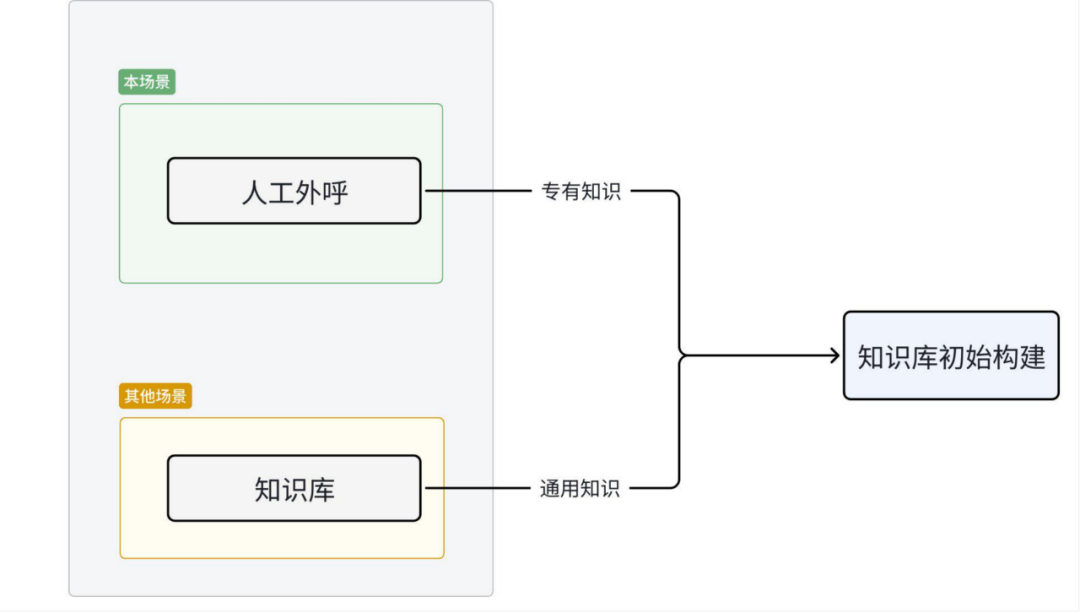
 图1 知识库初始构建
图1 知识库初始构建
在货拉拉的业务场景中,知识库的初始构建主要依赖两种方式:从本场景的人工外呼中提炼专有知识,以及从其他场景的知识库迁移通用知识。这一过程高度依赖人工整理与标注。
初始构建的知识库通常包含三个核心部分:相似问法、意图和标准话术(如图2所示)。在线上服务环节,RAG(检索增强生成)技术会召回相关的意图、相似问法及标准话术,并将其拼接至提示词(Prompt)中,最终由大语言模型(LLM)生成回复话术。因此,确保知识库中“相似问法 - 意图 - 标准话术”三者映射关系的准确性至关重要。
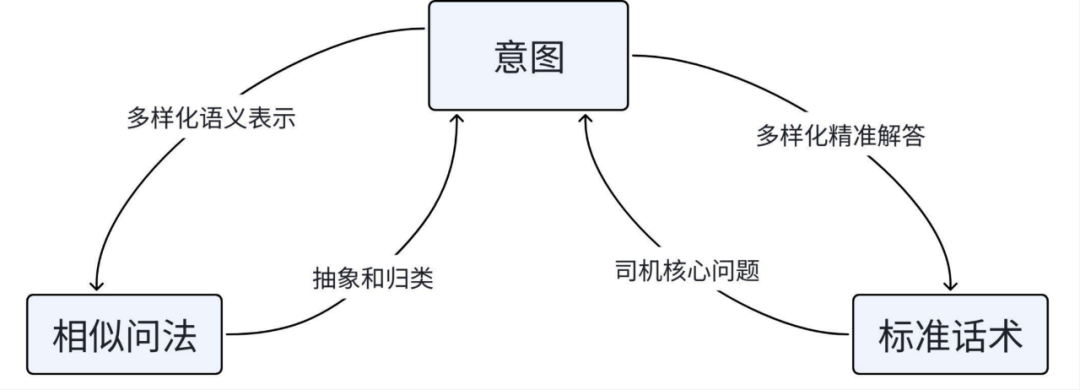 图2 相似问法、意图、标准话术的映射关系
图2 相似问法、意图、标准话术的映射关系
示例:
- 相似问法:
- “你们帮我订阅这个路线需不需要收费,你说?”
