过去一年 DPU 再次火起来,各类观点“盲人摸象”式地涌现。回头看网络设备与网络处理器的演进史,会发现很多争论其实早就发生过。理解历史,是为了减少重复踩坑。
注:建议从三个维度一起看——软件 / 硬件 / 网络报文编码。
我把互联网网络设备(含路由器、交换机、线卡、网络处理器、智能网卡等)的发展,按思路分为 5 个阶段,后文再逐段展开。
五个阶段总览
1986~1995:软件实现为主
报文编码:基于目的 IP 地址的最长匹配(LPM)查询软件结构:靠软件算法优化,Tree 查找 + Cache 优化硬件结构:大量基于 MIPS 指令集 CPU 的软件转发;后期出现总线型分布式转发(如 Cisco 7500 的分布式 CEF)
1995~2010:由软向硬的过渡
报文编码:MPLS 通过标签降低核心路由表复杂度软件结构:整体相对稳定硬件结构:专用处理器与 Offload 十年:加密芯片、TCAM 查表、微码网络处理器;Fabric 逐步走向 CLOS 多机集群
2010~2015:由硬到软(软件定义时代)
报文编码:VXLAN/Overlay 兴起软件结构:软件转发回归,DPDK/VPP 等出现硬件结构:多核通用 CPU 性能提升;SR-IOV 普及;交换芯片更强并支持虚拟化
2015~2019:由软到硬(可编程智能网卡时代)
报文编码:Segment Routing,“数据包即指令”软件结构:容器推动 CNI/Host Overlay;更多卸载到协处理器/网卡;P4 等通用网络编程语言兴起硬件结构:可编程交换芯片与 SmartNIC 方案爆发;低时延通信需求上升,AI/分布式存储带来更快 I/O 响应诉求
2020~未来:把“智能选择权”下沉到更多终端
报文编码:以应用为中心,并兼顾软硬件一体化软件结构:软总线、多云 RPC 等新形态出现硬件结构:智能下沉到边缘;网络形态更简化;以“直接内存交付、隐藏通信”为目标
1986~1995:其实网络一开始就是“软件定义”的
最早的路由器更像“服务器”。1986 年思科发布 AGS(Advanced Gateway Server),Cisco IOS 本质就是运行在设备上的软件操作系统。

当时优化主要围绕 软件算法 展开:
- 进程交换(Process Switching):每个包进来都跑一次转发进程、查路由表再转发。直观,但代价是每包都做“完整查表”,规模一大性能就崩。
- 快速交换(Fast Switching):引入
Cache 做路由查询缓存,避免每包全量查表。
