Sea of Nodes IR是一种创新的编译器中间表示,它将程序建模为数据流与控制流交织的图结构。每个操作或值成为一个节点,节点间的边显式地表达依赖关系,这为进行全局优化提供了天然的优势。那么,如何验证这种复杂IR图的语义是否正确呢?这就是GraphEvaluator的用武之地——一个为该IR设计的、采用 控制流驱动、路径敏感、惰性求值 模型的解释执行引擎。它直接对IR图进行解释执行,为编译器验证、程序分析和教学演示提供了强大工具。
目录
- Sea of Nodes IR:基于图的程序表示
- 节点类型系统
- GraphEvaluator:解释执行引擎设计
- 关键执行阶段详解
- 简单示例:算术表达式的IR与解释执行
- 完整示例:阶乘函数的IR与解释执行
- GraphEvaluator的高级特性与实现考量
- 应用与展望
1. Sea of Nodes IR:基于图的程序表示
1.1 核心设计哲学
Sea of Nodes的核心思想是 “一切都是节点,一切都是边”。程序状态(值、控制、内存)的每一次定义和每一次使用都被建模为图中的节点和有向边。这种极致的细粒度表示,使得程序的所有依赖关系都变得显式和可分析,为编译器优化奠定了坚实的基础。
1.2 图结构模型与优势
1.2.1 与传统控制流图(CFG)的对比
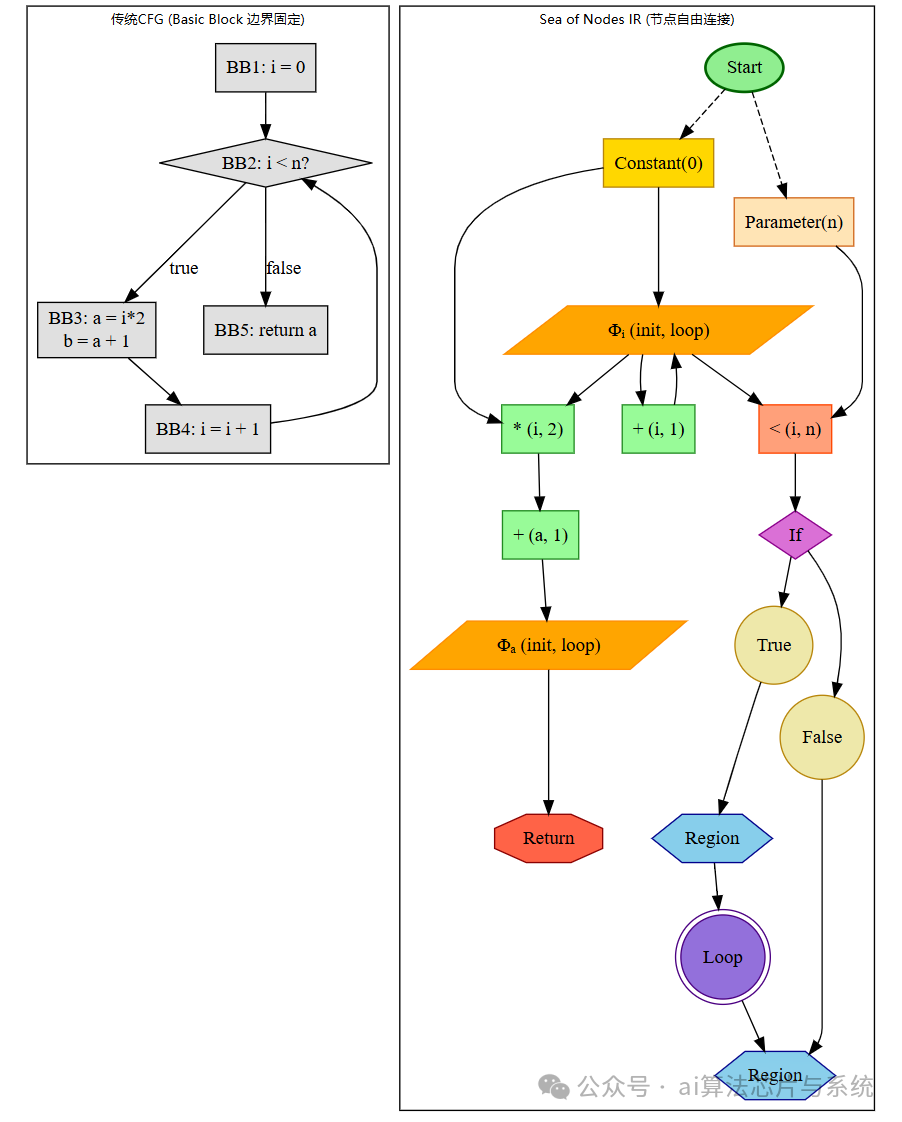
- 对比图说明
- 此图直观对比了传统控制流图(CFG)与Sea of Nodes IR在程序表示上的本质差异。左侧传统CFG以线性的基本块为组织单元,每个基本块包含一系列顺序执行的操作,块间通过条件或无条件跳转连接。这种结构清晰但边界固定,使得跨基本块的优化和分析变得复杂。
- 右侧Sea of Nodes IR则彻底打破了基本块的约束,将程序解构为一个由节点自由连接的网状图。每个节点(如
Start、Constant、Phi、If、Mul 等)独立代表一个具体的值、操作或控制点,边则显式地表示数据依赖(实线)与控制依赖(虚线或根据节点类型隐含)。例如,乘法节点 Mul 与其输入 PhiI 和常量 2 的依赖关系一目了然。
- 这种图结构使得编译器能够以全局视角审视整个函数,优化器可以轻易识别跨基本块的公共子表达式、判断操作的循环不变性等,为进行激进的全程序优化(如全局值编号GVN、循环无关代码外提LCSSA)提供了天然的便利,这是传统CFG难以直接做到的。
2. 节点类型系统
2.1 控制流节点
控制流节点构建了程序的执行骨架。
StartNode :图的唯一入口点,定义初始控制流状态和初始内存状态。它通常投影(Project)出后续节点所需的最初的控制、数据和内存边。RegionNode :控制流的合并点。它将多个前驱控制流路径(例如If的两个分支,或循环体与循环旁路)合并为一条路径。它是后续操作的单一控制依赖来源。IfNode :条件分支。它接受一个布尔值谓词(Predicate)输入,并具有两个控制输出:True和False投影。LoopNode :循环结构的头部。它是一个特殊的 RegionNode,除了合并进入循环的初始控制流,还负责合并循环体回边(Back Edge)的控制流,从而形成循环。ProjNode(投影节点):用于从多输出节点(如 IfNode, StartNode)中提取特定的输出边。例如,IfTrueProj 和 IfFalseProj 分别对应If分支的两条路径。ReturnNode :函数的出口点,消费一个返回值和控制流。
2.2 数据流节点
数据流节点执行具体的计算。
ConstantNode :表示编译时常量值。ParameterNode :表示函数的形参。PhiNode(φ-函数):值合并点。其值取决于到达它的控制流路径。在 RegionNode 处,它合并来自不同路径的数值;在 LoopNode 处,它合并循环的初始值和每次迭代后产生的新值。- 算术/逻辑运算节点:如
AddNode, SubNode, MulNode, CmpLTNode 等。它们具有明确的数据输入边并产生一个结果。
3. GraphEvaluator:解释执行引擎设计
3.1 总体架构与执行模型
GraphEvaluator 采用 控制流驱动、路径敏感、惰性求值 的执行模型。
- 控制流驱动:解释器沿着由
StartNode、IfNode、RegionNode、LoopNode 等构成的控制流骨架前进,决定下一步执行哪些节点。