- “你先说订阅这个收不收费。”
- 意图:询问订阅路线是否收费
- 标准话术:
- “自动订阅是不收费的。”
- “不收费的。”
- “自动订阅是完全免费的,不收您钱。”
然而,由于人工构建存在人力资源限制和主观性,初始知识库常出现以下三类典型问题:
1. 意图名定义不清晰
意图名称无法准确概括相似问法的核心语义,导致LLM生成的话术不合理,需重新定义意图名。
例如,下图中的相似问法实际语义是“质疑来电的真实性”,但意图名被定义为“来电目的”,语义概括不准,导致回复话术偏离预期。
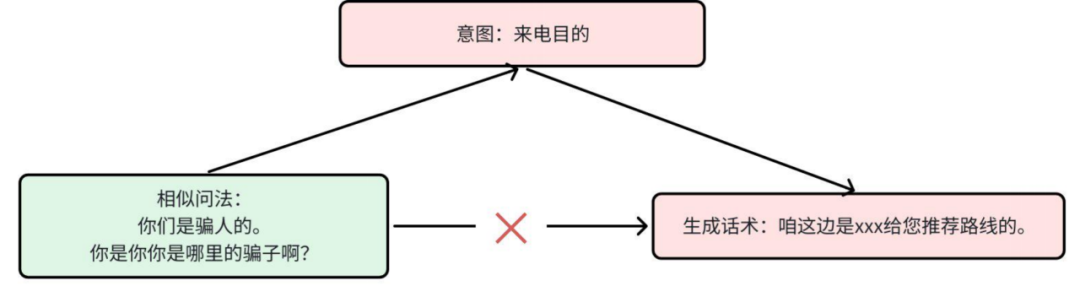 图3 意图名定义不清晰示例
图3 意图名定义不清晰示例
2. 相似问法与意图话术不匹配
相似问法被错误归类到某个意图下,导致LLM参考错误的标准话术进行回复,出现“答非所问”的情况。
如下图,相似问法被错分至“车子有货了”意图,而该意图的标准话术显然不适用于此问法。
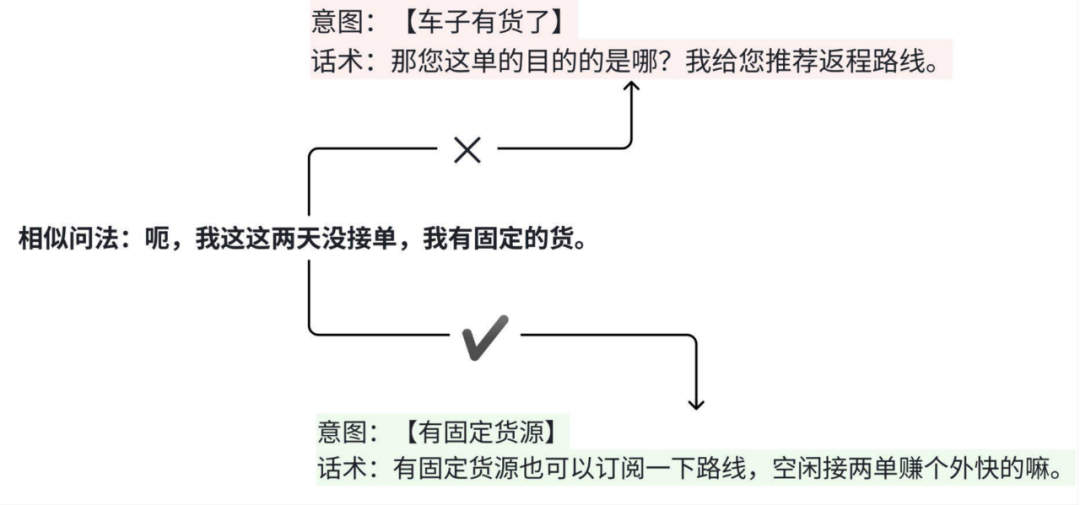 图4 相似问法与意图话术不匹配示例
图4 相似问法与意图话术不匹配示例
3. 意图过于概括
一个意图下包含了语义差异较大的多种相似问法,而单一的标准话术无法做到精准回复,需要对意图进行细分。
例如,下图“没出车”意图中,包含了住院、在老家、修车、下大雪等多种不同原因,统一回复的话术无法满足个性化需求。
