在 12 月 18 日的火山引擎 Force 大会上,字节跳动正式发布 veRoCE——字节跳动自研的高性能 RDMA 传输协议。
随着大语言模型(LLM, Large Language Model)规模指数级增长,构建万卡乃至更大规模的 GPU 集群,已成为支撑大模型训练的基础设施刚需。这类超大规模集群的节点间通信高度依赖 RDMA 网络,但传统 RoCEv2 在组网规模、带宽与时延等方面逐渐难以满足需求。
同时,云网络持续演进,通用计算、存储等业务也对 RDMA 组网提出了更高要求。主流 RoCEv2 高速网络存在两大关键局限:
- 依赖 PFC 无损网络:在大规模组网中,PFC 容易引发网络稳定性问题,限制集群规模进一步扩展。
- 不支持多路径传输:容易产生 ECMP 冲突,导致带宽利用率下降与浪费。
在此背景下,字节跳动推出自研高性能传输协议 veRoCE,从源头解决 RoCEv2 的遗留问题,为大规模 GPU 集群通信提供更优的 RDMA 方案。
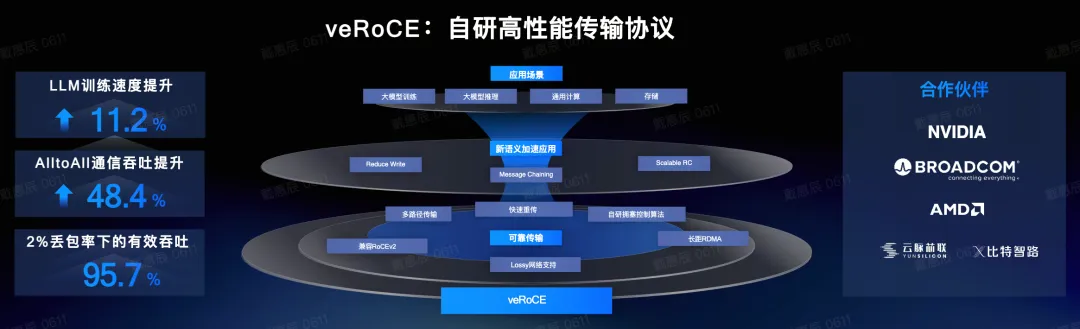
veRoCE 的关键创新点
veRoCE 主要围绕 RoCEv2 的核心短板做了针对性改造,重点能力包括多路径、可靠传输与拥塞控制等。
1)多路径与乱序优化
veRoCE 原生支持多路径传输,提供两种模式:
多路径带来的直接挑战是报文乱序。为降低乱序对性能与缓存的影响,veRoCE 引入 DDP(Direct Data Placement):数据无需等待保序即可直接交付应用,从而显著减少网卡侧缓存开销。