- 路径敏感:在遇到
IfNode 时,只根据当前谓词的实际布尔值,选择一条分支(IfTrueProj 或 IfFalseProj)继续执行。另一分支的子图被完全忽略。
- 惰性求值:数据流节点(如
AddNode)的值仅在它被“需求”时才进行计算(例如,当它作为 ReturnNode 的输入,或作为 IfNode 的谓词时)。
3.2 核心数据结构
GraphEvaluator 的核心数据结构包括:
class GraphEvaluator:
def __init__(self):
self.cache_values = {} # 节点值缓存:将节点映射到其当前执行上下文下的计算结果
self.loop_phi_cache = [] # 循环Phi缓存:记录循环内Phi节点的临时值
self.start_node = None # 程序起点
self.max_loops = 100000 # 最大循环次数
- 核心数据结构说明
cache_values 是一个字典,作为节点到其计算结果的映射缓存,是实现 惰性求值 和避免重复计算的关键机制。当一个节点的值被首次请求时,它会被计算并存储于此;后续同一执行上下文下的请求将直接返回缓存值,这模拟了编译器的公共子表达式消除优化。loop_phi_cache 是一个列表,专门用于在模拟循环迭代时,临时存储和更新循环头 PhiNode 的值,以正确反映循环携带依赖。在循环回边处理中,旧值被新计算的值覆盖,为下一次迭代做准备。start_node 记录程序的入口点 StartNode,是整个解释执行过程的起点。max_loops 是一个安全界限,用于防止解释器陷入无限循环,通过限制最大迭代次数来确保执行的终止性,这对于处理不可信或用于分析的IR图至关重要,保障了工具本身的健壮性。
3.3 主执行算法架构
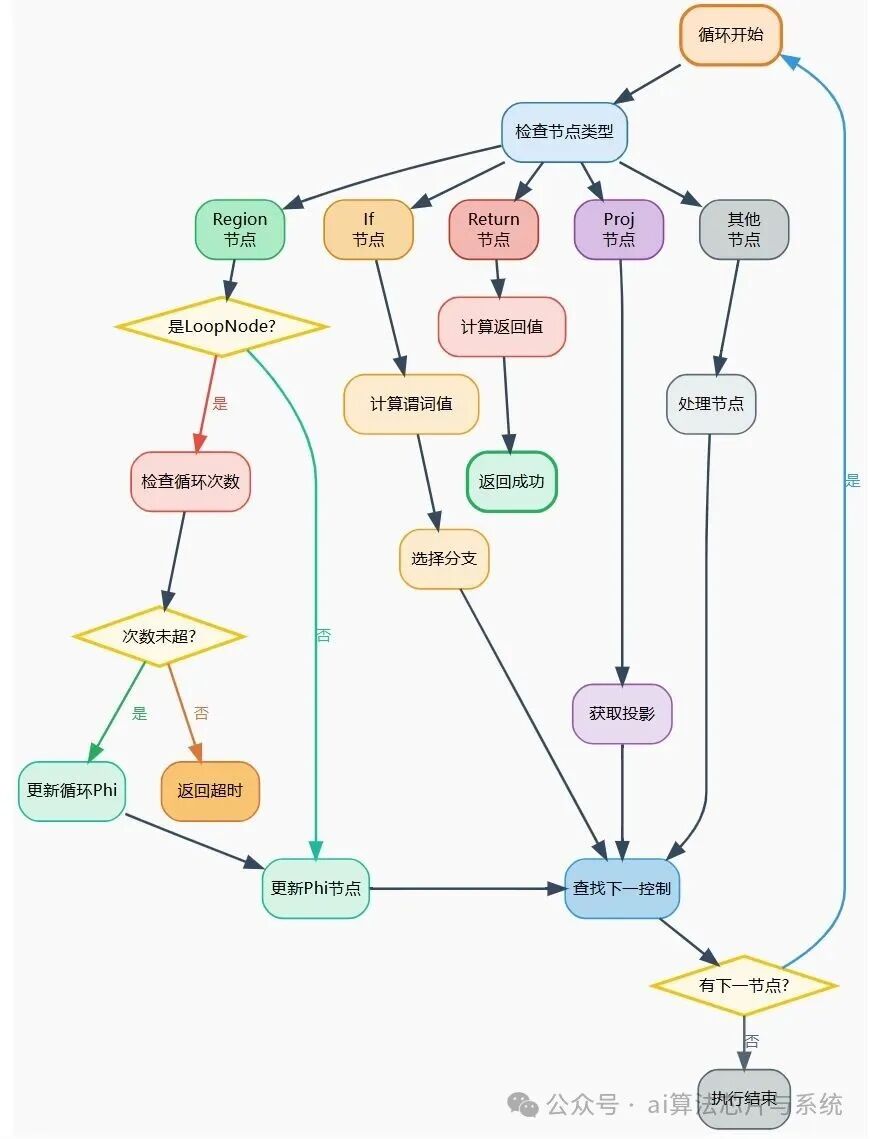
- 主执行算法流程图说明
- 此流程图清晰地勾勒出
GraphEvaluator 解释执行引擎的完整工作流程,其核心是 控制流驱动 和 路径敏感 的执行模型。流程始于对 StartNode 的定位和参数的初始化,这是解释器正确运行的先决条件。
- 进入主执行循环后,解释器的工作重心是处理控制流节点:它不断获取当前控制节点,并根据其类型(
RegionNode、IfNode、ReturnNode、ProjNode)进行分发处理。这种基于节点类型的分发机制是解释器理解IR图语义的基础。
- 对于
RegionNode,需要根据前驱路径更新关联的 PhiNode 值,若为循环头还需检查迭代次数以防无限循环。对于 IfNode,则通过计算谓词值动态选择一条分支继续执行,完全忽略另一分支,这体现了 路径敏感 性。ReturnNode 是终点,计算其返回值后成功退出。
- 整个循环通过
findControl 函数沿着控制依赖边推进,直至无可执行节点或遇到错误。图中菱形决策框和明确的状态输出(成功、超时、错误)展示了算法的健壮性和对异常情况的处理能力,确保解释器在各种IR图输入下都能给出明确的执行结果。
3.4 核心辅助函数
def find_start(self, visited, node):
"""定位StartNode作为程序入口点"""
if node is None:
return None
# 扩展visited数组大小
if node.nid >= len(visited):
visited.extend([False] * (node.nid - len(visited) + 1))
if visited[node.nid]:
return None
visited[node.nid] = True
# 检查当前节点是否为StartNode
start = node if isinstance(node, StartNode) else None
# 递归搜索输入节点
for input_node in node.inputs:
result = self.find_start(visited, input_node)
if result is not None:
start = result
# 递归搜索输出节点
for output_node in node.outputs:
