当前,大语言模型(LLM)在开放域问答(ODQA)任务上展现出强大能力,但“幻觉”(Hallucination)问题仍是实际部署中的一大挑战。为了缓解这一问题,GraphRAG(Graph Retrieval-Augmented Generation)应运而生,它将大模型与结构化知识结合,利用知识图谱(KG)进行更可靠的推理。
然而,主流的GraphRAG方法普遍采用 “先构建后推理”(build-then-reason) 的范式。即预先从语料中抽取并构建一个静态的知识图谱,然后在回答问题时基于此图谱进行路径搜索和推理。这种范式虽然直观,却存在两个根本性缺陷。
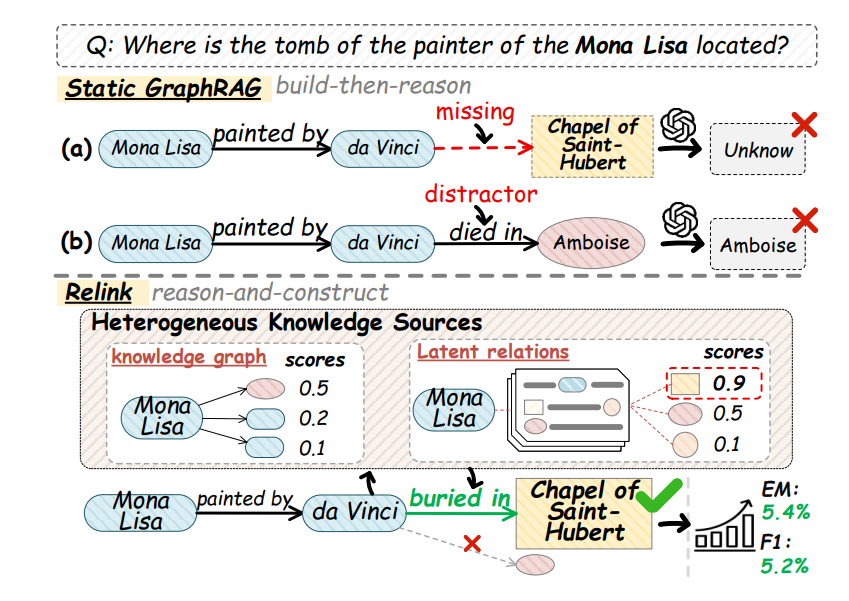
知识图谱的不完整性:静态知识图谱因知识不断演化、信息抽取技术存在误差,天然存在事实覆盖缺口。当关键事实链接缺失时,推理链会直接断裂。如上图(a)所示,回答“《蒙娜丽莎》画家的墓地在哪里?”时,由于缺少“达芬奇”到“Saint-Hubert小教堂”的直接链接,静态方法无法得出正确答案。
低信噪比与干扰事实:通用知识图谱包含大量与查询主题相关但对回答特定问题没有帮助的“干扰事实”。如上图(b)所示,一个人物的“died in”(死于)和“buried in”(葬于)都与查询高度相关,但只有后者能真正回答问题。现有方法难以有效区分“相关”与“有用”的事实,容易被带偏。
核心思想:从“构建后推理”到“推理中构建”
针对上述静态图谱的固有问题,研究人员提出了 “推理并构建”(reason-and-construct) 的新范式,并设计了名为 Relink 的框架。其核心洞察是:与其让复杂多变的查询去适应一个固定不变的图谱,不如让图谱为每个特定查询动态地生长和构建。
Relink 的实现依赖于三个核心机制:
1. 异构知识源融合
- 高精度事实图谱(G_b):作为可靠但可能覆盖不全的“骨架”,由 LLM 从文本中精确抽取得到,提供高置信度的事实关系。
- 高召回潜在关系池(R_c):作为灵活的知识补充源,从原始文本语料中基于实体共现(通过 PMI 筛选)构建而成,用于动态修补缺失的推理路径。
