在AI大模型训练与推理席卷行业的当下,传统内存架构正面临严峻挑战:DDR内存带宽增长缓慢,HBM内存单栈容量有限,难以同时满足新兴工作负载对大容量与高带宽的双重渴求。
CXL(Compute Express Link)作为新一代高速互连协议,为内存扩展开辟了新路径。而由Wolley提出的NVMe-over-CXL (NVMe-oC) 内存模式,则是一种将DRAM与NAND SSD在物理和协议层面深度融合的创新架构。它究竟如何运作?其宣称的“主机管理分层”策略,相比传统的设备管理缓存有何优势?从FPGA原型到ASIC量产,性能又将获得多大提升?本文将结合详细的测试数据,为你深入剖析。

内存演进之困:带宽墙与容量墙并存
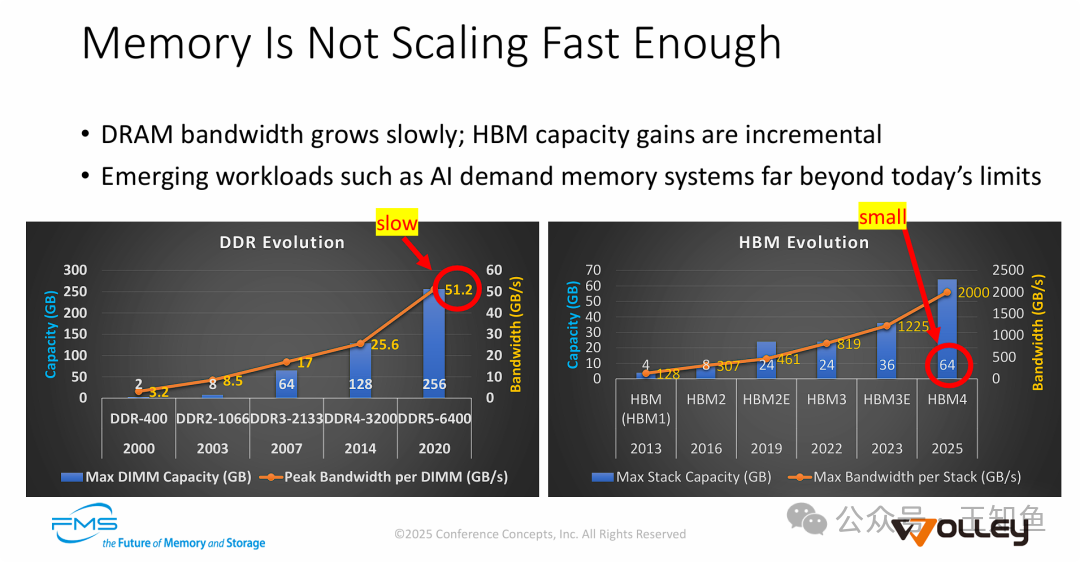
当前的存储器层次结构主要面临两大瓶颈:
- DDR内存的“带宽墙”:尽管单条DDR5 DIMM的容量可达256GB,但其峰值带宽(51.2 GB/s)的增长速度,远落后于AI计算对数据吞吐的爆炸性需求。
- HBM内存的“容量墙”:HBM虽然提供了极高的带宽(HBM4预计可达2000 GB/s),但单堆栈容量受限(HBM4约为64GB),难以容纳参数规模不断膨胀的大模型。
这种“一个慢,一个小”的局面,催生了业界对新型内存扩展方案的迫切需求,CXL及基于其的混合内存架构正是解决之道。
什么是NVMe-over-CXL (NVMe-oC)?
