一、引言
在探讨了字节的ByteRobust大规模LLM训练管理系统后,我们不妨将目光投向另一个极具挑战性的场景。Meta提出的FT-HSDP方案,其目标直指超过10万GPU的超大规模训练环境。这与万卡级别的挑战存在显著差异,无论是故障频率还是恢复复杂度都跃升到了新的量级。
本文对应的核心论文为:[2602.00277] Training LLMs with Fault Tolerant HSDP on 100,000 GPUs。
二、摘要
当前大规模LLM训练普遍采用同步模式,这要求所有参与计算的GPU时刻保持健康。然而,在作者亲身实践的100K GPU集群中,这种模式因频繁的故障和漫长的恢复时间而显得效率低下。数据显示,每18分钟就可能发生一次故障,而恢复过程需要10分钟,导致有效训练时间占比仅剩44%左右。
为了突破这一瓶颈,作者提出了FT-HSDP(Fault Tolerant Hybrid-Shared Data Parallelism)方案。其核心思想是将数据并行(DP)副本作为基本的容错单元。当故障发生时,系统仅需将包含故障GPU或服务器的单个DP副本离线重启,而其他健康的副本可以不受影响地继续训练。
FT-HSDP融合了多项创新技术(注:并非严格的数学等价):
- 设计了跨DP副本的容错AllReduce(FTAR)梯度交换协议。该协议通过CPU处理动态增减副本的复杂控制逻辑,同时利用GPU执行高效的数据传输,以追求最优性能。
- 提出了非阻塞追赶协议,使得正在恢复中的副本能以最小的延迟重新融入主训练流程。
与在O(100K) GPU规模上进行完全同步训练相比,FT-HSDP能将故障恢复导致的停滞时间从10分钟大幅压缩至3分钟,从而将有效训练时间从44%提升到80%。
三、背景
3.1 硬件稳定性
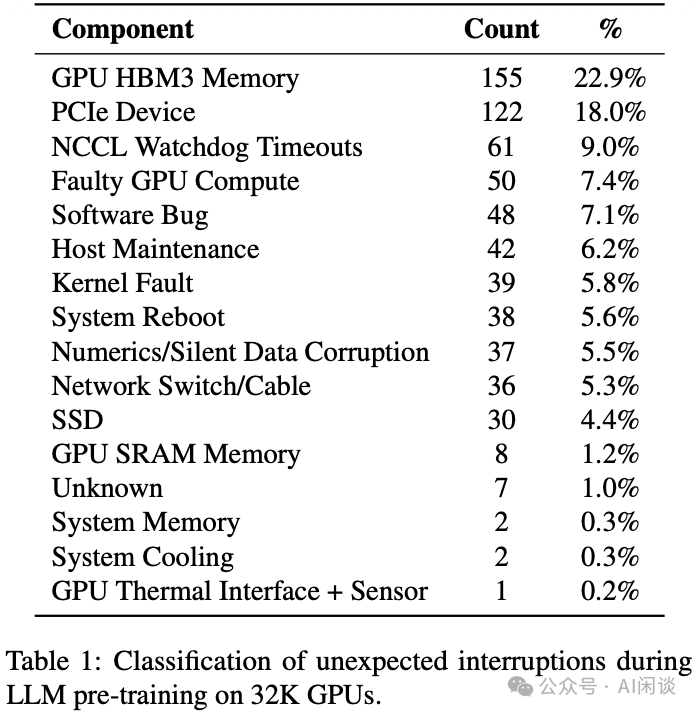
在一个32K GPU的LLM预训练任务中,通常能获得95%-97%的有效训练时间。平均来看,每天每1000台服务器会发生约2.3次中断。下表(Table 1)分类统计了所有的训练中断原因,其中高达78%与硬件相关:
- “Faulty GPU Compute” 曾是最主要的故障源。得益于先进的技术手段隔离了大量故障GPU,其占比已大幅下降至7.4%。
- “HBM3 Memory” 是目前最常见的问题,占比达到22.9%。
- “PCIe Device” 故障也相当频繁,这可能与从A100的PCIe Gen4升级到H100的PCIe Gen5后稳定性变化有关。
3.2 100K GPU的挑战
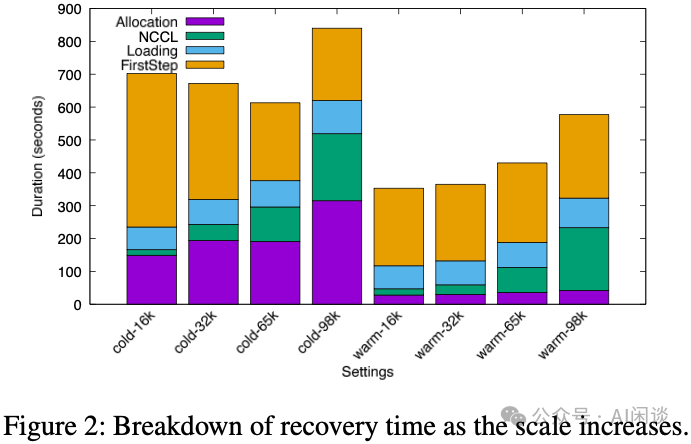
下图(Figure 2)揭示了当GPU规模从16K激增至98K时所面临的严峻挑战(其中“cold-N”表示终止整个任务,“warm-N”表示仅终止与故障相关的设备):
- Allocation(资源分配):GPU分配耗时惊人。采用warm-N方案仅替换异常设备需要20-40秒;而全部重新分配的时间则高达3-5分钟。
- NCCL初始化:NCCL的初始化时间随GPU数量增加而大幅攀升(字节在论文[2402.15627] MegaScale中也提及了类似问题)。16K GPU的初始化时间约为17秒,而98K GPU则暴增至200秒。
- FirstStep(首个训练步):训练的第一个Step由于需要执行额外的初始化工作,如初始化DataLoader、分配内存、JIT编译等,耗时远超普通Step。普通Step可能只需20秒,而FirstStep却需要2-4分钟。
- Loading(加载):此外,还包括检查点加载、健康检查等一系列开销。
3.3 集群与网络架构
超过10万GPU的训练集群必然会分布在多个数据中心建筑(DC Building)中。为此,Meta设计了一种多建筑网络架构,将多个相邻的DC Building连接到一个统一的RoCE Fabric网络(该架构在论文[2510.20171] Collective Communication for 100k+ GPUs中亦有介绍)。
- 如图(a)所示,每个建筑内部采用经典的三层Clos架构。
- RTSW(机架训练交换机)连接一个机架内的GPU。
- CTSW(集群训练交换机)实现一个AI Zone内所有RTSW的全互联(Full-mesh)。
- ATSW(聚合训练交换机)将一个建筑内的多个AI Zone连接起来,跨AI Zone的带宽收敛比为1:2.8。