2. 查询驱动的动态路径探索
采用“粗到细”的两阶段排序策略,在推理过程中实时评估和构建路径:
- 粗排阶段:使用一个轻量级、可训练的排序器(Ranker)快速筛选大量候选路径。
- 精排阶段:利用 LLM 深入评估候选路径对回答当前查询的语义贡献度。
当排序器倾向于选择来自潜在关系池(R_c)的候选时,系统会调用 LLM,结合查询和原文的上下文信息,将抽象的潜在关系动态“实例化”为一个具体的事实三元组,从而实现“按需补全”。
3. 统一语义空间对齐
通过对比学习(InfoNCE损失),将来自显式事实图谱(G_b)和潜在关系池(R_c)的异构知识编码到同一个语义向量空间中。这确保了排序器能够在统一的维度上公平地比较不同来源的证据。
模型架构与工作流程
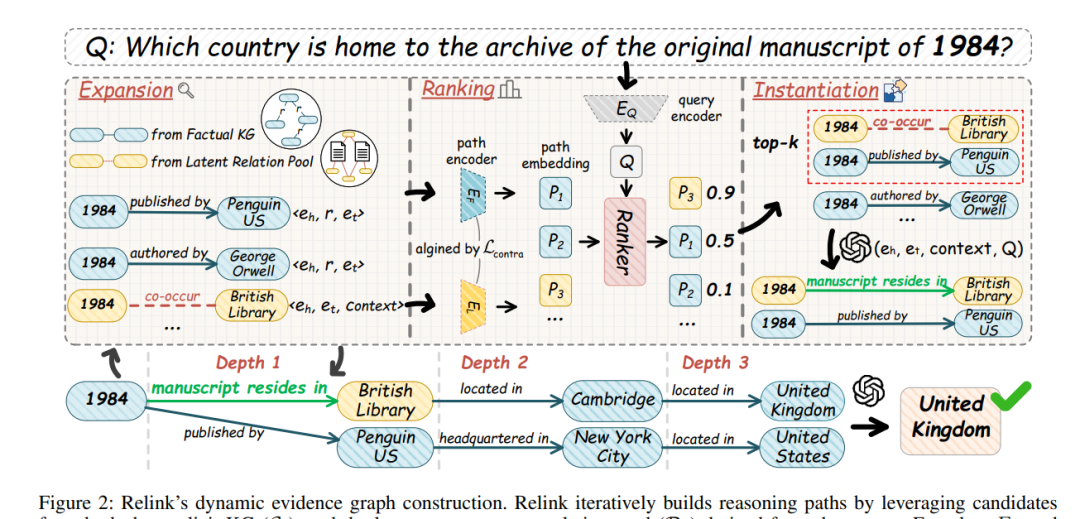
如上图所示,Relink 的工作流程包含三个核心模块,以迭代方式构建查询专属的证据图:
1. 异构知识源构建
- G_b 通过 LLM 抽取事实三元组构建。
- R_c 通过计算实体共现并设定 PMI 阈值筛选得到,并使用专门的编码器 Encoder_L 对包含该关系对的上下文句子进行编码(通常取
[MASK] 位置的表示)。
2. 动态路径扩展与排序
- 从查询中的主题实体出发,在每一轮迭代中,同时从 G_b 和 R_c 中扩展候选路径。
- 在统一的语义空间中,使用训练好的排序器评估每个候选路径与查询之间的相关性。
- 对于排名靠前但来自 R_c 的“潜在关系”,调用 LLM 根据查询和上下文将其实例化为具体事实。
- 保留排名最高的 K 条路径,作为下一轮扩展的基础,直到达到预设的深度或找到答案。
3. 证据赋能的答案生成
将最终构建出的、与查询高度相关的紧凑证据图,以及图中三元组关联的原始文本句子,一并输入到生成式 LLM 中。这确保了生成的答案不仅准确,而且可验证、可追溯。