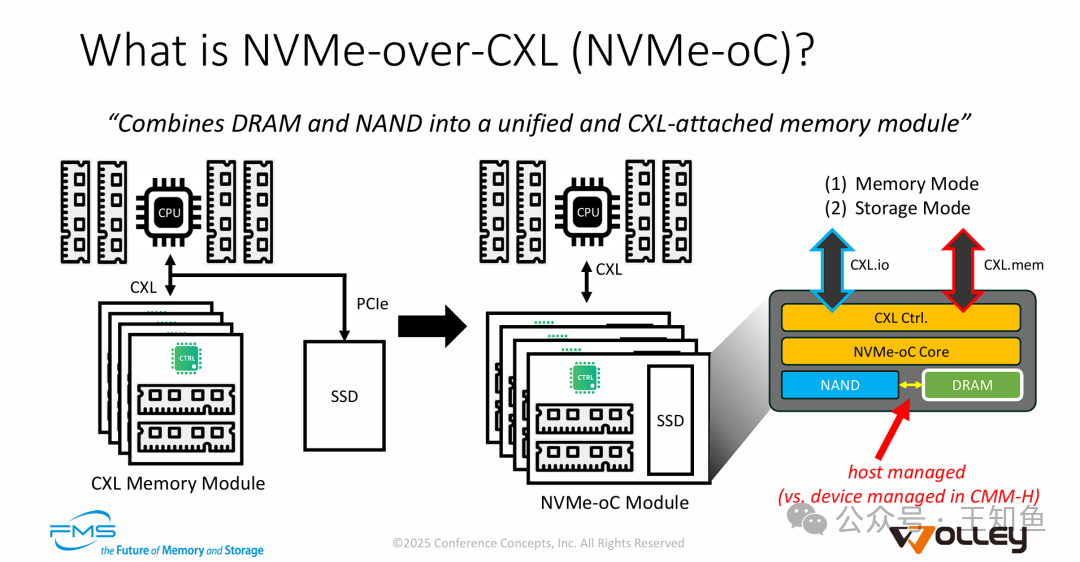
NVMe-oC的核心思想是将DRAM和NAND SSD融合到一个统一的、通过CXL接口连接的设备模块中。其技术要点包括:
- 物理与协议融合:在同一张卡上集成DRAM和SSD,通过CXL协议栈同时支持 CXL.mem(用于低延迟内存访问)和 CXL.io(用于存储类访问与管理),复用物理链路。
- 主机主导的分层管理 (Host-Managed):这是与三星CMM-H等“设备管理缓存”方案的关键区别。NVMe-oC让主机操作系统或驱动软件能够明确感知并智能管理DRAM(作为缓存)和NAND(作为容量层)之间的数据流动,而非依赖设备内部的黑盒控制器。
简单说,NVMe-oC是一种允许主机软件直接、灵活地管理混合内存资源的CXL Type 3设备。
NVMe-oC内存模式:构建三级存储金字塔
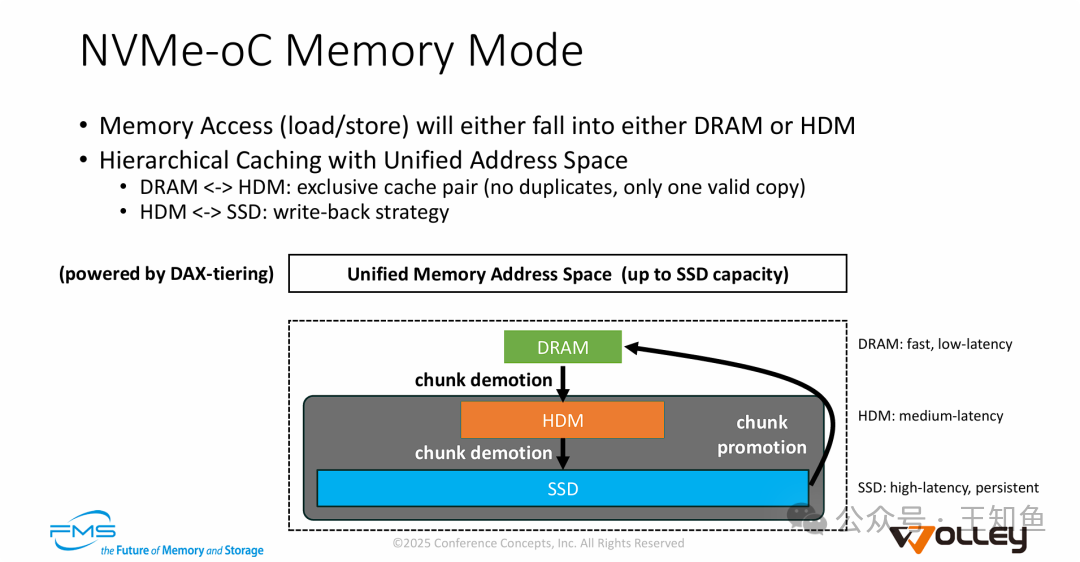
NVMe-oC的内存模式旨在将大容量SSD“变身”为系统可用的内存。其机制如下:
- 三级混合架构:系统构建了从主机DRAM(最快) -> 设备DRAM/HDM(高速) -> 设备SSD(大容量) 的存储层次。
- 统一地址空间与DAX-Tiering:通过DAX-tiering等技术,对上层应用呈现一个统一的、容量高达SSD级别的内存地址空间,无需修改应用代码。