result = self.find_start(visited, output_node)
if result is not None:
start = result
return start
- find_start函数说明
find_start 函数负责在可能从任意节点(如 ReturnNode)出发的IR图中,通过图的遍历定位唯一的程序入口点 StartNode。该函数采用深度优先搜索(DFS)策略,并使用 visited 列表记录已访问节点ID以防止无限递归和重复搜索。- 其逻辑是:若当前节点就是
StartNode,则直接将其作为结果;否则,递归地搜索其所有输入(inputs,即数据/控制的前驱)和输出(outputs,即数据/控制的后继)节点。这种双向搜索确保了无论从图的哪个位置开始,都能最终找到作为所有数据流和控制流源头的 StartNode。
- 这个函数是解释器正确初始化的第一步,为后续参数设置和控制流执行奠定基础。它体现了
GraphEvaluator 的灵活性:不需要用户显式指定入口点,能够自动分析IR图结构找到正确的起点。
def find_control(self, control):
"""查找控制后继节点"""
for use in control.outputs:
if use.is_cfg():
return use
return None
- find_control函数说明
find_control 函数是主执行循环中推进控制流的关键。它接收一个当前控制节点,遍历其所有输出边(outputs),寻找并返回第一个是控制流节点(通过 is_cfg() 方法判断,如 RegionNode、IfNode、ProjNode、ReturnNode)的后继。- 这个简单的函数实现了控制流的隐式传递。在Sea of Nodes IR中,控制依赖通过边连接,但一个控制节点(如
RegionNode)可能同时有多个输出连接到不同的数据节点。find_control 通过筛选,只获取真正的控制流后继,从而引导解释器沿着正确的控制路径前进。
- 它是 控制流驱动 模型得以实现的基础操作。通过不断调用
find_control,解释器能够在不关心具体数据计算的情况下,仅跟随控制依赖边就能遍历程序的所有可能执行路径。
def find_projection(self, node, idx):
"""查找指定索引的投影节点"""
for use in node.outputs:
if isinstance(use, ProjNode) and use.idx == idx:
return use
return None
- find_projection函数说明
find_projection 函数用于从具有多个输出的节点(主要是 StartNode 和 IfNode)中,定位具有特定索引 idx 的 ProjNode(投影节点)。例如,StartNode 通常有多个投影分别对应初始控制、内存和各个参数;IfNode 则有索引为1和0的投影分别对应True和False分支。- 该函数遍历给定节点的所有输出,检查是否为
ProjNode 且其 idx 属性匹配目标值。在解释器初始化阶段,它用于找到参数投影以设置输入值;在执行阶段,用于在 IfNode 处根据条件值选择正确的分支投影。
- 它是连接多输出节点与其特定用途的桥梁,确保了数据和控制能够被正确地提取和分发。这个函数的存在使得Sea of Nodes IR中多输出节点的语义能够被解释器正确理解和执行。
4. 关键执行阶段详解
4.1 值计算策略(惰性求值)
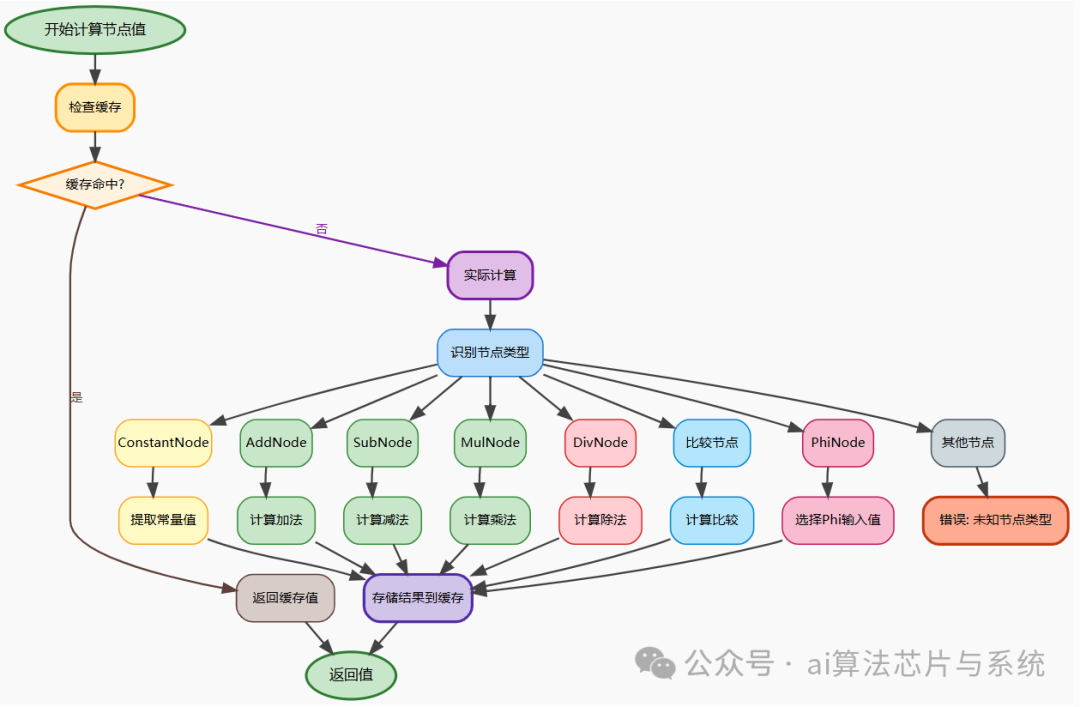
- 值计算策略流程图说明
- 该流程图详细描述了
get_value 函数的执行逻辑,它是 GraphEvaluator 实现 惰性求值 的核心引擎。其设计哲学是“按需计算”,只有在节点的值真正被需要时才会触发计算流程,避免了不必要的计算开销。
- 流程始于对
cache_values 字典的检查,若命中则立即返回缓存值,这避免了表达式的重复计算,是运行时对公共子表达式消除的模拟。缓存机制是解释器性能的关键优化,确保了相同节点在单次执行中只计算一次。
- 若未命中,则进入实际计算阶段:首先通过一系列
isinstance 检查进行节点类型识别,然后根据类型分派到不同的计算逻辑。对于 ConstantNode 直接取值;对于运算节点(如 AddNode)则递归地获取其操作数值;对于 PhiNode 则需要根据当前控制流上下文选择正确的输入值。