- 如图(b)所示,各个建筑之间的ATSW同样采用全互联方式,以实现多个DC Building的互联,跨DC Building的带宽收敛比同样为1:2.8。
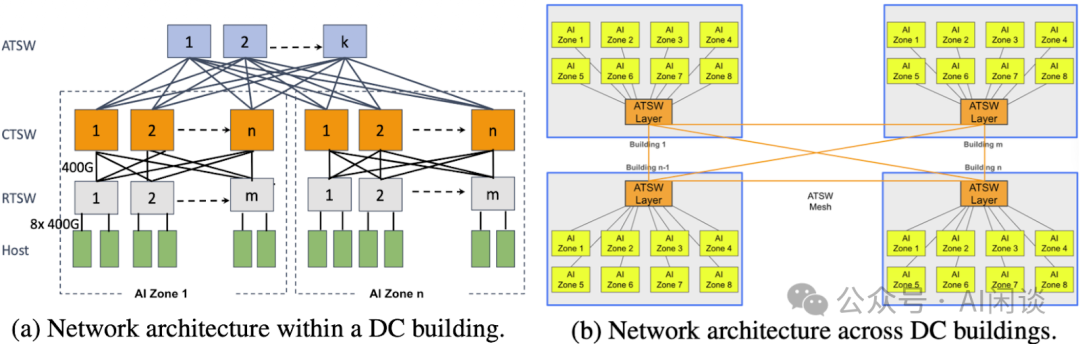
相应的通信时延也存在巨大差异。同一机架内的GPU通信时延最低。同一AI Zone不同机架、同一DC Building不同AI Zone、不同DC Building之间的通信时延分别约为前者的7倍、15倍和30倍。
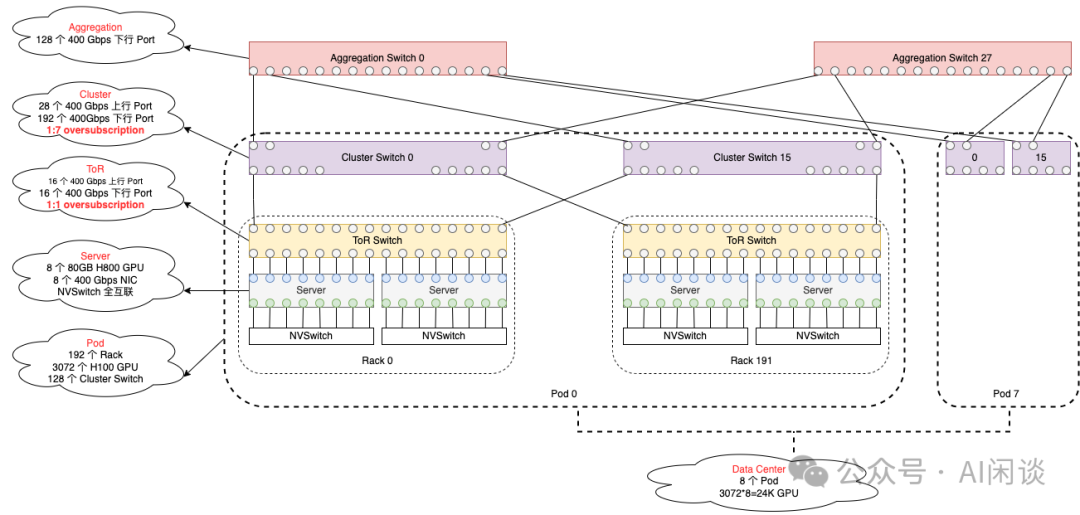
Meta在论文[2407.21783] The Llama 3 Herd of Models中也曾介绍过LLaMA 3训练所用的网络架构。如下图所示,其部分采用了Arista 7800系列交换机。但在新的方案中,跨AI Zone的带宽得到了进一步增加,收敛比从旧的1:7优化为1:2.8,跨DC Building也保持1:2.8。
四、相关工作
4.1 Amazon HSDP
HSDP(Hybrid sharded data parallelism)可以看作是对FSDP(Fully Sharded Data Parallelism)的扩展。简单理解,HSDP相当于把FSDP当作一个DP副本,并在此基础上进一步扩展出多个DP组,当然这会引入额外的通信操作。具体对比如下:
- FSDP:
- 整个集群只有一个逻辑副本,模型参数、梯度、优化器状态被均匀分片到所有GPU上。
- 每张GPU只存储
model_size / world_size 的状态,内存占用最低。
- 所有通信(AllGather参数、ReduceScatter梯度)都需要跨整个集群进行,通信规模随节点数线性增长,容易成为性能瓶颈。
- HSDP:
- 将所有GPU分成
R = world_size / K 个独立的分片组,每组包含K个GPU。
- 每个组相当于一个小型的FSDP副本:
- 组内拥有完整的模型副本,模型参数、梯度、优化器状态均匀分布在组内的K个GPU上。
- 整个任务拥有R个这样的完整模型副本。
- 每个GPU的内存占用比FSDP大R倍,为
