte
var testPass, testData []byte
testPass = []byte("123456788765453211234567887654321")
testData = []byte(`fmt.Printf("Test1123456788765432134 Normal123456788AesEncrypt")
fmt.Println("Test1123456788765432134 Normal123456788AesEncrypt")`)
err, resultData = NormalAesEncrypt(testPass, testData)
fmt.Println("TestAes Encrypt:", err, resultData)
err, resultData = NormalAesDecrypt(testPass, resultData)
fmt.Println("TestAes Decrypt:", err, string(resultData))
fmt.Println("=================")
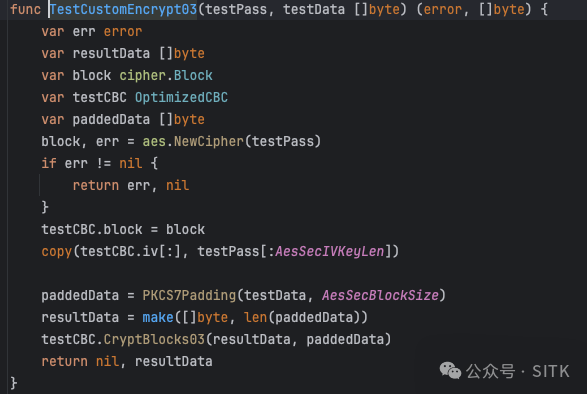
err, resultData = TestCustomEncrypt03(testPass, testData)
fmt.Println("TestCustomEncrypt03:", err, string(resultData))
err, resultData = TestCustomEncrypt04(testPass, testData)
fmt.Println("TestCustomEncrypt04:", err, resultData)
}
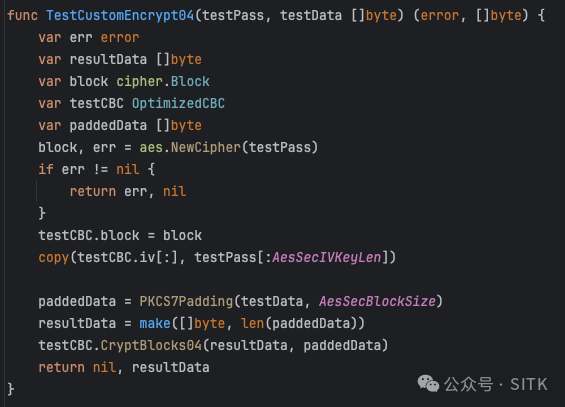
基准测试函数
功能测试结果
运行测试程序,加密和解密结果符合预期,表明新版本的逻辑是正确的。

性能测试
测试环境
首先确认测试的Go环境与系统硬件信息。
性能测试结果
使用 go test -bench 进行基准测试,结果如下:
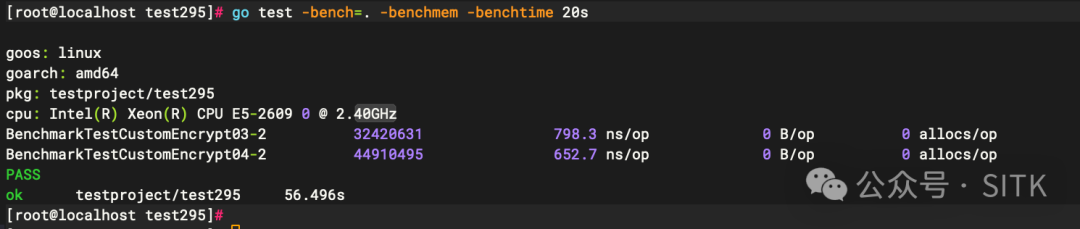
BenchmarkTestCustomEncrypt03-2 324240631 798.3 ns/op 0 B/op 0 allocs/op
BenchmarkTestCustomEncrypt04-2 44910495 652.7 ns/op 0 B/op 0 allocs/op
从数据上看,优化效果显著。CryptBlocks04 相比 CryptBlocks03 单次调用耗时从 798.3 ns 降到了 652.7 ns,节省了约 146 ns,性能提升约 18.3%。对于纯CPU密集的加密操作,这是一个非常可观的提升。但这是性能的尽头吗?让我们继续深入分析。
优化说明
CryptBlocks03 的问题
CryptBlocks03 采用了朴素且稳定的逐字节异或方式。但在追求极致性能的场景下,这种细粒度的操作会带来显著的CPU开销。
其核心热点在于内层的 for j 循环,需要执行16次 byte 级别的读取、异或和写入操作,并伴随循环变量的递增和条件判断,这在汇编层面会产生大量指令。
CryptBlocks04 的优化思路