- 无论通过哪条路径得到计算结果,都会将其存入缓存以备后用。这种“计算-缓存”的闭环设计确保了正确性与效率的平衡,是
GraphEvaluator 能够高效解释复杂IR图的基础。
4.2 值计算核心实现
def get_value(self, node):
"""获取节点值(惰性求值)"""
# 检查缓存
if node in self.cache_values:
return self.cache_values[node]
result = 0
# 根据节点类型分发计算
if isinstance(node, ConstantNode):
result = node.value
elif isinstance(node, ParameterNode):
# 参数值应在初始化时已存入缓存
if node not in self.cache_values:
raise RuntimeError(f"参数节点 {node.nid} 未初始化")
result = self.cache_values[node]
elif isinstance(node, AddNode):
left = self.get_value(node.inputs[0]) if len(node.inputs) > 0 else 0
right = self.get_value(node.inputs[1]) if len(node.inputs) > 1 else 0
result = left + right
elif isinstance(node, SubNode):
left = self.get_value(node.inputs[0]) if len(node.inputs) > 0 else 0
right = self.get_value(node.inputs[1]) if len(node.inputs) > 1 else 0
result = left - right
elif isinstance(node, MulNode):
left = self.get_value(node.inputs[0]) if len(node.inputs) > 0 else 0
right = self.get_value(node.inputs[1]) if len(node.inputs) > 1 else 0
result = left * right
elif isinstance(node, DivNode):
dividend = self.get_value(node.inputs[0]) if len(node.inputs) > 0 else 0
divisor = self.get_value(node.inputs[1]) if len(node.inputs) > 1 else 1
result = self.safe_div(dividend, divisor)
# ... 处理其他节点类型
# 缓存结果
self.cache_values[node] = result
return result
- get_value函数核心实现说明
- 此代码段是
get_value 方法的核心实现,展示了惰性求值引擎的具体运作机制。函数入口处的缓存检查是性能关键,直接返回已计算值,避免了重复遍历和计算子图。
- 如果缓存未命中,则通过一系列
isinstance 检查进行节点类型分发。对于 ConstantNode,直接读取其存储的常量值。对于 ParameterNode,假设其值已在解释器初始化时存入缓存,否则报错。这种设计将参数值的设置与使用解耦。
- 对于算术运算节点(
AddNode, SubNode, MulNode, DivNode),代码通过递归调用 self.get_value() 获取其操作数的值。这一过程可能触发复杂的子图计算,但缓存机制确保了每个子节点至多计算一次。
- 最后,无论通过哪个分支计算出的
result,都会被存入 self.cache_values 字典中,完成“计算-缓存”的闭环。这种清晰的分发结构使得添加对新节点类型的支持变得非常直接,只需添加新的 elif 分支即可。
递归计算等同于通过数据依赖进行深度优先遍历,根据遍历顺序计算!
