当大模型训练进入千卡、万卡时代,超节点已成为智算中心的“核心引擎”。但长期以来,行业被封闭超节点架构“绑架”——厂商私有协议、定制化硬件、高昂运维成本,让不少企业望而却步。直到中国移动云提出“开放解构超节点(ODS)”理念,这场困局才迎来转机:用开放以太网打破协议垄断,靠硬件解耦降低厂商锁定,以弹性扩展覆盖从推理到训练的全场景。这种全新架构不仅让1024卡集群部署成本降低50%,更重新定义了AI基础设施的发展范式。
一、超节点的“两难困境”:封闭架构为何成了行业绊脚石?
超节点的核心诉求很明确:为大模型训练提供“超高带宽、超低延迟”的通信环境。但传统封闭架构在满足这些需求时,却埋下了三大隐患,让智算中心陷入“想用却用不起”的尴尬。
首先是协议垄断与生态割裂。以某头部厂商的超节点为例,采用私有互联协议,只能搭配自家GPU和交换机,一旦入局就意味着彻底被“绑定”——后续升级必须采购同品牌设备,运维也需依赖专属团队。更棘手的是,封闭协议与通用以太网不兼容,超节点集群(Scale-up)和普通服务器集群(Scale-out)需两套独立技术栈,运维复杂度翻倍,人力成本增加30%以上。
其次是硬件僵化与扩展难题。封闭超节点多采用“整机柜定制”设计,计算单元与交换单元深度集成,甚至连线缆都需专属规格。这种架构看似高效,却失去了弹性:当业务需要从64卡扩展到256卡时,不能简单增加标准服务器,只能整体更换机柜,成本骤增数千万元。更关键的是,封闭架构几乎只支持液冷,大量存量风冷机房无法适配,企业要么承担改造机房的高昂费用,要么放弃超节点方案。
最后是成本高企与性价比失衡。数据显示,传统封闭超节点单柜成本高达千万元级别,不仅硬件采购价昂贵,运维阶段的能耗和人力支出也居高不下——单机柜功耗普遍超过120KW,年电费比开放架构多支出数十万元。对于中小规模企业而言,这样的成本门槛足以让超节点成为“奢侈品”,难以享受大模型训练的技术红利。
二、开放解构超节点:中国移动云的“五维破局之道”
面对封闭架构的痛点,中国移动云的开放解构超节点(ODS)给出了一套系统性解决方案。其核心逻辑是:用“开放、解耦、弹性”替代“封闭、集成、僵化”,在保证性能的同时,大幅降低部署和运维成本。
1. 协议开放:以太网生态打破垄断
