随着人工智能计算规模的爆炸式增长,单个数据中心的功率和工程承载能力正迅速接近极限。NVIDIA正在将网络扩展的边界,从“数据中心内部”推向“城域级”。MetroX-2系统正是这一战略转变的典范:它不再将跨数据中心互联视为一种性能上的妥协,而是以人工智能工作负载为中心,重新定义了跨域网络在带宽、延迟和可预测性上的标准。
通过 MetroX-2,NVIDIA致力于解决一个核心问题:如何让分布在不同数据中心、不同园区甚至同一城市不同区域的GPU集群,在应用层面上像一个统一、连续且可调度的超大规模系统一样运行? 这正是跨平台扩展(Scale-across)架构从概念走向工程实现的关键起点。
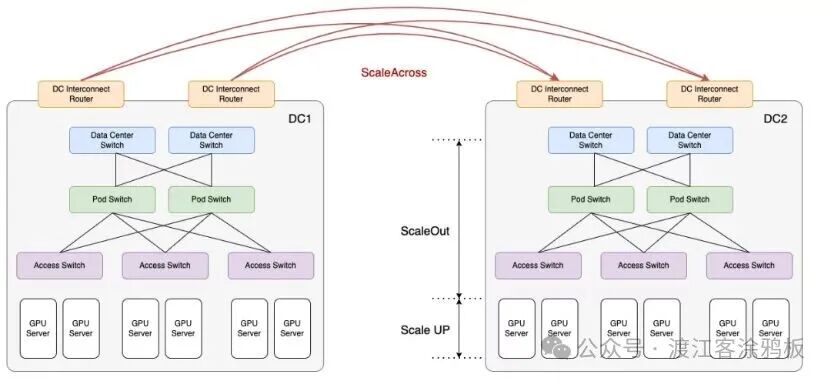
一、什么是 Scale-across?
简单来说,Scale-across 就是将多个数据中心连接起来,使它们能够像一个巨型集群一样共享工作负载。其核心原理是利用高带宽的水平扩展网络在数据中心之间搭建桥梁,这种带宽远超传统的数据中心互连(DCI)方式。
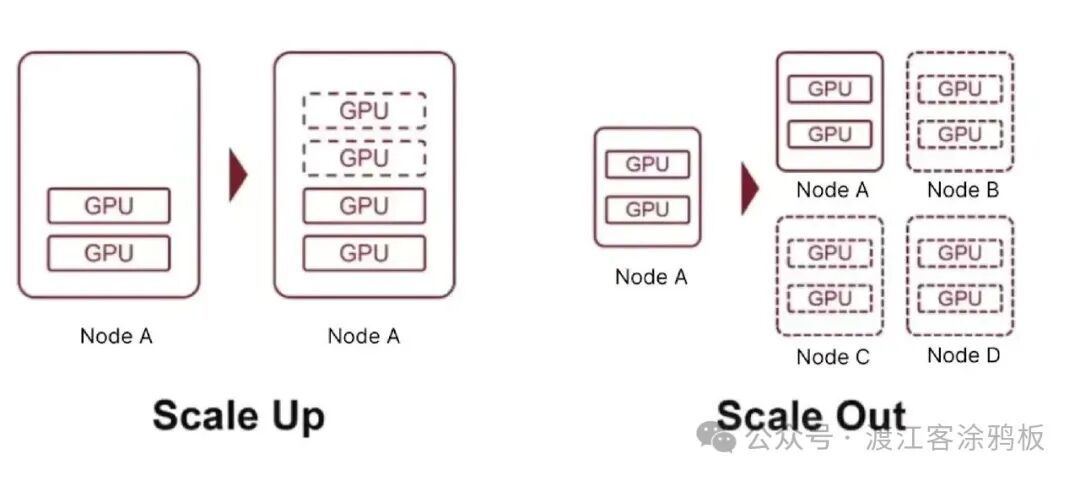
随着现有的纵向扩展(Scale-up)和横向扩展(Scale-out)路径逐渐逼近物理和工程极限,跨域扩展(Scale-across)成为不可避免的演进方向。尽管跨数据中心和跨区域的扩展会带来更高的延迟、更复杂的带宽管理以及拥塞和故障域放大等挑战,但单个系统的规模和单个数据中心的容量已不足以支持不断增长的人工智能计算需求。
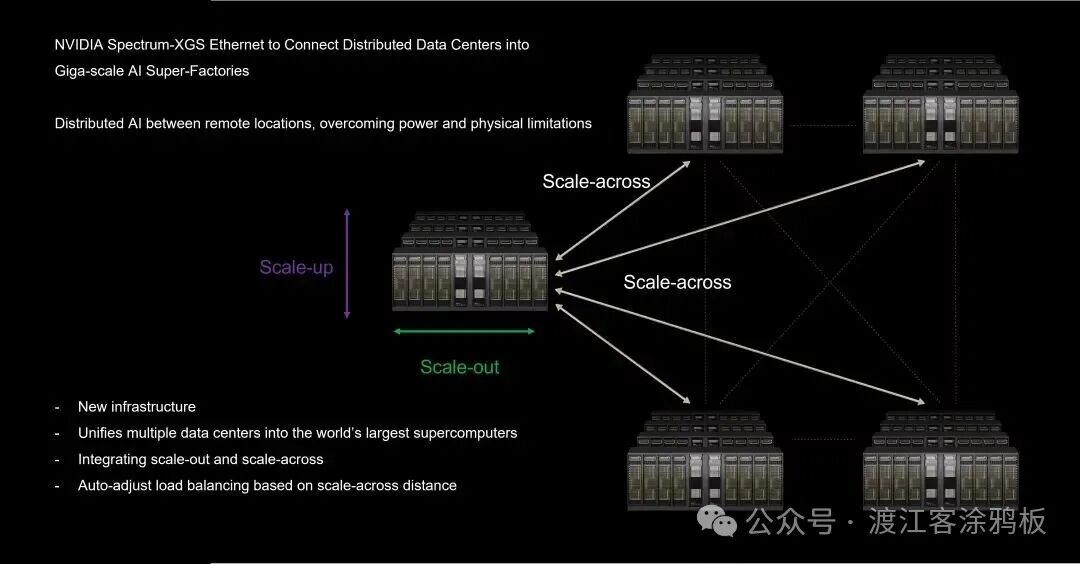
二、Scale-across 兴起的技术背景
推动 Scale-across 成为必然选择的,是多重因素共同作用的结果。
1. 功耗和散热瓶颈
对超大规模数据中心的分析表明,传统机架功耗约为15-30千瓦。而目前NVIDIA的机架级GPU基础设施功耗已达约140千瓦/机架,预计到今年年底将攀升至1000千瓦/机架。单机功耗持续增加,主流风冷散热已难以为继,液冷成为必然选择。单个数据中心根本无法应对如此巨量的功耗与散热需求。
2. 电力成本与供应
在单一地点为数百万个计算单元(XPU)供电极其困难。即便采用天然气发电等方案,电力传输和基础设施建设的复杂度依然很高。此外,全球各地的电价和能源结构差异显著。由于AI数据中心功率密度和总能耗远超传统数据中心,其选址与扩展必然走向分布式部署。
