在人工智能领域,多模态信息检索一直是研究与工程的热点。我们每天接触的信息不仅是文本,还有大量的图片、视频和截图。如何让机器像人一样,高效地理解并用一种统一的“语言”来处理这些不同形态的数据,进而实现精准的“以文搜图”或“以图搜文”,是许多应用面临的挑战。
阿里通义推出的 Qwen3-VL-Embedding 系列模型,正是为了解决这一难题而生的开源利器。它基于强大的 Qwen3-VL 基础模型构建,专为处理文本、图像、可视化文档和视频等多种模态输入而设计。简单来说,它能把一张图、一段话甚至一个视频片段,都转换成一个高维的“向量指纹”,让不同形态但意义相近的内容,在这个向量空间中距离更近,从而为高效的跨模态检索奠定了基础。
一、 核心能力:不止于图文互搜
Qwen3-VL-Embedding 模型的核心设计理念是构建一个统一的语义空间,其功能亮点主要体现在以下几个方面:
- 真正的多模态输入:它不仅支持单一的文本或图像输入,还能处理图文混合、视频、截图等复杂输入模态。这意味着你可以用一个描述性的句子去搜图,也可以用一张包含文字的截图去搜索相关文档,极大扩展了应用场景的想象力。
- 统一语义表示:这是实现跨模态检索的关键。模型通过深度学习,将不同模态的数据映射到同一个语义空间,生成语义丰富的高维向量。这样,一段描述“日落海滩”的文字和一张真实的日落海滩照片,它们的向量表示在空间里就会非常接近。
- 双塔架构与高效检索:模型通常采用双塔(Dual-Encoder)架构,查询端和文档(图像/视频库)端可以独立编码,便于实现大规模向量库的预先计算和快速相似度匹配(如使用余弦相似度),非常适合需要毫秒级响应的在线检索系统。
- 灵活性与实用性:
- Matryoshka Representation Learning (MRL):支持灵活的向量维度选择(例如 64、256、1024 维等)。你可以根据存储和计算成本的限制,选择较小的维度,而无需重新训练模型,性能损失很小。
- 量化感知训练 (QAT):在训练时就考虑了模型量化(如转为 int8 格式)的影响,使得量化后的模型在保持较高性能的同时,显著降低存储占用和计算开销,更易于在资源受限的边缘设备部署。
二、 性能表现:用数据说话
模型好不好,跑个分看看。Qwen3-VL-Embedding 系列在多个权威的多模态及多语言检索基准测试中都取得了领先或极具竞争力的成绩。
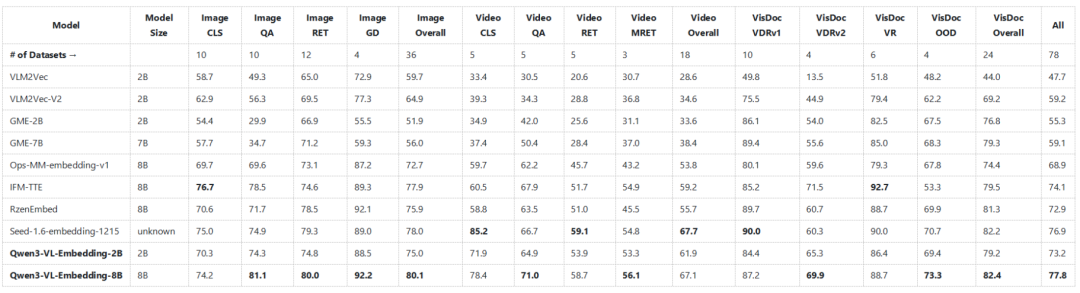
在 MMEB-V2(一个综合性的多模态嵌入评测基准)上,Qwen3-VL-Embedding-8B 模型在图像、视频、视觉文档等多种任务上的总体表现优异,超越了之前多个知名的开源多模态嵌入模型。
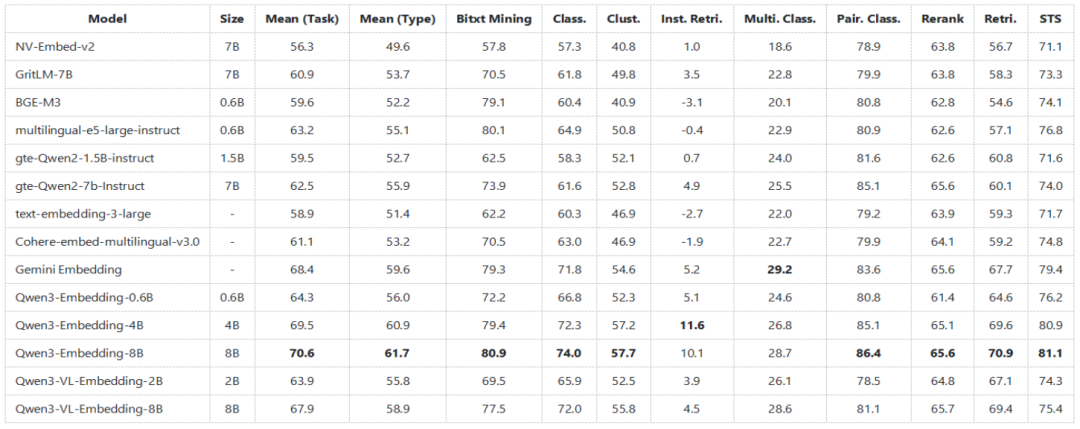
在 MTEB 多语言文本嵌入基准测试中,其纯文本嵌入能力同样出众。下图显示,即使是专注于多模态的 VL-Embedding 模型,其在纯文本任务上的表现也足以媲美甚至超越许多纯文本嵌入模型,展现了其强大的通用语义理解能力。
此外,在同系列重排序模型(Reranker)的对比中,Qwen3-VL-Reranker 也展现出强大的性能,能够对初步检索结果进行更精细的排序,进一步提升最终检索精度。

三、 应用场景:从想法到落地
有了强大的模型能力,它能用在哪些实际场景中呢?
- 增强型图文/视频检索:这是最直接的应用。电商平台可以用它实现更精准的“以图搜款”或“用文字描述找商品”;内容平台可以构建跨模态的搜索引擎,让用户用一句话找到相关的视频片段或新闻图片。