model_size / K。
- 除了组内的ReduceScatter梯度聚合外,还需要进行组间(多个副本)的梯度AllReduce,然后各组独立更新优化器状态和参数。
4.2 NVIDIA非均匀张量并行
NVIDIA在论文[2504.06095] Nonuniform-Tensor-Parallelism: Mitigating GPU failure impact for Scaled-up LLM Training中也提出了一种缓解大规模训练中GPU故障影响的方法。其核心包含两项关键技术:非均匀TP和具备增强供电与散热能力的机架方案。
非均匀TP:在标准TP中,张量被均匀切分到TP组内的各个GPU上。当某个GPU故障时,NTP会将故障GPU对应的张量切片及计算负载重新均匀分配到TP组内剩余的健康GPU上。例如,一个TP-64组中有一个GPU故障,剩余的63个GPU将重新构成一个新的TP组。
然而,NTP也带来了新的挑战:
- 一方面,不同DP组之间的TP组大小变得不一致,使得梯度AllReduce操作更加复杂,需要对通信进行专门优化。
- 另一方面,遭遇GPU故障的DP副本会以降低后的TP维度运行,其贡献的吞吐量与剩余健康GPU的比例相匹配,从而导致该TP组成为整个训练流程中的“慢节点”。
具备增强供电与散热能力的机架方案:为缓解“慢节点”导致的性能下降,作者提出了一种创新的机架电源动态分配方案。该设计允许将故障GPU的功率预算重新分配给同机架内正常工作的GPU,使其在不减少本地批次大小的前提下维持全吞吐量运行。实验表明,该方案可近乎完全消除因单GPU故障导致的性能损失。
当然,对于非单一GPU故障或Scale-Up域较小的场景,此方案也存在一定的局限性。
五、FT-HSDP方案
5.1 方案概览
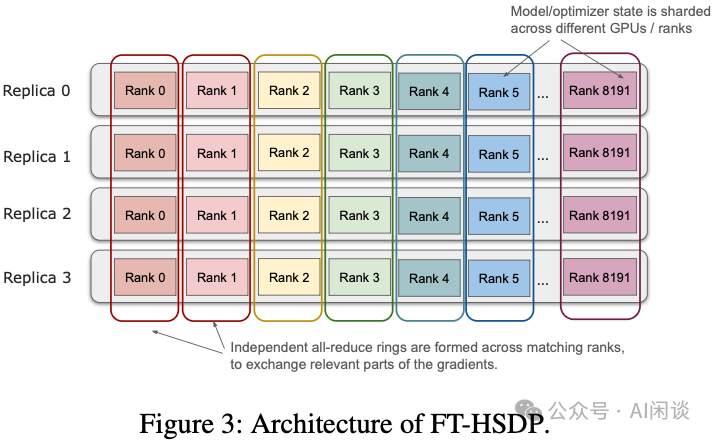
FT-HSDP会创建多个训练副本,每个副本处理不同的数据子集。副本内的每个GPU根据其位置被赋予一个唯一的Rank。在一个训练步完成后,不同副本中相同Rank的GPU需要通过AllReduce来同步梯度。副本内部的通信被限制在同一DC Building内,而跨副本的梯度交换则可以跨越多个DC。