4.3 Phi节点处理机制
def latch_loop_phis(self, region, prev):
"""更新循环Region的Phi节点值"""
# 找到prev在region.inputs中的索引
try:
idx = region.inputs.index(prev)
except ValueError:
raise RuntimeError(f"节点 {prev.nid} 不是Region {region.nid} 的输入")
assert idx > 0 # 第一个输入通常是控制输入
# 收集所有Phi节点的值
phi_values = []
for output in region.outputs:
if isinstance(output, PhiNode):
value = self.get_value(output.inputs[idx])
phi_values.append(value)
# 更新缓存
phi_idx = 0
for output in region.outputs:
if isinstance(output, PhiNode):
if phi_idx >= len(self.loop_phi_cache):
self.loop_phi_cache.extend([0] * (phi_idx - len(self.loop_phi_cache) + 1))
self.loop_phi_cache[phi_idx] = phi_values[phi_idx]
phi_idx += 1
phi_idx = 0
for output in region.outputs:
if isinstance(output, PhiNode):
self.cache_values[output] = self.loop_phi_cache[phi_idx]
phi_idx += 1
- latch_loop_phis函数说明
latch_loop_phis 函数专门用于处理循环结构中的 PhiNode 更新,这是模拟循环语义最复杂的部分。当一个 LoopNode(循环头)作为 RegionNode 被处理,且当前前驱节点 prev 不是其第一个输入(即来自循环体回边)时,调用此函数。- 函数首先确定
prev 在 region.inputs 列表中的索引 idx,该索引对应循环体出口的路径。然后,它遍历该 RegionNode 的所有输出,找出所有 PhiNode,并通过 get_value 获取这些 PhiNode 对应于回边输入(inputs[idx])的值。
- 这些新值代表了本次迭代计算出的新值,将用于下一次迭代。它们被临时存储到专用的
loop_phi_cache 列表中,然后再批量更新到主缓存 cache_values 中。使用独立缓存列表是为了在循环迭代间高效地暂存和传递这些“即将成为下一轮初始值”的数据。
- 这种两阶段更新(先收集到临时列表,再更新主缓存)确保了在更新过程中,如果某个
PhiNode 的计算依赖于另一个 PhiNode 的旧值,仍然能获取到正确的旧值,这是正确模拟循环携带依赖的关键。
def latch_phis(self, region, prev):
"""更新普通Region的Phi节点值"""
try:
idx = region.inputs.index(prev)
except ValueError:
raise RuntimeError(f"节点 {prev.nid} 不是Region {region.nid} 的输入")
for output in region.outputs:
if isinstance(output, PhiNode):
value = self.get_value(output.inputs[idx])
self.cache_values[output] = value
- latch_phis函数说明
latch_phis 函数用于处理非循环的普通 RegionNode(如合并If两个分支的Region)的 PhiNode 更新。其逻辑比循环版本简单直接,因为不涉及迭代间的值传递。- 确定前驱节点
prev 在Region输入列表中的索引 idx,该索引标识了执行路径来自哪一个前驱(例如,是来自If的True分支还是False分支)。然后,遍历该Region的所有输出节点,对每一个 PhiNode,通过 get_value 获取其对应于该路径的输入值(inputs[idx]),并直接将该值存入主缓存 cache_values。
- 这个操作实现了
PhiNode 的核心语义——根据实际到达的控制流路径,从多个可能的值中选择一个作为当前执行上下文下的值。它是实现路径敏感执行的关键机制之一。
latch_phis 和 latch_loop_phis 共同完成了对Sea of Nodes IR中 PhiNode 的动态解析,使解释器能够正确处理条件分支和循环结构,将控制流的动态选择映射为数据值的具体取值。
4.4 主执行函数实现