模型的训练采用 分阶段优化策略:首先冻结编码器参数,单独训练排序器(优化排序损失 L_rank);然后冻结排序器,优化编码器以对齐异构知识源的语义空间(优化对比损失 L_contra)。两者交替进行直至收敛。
实验结果与关键发现
在五个标准的多跳问答数据集(2WikiMultiHopQA、HotpotQA、ConcurrentQA、MuSiQue-Ans、MuSiQue-Full)上的实验表明,Relink 具有显著优势。
主实验性能
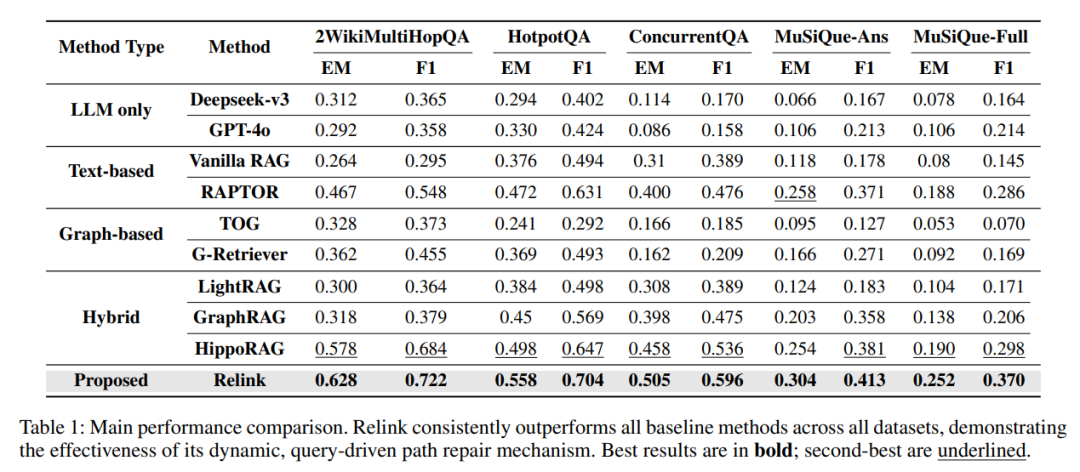
如下表所示,Relink 在所有数据集上全面领先于所有基线模型(包括纯 LLM、基于文本的 RAG、基于图谱的方法以及混合方法),平均提升达 5.4% EM 和 5.2% F1。与之前最优的 RAG 方法 HippoRAG 相比,在 HotpotQA 上 EM 提升 12.0%,在更具挑战性的 MuSiQue-Full 上 EM 提升高达 32.6%。
消融实验分析
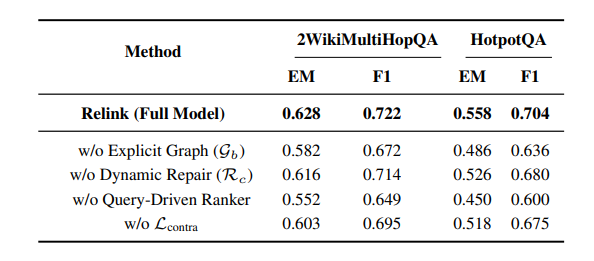
下表的消融实验进一步验证了各组件的重要性:
- 移除潜在关系池(R_c):在 HotpotQA 上 EM 下降 5.7%,证明动态修补能力至关重要。
- 移除显式图谱(G_b):EM 暴跌 12.9%,说明高精度的知识骨架是可靠推理的基础。
- 替换查询驱动排序器为通用语义相似度:EM 下降 19.4%,凸显了区分“相关事实”与“有用事实”的必要性。
- 移除对比对齐损失(L_contra):EM 下降 7.2%,表明将异构知识映射到统一空间是有效排序的前提。
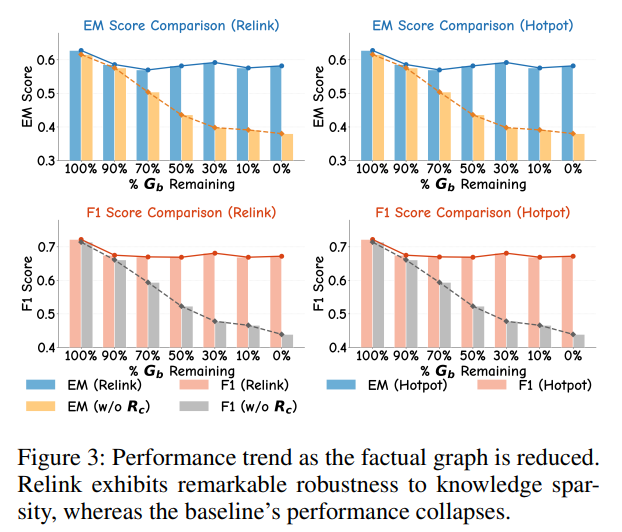
知识稀疏鲁棒性
为了测试系统对知识不全的韧性,实验逐步移除显式图谱(G_b)中的边。如下图所示,当 90% 的边被移除时,静态推理方法(w/o R_c)的性能(F1)暴跌 34.7%,而 Relink 仅出现轻微下降,F1 仍能维持在 0.669 的高水平。这强有力地证明了其动态修复机制在知识稀疏场景下的卓越鲁棒性。