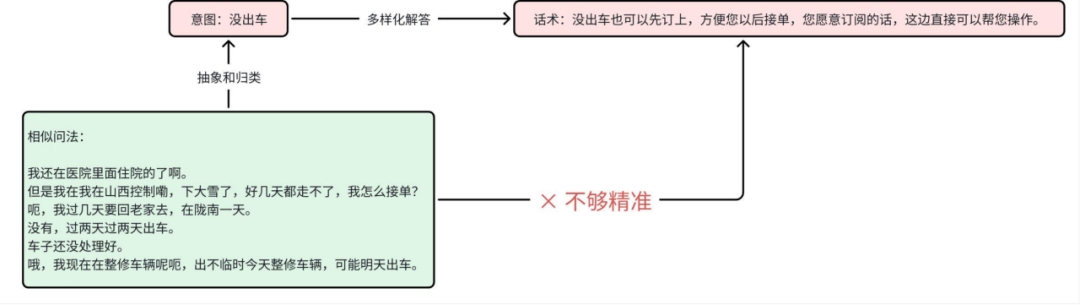 图5 意图过于概括示例
图5 意图过于概括示例
二、解决方案
针对知识库清洗,业界主要有两种技术路径:
2.1 方案一:嵌入模型+聚类
该方案首先使用嵌入模型将文本(相似问法)映射为高维向量,然后在向量空间中使用聚类算法(如K-Means、DBSCAN)进行分组,以期自动发现并合并语义相似的问法。
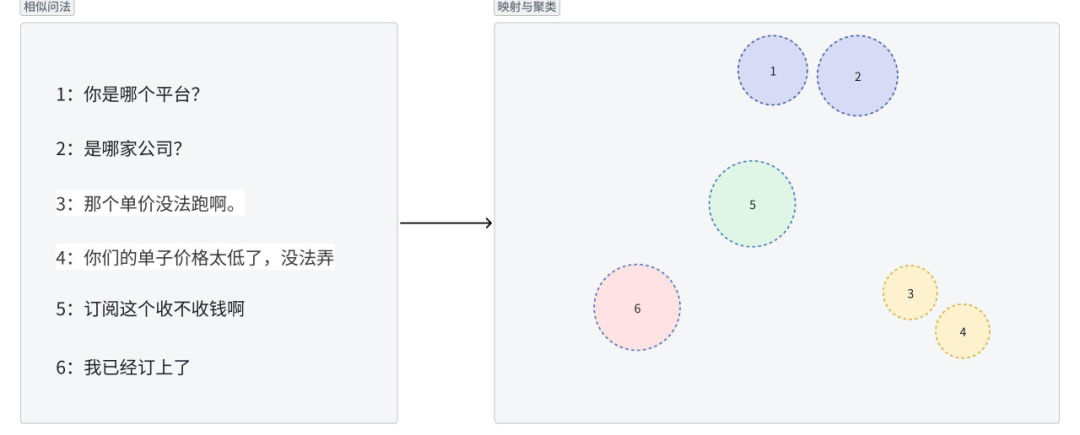 图6 利用嵌入模型清洗知识库的形式化表示
图6 利用嵌入模型清洗知识库的形式化表示
在模型选型阶段,经过综合评估,Qwen3-Embedding-8B在多项聚类任务评测中表现最佳,因此我们首选该模型进行实践。
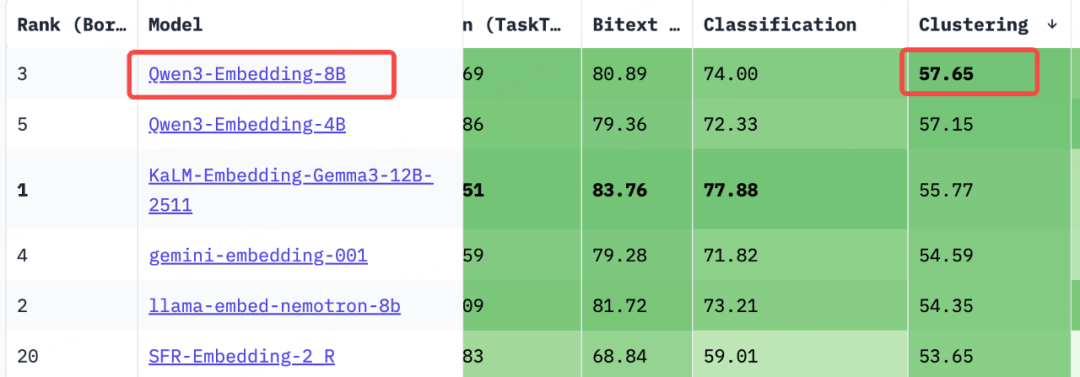
但在实际应用中,我们发现Qwen3-Embedding-8B的语义理解深度仍有局限,且聚类算法本身存在“类别数量不可控”和“聚类后类别语义不明确”的固有问题。这直接导致相似问法重新归类的准确率很低,且意图自动细分的结果过于琐碎,不符合业务逻辑。因此,我们转向了方案二。
2.2 方案二:大模型语义理解
本方案的核心思路是充分利用大语言模型(LLM)强大的语义理解与推理能力,辅助人工进行知识库清洗,从而大幅提升清洗效率与质量。

