构建和部署基于大型语言模型(LLM)的应用充满挑战。模型输出的非确定性、可能产生的“幻觉”问题,以及在复杂多步调用中难以追踪的行为链路,都使得开发和运维变得困难。本文将介绍如何利用 Langfuse 这一开源平台,系统地解决这些问题,为您的 AI应用 提供坚实的可观测性、评估与提示词管理基础。
什么是 Langfuse?
Langfuse 是一个专为 LLM 应用设计的开源可观测性与评估平台。无论是简单的单次API调用,还是涉及复杂工具调用和多轮对话的智能体(Agent),Langfuse 都能完整追踪、可视化并调试从提示词输入到最终响应的全流程。
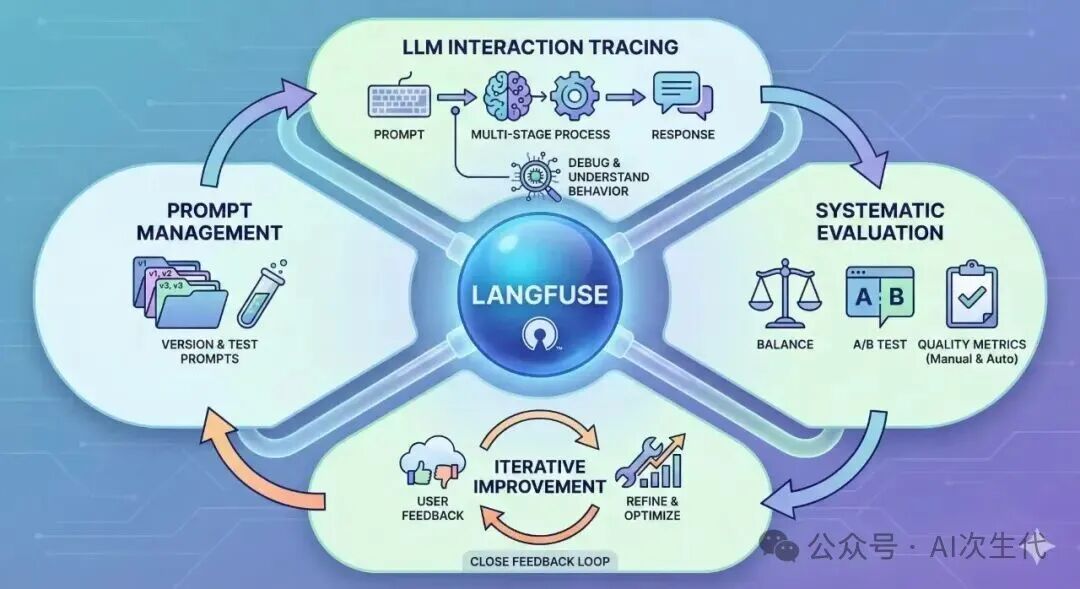
它不仅仅是一个日志工具,更提供了一套系统化的方法论来:
- 系统评估 LLM 性能:通过预定义指标衡量响应质量。
- A/B测试提示词:科学比较不同提示词版本的效果差异。
- 整合用户反馈:将用户评分与具体的LLM交互关联,形成改进闭环。
其核心价值在于为LLM应用开发带来前所未有的透明度,帮助开发者:
- 理解行为:清晰看到每次请求发送了哪些提示词、收到了什么响应,以及所有中间步骤。
- 快速排障:迅速定位错误、性能瓶颈或非预期输出的根源。
- 评估质量:通过手动标注或自动评估器,衡量LLM响应的有效性。