ODS架构最关键的突破,是基于开放以太网构建Scale-up网络。不同于厂商私有协议,以太网拥有最繁荣的产业生态——从芯片到交换机,从光模块到线缆,全球数百家厂商提供兼容产品,不仅采购成本更低,还能避免单一厂商锁定风险。
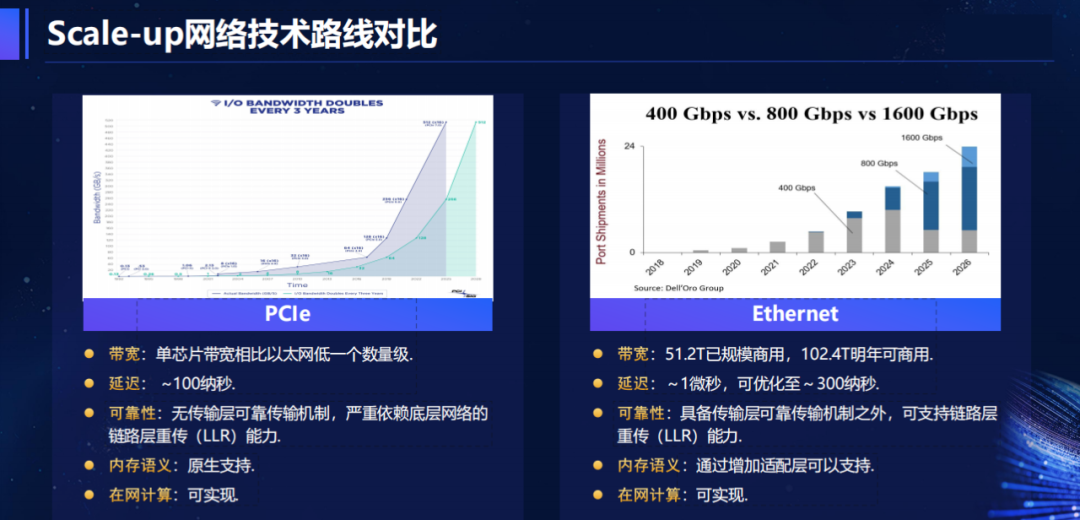
更重要的是,ODS通过ESUN(Ethernet for Scale-Up Networks)工作组标准,实现了Scale-up与Scale-out技术栈的统一。这意味着超节点集群和普通服务器集群可共用一套网络设备和运维体系,无需单独组建团队。例如,某互联网企业采用ODS后,运维人员减少20%,故障排查时间从小时级缩短至分钟级。

为了满足超节点的高性能需求,ODS还引入了FARE-in-SUN协议(全自适应路由以太网)。该协议基于IETF标准草案开发,能实时感知网络带宽变化,实现多路径负载均衡,单跳交换延迟优化至300纳秒以内,完全满足TP/EP通信的低延迟要求。
2. 硬件解耦:标准化设计降低门槛
在硬件层面,ODS彻底打破“整机柜定制”的模式,将计算节点与交换节点完全解耦。计算节点采用高度标准化的4U服务器,单节点支持4卡GPU(如英特尔GAUDI3),HBM容量超1TB,Scale-up带宽达3.2T+;交换节点则使用51.2T/102.4T标准以太网交换机,支持400G QSFP112或800G OSFP接口。
这种设计带来两大优势:一是采购灵活,企业可根据需求选择不同品牌的GPU和交换机,避免“捆绑消费”;二是维护便捷,当某台服务器或交换机故障时,只需更换单一设备,无需整机柜停机。数据显示,ODS架构的硬件故障率比封闭架构降低40%,维护成本减少25%。
3. 弹性扩展:从几十卡到千卡的平滑跃迁
ODS架构的弹性扩展能力,完美解决了封闭架构的“扩容难题”。其核心在于“模块化设计”:小规模场景(如64卡推理)可部署1个计算柜+1个交换柜;随着业务增长,只需增加计算柜和交换柜,无需重构网络。更关键的是,ODS支持“混合扩展”——风冷节点与液冷节点可共存,存量机房无需改造即可逐步升级。

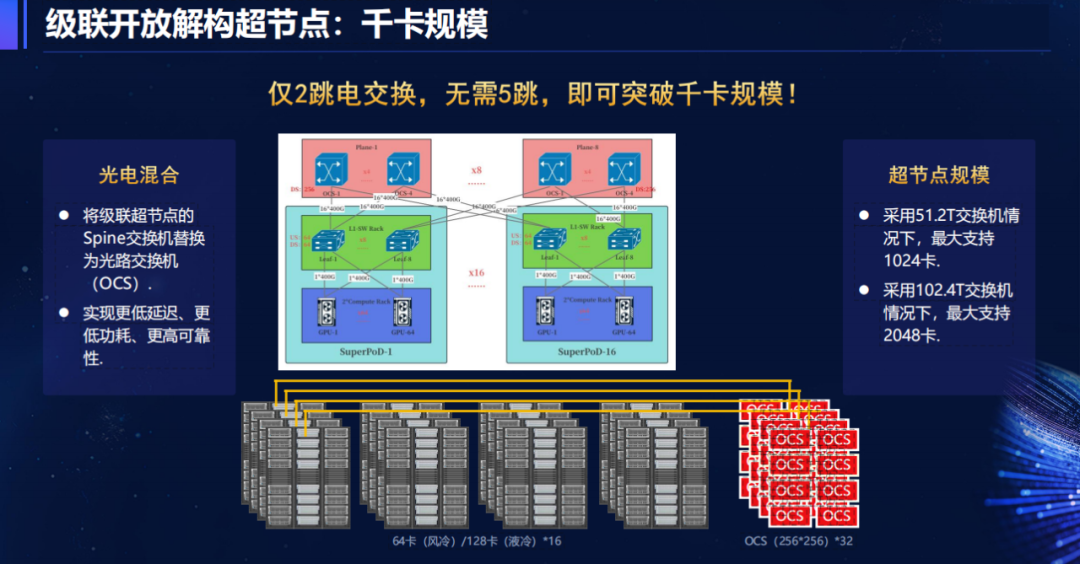
当规模突破千卡时,ODS通过“光电混合”方案进一步降低延迟:将级联超节点的Spine交换机替换为光路交换机(OCS),实现2跳电交换即可覆盖1024卡集群,而传统方案需要5跳。这种设计不仅减少了转发延迟,还降低了功耗,1024卡集群年电费节省超百万元。