def evaluate(self, start=None, parameter=0, max_loops=None):
"""主执行函数"""
# 如果未提供start节点,尝试自动查找
if start is None:
visited = []
start = self.find_start(visited, self.start_node if self.start_node else None)
if start is None:
return EvalResult(ResultType.ERROR, 0, "无法找到StartNode")
# 设置参数值
param_proj = self.find_projection(start, 1)
if param_proj:
self.cache_values[param_proj] = parameter
# 获取控制投影作为起始点
control = self.find_projection(start, 0)
if control is None:
return EvalResult(ResultType.ERROR, 0, "无法找到控制投影")
prev = start
loops_remaining = max_loops if max_loops is not None else self.max_loops
# 主执行循环
while control is not None:
# 处理RegionNode
if isinstance(control, RegionNode):
# 检查是否为循环回边
if isinstance(control, LoopNode) and control.inputs[1] != prev:
if loops_remaining <= 0:
return EvalResult(ResultType.TIMEOUT, 0, "循环超时")
loops_remaining -= 1
self.latch_loop_phis(control, prev)
else:
self.latch_phis(control, prev)
# 获取下一个控制节点
control = self.find_control(control)
# 处理IfNode
elif isinstance(control, IfNode):
# 计算条件值
cond_value = self.get_value(control.predicate)
# 选择分支(1为True分支,0为False分支)
proj_idx = 1 if cond_value != 0 else 0
selected_proj = self.find_projection(control, proj_idx)
if selected_proj is None:
return EvalResult(ResultType.ERROR, 0, f"无法找到分支投影 {proj_idx}")
# 更新控制流
control = self.find_control(selected_proj)
# 处理ReturnNode
elif isinstance(control, ReturnNode):
# 计算返回值
return_value = self.get_value(control.value_input)
return EvalResult(ResultType.SUCCESS, return_value, "")
# 处理ProjNode
elif isinstance(control, ProjNode):
# 直接获取下一个控制节点
control = self.find_control(control)
# 处理其他节点
else:
# 这些节点通常不应该作为控制流节点
control = self.find_control(control)
# 更新前驱节点
if control is not None:
prev = control
return EvalResult(ResultType.ERROR, 0, "执行未到达返回节点")
- evaluate主执行函数说明
evaluate 函数是 GraphEvaluator 的入口和主控制器,它将所有组件串联起来实现完整的解释执行。函数首先处理初始化:定位 StartNode,将输入参数值存入对应的参数投影节点缓存,并获取初始控制投影节点。- 然后进入核心的
while 循环,该循环以控制流节点 control 为驱动。在循环体内,通过 isinstance 检查对 control 进行类型分发。对于 RegionNode,区分普通合并与循环回边,分别调用 latch_phis 或 latch_loop_phis 更新Phi值,并对循环进行次数限制检查。
- 对于
IfNode,通过 get_value 计算谓词(触发惰性求值),根据结果选择分支投影,实现了 路径敏感 执行。对于 ReturnNode,计算返回值并成功终止。对于 ProjNode,直接寻找其控制后继。