1. 重新定义意图名
结合LLM与领域知识,对模糊的意图名进行优化。
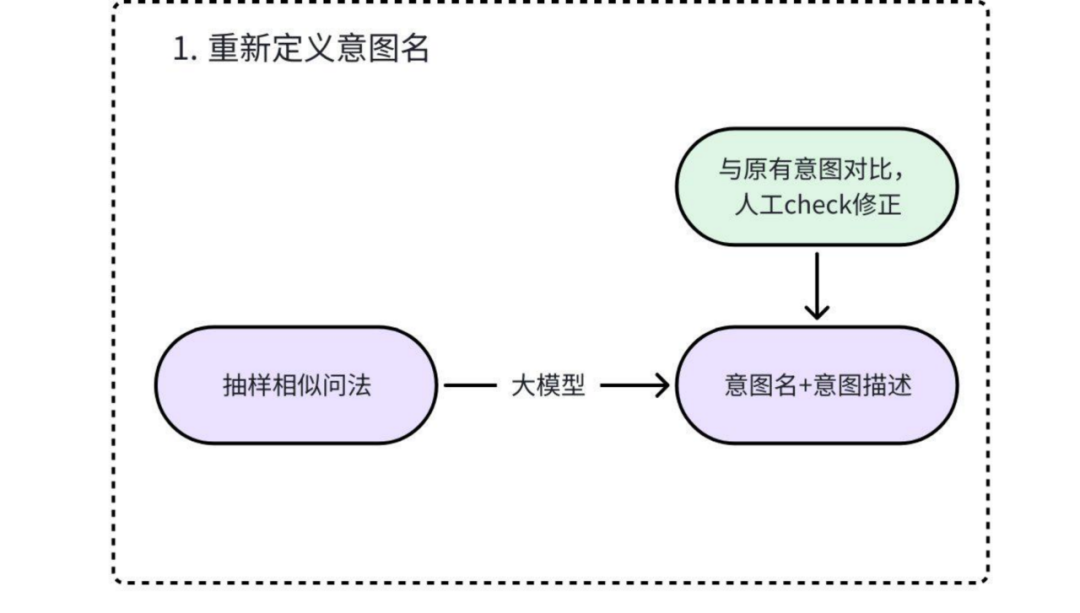
- a. 少量样本初始化:从现有知识库中抽取少量样本,输入给LLM,由其生成初步的意图名称和意图描述。
- b. 人工校验:业务专家根据领域知识,对LLM生成的意图名进行二次校验和修正,确保其能精准概括该类别下所有相似问法的核心语义。
2. 相似问法重新归类
利用“LLM + 精心设计的Prompt”对相似问法进行重新分类。此时,Prompt中对每个意图的描述是否精准,直接决定了分类的准确性。
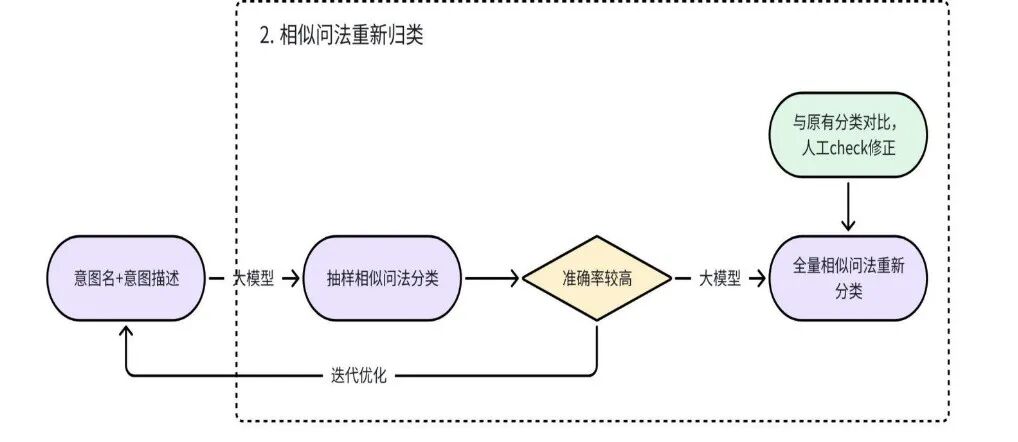
- a. 迭代优化意图描述:抽样部分相似问法,通过多次人工调整和测试,不断迭代优化Prompt中各个意图的描述文本,以提升LLM的分类准确率。
- b. 全量分类与人工复核:使用优化后的Prompt对全量相似问法进行分类。由于准确率难以达到100%,我们仍需对分类结果发生变更的条目进行人工二次校验,确保数据库中每条数据的归属正确。
3. 意图细分
对于过于宽泛的意图,利用LLM提供细分方案,再由人工最终定案。
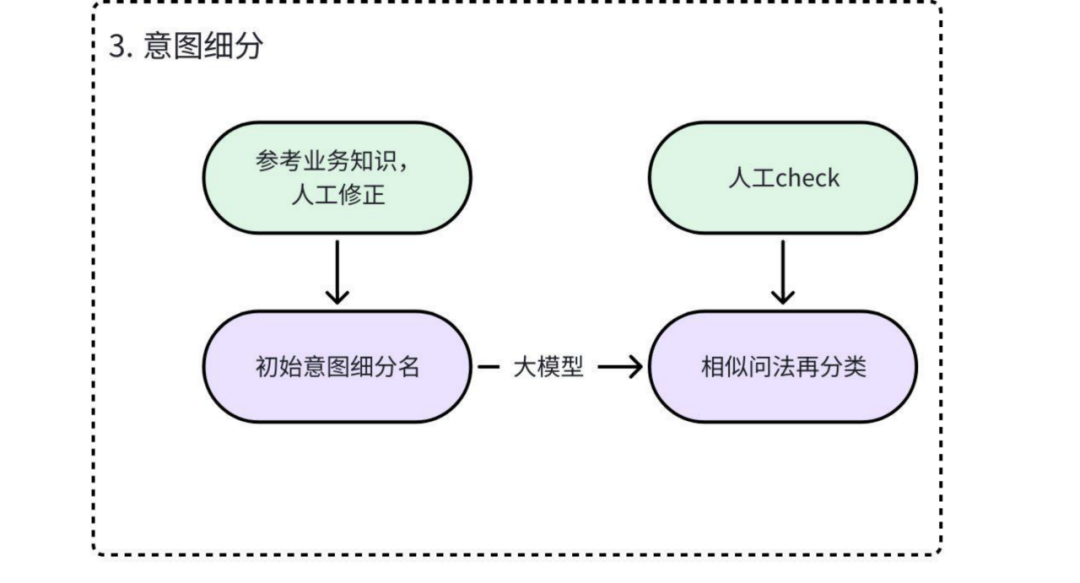