为了突破瓶颈,我们转换了思路:既然CBC的块大小是16字节,正好等于两个 uint64(8字节 * 2),为什么不直接以 uint64 为单位进行处理?我们借助 unsafe.Pointer 这一“黑科技”实现了以下关键优化:
- 逻辑优化:将16次
byte 异或,压缩为2次 uint64 异或。
- 指令减少:理论上,CPU需要执行的指令数量直接下降了一个数量级。
测试结果也证实了这一点:652 ns/op,性能瞬间提升18.3%。然而,当我们打开 perf 性能分析工具查看热点时,故事才刚刚开始。
根因分析
CryptBlocks03 的性能瓶颈分析
瓶颈并非来自AES加密算法本身,而是“准备数据”的过程。
1. 最大热点:字节级 XOR 内循环
代码:tmp[j] = src[i+j] ^ iv[j]
对应的perf热点汇编片段显示,这是一个典型的对CPU不友好的写法:每次循环都要进行零扩展移动(movzbl)、异或(xor)、回写,并伴随着循环计数器(inc)和条件跳转(cmp/jge)。
2. copy(dst, tmp) + iv 回写开销
每次循环有两次 copy 操作,将16字节数据从临时数组复制到目标数组和初始化向量(IV)中。perf 显示这部分存在内存搬运(movups)开销。
3. Encrypt 调用被淹没
实际的AES加密调用 c.block.Encrypt 在热点中的占比反而很低,说明前期数据准备的开销完全掩盖了核心计算。
CryptBlocks04 的关键优化点
1. uint64 × 2 批量 XOR(核心提升)
代码使用两个 uint64 指针直接进行异或:
tmpPtr[0] = srcPtr[0] ^ ivPtr[0]
tmpPtr[1] = srcPtr[1] ^ ivPtr[1]
对应的汇编只有两条 mov/xor/mov 序列,一次循环完成16字节异或,指令数急剧下降。
2. 完全消灭内层 j 循环
没有了 inc、cmp、jge 等指令,也消除了内层循环可能引发的边界检查(panicIndex)路径。这使得控制流极其简单,分支预测命中率极高,对CPU流水线非常友好。
3. Encrypt 直接写 dst,IV 零拷贝更新
(*block).Encrypt(dst[i:i+16], tmpData[:])
ivPtr = (*[2]uint64)(unsafe.Pointer(&dst[i]))
加密结果直接写入目标切片,避免了 tmp → dst 的拷贝。同时,IV指针直接重绑定到 dst 的相应位置,实现了“零拷贝”更新,减少了一次16字节的内存搬运。
4. 边界检查被“挤到边缘”
perf 热点中几乎看不到 panicSlice 或 panicIndex 的踪迹,说明Go编译器在主循环路径上成功消除了大量的边界检查。
两个版本差异总结
下表清晰地展示了两版实现的差异:
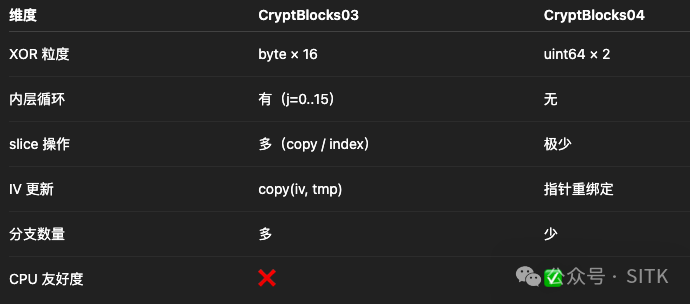
CryptBlocks04 的性能优势并非来自加密算法本身的优化,而是数据路径的优化:通过 unsafe.Pointer 结合 uint64 批量运算,显著减少了指令数量、分支判断和内存访问次数,让CPU能更专注、高效地执行AES-CBC的主循环。
与 Cache Line 有关吗?