- 树结构查找(Tree Lookup):路由表进一步增大后,靠数据结构继续提速。典型如 Linux 内核长期使用 Radix Tree;Cisco 从 Radix Tree 逐步发展到 CEF(Cisco Express Forwarding)。
那个年代的特点是:流量规模不算夸张、协议相对复杂、互通互联需求强,整体处理能力多在 100Mbps 级别以内,软件转发反而是更合适的工程解。
硬件侧,多数产品基于 MIPS 处理器,本质还是执行标准 MIPS 指令集。路由器升级往往等价于 CPU 升级:从 Motorola 68000 到 R4600/R4700/R5000;总线从早期私有 Cbus 到后期标准 PCI 的 PA 卡与 CyBus 等,整体结构并未本质变化。
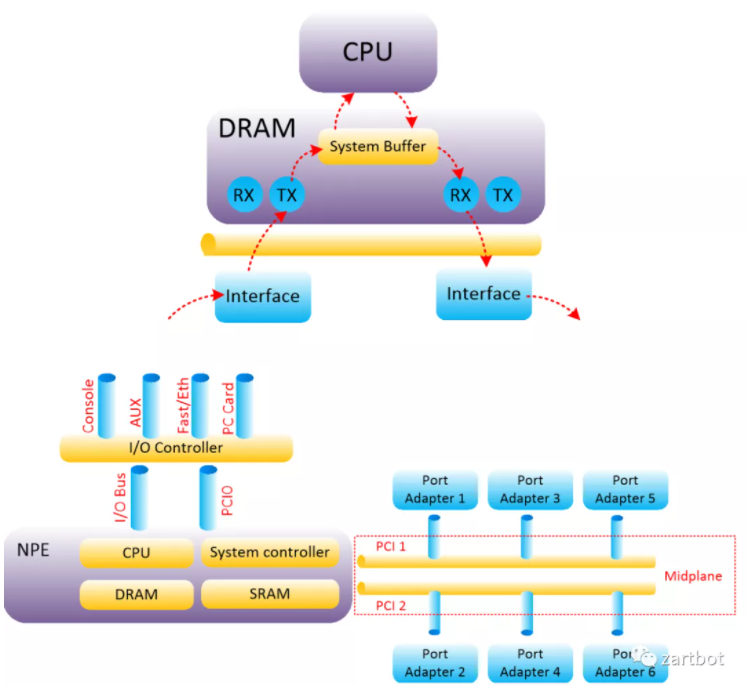
集中式架构遇到瓶颈后,一个自然想法是:不够就堆 CPU。Cisco 7500 走的就是这条路——在线卡上放 CPU,并将转发表下发到线卡,形成 Distributed-CEF。
报文编码:基于目的 IP 地址的最长匹配查询软件结构:Tree 查找 + Cache 优化硬件结构:MIPS CPU 软件转发 → 总线型分布式转发(Cisco 7500 等)
1995~2010:从软件到硬件转发的变革
这一阶段的核心,是软件算法逐步碰到瓶颈之后,工程界开始系统性地把“转发”做成硬件化能力。这个变革主要落在两处:
1) Fabric(交换结构)怎么做
2) Linecard(线卡/接口板)怎么做
1)硬件转发之 Fabric:从总线瓶颈到 Crossbar,再到 CLOS/多级交换
大量通信发生在同一网段主机之间,加上广域网带宽相对更小,“交换机”崛起。以太网交换公司大量采用 ASIC 做特定转发加速:精确匹配目的 MAC,用硬件查表比 CPU 指令译码更快。
典型交换策略包括:
- Cut-Through:低延迟但传统以太网易产生碰撞/残帧
- Fragment-Free:检查前 64B 以避免碰撞碎片
- Store-and-Forward:更稳妥但增加延迟
本质上,这些都在构造一个“交叉矩阵”控制开关互联,这也是 switch 一词的直观来源。
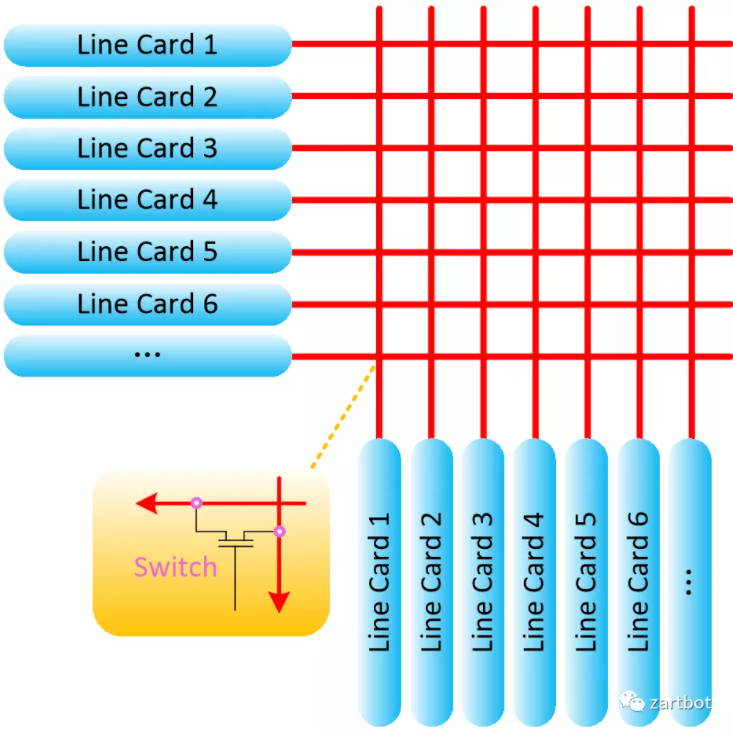
与此同时,总线型分布式路由器平台遇到背板瓶颈:ISA→EISA→PCI 的演进增速有限,共享总线易冲突,高速总线设计难度上升。于是架构开始转向“用交换结构连接线卡”。
Crossbar 架构的路由器由 Nick McKeown 在论文中提出,并参与了 Cisco GSR 12000 等系统实践。随之而来的关键问题是:
- 多个 Crossbar 如何同步、如何调度?
- 如何避免阻塞?
