在上一篇文章中,我们建立了一个核心直觉:Embedding 是把内容映射到向量空间里的一个点,距离越近含义越像。这章我们要探讨更深层的逻辑:模型凭什么知道谁该靠近、谁该远离?
答案是:Embedding 不是“天然懂语义”,而是通过对比学习训练出来的。训练过程在不断通过数据告诉模型:
- 正样本:哪些内容应该在空间中更近。
- 负样本:哪些内容应该在空间中更远。
- 度量函数:使用什么尺子来衡量远近。
- 相似定义:“相似”究竟是指同主题、同意图,还是同事实。
理解这套机制,你就能从“API 调用工程师”升级为“向量模型诊断专家”。
NLP 的大变革:Word Embedding 把“词”变成了坐标
在深度学习普及之前,计算机处理语言的方式是离散且孤立的:每个词对应一个独立的 ID,词与词之间在数学上没有距离概念(例如独热编码 One-hot Encoding)。
Word2Vec 等技术的革命性意义在于:它第一次让词语拥有了空间几何结构。
你可以这样理解:
- “猫”和“狗” 在空间里的坐标会非常接近。
- “猫”和“火车” 则会相距甚远。
这并非因为模型理解了生物学,而是因为它从海量语料库中观察到:“猫”和“狗”经常出现在相似的上下文中(例如周围常出现“宠物”、“喂食”、“毛发”等词)。
这一步意义巨大:语言不再只是枯燥的符号,而是变成了可以计算、可以度量的几何对象。
但早期词向量有一个天然限制:它无法直接处理变长的句子或段落,且无法解决多义词(如“苹果”在不同语境下的含义)的问题。
从词向量到句向量:为什么需要 Sentence/Passage Embedding
在 RAG 或语义搜索中,我们直接使用词向量会遇到两个致命问题:
问题 A:语义并非词汇的简单堆砌
“苹果总部在哪里?”和“Apple 的总部在什么地方?”。两句话词汇重合度不高,但查询意图 完全一致。简单的词袋模型或词向量加权很容易被表面词汇的差异误导。
问题 B:无法处理上下文偏移(Context Shift)
“苹果发布会”中的“苹果”是科技公司;“我吃了一个苹果”中的“苹果”是水果。静态词向量 无法区分这种差异,而现代的 Sentence Embedding 能够根据上下文动态调整整句话的表示。
因此,现代检索模型的目标是:
- Sentence Embedding:将整句话编码为一个定长向量。
- Passage Embedding:将整个段落或文档片段编码为一个定长向量。
- 核心目标:让 “语义相关” 的文本在空间中靠近,而非仅仅是“词汇重合”的文本靠近。
Bi-encoder 的核心:Query 与 Document 分开编码,用相似度匹配
在实际生产环境中,为了实现毫秒级检索,我们通常采用 Bi-encoder 架构。
Bi-encoder 的设计原则非常高效:
- 解耦编码:用编码器将 Query 映射为向量 Q,用(通常是同一个)编码器将 Passage 映射为向量 P。
- 向量匹配:使用简单的数学函数
sim(Q, P)(如余弦相似度)计算相关性。
- 大规模检索:利用向量数据库(如 Milvus, Pinecone)和 ANN(近似最近邻) 算法(如 HNSW, IVF),在数亿条数据中瞬间找到最接近的点。
为什么它在工业界不可替代?