此外,在 veRoCE 中,乱序接收与 DDP 对所有语义提供原生支持,包括:
- RDMA Write
- RDMA Read
- Send/Recv
- Atomics 等
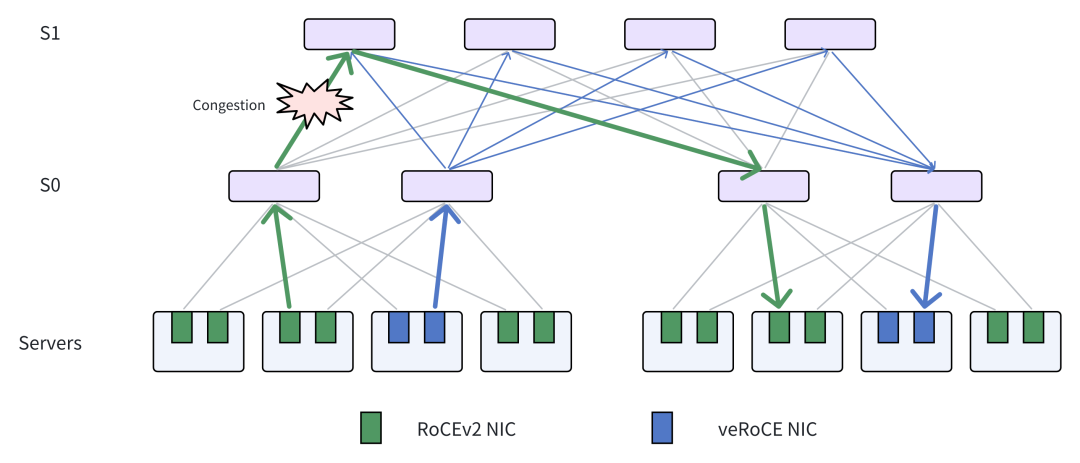
在涉及 RDMA/以太网传输路径与拥塞问题时,建议结合云栈社区的 网络/系统 相关资料做系统性补充阅读。
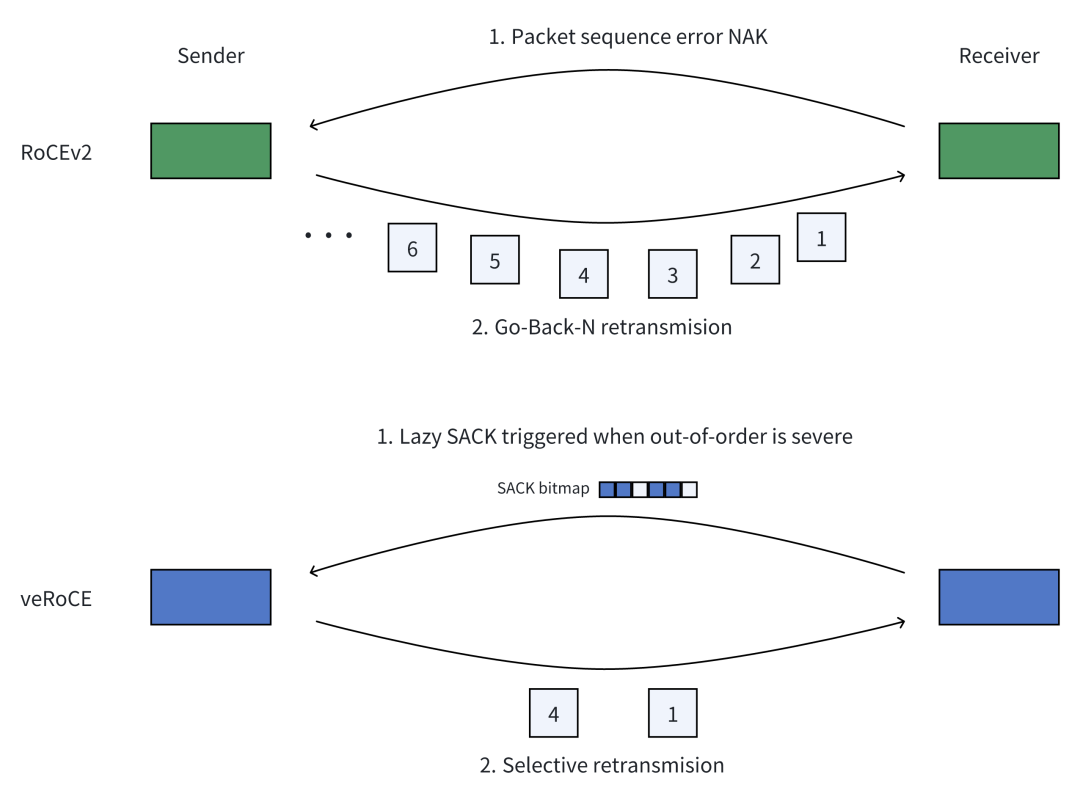
2)高效重传机制:选择性重传 + lazy SACK
为提升丢包场景下的有效吞吐与恢复速度,veRoCE 采用基于 SACK(选择性确认) 的选择性重传策略:
- 通过接收端位图精确定位丢包位置
- 支持单个报文的多次选择性重传
同时,引入 lazy SACK(延迟选择性确认) 机制:根据报文乱序程度,智能区分“乱序报文”与“丢包报文”,确保 SACK 在多路径环境下仍能高效运行,避免误判带来的额外开销。
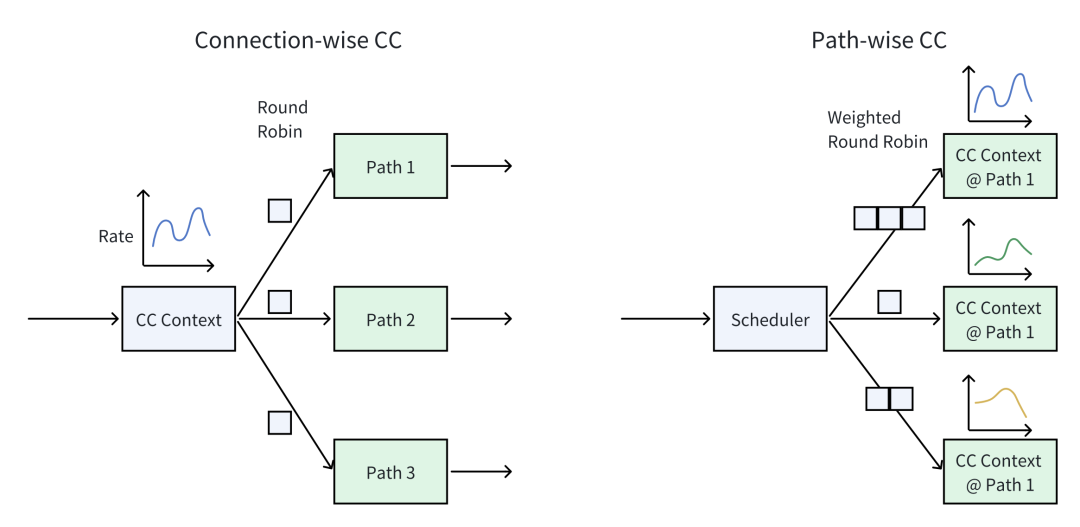
3)多路径拥塞控制:路径/连接粒度 + 快速慢路径检测
veRoCE 支持两种拥塞控制模式:
其关键设计之一是:将拥塞信号与可靠传输完全解耦,避免数据传输行为干扰拥塞感知的准确性,从而让拥塞反馈更“干净”、更可用。
针对多路径下常见的“路径拥塞不均衡”问题,veRoCE 提出了基于报文序列号的快速慢路径检测算法,以尽可能小的开销快速定位并剔除慢路径,提高整体吞吐与稳定性。
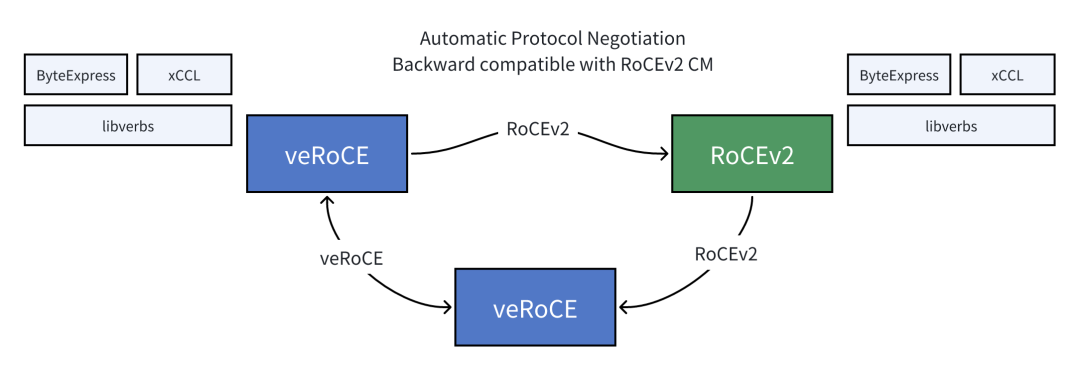