- 迭代优化:基于数据洞察,持续优化提示词、模型选择和应用逻辑。
- 管理提示词:对提示词进行版本控制、测试和部署,确保最佳效果。
核心功能
Langfuse 提供了一系列关键功能,构成其强大的能力支柱。
追踪与监控 (Tracing and Monitoring)
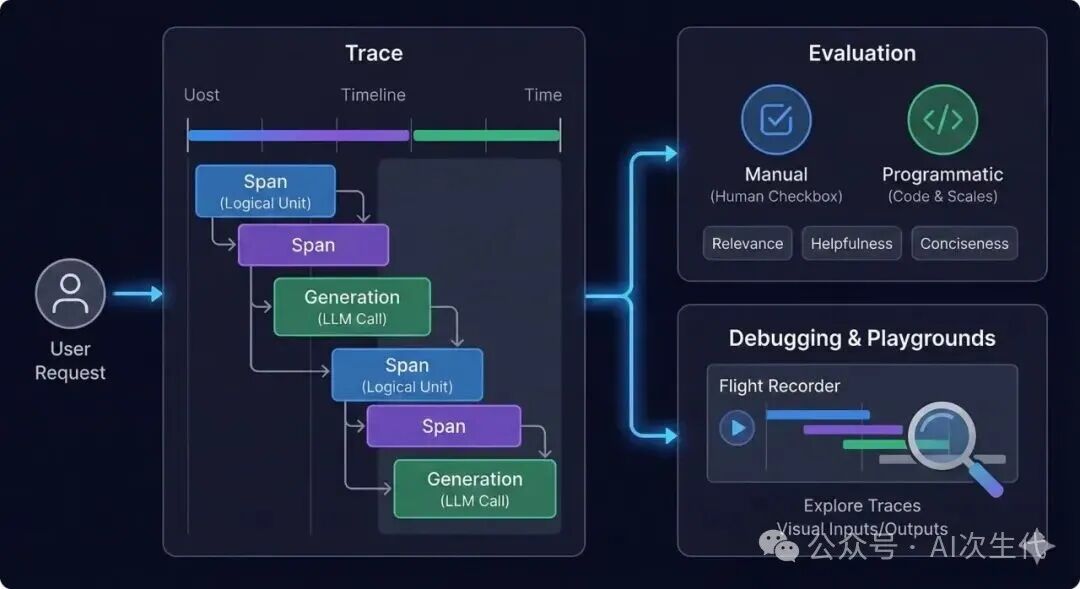
Langfuse 能捕获每次LLM交互的详细踪迹,其核心概念包括:
- 追踪 (Trace):代表一次完整的端到端用户请求或应用工作流。
- 区间 (Span):代表追踪中的一个逻辑工作单元,如工具调用、数据检索等。
- 生成 (Generation):特指对LLM的一次调用及其产生的输出。
评估 (Evaluation)
支持手动和编程式评估。开发者可以定义自定义指标,在不同数据集上运行评估,并可集成基于LLM的自动评估器。
提示词管理 (Prompt Management)
提供对提示词的中心化存储和版本控制。支持A/B测试以比较不同提示词的效果,并确保提示词在不同环境(如开发、生产)间的一致性,实现数据驱动的优化。
反馈收集 (Feedback Collection)
能够将用户评分或评论直接整合到追踪数据中。您可以将具体的反馈关联到产生该输出的精确LLM调用上,为问题排查和模型迭代提供实时依据。
解决了什么问题?