4. 散热灵活:风冷液冷无缝适配
不同于封闭架构对液冷的“强制要求”,ODS同时支持风冷和液冷方案,适配不同机房环境。对于存量风冷机房,可部署4卡风冷型计算节点,单机柜功耗约40KW,无需改造即可直接上架;对于新建机房或高密场景,则可选择液冷节点,单机柜支持256卡GPU,满足超大规模训练需求。
这种灵活性大幅降低了超节点的部署门槛。例如,某制造业企业利用现有风冷机房部署ODS 64卡集群,省去了机房改造的千万元费用,仅用3个月就完成上线,比封闭架构缩短50%的部署周期。
5. 效率优化:铜缆优先 + 硬件卸载
在互联效率上,ODS遵循“铜缆优先”原则——计算节点与交换节点优先采用AEC铜缆互联,最大距离达7米,相比光模块成本降低60%,且延迟更低。仅在长距离级联时才使用光模块,最大限度减少OEO(光-电-光)转换带来的损耗。

同时,ODS通过GPU内置的RDMA NIC实现硬件卸载,将集合操作(如梯度聚合)从主机端转移到硬件端,避免主机介入,减少处理延迟。测试数据显示,采用硬件卸载后,大模型训练效率提升15%,GPU利用率从80%提高到92%。
三、落地实践:从64卡到1024卡,ODS如何重塑智算场景?
目前,中国移动云的开放解构超节点已进入商用倒计时,64卡风冷型(基于英特尔GAUDI3)正在进行开源大模型适配调优,预计2025年底正式商用。从测试数据和场景适配来看,ODS已展现出强大的实用性。
在中小规模推理场景(如64卡),ODS的优势在于“低成本快速部署”。某自动驾驶企业采用ODS 64卡集群后,单卡推理延迟控制在20毫秒以内,满足实时性需求,而硬件成本仅为封闭架构的60%,年运维成本节省30万元。
在大规模训练场景(如1024卡),ODS通过光电混合组网和FARE-in-SUN协议,实现了高效的多节点协同。测试显示,用1024卡训练千亿参数大模型时,ODS的通信效率比传统以太网架构提升40%,训练周期从15天缩短至10天,而整体成本降低50%。
更值得关注的是,ODS还针对MoE大模型推出了“混合计算架构”——将P节点(纯计算节点,如CPX芯片)与D节点(超节点,如NVL144)结合,Prefill阶段由P节点负责,Decode阶段由D节点处理,充分发挥不同硬件的优势,推理效率再提升25%。
四、行业趋势:开放解构为何成超节点新方向?