我们常听到性能优化要关注CPU缓存行对齐。那么这次优化是因为 uint64 操作更好地对齐了缓存行吗?让我们用 perf 的数据来回答。
对两个版本分别进行更细致的性能计数器统计:
CryptBlocks03 的 perf stat 输出:
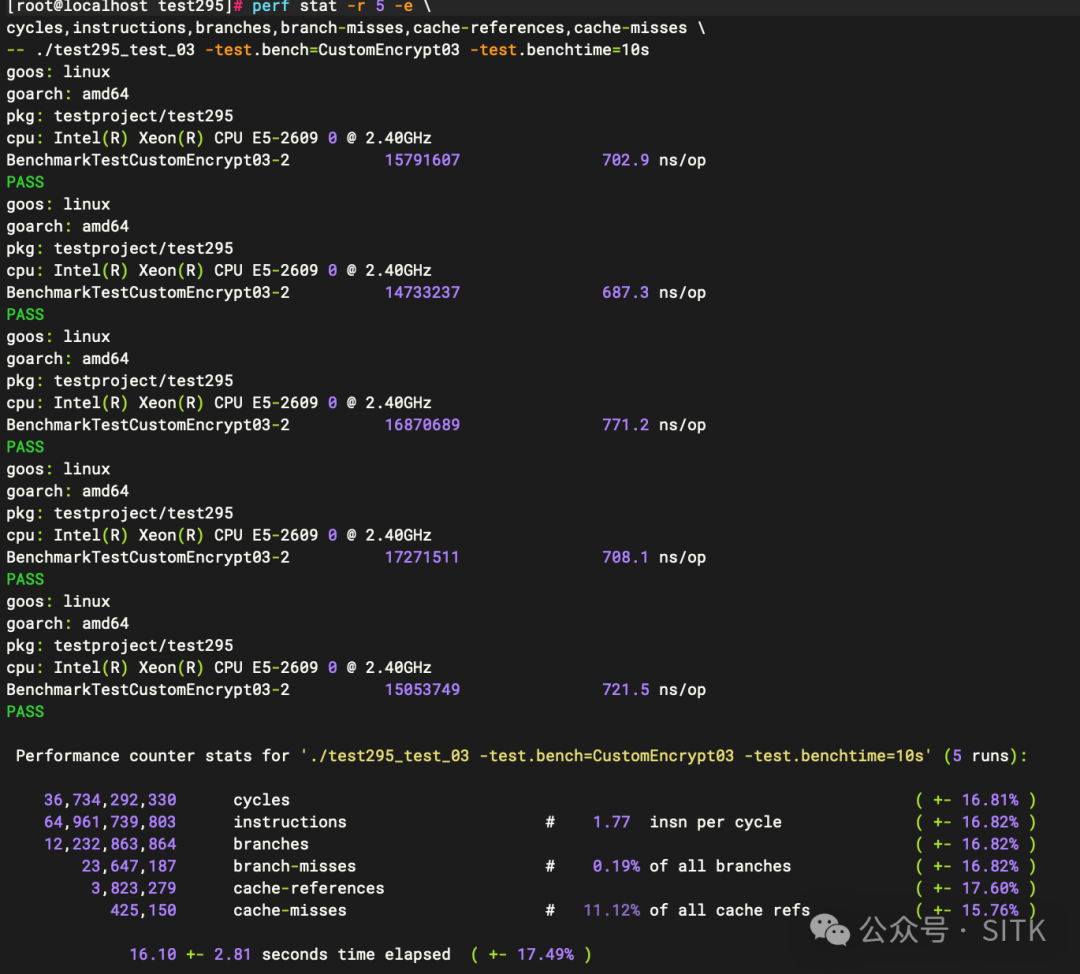
CryptBlocks04 的 perf stat 输出:
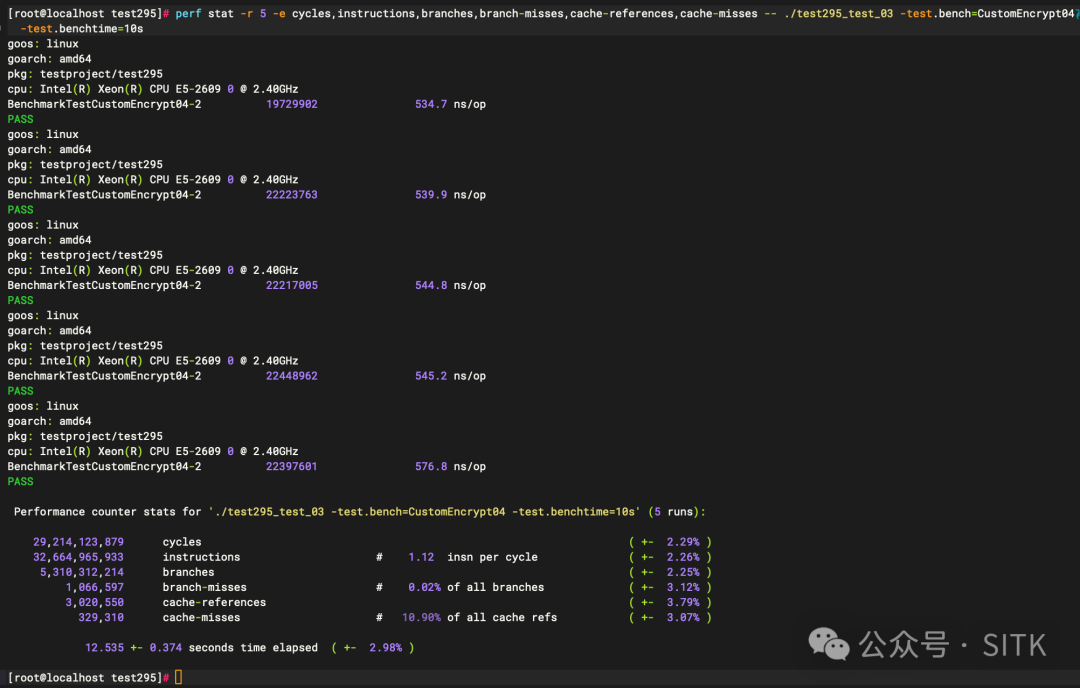
对比关键指标可以明确:本次性能提升基本与缓存行优化无关,而是纯粹由“指令数和控制流大幅减少”带来的计算收益。
1. 缓存相关指标对比
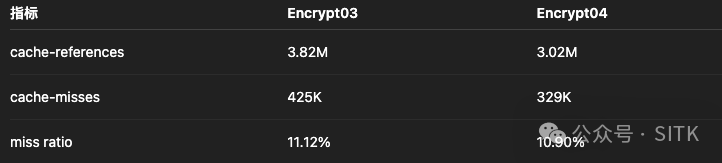
cache-references(缓存引用)和 cache-misses(缓存未命中)次数几乎不变,未命中率也高度一致。如果缓存行对齐起了作用,cache-misses 应有明显下降。
2. 真正的优化点:指令与分支
- 指令数腰斩:

CryptBlocks04 的指令数相比 CryptBlocks03 直接减少了约49.7%。
- 分支数锐减:

CryptBlocks04 的分支数减少56%,分支预测失败率也从0.19%下降到0.02%,说明控制流得到了极大简化。