FT-HSDP的容错优势主要体现在两方面:
- 恢复规模小:单个GPU故障只需重建包含该GPU的单个副本,恢复规模大幅缩小,时间显著缩短。(实践中,在98K GPU上使用12个副本,每个副本8192 GPU,以平衡资源利用和恢复开销)。
- 训练不中断:故障副本恢复期间,其他健康副本可以继续正常训练(仅整体吞吐量略有下降),避免了整个系统的完全停顿。
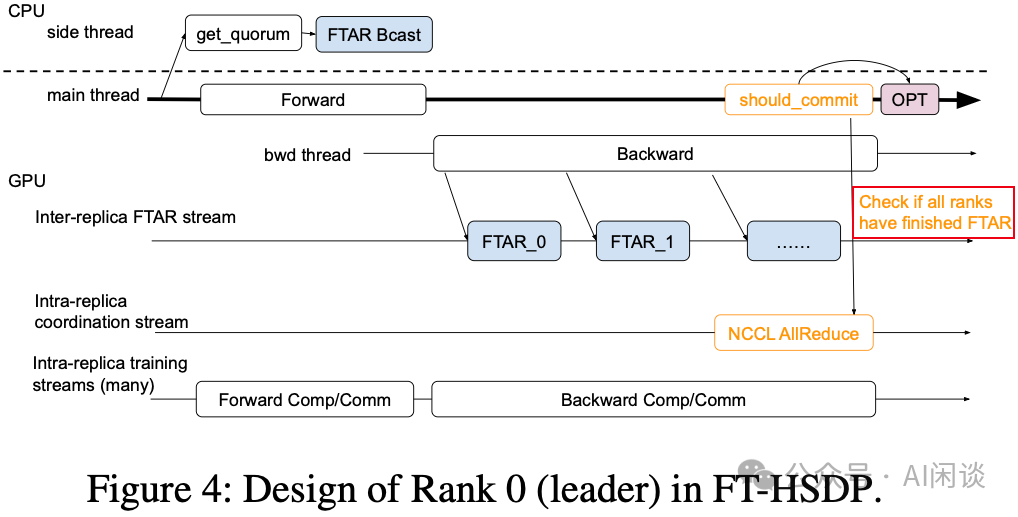
整个FT-HSDP的核心流程如下图所示(Figure 4),以Rank 0(副本Leader)为例:
- 包含多个副本内流,用于执行前向/反向计算以及副本内的通信。
- 包含1个副本间流,专门用于执行FTAR梯度交换。
- 主线程负责执行优化器步骤(OPT)来更新模型权重。
- FT-HSDP将FTAR与反向计算过程重叠,以提升训练速度。
- Rank 0还额外承担控制逻辑:通过共识服务与其他副本的Rank 0协调,确定健康副本集合;同时查询本副本内其他Rank是否已完成梯度交换,以此决定是否执行优化器步骤。
5.2 容错AllReduce协议
跨数据中心的梯度交换无法直接使用标准的NCCL库(因其不支持动态组重建、复杂的错误处理、网络感知等)。为此,FT-HSDP引入了自定义的FTAR协议,旨在满足四大目标:
- 网络感知架构(针对跨DC带宽受限进行拥塞控制)。
- 可重建的通信组(故障后健康Rank能清理旧连接并重建新组)。
- 易于故障管理(能够区分可恢复与不可恢复的错误)。
- 最小化资源争用(与反向计算过程重叠)。
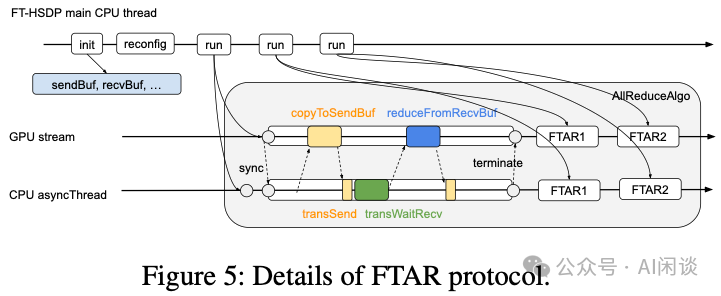
FTAR协议采用了CPU与GPU混合的设计,如上图(Figure 5)所示:
- CPU(控制平面):负责初始化RDMA连接、运行
reconfig函数决定参与梯度交换的Rank、处理拥塞控制、错误分类与重试等逻辑。
- GPU(数据平面):负责将数据拷贝到发送缓冲区、通知CPU、执行RDMA发送/接收、进行归约操作等。
此外,论文还对Ring算法、内核(Kernel)等进行了深度优化,此处不再赘述。
5.3 异常后的一致性保障
