在 Linux 内核中,sysfs 文件系统是极为关键的虚拟文件系统,通常挂载于 /sys 目录,是用户态与内核态交互的重要桥梁。与 proc 文件系统有所不同,proc 文件系统更侧重于提供进程相关信息,而 sysfs 则专注于将内核中的对象,特别是 kobject,以一种层次化的目录结构展示出来,让用户态能够直观地了解内核对象的状态和属性,实现了两者之间的双向交互。
举个例子,在设备驱动管理中,如果禁用了 sysfs,就必须在内核引导命令行上通过设备的主号(major)和副号(minor)指定引导设备,这无疑增加了操作的复杂性。而有了 sysfs,设备的各种信息都能清晰地呈现,用户态可以轻松获取和配置,极大地提高了设备管理的效率。不仅如此,sysfs 在热插拔通知等场景中也发挥着核心作用,当设备插入或拔出时,sysfs 能够及时将这些事件通知给用户态,以便系统做出相应的处理。
一、sysfs 认知
1.1 什么是 sysfs?
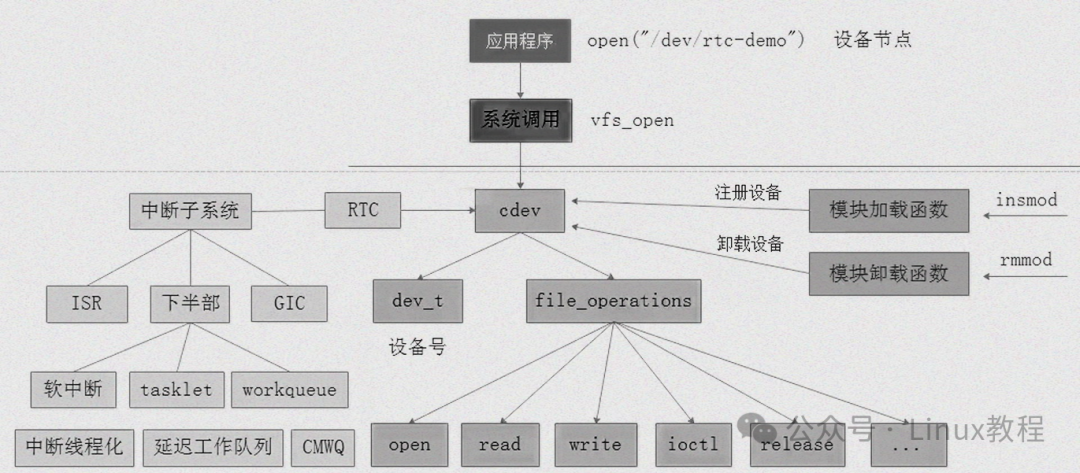
sysfs 是 Linux 内核中基于内存的虚拟文件系统,通常挂载于 /sys 目录,它并不占用实际的磁盘空间,而是将内核中的对象以一种层次化的目录结构呈现给用户态。sysfs 的核心在于以 kobject 为基础,组织和展示内核对象的层次关系。kobject 是 Linux 设备模型中的基本数据结构,它包含了引用计数、层次结构等关键信息,每个 kobject 在 sysfs 中都对应一个目录,使得内核中的对象能够以直观的文件系统形式被用户态访问和管理。
sysfs 具有以下几个核心特性:
- 动态性:sysfs 能够实时反映内核对象的状态变化,无论是设备的插入、移除,还是内核参数的动态调整,sysfs 中的文件和目录都会相应地更新,为用户态提供最新的系统信息。
- 双向性:它不仅允许用户态读取内核对象的属性,还支持用户态向内核写入数据,从而实现对内核行为的配置和控制,这种双向通信机制极大地增强了系统的灵活性和可定制性。
- 结构化:sysfs 采用了清晰的目录结构来组织内核对象,每个目录对应一个 kobject,而目录中的文件则对应着对象的属性,这种结构化的设计使得用户态能够轻松地遍历和操作内核对象。
1.2 sysfs 与 proc 的区别