- 每次成功处理一个节点后,都通过
find_control 获取下一个待处理的控制节点,从而沿着控制依赖边推进执行。函数通过 EvalResult 结构体封装执行结果(成功值、超时或错误信息),提供了清晰的执行状态反馈。整个函数结构清晰地体现了控制流驱动、路径敏感和惰性求值三大核心设计原则。
5. 简单示例:算术表达式的IR与解释执行
5.1 简单表达式示例
考虑一个简单的表达式计算:(a + b) * c。对应的函数为:
int compute(int a, int b, int c) {
return (a + b) * c;
}
5.2 对应的Sea of Nodes IR图
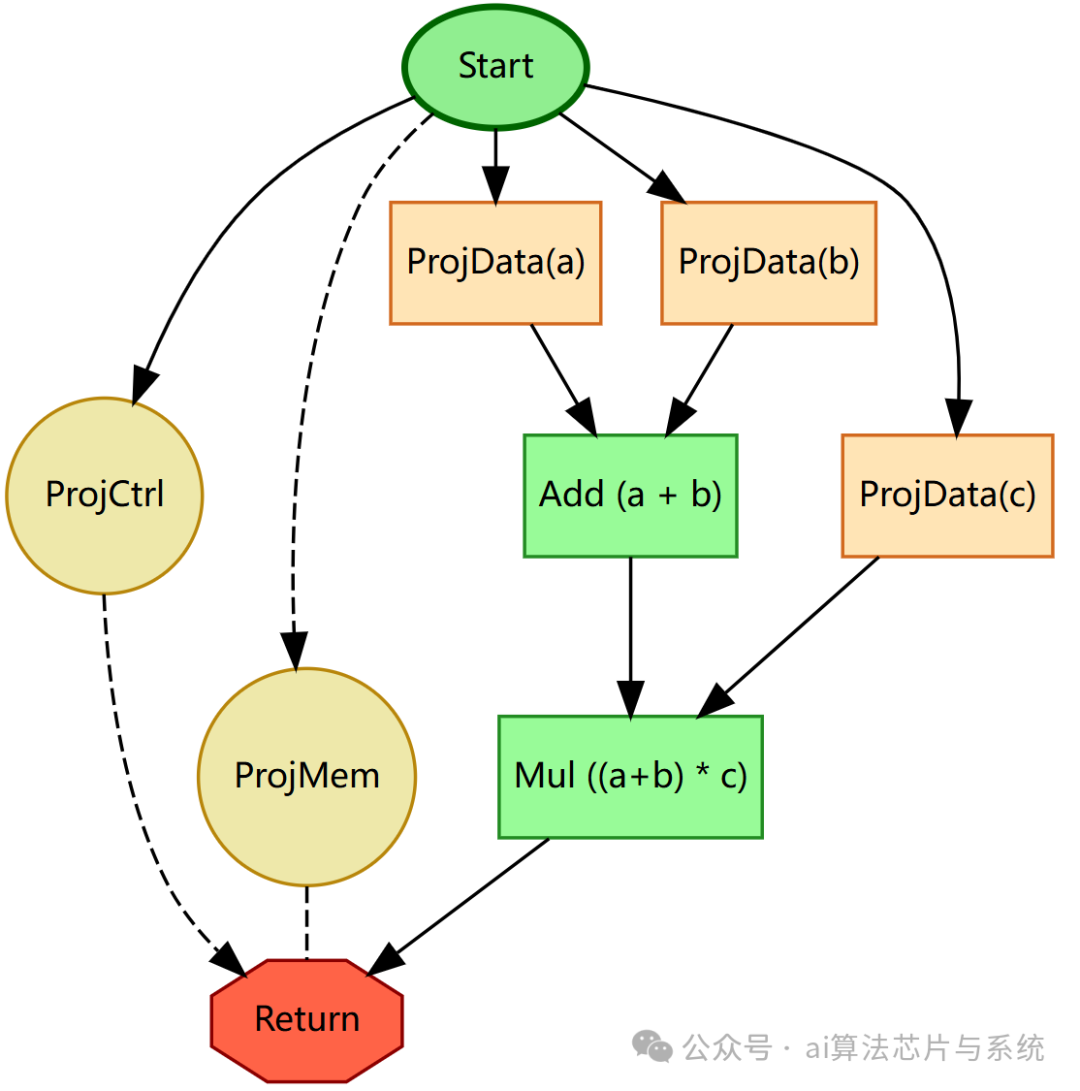
- 算术表达式IR图说明
- 此图展示了一个无控制流的纯数据流计算的Sea of Nodes IR表示,对应函数
(a + b) * c。图中心是 StartNode,它投影出初始控制流(ProjCtrl)、初始内存状态(ProjMem)以及三个参数 a、b、c 的数据投影(ProjA, ProjB, ProjC)。
- 数据流清晰可见:
ProjA 和 ProjB 作为输入流向 AddNode 执行加法运算,其结果与 ProjC 一起作为输入流向 MulNode 执行乘法运算。最终,乘法结果流向 ReturnNode 作为返回值,同时 ReturnNode 也需要消费初始控制流(来自 ProjCtrl)。
- 这个简单的图例揭示了Sea of Nodes IR的几个关键特点:显式的数据依赖边(实线)、控制流与数据流的分离(
ProjCtrl 独立存在)、以及 StartNode 作为所有值的唯一源头。
- 对于解释器
GraphEvaluator 而言,执行此图就是沿着 ProjCtrl -> ReturnNode 的控制路径,在 ReturnNode 需要返回值时,触发对 MulNode 及其依赖的 AddNode 和参数投影的惰性求值过程。这个例子展示了最基本的解释执行模式。
5.3 GraphEvaluator执行跟踪 (a=2, b=3, c=4)
- 初始化:定位到
Start。缓存 ProjData(a) = 2, ProjData(b) = 3, ProjData(c) = 4。ctrl = ProjCtrl。
- 控制流转:
ctrl 直接流向 Return 节点。
- 值计算:
Return 需要其返回值输入 Mul 的值。
getValue(Mul) 检查缓存(未命中),计算 Mul。getValue(Mul.in(1)) 即 Add 节点:
getValue(Add) 检查缓存(未命中),计算 Add。getValue(Add.in(1)) 即 ProjData(a) = 2(缓存命中)。getValue(Add.in(2)) 即 ProjData(b) = 3(缓存命中)。Add = 2 + 3 = 5,缓存 Add -> 5。
getValue(Mul.in(2)) 即 ProjData(c) = 4(缓存命中)。Mul = 5 * 4 = 20,缓存 Mul -> 20。
- 返回结果:
Return 获得值20,程序结束,返回20。
6. 完整示例:阶乘函数的IR与解释执行
6.1 源程序
int factorial(int n) {
if (n <= 1) return 1;
int r = 1;
while (n > 1) {
r = r * n;
n = n - 1;
}
return r;
}
6.2 详细的Sea of Nodes IR图
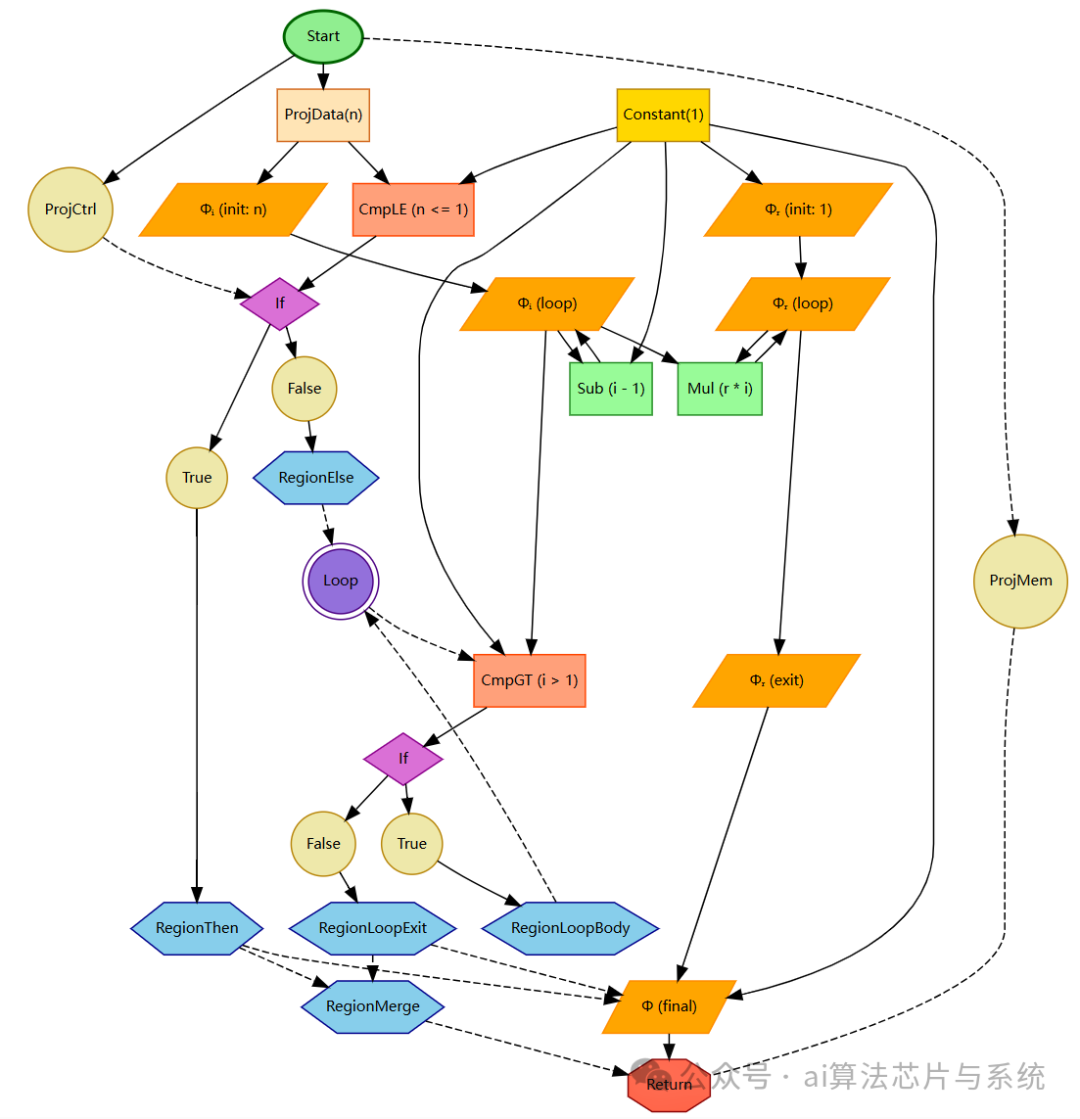
- 阶乘函数IR图说明
- 此图是阶乘函数
factorial(n) 的完整Sea of Nodes IR表示,它复杂地交织了数据流、控制流和循环结构,是展示 GraphEvaluator 能力的绝佳示例。图顶部是入口 StartNode 和参数 n。
- 第一个条件判断
CmpLE 决定执行流:若 n<=1,走左侧 Then 分支,通过 RegionThen 直接合并到最终返回值 Phi_Final(值为常量1)。否则,走右侧 Else 分支,进入循环结构。
- 循环由
LoopHead(一个特殊的 RegionNode)主导,它通过 Phi_I_Loop 和 Phi_R_Loop 这两个关键的 PhiNode 来合并每次迭代的初始值(来自前一次迭代体或循环开始)并产生本次迭代使用的值 i 和 r。循环体内部,Mul 和 Sub 节点根据当前 i 和 r 的值计算新的 r 和 i,并将结果通过回边反馈给 Phi 节点,形成循环携带依赖。
- 循环条件
CmpGT 决定继续迭代还是退出。退出后,值通过 Phi_R_Exit 和 Phi_Final 合并,最终由 ReturnNode 返回。此图生动地展示了Sea of Nodes如何用 Region 合并控制流、用 Phi 合并数据流、用 Loop 组织循环,以及 GraphEvaluator 如何通过处理这些节点来模拟完整的程序执行。