“消失”的 8.79%:寄存器溢出的幽灵
通过 perf 观察 CryptBlocks04 的汇编热点,我们发现了一个有趣的现象:
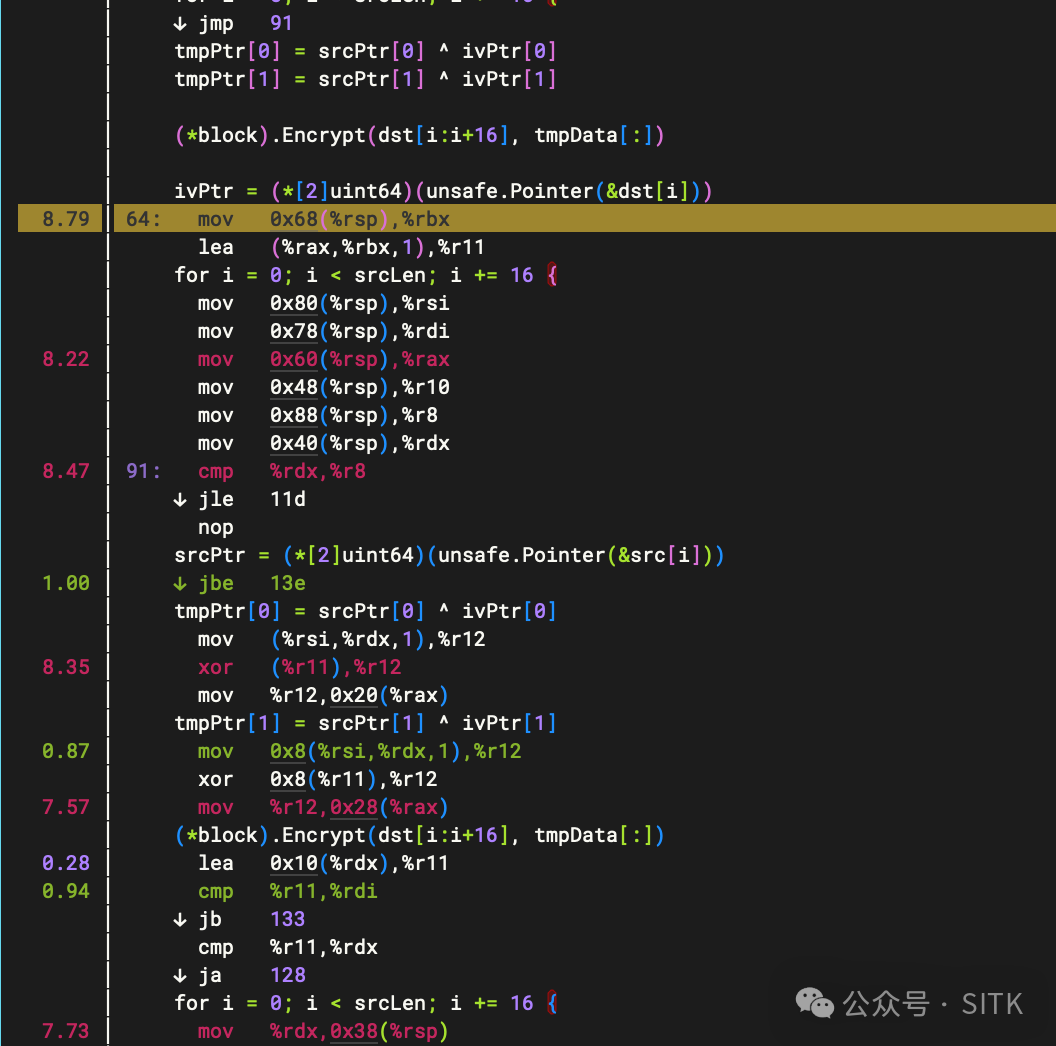
对应的热点指令是:
8.79% mov 0x68(%rsp), %rbx
8.22% mov 0x60(%rsp), %rax
为什么几条简单的、从栈上加载数据到寄存器的 MOV 指令,会占用近9%的CPU时间?
根本原因是 寄存器溢出 (Register Spilling)。由于加密循环内部调用了 (*block).Encrypt 这个方法调用(很可能无法内联),Go 编译器在分配寄存器时会变得非常保守。它不敢把所有循环中需要的变量(如指针、长度)都长期保留在有限的CPU寄存器中,生怕被函数调用破坏。
于是,编译器选择在每次循环迭代前,都将一些关键的指针值从寄存器“溢出”到函数栈帧的内存位置(如上所示的 0x68(%rsp))。在下次迭代或关键操作前,再通过 MOV 指令将它们从内存加载回寄存器。
这就导致了一个悖论:我们的计算逻辑变快了,但CPU却花了更多时间在“等待”或“搬运”这些本应待在寄存器里的数据上。就像给赛车换上了更强的引擎,但进出维修站的次数却莫名增加了。