- 智能数据调度:
- 独占式缓存:主机DRAM与设备HDM之间采用独占缓存策略,避免数据冗余,最大化高速缓存容量。
- 动态升降级:热数据通过“晋升”(promotion)驻留DRAM,冷数据通过“降级”(demotion)下沉至SSD,实现性能与容量的平衡。
实验环境与基准测试
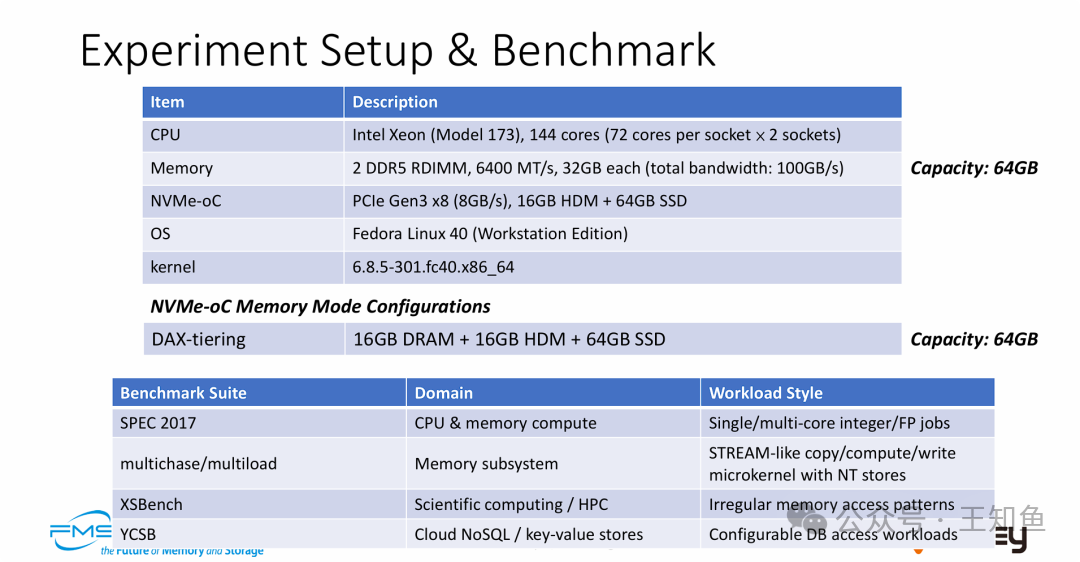
为了全面评估NVMe-oC,测试搭建了一个异构环境:
- CPU: Intel Xeon, 144核
- 内存: 64GB DDR5 (100GB/s总带宽)
- NVMe-oC设备: PCIe Gen3 x8接口 (8GB/s),含16GB HDM + 64GB SSD
- 配置: DAX-tiering模式,呈现64GB统一内存空间
- 测试套件:
- SPEC CPU 2017: 衡量通用计算性能
- multichase/multiload: 测试内存子系统微操作
- XSBench: 代表HPC不规则内存访问模式
- YCSB: 模拟云数据库键值存储负载
性能深度剖析
1. 最佳场景:近原生DRAM性能
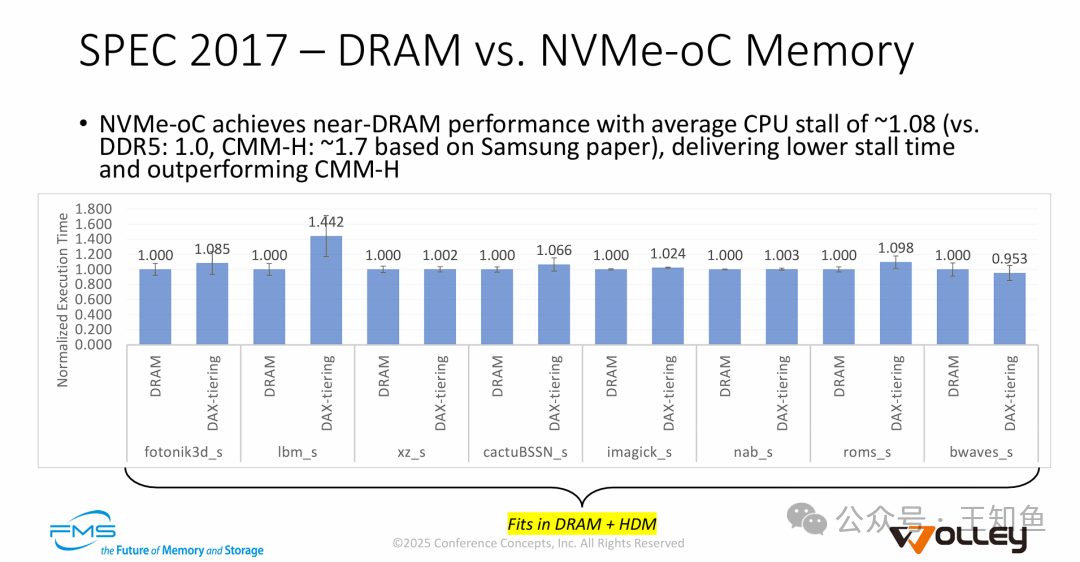
当工作集完全容纳在高速缓存层(主机DRAM + 设备HDM,本例共32GB)时,NVMe-oC表现惊艳。