Cell-Based Switch + VOQ + iSLIP 等机制在当时成为核心答案。

随后随着端口速率与端口数增加,Crossbar 扩展性问题凸显:芯片管脚、实现复杂度、集中仲裁器调度复杂度都成为上限。多级交换结构开始替代单级 Crossbar,多种拓扑并存:Clos、Banyan、Butterfly、Benes 等。
例如 Cisco CRS-1 使用 BENES 架构:
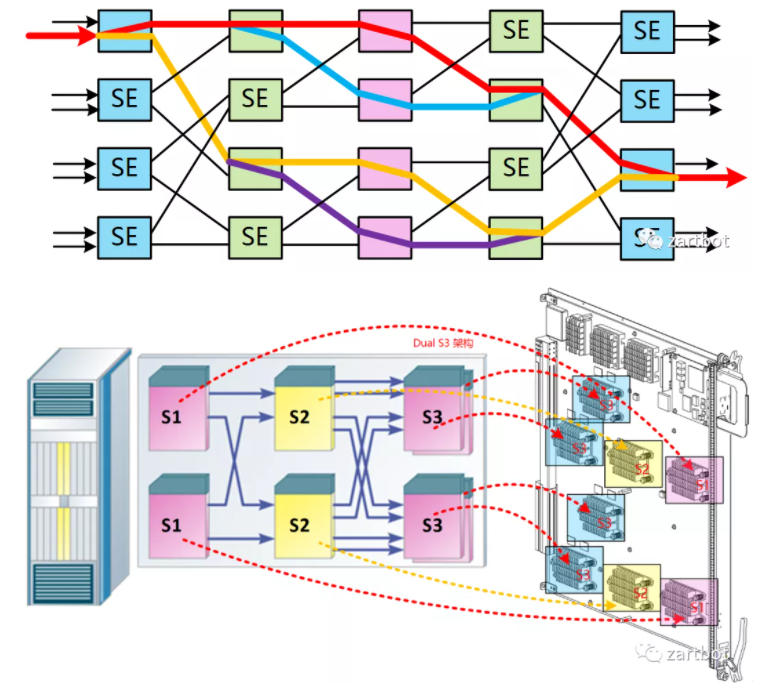
多芯片交换网既可作为并行 Fabric 连接线卡,也可做成路由器集群中的专用 Fabric 机框:
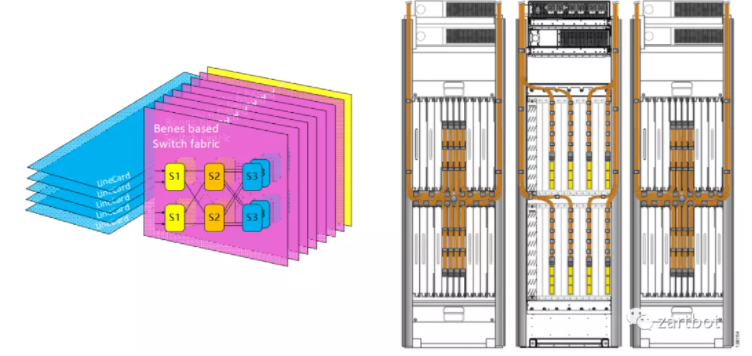
路由器进入“集群年代”。多年后,人们又会看到 1RU 的高集成系统去替代庞大集群——历史常常以不同形态重演。
2)硬件转发之 Linecard:ASIC、TCAM、流水线与网络处理器百花齐放
Fabric 的难点在“规模与调度”,线卡的难点在“功能与表项容量”。
线卡形态沿着一条清晰路径演进:
核心 CPU 转发 → 总线控制器调度 → 线卡 CPU 分布式处理(如 Cisco 7500 VIP)→ ASIC 加速 → 网络处理器(NP)+ 多种协处理器组合。
这一阶段的争论与实现非常多,很多讨论在今天的 DPU/SmartNIC 里又会原样出现:
不得不说的 ASIC:TCAM
传统表项查找大多基于 SRAM 的软件式查找,速度受限:线性查找要遍历,二叉树要走深度,性能与结构强相关。TCAM 的价值在于:并行比较,同一时刻查询整个表项空间,速度不随表项规模线性变差。
TCAM(Ternary Content Addressable Memory)之所以叫 Ternary,关键在每个 bit 支持三态:0/1/Don't care,天然适合做匹配,尤其适合路由器的 Longest Prefix Match。
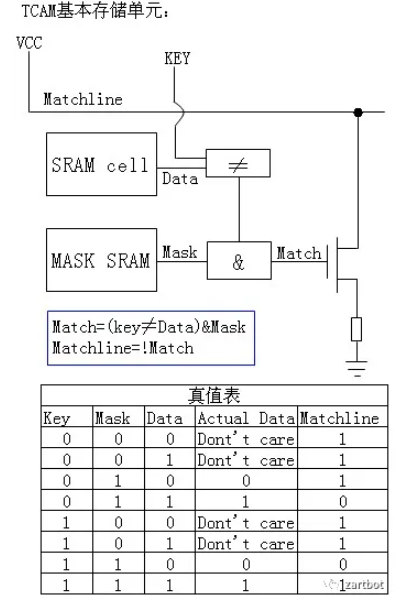
这种结构也成为许多可编程数据面的重要基础组件之一。
固定流水线的 ASIP:批量 Offload 的高峰