中国移动云的ODS架构并非孤例,而是行业发展的必然选择。从腾讯的ETH-X Ultra到Meta在OCP 2025提出的“硬件解耦”理念,再到某头部GPU厂商计划2027年商用的UAL256架构,“开放、解耦”已成为超节点的主流趋势。
这种趋势背后,是AI基础设施从“重硬件”向“重生态”的转变。随着大模型应用普及,企业对智算中心的需求不再是“单一高性能”,而是“性能、成本、灵活性”的平衡。开放解构架构正是抓住了这一核心需求——通过复用以太网生态、标准化硬件、弹性扩展能力,让超节点从“少数巨头的玩具”变成“多数企业的工具”。
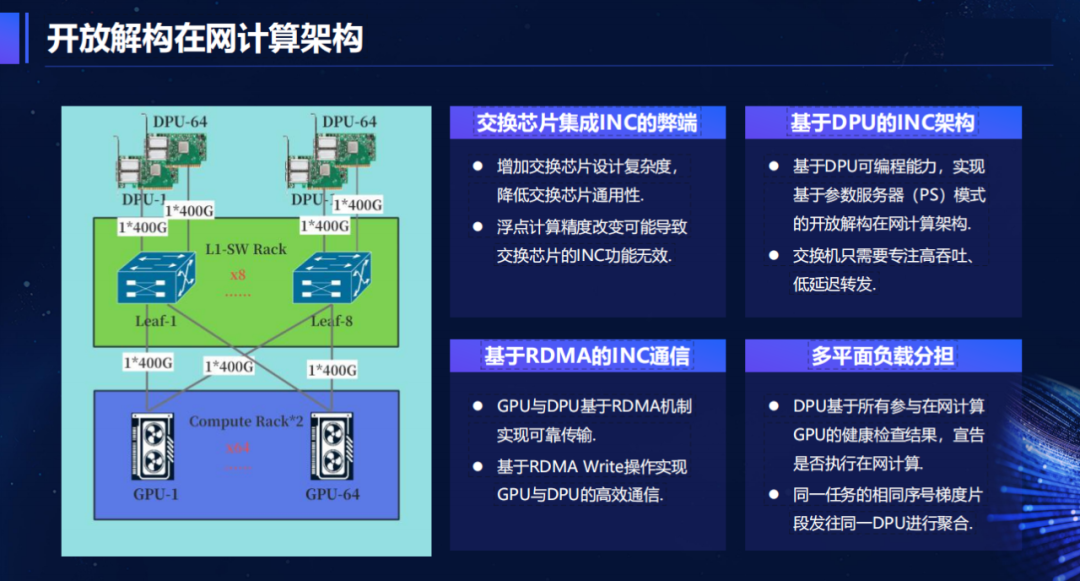
对于未来,中国移动云还计划进一步优化ODS架构:引入CPO/NPO光互联技术(未来3-5年),进一步降低延迟和功耗;深化在网计算能力,通过DPU实现梯度聚合卸载,提升训练效率;推动更多厂商加入ESUN工作组,完善开放生态。
结语:开放生态,才是智算的未来
当超节点从封闭“黑盒”走向开放架构,改变的不仅是硬件设计,更是整个AI基础设施的发展逻辑。中国移动云的开放解构超节点证明:高性能与低成本并非对立,通过协议开放、硬件解耦、弹性扩展,完全可以实现“鱼与熊掌兼得”。

对于企业而言,选择开放架构,不仅能降低当下的部署和运维成本,更能为未来预留足够的灵活性——当大模型参数继续增长、硬件技术迭代时,无需彻底推翻现有架构,只需模块化升级即可。这种“可持续发展”的特性,正是智算中心应对AI快速演进的关键。
可以预见,随着更多厂商加入开放生态,超节点的部署成本将进一步降低,应用场景也将从互联网、科研扩展到制造、医疗、教育等更多行业。届时,AI算力将真正实现“普惠”,成为推动各行业数字化转型的核心动力。
 发表于 2025-12-7 01:41:12
|
查看: 222|
回复: 0
发表于 2025-12-7 01:41:12
|
查看: 222|
回复: 0