- 在SPEC CPU 2017测试中,平均性能仅比纯DDR5配置慢8% (CPU停顿约1.08倍)。
- 这一结果远优于基于公开论文数据的CMM-H方案(约1.7倍停顿)。
- 结论:在缓存命中场景下,主机管理分层策略能高效掩盖CXL链路延迟,提供近乎原生的内存体验。
2. 压力测试:界定性能边界
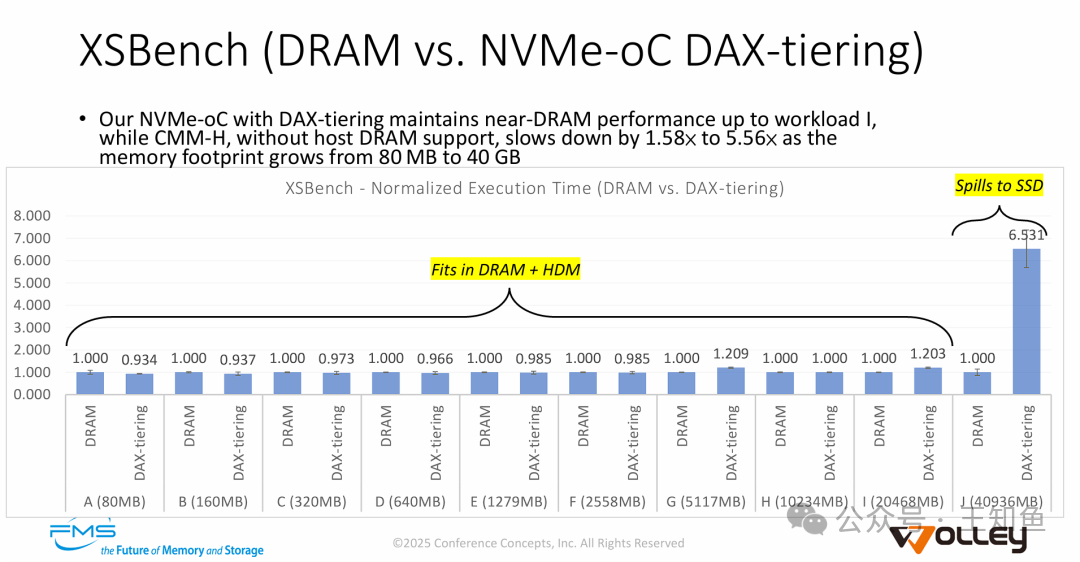
XSBench测试清晰展示了方案的适用边界:
- 缓存有效期内:当数据量未超过32GB时,性能与DRAM几乎持平(1.0x-1.2x),显著优于CMM-H(从80MB负载起就出现1.58x slowdown)。
- 触及性能悬崖:当工作集增长至40GB并溢出到SSD时,性能出现显著下降(延迟增加6.5倍)。这如实反映了NAND Flash与DRAM之间的物理速度鸿沟。
- 洞察:NVMe-oC非常适合工作集大部分时间能落在高速层内,但需要大容量后备的应用。
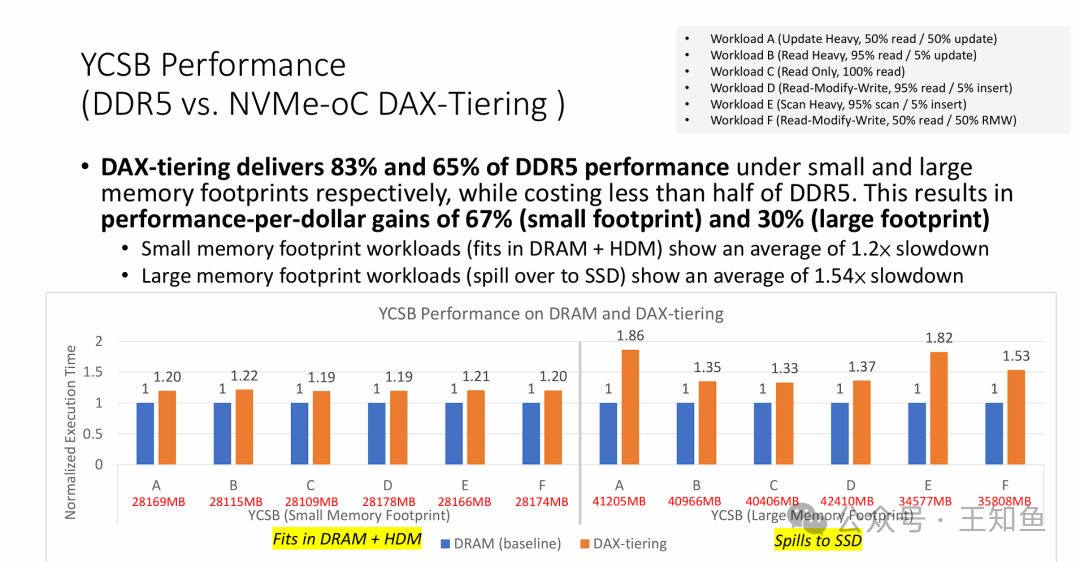
在更贴近实际业务的YCSB数据库测试中,NVMe-oC展现了强大的商业吸引力:
- 小内存足迹(未溢出SSD):达到DDR5 83% 的性能。
- 大内存足迹(溢出到SSD):达到DDR5 65% 的性能。