线卡加速的第一直觉是:把固定功能 Offload 到硬件流水线批量执行。Cisco PXF(Parralled eXpress Forwarding)诞生于此背景,让 IOS 第一次在转发上获得类似“多核并发”的效果。代价是仍需要大量微码/固化逻辑配合。
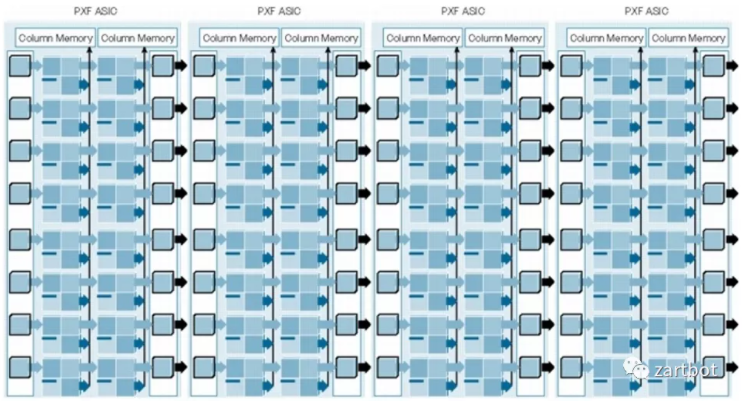
从形态上看,它就是“流水线 + 内存”的 ASIC:第一级做 A、第二级做 B,一次并发处理多个报文——与今天常见的 Match-Action pipeline 思想并不遥远。
RTC 处理器的代表作:QFP(Run-To-Complete)
固定流水线会遇到典型资源失衡:
- Feature 使用不均衡:有的资源闲置、有的资源不够
- MPLS VPN 等推动路由表容量持续增长
- 多业务硬件平台林立,研发与维护成本陡增
- 微码开发难以跟上市场变化
一些关键工作(例如 Tree Bitmap)把“查表能力”部分拉回到更灵活的实现路径,同时提出基于通用处理器裁剪的 RTC 包处理器内核,支持 C 语言编程、栈执行能力。QFP 由此成为代表性设计:
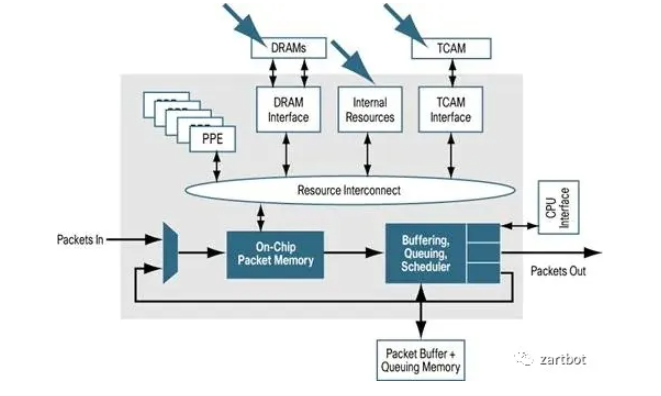
QFP 的典型思路是:一个处理器把一个包所需功能尽量一次跑完(RTC),编程以 C 代码为主,内存操作更灵活。其结构上将功能抽象拆分:
- On-Chip Memory:用于调度与等待
- PPE:多核、专用精简指令集处理器内核(例如 Tensilica 精简指令集)
- 片外协处理:TCAM/加密协处理器等
- QoS:专用 TM 芯片
- 路由表查询:Tree Bitmap 等算法,使用 DRAM 在容量与速度上做取舍
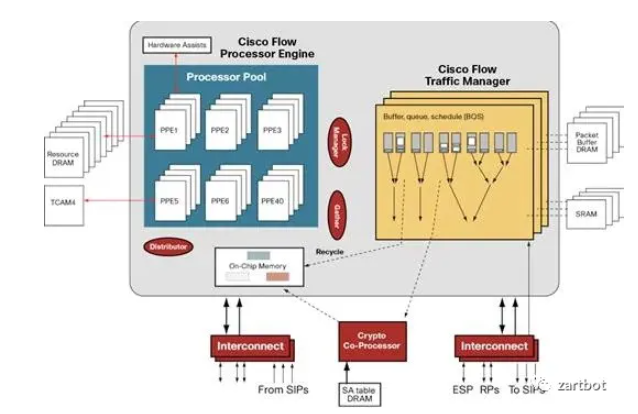
这种“I/O 与 CPU 核之间用一块共享内存组织数据流”的思想,影响了后来许多面向高 I/O 的系统设计。相关的思路也能在这篇论文里看到:https://arxiv.org/abs/2110.14902