传统软件的可观测性工具在处理LLM应用时往往力不从心,主要痛点包括:
- 非确定性:相同输入可能产生不同输出,调试困难。Langfuse记录完整的输入/输出,还原现场。
- 提示词敏感性:微小改动可能导致结果巨变。Langfuse帮助跟踪提示词版本及其对应的性能指标。
- 复杂调用链:现代 微服务 与Agent架构涉及多次LLM调用、工具使用。Langfuse提供可视化的时间线,是理解流程、定位瓶颈的唯一途径。
- 主观质量:响应的“好坏”难以客观衡量。Langfuse同时支持客观指标(延迟、Token消耗)和主观评估(人工反馈、LLM评估)。
- 成本管理:LLM API调用按Token计费。Langfuse监控Token使用量和调用次数,助力成本分析与优化。
- 缺乏可见性:开发运维(DevOps)团队难以了解应用在生产环境中的真实表现,持续改进受阻。
Langfuse 将LLM应用的开发范式从试错转变为数据驱动、可迭代的工程实践。
Langfuse 实战示例
开始使用前,需安装客户端库并配置,将数据发送至您的Langfuse实例(云托管或自托管均可)。
安装 (Installation)
Langfuse 为 Python 和 JavaScript/TypeScript 提供了官方SDK。
Python 客户端:
pip install langfuse
JavaScript/TypeScript 客户端:
npm install langfuse
# 或者
yarn add langfuse
配置 (Configuration)
安装后,使用项目密钥和主机地址初始化客户端。这些信息可在 Langfuse 项目设置中找到。
public_key: 适用于前端应用或仅发送非敏感数据。secret_key: 适用于后端应用,需要完整可观测性(含敏感数据)。host: Langfuse 实例的URL(例如:https://cloud.langfuse.com)。environment: (可选) 用于区分环境(如:production, staging)。
建议通过环境变量配置,以确保安全性与灵活性:
export LANGFUSE_PUBLIC_KEY="pk-lf-..."
export LANGFUSE_SECRET_KEY="sk-lf-..."
export LANGFUSE_HOST="https://cloud.langfuse.com"
export LANGFUSE_ENVIRONMENT="development"
初始化客户端示例:
Python:
from langfuse import Langfuse
import os
langfuse = Langfuse(
public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"),
secret_key=os.environ.get("LANGFUSE_SECRET_KEY"),
host=os.environ.get("LANGFUSE_HOST")
)
JavaScript/TypeScript:
import { Langfuse } from "langfuse";
const langfuse = new Langfuse({
publicKey: process.env.LANGFUSE_PUBLIC_KEY,
secretKey: process.env.LANGFUSE_SECRET_KEY,
host: process.env.LANGFUSE_HOST
});
基础追踪 (Trace) 实践
在Langfuse中,追踪(Trace) 是可观测性的基本单位,通常代表一次独立的用户交互或请求生命周期。一个追踪内可包含多个LLM调用(生成)和计算步骤(区间)。
以下是一个使用OpenAI API的简单LLM调用追踪示例:
Python 示例:
import os
from openai import OpenAI
from langfuse import Langfuse
# 初始化客户端
langfuse = Langfuse(
public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"),
secret_key=os.environ.get("LANGFUSE_SECRET_KEY"),
host=os.environ.get("LANGFUSE_HOST"),
)
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def simple_llm_call_with_trace(user_input: str):
# 1. 启动一个新的追踪
trace = langfuse.trace(
name="simple-query",
input=user_input,
metadata={"user_id": "user-123", "session_id": "sess-abc"},
)
try:
# 2. 在追踪中创建一个“生成”
generation = trace.generation(
name="openai-generation",
input=user_input,
model="gpt-4o-mini",
model_parameters={"temperature": 0.7, "max_tokens": 100},
metadata={"prompt_type": "standard"},
)
# 3. 执行实际的 LLM 调用
chat_completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": user_input}],
temperature=0.7,
max_tokens=100,
)
response_content = chat_completion.choices[0].message.content
# 4. 用输出和用量信息更新“生成”
generation.update(
output=response_content,
completion_start_time=chat_completion.created,
usage={
"prompt_tokens": chat_completion.usage.prompt_tokens,
"completion_tokens": chat_completion.usage.completion_tokens,
"total_tokens": chat_completion.usage.total_tokens,
},
)
print(f"LLM Response: {response_content}")
return response_content
except Exception as e:
# 5. 在追踪中记录错误
trace.update(
level="ERROR",
status_message=str(e)
)
print(f"An error occurred: {e}")
raise
finally:
# 6. 确保退出前所有数据发送完毕
langfuse.flush()
# 示例调用
simple_llm_call_with_trace("What is the capital of France?")