结论与建议
CryptBlocks04 的性能提升本质是“让CPU少干活”,通过减少指令和分支,而非提升单指令效率或改善缓存。- 性能优化是一个系统工程,本次实践告诉我们:
- 避开细碎循环:用
uint64 或思考SIMD的方式处理连续内存,是消除计算瓶颈的有效起点。
- 警惕“内存屏障”:
unsafe 虽快,但可能让编译器更“谨慎”,引发意外的寄存器溢出,抵消部分优化收益。深入理解内存管理和编译器行为很重要。
- 认识模式局限:CBC模式因其串行依赖特性,单靠逻辑优化存在天花板,后续可考虑算法层面或并行化探索。
- 善用分析工具:
perf 是剖析 Go 程序性能的利器,它能带你直达汇编指令级的热点。虽然也可以直接附着到生产环境进程,但请务必谨慎使用。

性能调优就像魔法,既要大胆尝试“黑科技”,也要细致洞察编译器与CPU的“小心思”。希望这次从798ns到652ns,再到发现8.79%“幽灵”热点的旅程,能为你下一次的性能优化带来启发。欢迎在云栈社区分享你的极致优化案例与思考。
 发表于 2026-2-1 01:12:50
|
查看: 203|
回复: 0
发表于 2026-2-1 01:12:50
|
查看: 203|
回复: 0
