
大语言模型(LLMs)推理能力强,但幻觉和知识过时的问题也一直存在。基于知识图谱(KG)的检索增强生成(RAG)方法,试图用结构化的外部知识为LLM的回答“打地基”。不过,现有方法在检索多少图信息给LLM“消化”这件事上,总在效果和效率之间左右为难:给多了冗余且计算贵,给少了又可能漏掉关键信息。
佐治亚理工学院的研究团队最近提出了一种新框架——SubgraphRAG。它核心思路很清晰:先为问题精准抓取一个相关子图,再让LLM基于这个子图进行推理。这个方法在检索和推理两端都有创新,不仅效果拔群,还能让像Llama3-8B这样的小模型都发挥出不错的推理能力,而像GPT-4o这样的大模型则能刷出最先进的准确率,关键是这一切都无需对LLM进行微调。
核心看点
研究背景与难点
- 核心问题:如何设计一个基于知识图谱的RAG系统,既能高效检索出最相关的结构化知识,又能充分发挥LLM的推理能力,从而显著减少幻觉?
- 主要挑战:
- 检索的精度与召回:从庞大的知识图谱中,如何精准定位并抽取出与复杂多跳查询真正相关的子图,避免引入噪声?
- 效率与可扩展性:检索过程需要足够轻量、快速,才能适应实际应用场景。
- 与LLM的协同:如何将检索到的图结构信息,以LLM易于理解和利用的方式(如自然语言提示)进行呈现,激发其推理能力?
SubgraphRAG如何工作?
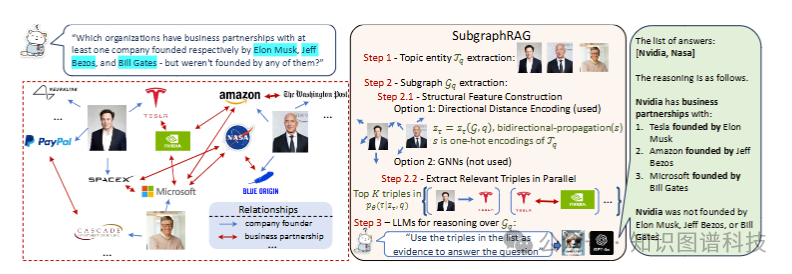
整个流程分为三大步:
第一步:提取主题实体
从用户问题中识别出关键的主题实体(例如,“Elon Musk创立的公司”中的“Elon Musk”)。
第二步:检索相关子图
这是SubgraphRAG的创新核心。它采用了一个轻量级的多层感知器(MLP)结合并行三元组评分机制,高效地对知识图谱中数百万计的三元组进行相关性打分。
- 定向距离编码(DDE):为了让模型理解图谱中的结构关系,SubgraphRAG引入了DDE。它编码了从主题实体到其他实体的方向性路径距离,帮助模型更好地区分“朋友的朋友”和“朋友”之间的区别,这对于处理多跳问题至关重要。
- 灵活的子图大小:系统可以根据查询的复杂度和下游LLM的处理能力,动态调整检索出的子图(三元组)数量,实现效率与效果的平衡。
第三步:LLM进行推理与回答
将检索到的高分三元组线性化(例如,(Tesla, foundedBy, Elon Musk)),并嵌入到一个设计好的提示模板中,交给LLM进行最终推理并生成答案。一个简化的提示模板示例如下:
System: Based on the triples retrieved from a knowledge graph, please answer the question. Please return formatted answers as a list, each prefixed with “ans:”
User:
Triples: (Tesla, foundedBy, Elon Musk) (Amazon, foundedBy, Jeff Bezos) ...
Question: Which organizations have business partnerships with at least one company founded respectively by Elon Musk, Jeff Bezos, and Bill Gates - but weren‘t founded by any of them?
效果怎么样?
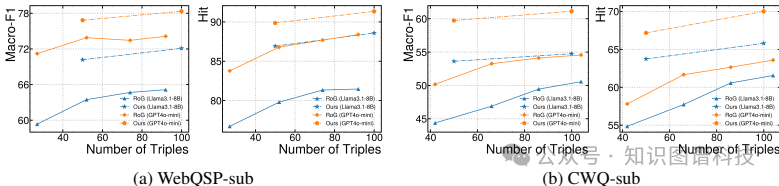
研究团队在WebQSP和CWQ这两个经典的知识图谱问答基准上进行了全面测试。
1. 检索效果卓越
SubgraphRAG在检索相关证据(三元组)方面,显著优于传统的基于文本相似度的方法(如余弦相似度)以及其他图检索基线。特别是在处理需要多步推理(多跳)的问题时,优势更加明显。
2. 最终答案准确率领先
得益于高质量的检索结果,即使使用未微调的通用LLM,SubgraphRAG生成的答案也极具竞争力。
- 使用GPT-4o作为推理引擎时,SubgraphRAG在CWQ数据集上取得了当前最优的准确率。
- 更有意思的是,使用较小的Llama3-8B-Instruct模型时,其表现也能与一些使用更大模型或专门微调过的基线方法相媲美,并且能提供可解释的推理链。
3. 有效减少幻觉
因为答案严格基于检索出的知识图谱事实,SubgraphRAG生成的回答“信口开河”的情况大大减少,回答的可靠性和事实准确性显著提升。
优势与启示
- 简单且有效:核心检索器采用轻量级MLP,避免了复杂的图神经网络(GNN),训练和推理效率高。
- 检索与推理解耦:将复杂的图结构检索任务交给专门的模块,让LLM专注于它擅长的语言理解和推理,这种分工协作模式非常高效。
- 即插即用:完全不需要对LLM进行任何微调,保持了基础模型的通用性,并能与任何最新的黑盒LLM(如GPT-4)快速集成。
- 可控可解释:通过调整检索的三元组数量,可以控制输入LLM的信息量,并且最终的推理过程基于提供的证据,更具可解释性。
这项研究展示了将知识图谱的结构化知识与大语言模型的强大推理能力相结合的巨大潜力。SubgraphRAG为构建更可靠、更准确的知识增强AI系统提供了一个颇具前景的技术方向。
对于想深入了解实现细节或复现实验的开发者,可以访问其开源项目:https://github.com/Graph-COM/SubgraphRAG。如果你对这类结合了图技术与大模型的前沿应用感兴趣,欢迎在云栈社区的人工智能板块与我们继续交流讨论。
 发表于 2026-3-19 02:15:38
|
查看: 188|
回复: 0
发表于 2026-3-19 02:15:38
|
查看: 188|
回复: 0