执行代码后,访问Langfuse界面,您将看到一个名为“simple-query”的新追踪,内含一个“openai-generation”记录。点击即可查看输入、输出、模型及元数据详情。
核心功能详解:Trace, Span, Generation
要充分利用Langfuse,关键在于理解并熟练使用trace、span和generation这三个核心对象。
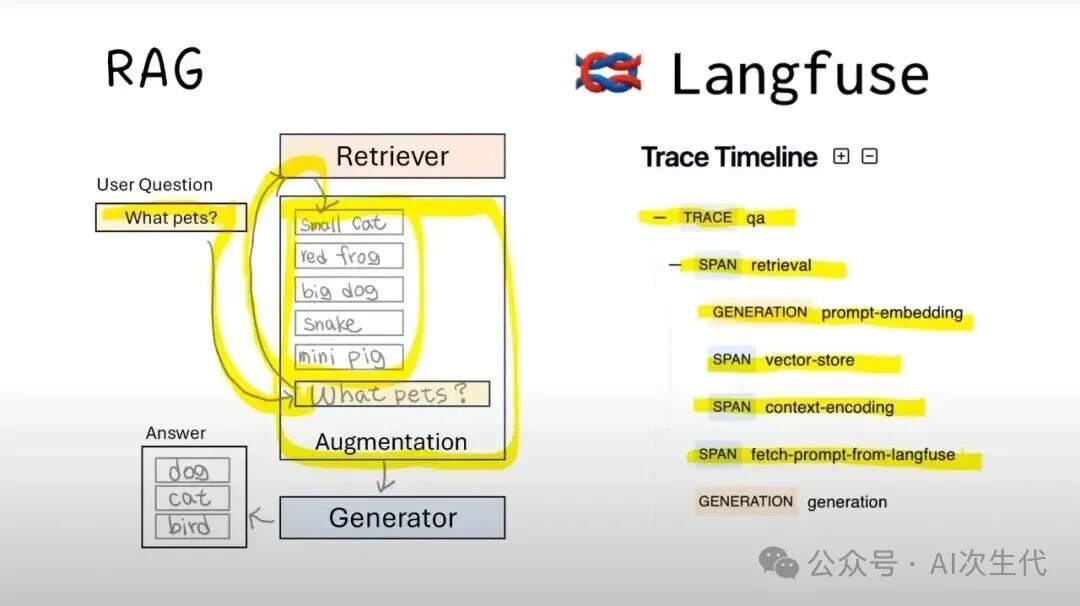
追踪 LLM 调用
langfuse.trace(): 启动一个新的顶级追踪容器。
name: 描述性名称。input: 整个流程的初始输入。metadata: 用于过滤分析的任意键值对(如:user_id, session_id)。session_id: (可选) 标识同一用户会话。user_id: (可选) 标识特定用户。
trace.span(): 表示追踪中的一个非LLM调用的逻辑步骤(如工具调用、数据查询)。
name: Span名称(如:“retrieve-docs”)。input/output: 相关输入输出。metadata: 附加元数据。level: 严重级别(INFO, ERROR等)。status_message: 状态信息(如错误详情)。parent_observation_id: 连接到父Span或Trace,构建嵌套结构。
trace.generation(): 表示一次特定的LLM调用。
name: 生成名称(如:“initial-response”)。input/output: 提示词与回复。model: 使用的LLM模型标识。model_parameters: 模型参数字典(如:temperature, max_tokens)。usage: Token使用量字典。metadata: 附加元数据。prompt: (可选) 关联Langfuse中管理的提示词模板。
总结
Langfuse 通过提供全面的追踪、系统化的评估和强大的提示词管理,将LLM应用的开发与维护转变为一个结构化、数据驱动的过程。它赋予了开发者前所未有的可见性,使其能够自信地调试问题、加速迭代周期,并在质量与性能上持续优化AI产品。
无论您是在构建一个简单的聊天机器人还是一个复杂的自主智能体,Langfuse 都提供了确保应用可靠、高效且能充分发挥其潜力的必要工具。
参考官方文档:langfuse.com/docs
 发表于 2025-12-3 23:30:21
|
查看: 214|
回复: 0
发表于 2025-12-3 23:30:21
|
查看: 214|
回复: 0