3. 可扩展性和物理限制
即便没有电力限制,构建一个无限扩展的单一数据中心也存在物理和工程上的天花板。分阶段在不同地区建设多个数据中心,并通过跨域网络逐步扩展AI算力,在技术和经济上都更为可行。
4. 推理与边缘计算需求
随着AI发展重心从训练转向推理,NVIDIA的Rubin平台显著提升了推理性能并降低了单位成本,这将带来推理需求的飞跃。为了满足用户对低延迟、高并发和大规模数据回传的需求,分布式数据中心的建设迫在眉睫。
5. 数据驻留与合规要求
由于区域政策限制,数据通常必须保留在本地。这种地理分散的数据对系统架构造成了“结构性约束”,迫使计算能力必须部署在数据所在的合规边界内。
相比之下,Scale-across 突破了单点资源的限制,为长期计算扩展开辟了新途径。它使得超大规模人工智能系统能够在更广泛的物理领域内实现协同运行。Scale-across 并非简单地替代Scale-up或Scale-out,而是扩展的下一个演进阶段——是功耗、能源、工程、商业和合规性等多重约束相互作用的自然产物。
三、NVIDIA MetroX-2 系统简介
正是在这样的背景下,NVIDIA推出了MetroX-2——一款专为“城域AI网络”设计的InfiniBand远程互连系统。在传统网络中,跨数据中心通信通常意味着更高的延迟、更复杂的路由路径和不可预测的抖动,这些都会对AI训练和推理造成致命影响。
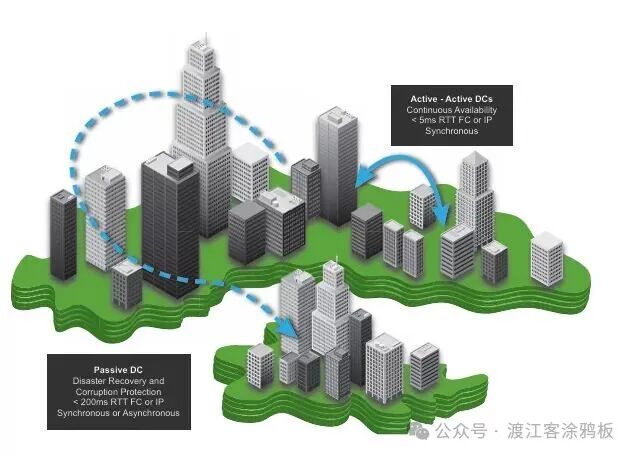
为了将地理距离的影响降至AI工作负载可接受的水平,仅仅增加光纤带宽是不够的,需要进行多层次的协同优化:
- 光层和硬件层:采用低损耗远距离收发器、针对远距离链路优化的波分复用/调制技术以及链路修复能力,确保链路本身具有可预测的物理特性。
- 交换/路由层和控制平面:实现距离感知调度和拥塞控制机制,例如基于端到端遥测的拥塞感知、延迟和丢包驱动的队列管理,以及自适应路由以绕过临时拥塞点。
- 协议/平台层:GPU、DPU和软件栈等组件必须保留RDMA和GPUDirect等直接路径,最大限度地减少中间设备上的内存复制或上下文切换。
实现跨平台扩展能力的关键在于:硬件确保带宽和基线延迟,网络算法保证流量优先级和公平性,软件堆栈则能在应用层透明地利用远程资源,而无需针对网络变化进行大量调整。