- 核心优势:由于大量使用廉价NAND替代昂贵DRAM,硬件成本降低一半以上。换算成功率-每美元收益,带来了67%(小足迹)和30%(大足迹)的提升。对于追求TCO优化的数据中心而言,这是关键价值。
4. 从FPGA到ASIC:释放全部潜力
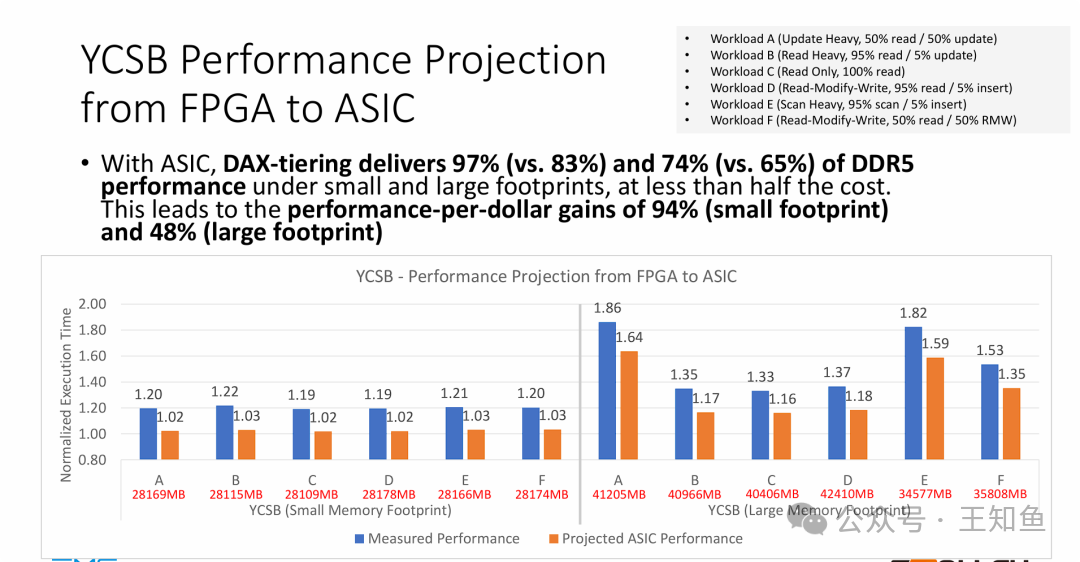
测试中约20%的性能开销部分源于FPGA原型机的限制。迁移至专用ASIC后,性能预计将大幅提升:
- 小内存足迹性能:从DDR5的83%提升至97%。
- 大内存足迹性能:从65%提升至74%。
- 性价比增益:进一步跃升至94%(小足迹)和48%(大足迹)。
FPGA与ASIC的关键差异对性能的影响:
| 对比项 |
FPGA 特性 |
ASIC 特性 |
对性能的影响 |
| 时钟频率 |
通常运行在250-500MHz |
可轻松达到1GHz以上 |
主频提升直接大幅降低处理延迟。 |
| 逻辑与布线延迟 |
信号路径绕行,延迟大(几十纳秒) |
物理路径最短,延迟极低(几纳秒) |
对于纳秒级的内存访问至关重要。 |
| CXL PHY/控制器 |
通用软核实现,有转换开销 |
专用硬化电路,极致优化 |
消除了大部分“非介质层面”的协议处理开销。 |
ASIC化意味着NVMe-oC能够以接近零额外开销的姿态,提供逼近原生内存的性能,是其走向大规模商用的关键一步。
与CMM-H的正面较量