兼容性与迁移:保持 RoCEv2 语义,降低切换成本
veRoCE 在兼容性与落地门槛方面做了重点考虑:
- 支持通用 verbs 接口
- 消息语义与保序模型与 RoCEv2 保持一致,业务可实现无缝切换
- 连接管理支持协议协商:与 RoCEv2 网卡互通时可自动回退到 RoCEv2 模式
- 在与核心新功能无关的部分与 RoCEv2 完全一致,从而显著降低迁移与部署难度
典型测试收益:LLM 训练与集合通信提升明显
在典型测试场景中,veRoCE 对大模型训练带来显著收益。例如:
- 在 128 GPU 集群中,LLM 训练速度相较 RoCEv2 提升约 11.2%
- AlltoAll 通信吞吐提升约 48.4%
- 在 2% 丢包率下,veRoCE 的有效吞吐仍可达到网卡带宽的约 95.7%;而 RoCEv2 在该场景下可能因丢包过多出现通信中断
面向大模型训练与集群通信优化,也可以对照云栈社区的 人工智能 相关内容,从训练负载与通信模式角度进一步理解收益来源。
生态合作与硬件支持进展
字节跳动正在与 NVIDIA、AMD、Broadcom、云脉芯联、比特智路等厂商就 veRoCE 展开合作。当前 veRoCE 已在部分网卡上完成验证与小规模试用,更多 400G、800G 以及 1.6T 网卡也在逐步支持 veRoCE,推动以太网高性能传输生态的完善与扩展。 |  发表于 2025-12-24 17:46:23
|
查看: 280|
回复: 0
发表于 2025-12-24 17:46:23
|
查看: 280|
回复: 0
