国内光纤价格正经历一轮显著上涨。截至2026年1月,最新的G.652.D散纤价格已突破40元/芯公里,近一年内的涨幅超过了50%。有行业专家分析,这一轮涨价的主要推手,正是智算中心建设需求的爆发性增长。
那么,一个智算中心的建设,究竟会消耗多少光纤呢?这不仅是成本问题,更关系到前期的布线规划与容量设计。本文将从技术细节出发,重点分析智算中心楼内网络对光纤的真实需求。
智算中心AI组网的总体架构
与传统数据中心不同,智算中心内部根据网络功能的不同,通常划分为多个逻辑或物理隔离的子网。尽管不同厂商的命名可能略有差异,但核心的几大平面基本一致:
- 参数面:也称为训练面或AI计算面,其核心功能是实现智算集群内GPU(或AI加速卡)之间的高速、无损互联,这是支撑大规模模型分布式训练的关键。
- 样本面:也称为存储面,负责实现智算集群与存储区之间的高速数据交换,确保训练所需的海量数据集能够高效供给。
- 业务面:用于承载互联网用户对智算、通用计算等资源的访问流量。
- 管理面:进一步分为带内管理面和带外管理面。带内管理流量走业务网络,而带外管理则拥有独立、高可靠的专用网络,类似于通信设备的管理模式。
智算中心AI组网的总体物理架构可参考下图:
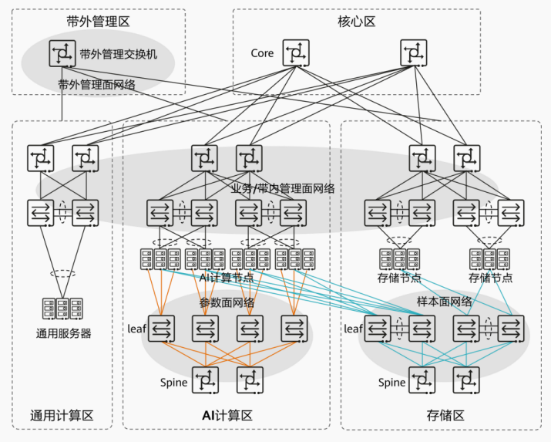
图1:智算中心AI组网物理架构示意图
其中,业务面和管理面的组网与传统数据中心差异不大。真正导致光纤需求激增的,是参数面和样本面的特殊网络架构。
参数面互联光纤需求分析
参数面网络的目标是将成百上千台AI服务器中的GPU连接成一个低时延、高带宽的庞大计算集群。通常,一台AI服务器会配备8张GPU,每张GPU通过一块高速网卡接入参数面网络。
参数面网络架构
参数面网络主要采用两种架构:Leaf-Spine二层架构 和 Leaf-Spine-Core三层架构。这里的Leaf、Spine、Core可以理解为接入层、汇聚层和核心层交换机,并且它们之间通常采用1:1的无收敛设计。
1. Leaf-Spine二层架构
在这种架构下,网络拓扑清晰规整。每台AI服务器的8张GPU,会分别连接到8台不同的Leaf交换机上相同序号的端口。同时,每台Leaf交换机的下行端口会去连接不同服务器中相同序号的GPU。Leaf交换机的所有上行端口,则与所有Spine交换机形成全互联(Full-Mesh)。