与三星CMM-H方案的直接对比,凸显了NVMe-oC架构的优势:
- SPEC CPU 2017: NVMe-oC平均慢8.4%,而CMM-H平均慢70%。
- XSBench (小负载): NVMe-oC保持1.0x,CMM-H起步即为1.58x。
- 结论:在通用计算和缓存命中场景下,NVMe-oC凭借主机管理缓存带来的“近原生”体验,性能优势显著。
特性对比:架构差异的本质
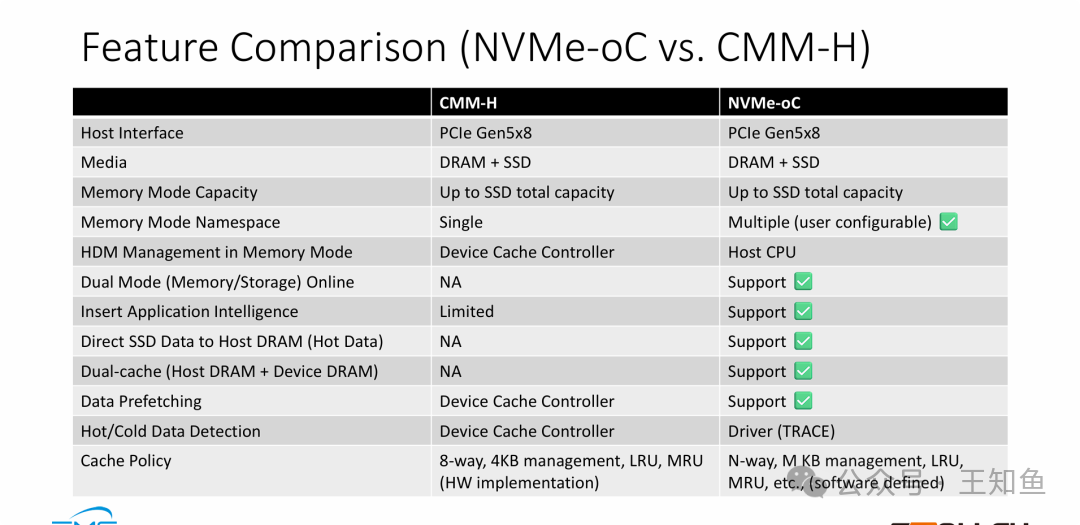
性能差异根植于底层架构与管理的不同:
- 软件定义 vs 硬件固化:CMM-H依赖设备内固定策略的硬件缓存控制器;NVMe-oC将管理权交予主机软件,支持可自定义的缓存粒度、算法,灵活性极高,实现了软件定义内存的雏形。
- 三层架构 vs 两层缓存:NVMe-oC独有 “双缓存” 和 “SSD数据直通主机DRAM” 能力,构建了SSD -> 设备DRAM -> 主机DRAM的完整链路,利用最快的主机DRAM作一级缓存,是性能领先的关键。
- 双模式在线:NVMe-oC支持同时作为内存和存储设备使用,提供部署灵活性。

注:CMM-H作为三星CXL设备组合中的分层内存解决方案,其设计更侧重于设备端的管理。
技术总结与展望

Wolley NVMe-oC内存模式的价值主张可总结为三点:
- 高性价比的内存扩展:为数据密集型应用提供成本效益极高的CXL内存扩容方案,性价比提升可达30%-90%。