当软件编程弹性足够时,设备就能不断叠加功能:IPSec 加解密、路由查询、隧道解封装、内层 TLS 卸载、压缩、防火墙、DPI、流量调度、计费……在今天的 DPU 上,这些融合诉求并没有消失,只是换了载体。
这里也顺带提示:讨论 DPU/SmartNIC 时,别只盯“算力”,还要同时盯数据面路径与安全卸载(如 IPSec/TLS/ACL/DPI),很多坑本质属于网络安全工程化问题,而不是单一芯片性能问题。
另一类网络处理器:产业链的轮回
那几年有的用 C 写 NP,有的用微码写 NP。十几年后,这些人和团队又在 DPU 时代以不同公司形态重新出现:当年的 IXP、Cavium、RMI、Tilera/EzChip/Mellanox 等路径,也在提示一个事实——技术路线会循环,但约束条件会变。
这一阶段的结论可以浓缩为一句:当软件出现瓶颈,解决方式往往来自两手——
- 硬件 Offload(ASIC/协处理器/NP)
- 报文编码变化(例如 MPLS 降低查表复杂度)
也因此,今天看到“微码变 P4、P4 编译出 RTL 放 FPGA”等现象,并不意外。
报文编码:MPLS 简化核心路由表条目数软件结构:整体相对稳定硬件结构:Offload 芯片繁荣(加密、TCAM、NP),Fabric 走向 CLOS 集群
反思:纯 P4 流水线或纯 FPGA 式 DPU,可能会遇到当年固定流水线类似的困境。另一个长期矛盾是 Pipeline 与 RTC 的切分粒度:当一次 offload 的同步/调用成本超过软件本地执行成本(例如 200 cycles),软件团队往往会“自己干”。这会逼着硬件只接更粗粒度的功能(例如 2000 cycles),而这又带来可编程性与开发成本的新约束。
2010~2015:由硬到软——软件定义时代的回归
虚拟化兴起后,虚拟机之间的东西向流量让“主机内网络”成为网络设备再次软件化的起点。最初从虚拟交换开始:OpenFlow、Open vSwitch(OVS)出现,公有云/私有云推动网络设备进一步虚拟化,虚拟路由器、防火墙等逐渐常态化,伴随 VDC/VPC 等能力,设备虚拟化形态越来越多:
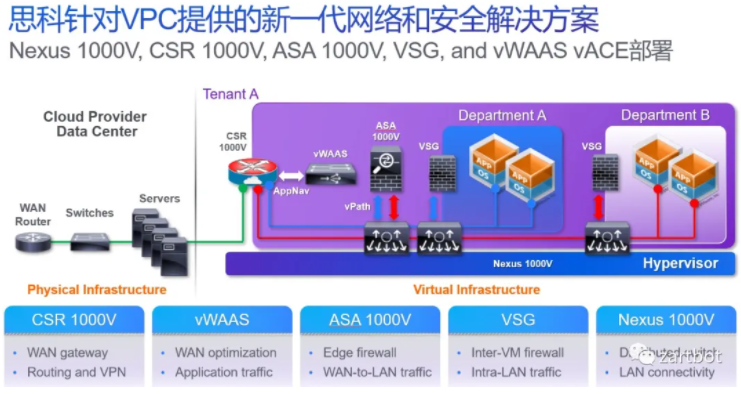