- 智能视觉问答 (VQA):结合检索与生成模型,可以构建这样的系统:用户上传一张设备故障图并问“可能是什么问题?”,系统先通过 Qwen3-VL-Embedding 从知识库中检索出相似的故障案例和解决方案,再交由大模型生成回答。
- 多模态内容管理与知识库:企业内部的文档往往包含大量截图、图表和文字。该模型可以自动为这些多模态内容生成语义向量,实现智能分类、聚类和关联,让知识查找不再局限于关键词匹配。
- 跨模态推荐系统:在内容平台,可以根据用户刚看过的视频,推荐语义相关的文章或图片,提供更沉浸和连贯的内容消费体验,这背后就需要跨模态的语义理解作为支撑。
四、 快速上手:三步跑通Demo
如果你已经心动,想亲手试试这个强大的开源模型,以下是快速上手的步骤。
1. 环境准备
克隆项目仓库并安装依赖:
git clone https://github.com/QwenLM/Qwen3-VL-Embedding.git
cd Qwen3-VL-Embedding
bash scripts/setup_environment.sh
source .venv/bin/activate
2. 下载模型
你可以通过 Hugging Face CLI 方便地下载模型,例如下载 2B 版本的模型:
huggingface-cli download Qwen/Qwen3-VL-Embedding-2B --local-dir ./models/Qwen3-VL-Embedding-2B
3. 运行示例代码
使用以下 Python 代码加载模型并进行简单的跨模态嵌入计算:
import torch
from src.models.qwen3_vl_embedding import Qwen3VLEmbedder
model = Qwen3VLEmbedder(model_name_or_path="./models/Qwen3-VL-Embedding-2B")
inputs = [
{"text": "A woman playing with her dog on a beach at sunset."},
{"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}
]
embeddings = model.process(inputs)
print(embeddings @ embeddings.T) # 计算相似度矩阵
这段代码会分别生成一段文本和一张图片的向量,并计算它们之间的相似度。理论上,如果图片内容与文本描述相符,它们的向量点积(相似度)会较高。
五、 总结与资源
Qwen3-VL-Embedding 的出现,为开源社区提供了一个强大且实用的多模态信息检索基础工具。它通过统一语义空间、支持灵活部署等技术,有效降低了跨模态理解与检索的应用门槛。无论是用于研究还是具体的产品开发,它都是一个值得深入探索的选项。
对于希望深入研究多模态和信息检索技术的开发者,理解其背后的双塔架构、对比学习以及 MRL 等思想,也大有裨益。
相关资源
希望这篇介绍能帮助你快速了解 Qwen3-VL-Embedding。在实际项目中遇到任何技术问题或想分享你的使用经验,欢迎到 云栈社区 的相关板块与众多开发者一起交流探讨。
 发表于 2026-1-31 10:22:46
|
查看: 178|
回复: 0
发表于 2026-1-31 10:22:46
|
查看: 178|
回复: 0