FT-HSDP使用了一种类似两阶段提交的协议,作为更新权重前的屏障,以确保故障发生后系统状态的一致性。具体而言,在执行优化器步骤(更新模型权重)之前,副本的Leader(Rank 0)会向副本内的所有GPU确认是否所有的梯度交换都已圆满完成。
- 只有当副本内所有GPU都回复“Yes”时,才会统一执行权重更新。
- 如果有人回复“No”(表明副本中存在故障),Rank 0就会命令副本内的所有GPU重试当前这一步。此时,该异常副本尚未更新模型权重,因此可以直接重新执行该副本的前向传播、反向传播以及梯度ReduceScatter(注:由于梯度聚合是分桶进行且与反向计算重叠,部分梯度可能已被释放,因此需要从前向传播重新开始)。
需要注意的是,由于健康副本会更新权重,而异常副本会回退,这导致了不同副本之间的训练步数可能出现不一致(例如,副本1和2在训练第100步,而副本3还在第99步)。这是FT-HSDP所允许的,也是其实现高效容错的关键所在。
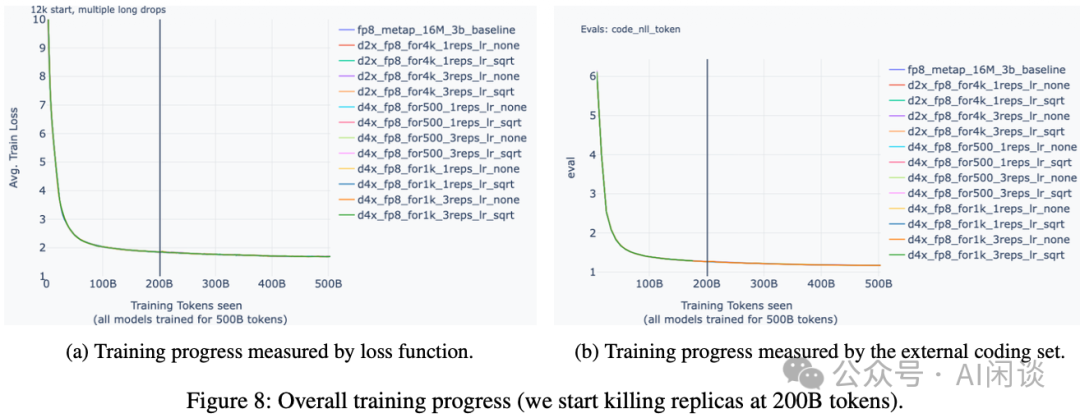
作者通过实验证明,这种“不一致”(与严格的同步训练在数学上不完全等价)并不会对最终模型的训练效果产生负面影响。
5.4 非阻塞追赶协议
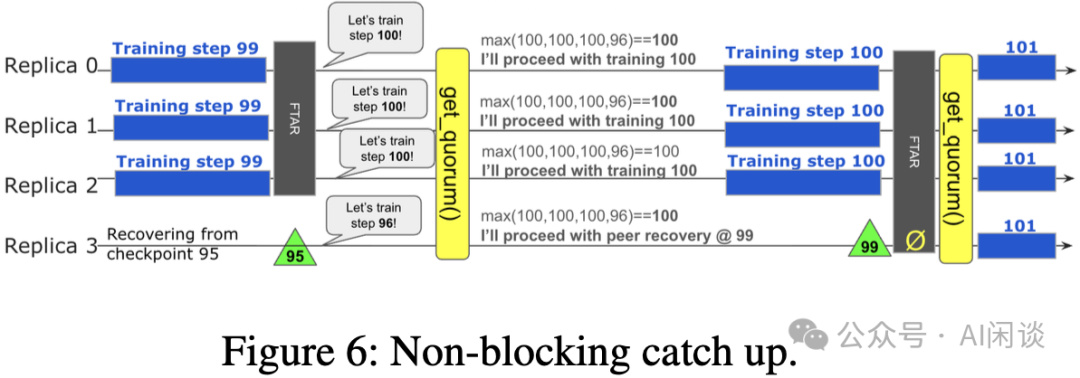
当故障发生时,可能出现副本1成功完成梯度交换并更新权重进入下一步,而副本2因故障导致提交失败,丢弃梯度并停留在当前步的情况。FT-HSDP允许这种跨副本的进度差异,落后的副本随后通过非阻塞追赶协议重新与大部队同步。如上图(Figure 6)所示:
- 每一步训练开始时,各副本通过共识服务上报自己“下一步准备训练的编号”。
- 步数最高的副本(健康副本)正常训练当前步n。
- 落后的副本从健康副本那里获取(fetch)步n-1的检查点。
- 在FTAR阶段:健康副本发送真实的梯度,落后副本则发送零梯度。
- FTAR操作会自动使得所有副本的状态达成一致,从而在下一步共同训练步n+1。
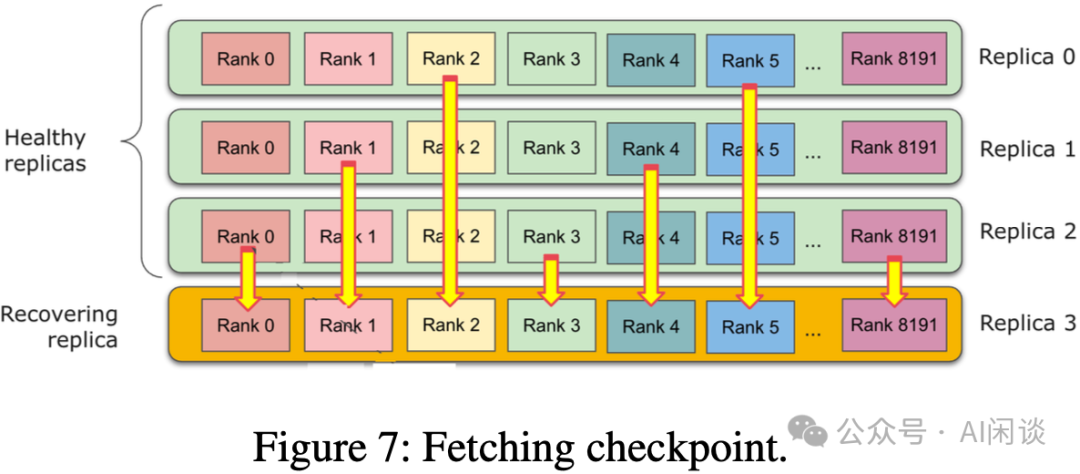