多年后你会发现,这类“功能总览图”几乎就是所有 DPU 厂商要集成能力的清单:OVS Offload、防火墙、压缩、VPN 加密等等。
DPDK:软件转发再次突破的关键拼图
在由硬到软的过程中,传统 Linux 转发路径遇到明显瓶颈:
- 数据包到达网卡设备
- 网卡依据配置进行 DMA
- 网卡发送中断唤醒处理器
- 驱动填充读写缓冲区数据结构
- 数据报文进入内核协议栈进行处理
- 用户态应用需要从内核搬移到用户态
- 或在内核态继续处理
核心代价来自:中断开销 + 多次拷贝 + 内核路径复杂度。DPDK 的思路是把包快速处理机制做在 x86 多核上:报文尽量直接进入用户态;采用轮询(polling)替代中断;网卡将包放入内存,由用户态应用通过 DPDK 接口直接处理,节省大量 CPU 中断时间与内存拷贝。

而在十年后的 DPU 语境下,很多能力又逐步从 CPU 往外搬,但“用户态交付/近内存交付”的方向并没有改变。理解这一点,对判断 DPU 终局形态很重要。
同一时期,报文编码的演进主要为了解决虚拟化:VXLAN、LISP 等 Overlay 兴起;大量设备被要求在 x86 虚拟化平台运行,虚拟路由/交换/防火墙出现。控制面上,BGP-EVPN、YANG/NETCONF 与控制器推动 SDN 落地。硬件侧则更多是 SerDes 增强、端口速率提升与交换芯片堆料,行业进入一段“简单粗暴但很有效”的增长期。
报文编码:VXLAN/Overlay 兴起软件结构:软件转发回归,DPDK/VPP 等出现硬件结构:多核通用处理器增强,SR-IOV 出现,交换芯片更强并支持虚拟化
(相关的基础知识体系,可结合 TCP/IP、Linux 网络与并发 一起补齐,会更容易看清“为什么软件路径会贵”。)
2015~2019:又“硬”了——智能网卡与可编程网络
当大家把东西“全软件化”后,现实往往是:CPU 资源大量被网络消耗(在一些场景甚至超过 50%)。对公有云来说,CPU 是要拿来卖钱的,于是 Offload 运动再次轰轰烈烈开始,网络再次走向硬件化与半硬件化。
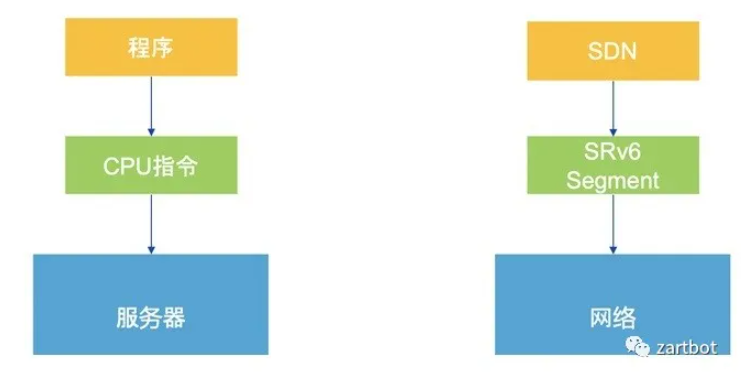
Segment Routing 与 P4:把“指令”塞进包里