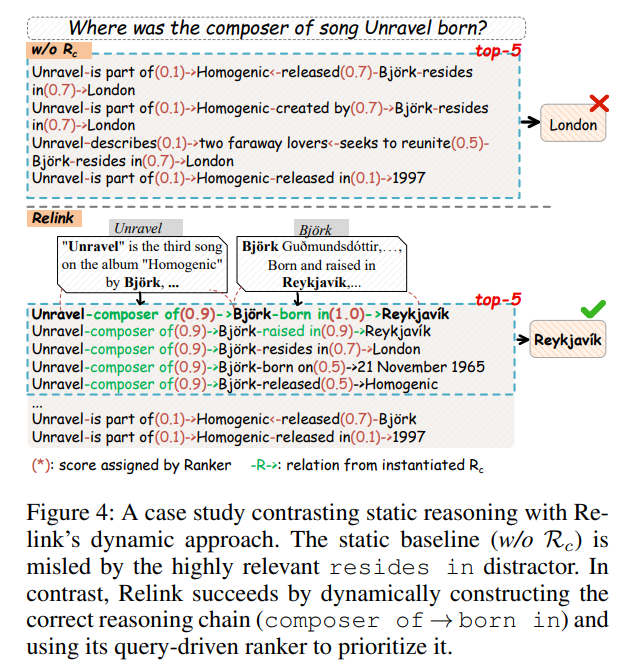
案例研究
下图对比了一个具体案例:询问“歌曲《Unravel》的创作者出生在哪里?”。静态方法(w/o R_c)被高度相关但具有误导性的“resides in London”(居住在伦敦)事实所吸引,给出了错误答案。而 Relink 则成功动态构建了“composer of → born in”的正确推理链,并通过其查询驱动的排序器优先选择了目标路径,最终指向了正确答案“Reykjavik”(雷克雅未克)。
总结与启示
Relink 通过 “推理并构建” 的新范式,实现了 GraphRAG 领域的根本性范式转变:从 “让查询适应图谱” 转变为 “让图谱为查询服务” 。其核心贡献在于:
- 动态路径修复:通过潜在关系池(R_c)按需实例化缺失链接,有效解决了静态知识图谱不完整的问题。
- 干扰事实过滤:采用查询驱动的统一评估策略,能够主动识别并丢弃那些相关但无用的误导性事实。
- 异构知识融合:高精度骨架(G_b)与高召回修补源(R_c)的协同设计,实现了覆盖率与准确率的平衡。
这项工作为复杂问答系统的设计带来了深刻启示:真正的系统鲁棒性,并非建立在知识完备的假设之上,而是体现在面对不完备信息时,能够动态构建有效推理路径的能力。 对于需要多步逻辑推理的复杂问答场景,Relink 提供了一套兼具高精确性与高覆盖率的实用解决方案,代表了下一代 自然语言处理 与知识推理系统的发展方向。
论文与代码
Relink: Constructing Query-Driven Evidence Graph On-the-Fly for GraphRAG
https://arxiv.org/pdf/2601.07192
https://github.com/DMiC-Lab-HFUT/Relink
想了解更多前沿技术解析与实践讨论,欢迎来到 云栈社区 与广大开发者一同交流。
 发表于 2026-2-4 09:11:16
|
查看: 244|
回复: 0
发表于 2026-2-4 09:11:16
|
查看: 244|
回复: 0