MetroX-2通过AI优化的以太网架构、高带宽低延迟数据路径,以及与NVIDIA生态系统深度集成的拥塞控制/流量调度机制,旨在消除GPU间通信的距离感。从应用视角看,训练框架能够持续感知到一个高度一致、低延迟且可预测的通信平面,而非由多个地理位置拼接而成的复杂网络。
四、MetroX-2 对AI训练和推理的实际影响
对训练工作负载的影响
在大型模型训练中,尤其是在采用模型并行(TP)、流水线并行(PP)和专家混合模型(MoE)等复杂通信模式时,跨节点通信通常会占用大量训练时间。MetroX-2系统低抖动和高可预测性的特性,确保这些通信模式即使在跨数据中心场景下也能保持稳定的步调,防止偶发性拥塞拖慢整体训练速度。
对推理工作负载的影响
在推理场景中,MetroX-2的价值更加凸显。推理工作负载本身具有突发性、高并发性和对延迟高度敏感的特点。通过在都市区部署多个推理节点,并使用MetroX-2将它们组织成一个统一的资源池,可以实现更精细的流量调度和基于邻近性的响应:
- 用户请求会优先调度到物理距离最近、负载最低的节点。
- 热点模型可以跨多个数据中心快速同步。
- 在流量高峰期,任务可被调度到其他空闲的数据中心,以分散压力,避免单点过载。
这项功能使AI服务提供商无需为每个城市或地区构建完整且冗余的推理集群。相反,他们可以通过跨区域资源池的方式,显著提高整体资源利用率,同时确保流畅的用户体验。
五、结束语
如果说过去AI网络架构的核心演进是从三层架构向Clos架构的过渡,那么下一阶段的演进很可能是从“数据中心网络”转向“人工智能城域网”。在MetroX-2等城域级AI网络中,更长的链路距离、更复杂的环境以及持续的高强度工作负载,对光模块和光缆在传输距离、损耗控制、稳定性和可靠性方面提出了远高于传统数据中心的要求。
这不仅仅是连接方式的改变,更是对超大规模人工智能计算基础设施的一次根本性重构。对于广大开发者和技术社区而言,理解并跟上这一趋势,是把握下一代智能 & 数据 & 云基础设施发展的关键。想了解更多前沿技术解析和实践分享,欢迎访问云栈社区,与众多开发者一同交流成长。
参考资料:Sourced from NADDOD.com
免责声明:本文尊重知识产权与数据隐私,部分内容与图片来源于公开网络,版权归原发布方所有。如涉及侵权,请联系我们删除。
 发表于 2026-2-7 14:20:52
|
查看: 185|
回复: 0
发表于 2026-2-7 14:20:52
|
查看: 185|
回复: 0