为了确保获取检查点的时间短于一个训练步的耗时,FT-HSDP还实现了一套高效的检查点获取方案,如上图(Figure 7)所示,恢复中的副本可以并行地从多个健康副本获取自己缺失的分片状态。
5.5 实现细节
在工程实现层面,还有一些额外的要点需要注意:
- 数据一致性:既不允许跳过数据,也不允许重复训练同一个批次。这需要精确记录每个DataLoader的状态(如索引和偏移值)。虽然某个副本频繁故障可能导致数据分布极端不均衡,此时可能需要进行批次数据的重新洗牌,但这种概率极低。
- 副本大小权衡:副本太小无法有效节约资源,太大则GPU显存压力剧增。为了缓解显存压力,FT-HSDP增加了将优化器状态卸载到CPU内存的机制,实测拉取1GB数据仅需约60ms,对训练进度影响甚微。
- 首步优化:恢复后的第一个训练步通常很慢。为此,系统将许多初始化过程提前,从而大幅降低了FirstStep的时间。
- 仿真验证:在真实的10万GPU集群上进行测试成本极高。为此,团队创建了仿真工具,透明地将GPU模块替换为CPU模拟版本,计算部分直接跳过,通信部分则用基础的CPU通信库替代。这确保了方案在真实百卡规模部署前就能完成大规模验证。
六、参考链接
- https://arxiv.org/abs/2602.00277
- https://arxiv.org/abs/2402.15627
- https://arxiv.org/abs/2510.20171
- https://arxiv.org/abs/2407.21783
- https://www.arista.com/en/products/7800r3-series/specifications
- https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features-v2-sharded-data-parallelism.html
- https://arxiv.org/abs/2504.06095
对于超大规模分布式训练和AI基础设施的更多深度讨论,欢迎关注云栈社区的相关技术板块。
 发表于 2026-3-1 07:07:28
|
查看: 406|
回复: 0
发表于 2026-3-1 07:07:28
|
查看: 406|
回复: 0