- a. 初始化意图细分:将需要细分的意图及其下的相似问法提交给LLM,要求其根据问法语义的差异,提供初步的细分方案(如细分维度、细分后的意图名)。
- b. 人工优化确认:业务专家对LLM的细分方案进行评审,合并、拆分或重命名,确保最终的细分结果既符合语义区分度,也满足业务运营的实际需求。
4. 话术生成
利用LLM的生成能力,辅助创建多样化的标准话术。
为海量意图逐一编写多种话术是繁重的人力工作。我们可以基于清洗后的意图和其语义描述,结合场景知识(如邀约话术规范),让LLM为每个意图生成若干条初始话术,再由人工进行筛选和润色,保证话术的准确性与得体性。
三、实践成果
1. 意图名定义不清晰
通过合并语义相似的意图,并为每个意图优化命名,解决了定义模糊的问题。
- 优化前意图:【来电目的】
- 优化后意图:【怀疑来电真实性】
- 相似问法示例:
2. 相似问法与意图不匹配
通过明确意图边界并对相似问法进行再分类,提升了映射准确性。在本次实践中,我们对10%的相似问法进行了重新归类,准确率达到65%。
- 原错误意图:【车子有货了】
- 正确归类意图:【有固定货源】
- 相似问法示例:“呃,我这这两天没接单,我有固定的货。”
3. 意图过于概括
根据司机情绪、具体原因、产品维度等对粗粒度意图进行拆分,使回复更具针对性。本次对63%的意图进行了细分,原有44个意图类别细分为89个。
- 原始概括意图:【没出车】