- 主机管理的缓存智能:通过联合调度主机DRAM、设备DRAM和NAND,在缓存命中时提供近原生性能,在数据溢出时通过智能策略优于传统设备管理方案。
- 无缝应用集成:无需修改现有应用程序代码即可享受大内存容量,降低了部署门槛。
延伸思考
NVMe-oC技术为我们打开了新的想象空间:
- “主机管理分层”策略在大规模集群中如何实现集中调度与资源平衡?其与现有Linux内存管理子系统的深度融合会面临哪些挑战?
- ASIC的高成本会如何影响该技术在中小型数据中心的普及?是否存在基于DPU或智能网卡的分层管理折中方案?
- 除了AI与数据库,在科学计算、流数据处理、内存分析等领域,NVMe-oC是否也能发挥独特优势?它与存内计算(PIM)、持久内存(PMem)等技术是竞争还是互补关系?
技术的演进总是伴随着新的问题与机遇。NVMe-oC能否重塑下一代数据中心的内存架构,我们拭目以待。对于这类前沿硬件与系统软件的结合,欢迎在云栈社区继续深入探讨。
原文参考:System Test Results with NVMe-over-CXL (NVMe-oC) Memory Mode |  发表于 2026-2-7 04:05:58
|
查看: 179|
回复: 0
发表于 2026-2-7 04:05:58
|
查看: 179|
回复: 0