- 预计算性:文档向量可以提前离线计算并建立索引。
- 低延迟:检索时只需实时计算一个 Query 向量。
- 可扩展性:天生适配现代向量数据库的检索结构。
对比学习:让“该近的近,该远的远”
对比学习是 Embedding 学会语义的核心手段。其目标可以概括为:给定一个锚点(Query),拉近正样本,推开负样本。
InfoNCE:在一堆干扰项中精准命中
想象模型在做一道多选题:给出一个 Query q,一个正确答案 p+,以及 n 个随机抽取的干扰项 p-。
模型的训练目标是:最大化正样本的相似度,同时最小化所有负样本的相似度。 这本质上是在优化模型在海量候选中的区分能力。
Triplet Loss:拉开安全边界
Triplet(三元组)更强调“距离差”。它要求:sim(q, p+) > sim(q, p-) + margin。
不仅要求正样本比负样本更近,还要近出一段安全间隔。这个间隔能显著提升模型在复杂排序任务中的鲁棒性。
正样本的来源:数据的质量决定能力的上限
Embedding 模型学会的“相似”定义,完全取决于你喂给它的正样本。数据可以来源于问答对、同义改写、点击日志,甚至是同一内容的不同视角。
负样本的奥秘:随机负样本 vs Hard Negative
很多人认为训练 Embedding 只要有正样本就够了,实际上,负样本的策略直接决定了模型的上限。
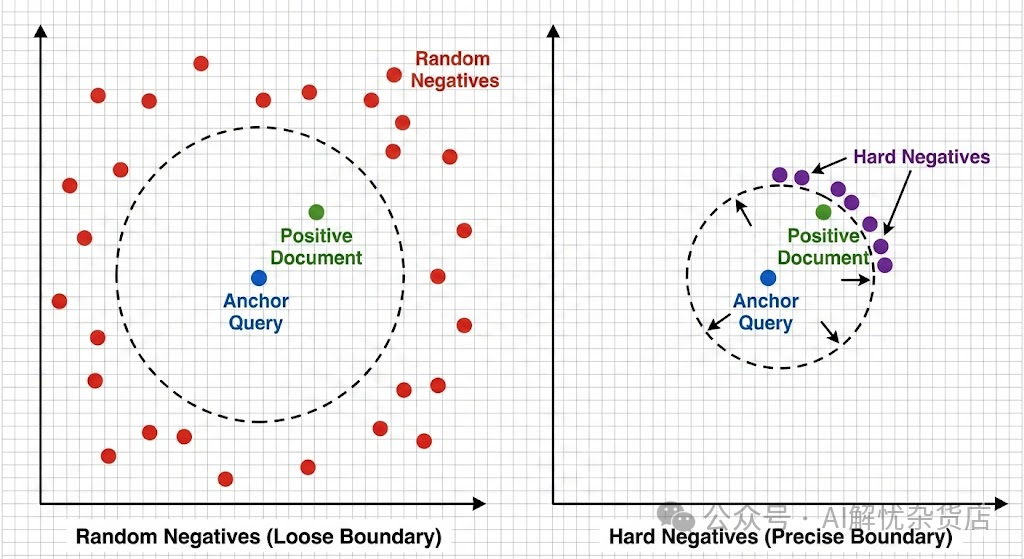
随机负样本:打好基础
从语料库中随机抽取的段落通常与 Query 毫不相关。模型很容易学会识别这种明显的差异。这能让模型学会大类语义的分隔,但无法应对精细化挑战。
Hard Negative(难负样本):进阶的关键
Hard Negative 是指那些看起来和 Query 非常像,但逻辑上不匹配的内容。
- Query: “如何办理退款?”
- 正样本: “退款操作指引。”
- Hard Negative: “退货物流查询。”(关键词高度重合,但意图完全不同)
Hard Negative 决定了检索的上限。如果模型只见过随机负样本,它上线后会频繁把“看起来像”的错误答案排在前面。随机负样本教模型“分大类”,而 Hard Negative 教模型“做精细辨析”。
训练目标如何塑造空间规则
Embedding 空间不是天然形成的,它是被训练目标塑形出来的。
- 如果你的目标是同主题,空间会按学科或行业聚类。
- 如果你的目标是同意图,空间会把“解决同一个麻烦”的话语聚在一起。
- 如果你的目标是同事实,它会成为 RAG 的利器,把问题和支撑它的证据证据紧紧绑定。
模型学到的不是语义的“终极真相”,而是在特定任务目标下的“空间组织法则”。
总结
- 对比学习是核心:通过正样本拉近、负样本推远,手动“捏”出语义空间。
- Bi-encoder 是基石:它是实现大规模、低延迟检索的工程基础。
- Hard Negative 是灵魂:只有学会区分“极度相似的错误项”,模型才能在真实场景中抗住压力。
通过深入理解这些机制,你将能更好地进行模型选型、优化训练数据,并诊断检索系统中出现的各种问题。如果你对 AI 技术、模型训练有更多兴趣,欢迎到 云栈社区 的 人工智能 板块进行更深入的交流与学习。
 发表于 2026-2-5 05:00:37
|
查看: 173|
回复: 0
发表于 2026-2-5 05:00:37
|
查看: 173|
回复: 0