- 相似问法混杂:我还在医院里面住院的了啊。/ 但是我在我在山西控制嘞,下大雪了,好几天都走不了,我怎么接单?/ 呃,我过几天要回老家去,在陇南一天。/ 没有,过两天过两天出车。/ 车子还没处理好。/ 哦,我现在在整修车辆呢呃,出不临时今天整修车辆,可能明天出车。
- 细分后意图示例:
- 【车辆故障或维修】:车子还没处理好。/ 哦,我现在在整修车辆呢呃,出不临时今天整修车辆,可能明天出车。
- 【生病住院】:我还在医院里面住院的了啊。
- 【在老家】:呃,我过几天要回老家去,在陇南一天。
- 【外部原因】:但是我在我在山西控制嘞,下大雪了,好几天都走不了,我怎么接单?
- 【暂时未出车】:没有,过两天过两天出车。
四、未来展望
1. 自动提示词优化
当前在“相似问法重新归类”环节,意图描述的优化严重依赖人工调整。未来可以探索自动提示词优化技术,让系统能自动迭代并找到分类效果最佳的Prompt表述,进一步提升自动化水平。
2. 处理复杂语义问法
针对一条相似问法中同时涵盖多个意图的复杂情况,未来可以考虑利用LLM的语义解析能力,将复合问法拆解,并将其组成部分分别归入对应的意图相似问法库中,使知识库的覆盖更细致、更智能。
 发表于 2025-12-4 01:57:50
|
查看: 195|
回复: 0
发表于 2025-12-4 01:57:50
|
查看: 195|
回复: 0