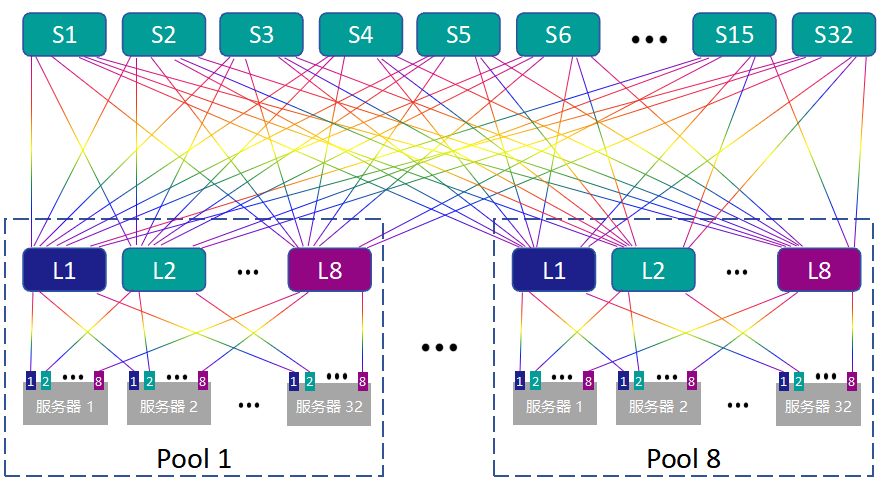
图2:Leaf-Spine二层架构拓扑示意图
假设单台Spine和Leaf交换机的端口数均为P。那么,Spine交换机的数量等于单台Leaf的上行端口数(P/2),Leaf交换机的数量等于单台Spine的端口数(P)。因此,该架构能支持的最大GPU数量为:P × P/2 = P²/2。
2. Leaf-Spine-Core三层架构
当计算集群规模进一步扩大时,会引入Core(核心)层。可以简单理解为,将二层架构中所有的Spine交换机(共P/2台)视为一个整体,作为上一级的“接入设备”,再通过其上行端口连接到多台Core交换机。
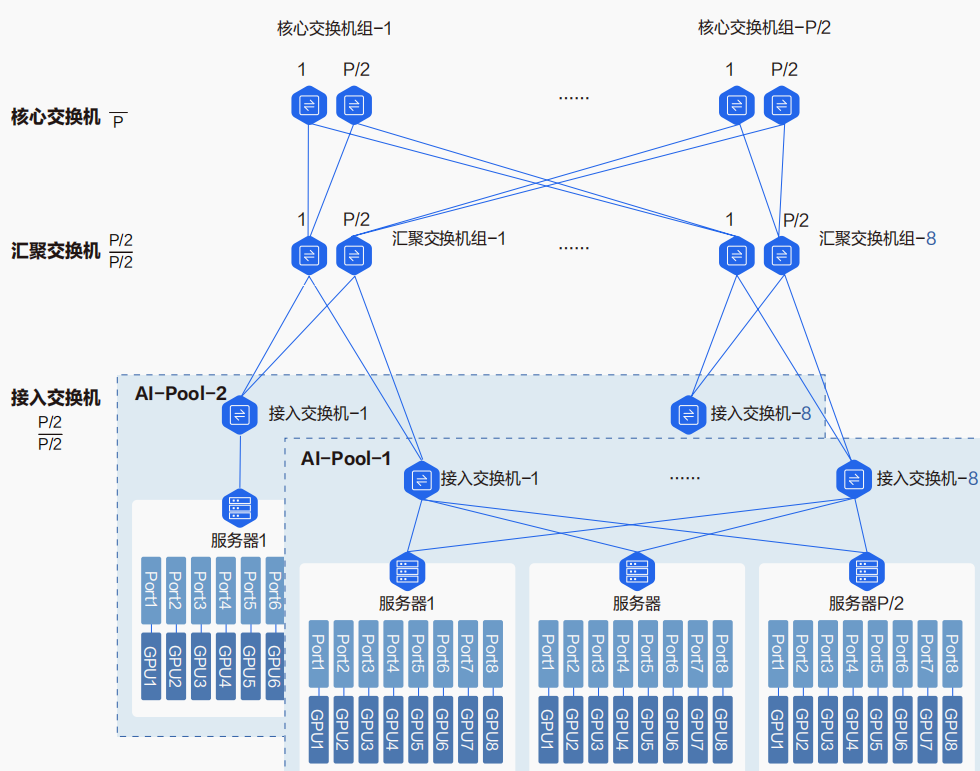
图3:Leaf-Spine-Core三层架构示意图
这种架构的扩展能力更强,能支持的最大GPU数量跃升至 P³/4。不同端口数交换机在两种架构下所能容纳的GPU数量对比如下:
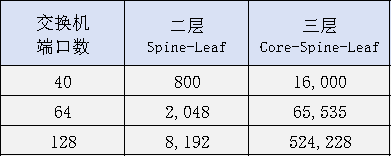
表1:不同网络架构下可容纳的GPU数量
互联光纤需求的影响因素
光纤总需求通常以“芯公里”来衡量,主要取决于三个因素:
- 光信道数量:即交换机之间、交换机与网卡之间需要光纤连接的通路数量。在无收敛的AI网络中,这个数量基本等于GPU的总数。
- 每条光信道的光纤芯数:这与光模块的速率和传输距离有关。例如,在AI服务器到Leaf这段,25G/50G光模块常用2芯多模光纤,100G/200G/400G常用8芯多模光纤,800G/1.6T则可能用到16芯。距离更长的Spine-Core段,通常使用2芯单模光纤。芯数需要与光模块的通道数匹配。
- 每条光信道的长度:这与数据中心的物理布局紧密相关。
- AI服务器 ↔ Leaf:长度取决于一个“计算池”(Pool)内机架的排列,通常在3-30米之间。
- Leaf ↔ Spine:长度取决于一个集群或POD(三层架构中的单元)的规模,约为10-50米。
- Spine ↔ Core:长度由建筑物尺寸决定,通常在30-90米之间。
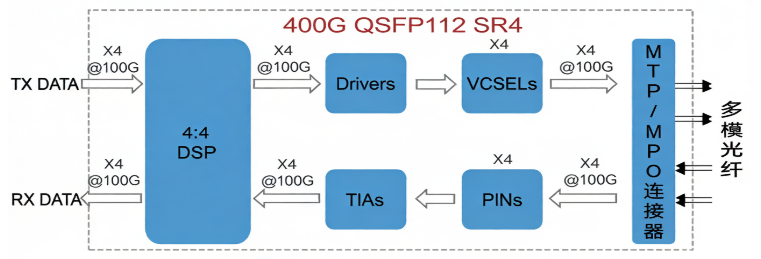
图4:4通道(8芯)多模光模块内部结构示意图
参数面互联光纤需求估算