当软硬都不够顺手时,人们再次把目光投向“指令集/编码方式”。
一方面,SR 对网络设备进行编码:有 SID,再编码 Function 与 Args,使设备在做目的查找时可以触发更灵活的函数回调栈,实现更丰富功能。
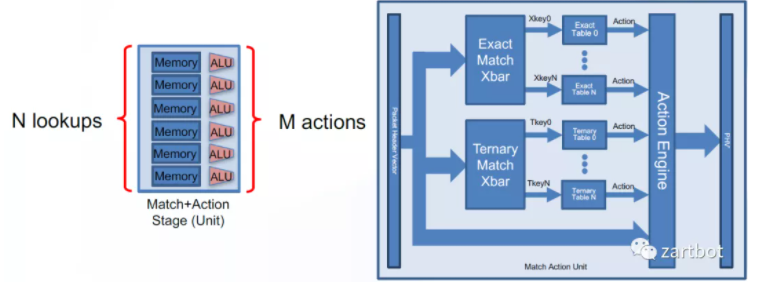
另一方面,网络处理可以抽象为连续的 Match-Action 操作,于是 pipeline 形态更明确,P4 顺势成为通用网络编程语言之一。围绕可编程交换芯片、P4 工具链、以及 FPGA 的 P4→IPCore 转换等,产业链在这一时期快速成形。
智能网卡:以 AWS Nitro 与 Azure FPGA 为代表
AWS 早期智能网卡以 SR-IOV VF 能力为起点,后续自研/并购方案将主机内虚拟交换负载逐步搬到网卡侧:路由、conntrack 匹配、ACL、VTEP 查表、MAC 代答、tunnel 建立等,从而降低时延、提升吞吐;同时在硬件层面实现虚拟机粒度的带宽与五元组 QoS,保证网络性能稳定可预测。
Azure 这条线则以“可重构计算”与 FPGA 为一大特色,不只做智能网卡,也把数据中心服务加速、AI Offload 等一起纳入统一思路,相关论文体系相对完整。
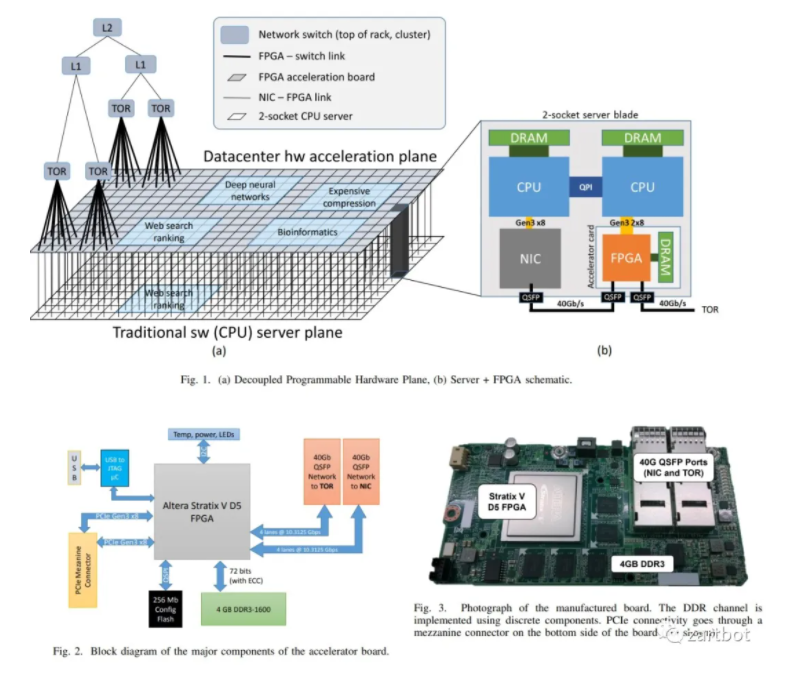
拆分 → 虚拟化;组合 → DPU
- 拆分:一个 CPU 多核拆开卖,对应 SR-IOV/PCIe 虚拟设备化。以 Nitro 为例,AWS 逐步缩短虚拟化 I/O 路径,将远端存储以 NVMe 方式呈现给虚机,网络与存储能力按需“外设化”。
- 组合:将多个 socket、内存、存储按需 attach 并通过 Fabric 组合,强调资源池化与可组合基础设施,这也是 DPU 概念常被讨论的方向。但随之而来的问题是:私有协议、跨厂互联、内存池化加载机制等,都会成为现实约束。
这一时期的背景,是更轻量级的容器、Service Mesh、Serverless 形态涌现;AI 与高速分布式存储繁荣;ROCE/RDMA 降低时延诉求强烈。可编程数据面与智能网卡,为报文编码扩展与体系结构重构提供了土壤。