6.3 GraphEvaluator 执行过程逐步跟踪 (n=3)
- 初始化:定位到
Start。缓存 ProjData(n) = 3。当前控制流 ctrl = ProjCtrl。
- 条件判断:
ctrl 到达 If1。- 求值谓词
CmpLE(3,1) = false。
- 选择
False 投影,ctrl = ProjFalse1。
- 进入循环前:
ctrl 经过 RegionElse,到达 LoopHead。- 初始化循环Phi:
Φᵢ (init) = 3, Φᵣ (init) = 1。
- 设置
Phi_I_Loop = 3, Phi_R_Loop = 1 (首次迭代初始值)。
- 第一次循环迭代:
- 求值条件
CmpGT(Phi_I_Loop(3), 1) = true。
- 进入
If2 的 True 分支。
- 执行循环体:
Mul(Phi_R_Loop(1), Phi_I_Loop(3)) = 3;Sub(Phi_I_Loop(3), 1) = 2。
- 更新循环Phi回边值:
Phi_R_Loop <-- 3, Phi_I_Loop <-- 2。
- 第二次循环迭代:
- 条件:
CmpGT(2, 1) = true。
- 循环体:
Mul(3, 2) = 6;Sub(2, 1) = 1。
- 更新:
Phi_R_Loop <-- 6, Phi_I_Loop <-- 1。
- 第三次循环迭代 (退出):
- 条件:
CmpGT(1, 1) = false。
- 进入
If2 的 False 分支,ctrl = ProjFalse2。
- 经过
RegionLoopExit,Phi_R_Exit 取值自 Phi_R_Loop (6)。
- 合并与返回:
ctrl 到达 RegionMerge。Phi_Final 根据控制流来源选择值:当前来自 RegionLoopExit,故选择其输入 Phi_R_Exit (6)。Return 节点求值 Phi_Final = 6,程序结束,返回结果6。
7. GraphEvaluator的高级特性与实现考量
7.1 循环处理与安全界限
必须防止解释器因无限循环而挂起。标准做法是设置一个全局迭代计数器上限(如100,000)。当 LoopNode 的迭代次数超过此限时,GraphEvaluator 应停止执行并返回一个“超时”或“可能不终止”的特殊结果。这对于处理不可靠的或用于静态分析的IR图是必要的安全措施。
7.2 错误处理与健壮性
- 未实现的节点类型:当遇到未知或未实现的
Opcode 时,应抛出清晰的错误信息,包含节点ID和类型,而不是崩溃。
- 图结构不一致:例如,
PhiNode 的输入数与 RegionNode 的前驱数不匹配。解释器应在初始化或首次遇到时进行合理性检查。
- 值类型不匹配:在计算
AddNode 时,如果输入值是内存地址而非整数,应进行类型检查并报错。
7.3 性能优化策略
虽然解释执行本身较慢,但在其设计范围内仍可优化:
- 激进的值缓存:
getValue() 中的缓存是必须的。对于纯函数节点(如算术运算),其值在单次执行中不变,缓存可消除重复子图计算。
- 控制流快照:如果解释器需要支持回溯(如用于路径探索),则需要能保存和恢复
value_cache_ 和 loop_context_stack_ 的状态。可采用复制-写时优化策略。
- 节点排序:在解释开始前,对图进行拓扑排序(考虑控制依赖和数据依赖),生成一个近似的线性执行顺序,可以减少解释循环中的分发开销。
8. 应用与展望
8.1 在编译器开发中的应用
这是 GraphEvaluator 的首要用途。在实现一个新的优化通道(Pass)后,可以:
- 对同一函数,分别获取优化前和优化后的IR图。
- 使用
GraphEvaluator 对两张图,输入相同的随机参数集,进行解释执行。
- 比较两者的输出结果。如果一致,则优化大概率正确;如果不一致,则优化存在bug。这种方法比生成汇编代码再测试更直接、更与平台无关。
8.2 作为程序分析工具
通过赋予 GraphEvaluator 符号执行的能力(即让 ParameterNode 的值为符号而非具体值),它可以用于探索程序的所有可行路径,生成路径约束,进而用于 漏洞挖掘(如发现除零、数组越界)、可达性分析 或 测试用例生成。
8.3 教学与可视化演示
GraphEvaluator 可以驱动一个图形界面,高亮显示当前正在执行的节点,并动态展示 value_cache_ 的变化。学生可以单步执行IR图,观察值如何通过 PhiNode 在循环中演变,或如何通过条件分支选择不同的路径,这对于理解编译器的中间表示和优化原理极具帮助。这种直观的互动方式,使得复杂的图结构概念变得易于掌握,非常适合在 云栈社区 等技术平台上进行技术分享与学习交流。
 发表于 2026-2-2 03:05:00
|
查看: 179|
回复: 0
发表于 2026-2-2 03:05:00
|
查看: 179|
回复: 0