我们以一个容纳3万张GPU的单体智算中心为例进行估算。假设其中最大的一个1.5万卡集群采用三层架构,其余集群采用二层架构。各段光信道平均长度参考典型值:AI-Leaf段10米,Leaf-Spine段25米,Spine-Core段60米。
估算结果如下表所示:
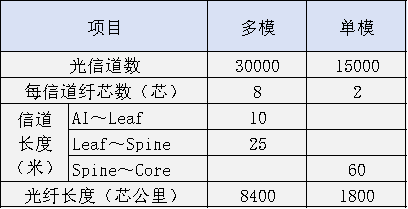
表2:参数面楼内互联光纤需求估算(以3万GPU为例)
从这个估算可以看出,参数面对多模光纤(尤其是OM4)的需求量极大,而楼内单模光纤的需求相对较少。
楼内互联光纤总需求
样本面的网络架构与参数面类似,同样采用1:1无收敛设计,并分为AI侧和存储侧两部分。其光纤需求可以根据与参数面的配置比例进行估算。
以一个实际案例为例:参数面每台AI服务器使用8条200G光信道上联;样本面中,AI侧和存储侧每台服务器各使用2条光信道上联,速率分别为25G和100G。
基于此配置,样本面光纤需求相对于参数面的占比如下表所示:
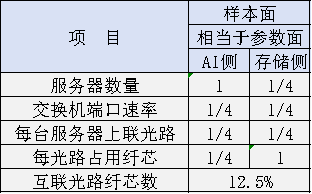
表3:样本面互联光纤需求占比估算
至于业务面和管理面,其网络通常存在收敛比,光纤需求远小于样本面。因此,在规划阶段,我们可以将样本面、业务面和管理面的总光纤需求,粗略估算为参数面需求的20%。
综上,一个智算中心楼内AI组网所需的总光纤芯公里数,大约可以按 参数面需求 × 1.2 的系数来初步估算。
小结
在智算中心建设初期,尽管无法预知所有业务细节,但我们可以根据建筑的供电能力和面积,推算出可承载的GPU总规模。再结合网络架构选型和建筑平面布局,就能相对准确地估算出整个数据中心楼内的光纤布线需求。
核心结论是:智算中心对多模光纤的需求量可能是传统数据中心的十倍甚至数十倍,这是由其特殊的无收敛、高密度网络架构决定的。而楼内对单模光纤的需求虽然绝对量不小,但与长途通信网相比仍属有限。楼间互联部分将产生更大的单模光纤需求,这将是另一个需要深入探讨的话题。
本文由专业技术社区 云栈社区 进行优化编辑,旨在清晰呈现智算中心基础设施规划中的关键考量。技术内容源于行业实践与公开资料分析。
 发表于 2026-2-12 17:11:33
|
查看: 317|
回复: 0
发表于 2026-2-12 17:11:33
|
查看: 317|
回复: 0