报文编码:Segment Routing,数据包即指令软件结构:容器推动 CNI/Host Overlay,更多卸载到协处理器/网卡,P4 兴起硬件结构:可编程交换芯片、SmartNIC 盛行,低时延 I/O 需求上升
(与容器/虚拟化强相关的落地实践,可延伸阅读 Kubernetes、Docker 等云原生/IaaS 体系,更容易把“Host 网络开销为什么贵”这件事讲清楚。)
2020~未来:把“智能选择权”交给更多终端
有观点提到:新一代 IPU/DPU 的创新之一,是与上层应用/平台一起设计“下一代可靠传输协议”,以解决 有损网络 上的 长尾延迟,并配套更先进的加密与压缩加速器。
这提示了一个新的开端:
- 软件编码逐渐以应用为中心
- 通信协议本身开始兼顾软硬件一体化
- 资源更广泛地下沉到边缘,端侧需要更强的“智能选择权”
在功耗墙约束下,高密度场景很难无限堆算力或堆能力;可编程交换芯片也在触碰物理瓶颈。把可编程能力、协议能力、可靠性能力更合理地下放给终端与边缘,反而可能是下一阶段的主线。
与此同时,容器带来新的挑战:协议栈消耗大、智能网卡的 PCIe SR-IOV 配置速度与运维复杂度也不低;“直接的容器内存交付”成为更自然的趋势,Serverless 也会从概念走向更大规模商用。多云 RPC、多云分布式数据库与存储,是这些变革的底层需求。
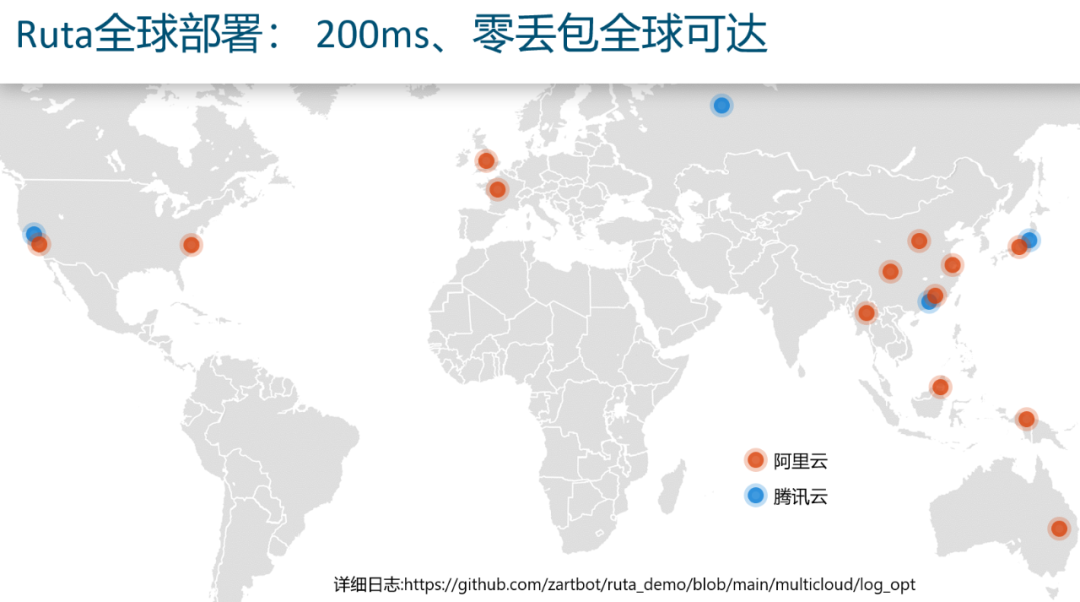
最后回到一句更“底层”的判断:
网络的本质是承载数据流;内存是数据流在某个时刻的快照;计算基于快照产生新的数据流。面向未来的可编程网络,可能会更接近“以内存直接交付为中心、尽量隐藏通信成本”的通信系统形态。
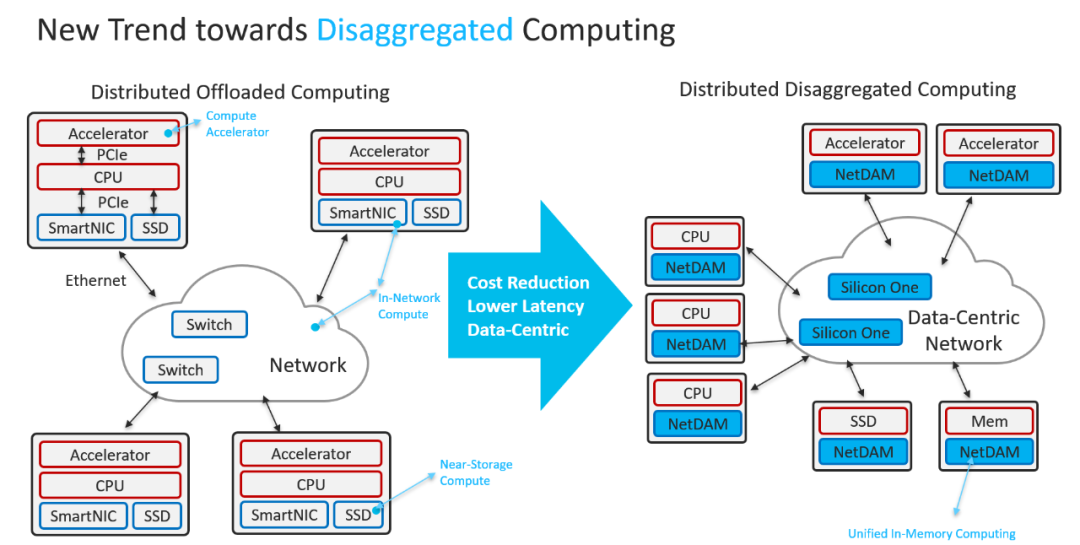
报文编码:以应用为中心,并兼顾软硬件一体化软件结构:软总线、多云 RPC 等硬件结构:智能下沉到边缘;网络简化;以直接内存交付为主,尽量隐藏通信成本
转自公众号作者:zartbot
 发表于 2025-12-24 17:44:50
|
查看: 278|
回复: 0
发表于 2025-12-24 17:44:50
|
查看: 278|
回复: 0