在 Linux 系统中,proc 文件系统和 sysfs 文件系统都是重要的虚拟文件系统,proc 文件系统诞生较早,最初主要用于提供进程相关的信息,如进程状态、内存使用、文件描述符等,后来逐渐扩展到包含内核参数、系统状态等信息。它的设计相对较为松散,文件和目录的结构缺乏统一的规范,不同的 proc 文件可能采用不同的数据格式和操作方式。
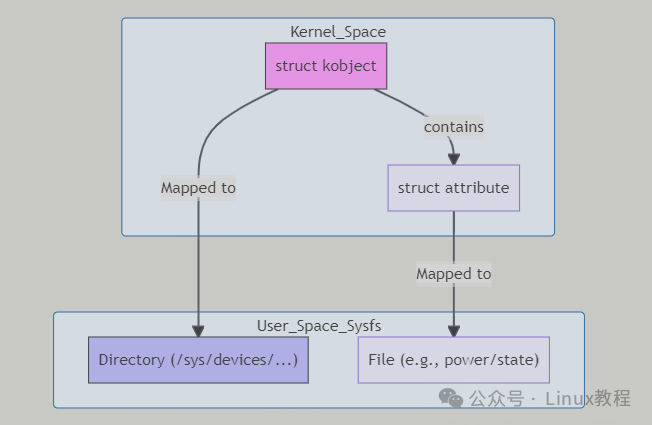
而 sysfs 则是为了更好地管理设备和驱动而设计的,它以 kobject 为核心,构建了一个层次化的设备模型,将设备、驱动、总线等内核对象以清晰的目录结构展示出来。sysfs 遵循 “一个属性一个文件” 的设计原则,每个属性都对应一个独立的文件,数据格式更加规范,用户态读写操作更加便捷。例如,在读取 GPIO 状态时,通过 sysfs 可以直接读取 /sys/class/gpio/gpioX/value 文件,即可获取 GPIO 的电平状态,而在 proc 文件系统中,可能需要通过复杂的字符串解析才能获取到相同的信息。
1.3 sysfs 的核心价值
主要体现在以下三个方面:
- 展示设备树层次结构:sysfs 将系统中的设备、驱动和总线组织成一个清晰的层次化目录结构,可以通过
/sys/devices、/sys/bus 等目录,快速了解系统中硬件设备的连接关系和拓扑结构,为设备驱动的开发和调试提供了极大的便利。
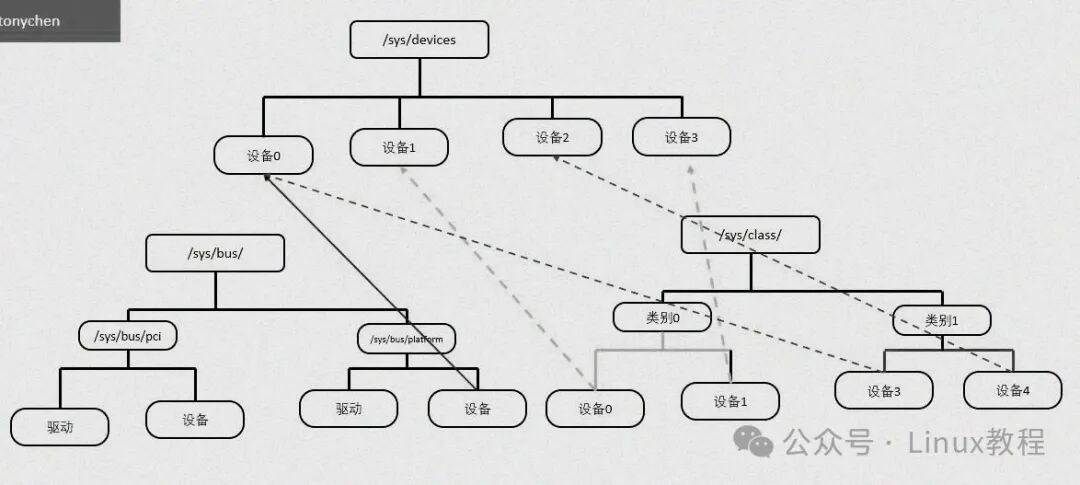
- 暴露内核对象属性与配置接口:通过 sysfs,内核对象的属性和配置参数被以文件的形式暴露给用户态,用户态程序可以通过读写这些文件,实现对内核对象的配置和控制。例如,通过修改
/sys/class/leds/led0/brightness 文件,可以调整 LED 灯的亮度。
- 支持热插拔事件通知:当设备插入或拔出系统时,sysfs 会及时向用户态发送热插拔事件通知,用户态程序可以根据这些通知,做出相应的处理,如加载或卸载设备驱动、更新设备列表等,这为设备的动态管理提供了底层支持。
二、sysfs 的核心数据结构与挂载机制
2.1 三大核心数据结构
想搞懂 sysfs 文件系统底层怎么跑的,真得盯紧那几个核心数据结构——它们就是 sysfs 的“骨架”,没它们整个系统根本立不住。说白了,关键就仨:kobject 负责内核对象的组织和生命周期,kobj_type 定义了这类对象该有哪些操作(比如释放逻辑),attribute 则把具体属性(像设备状态、配置值)挂到 sysfs 目录里,让用户空间能读能写。三者配合得严丝合缝,sysfs 才能稳稳地把内核信息透出来。
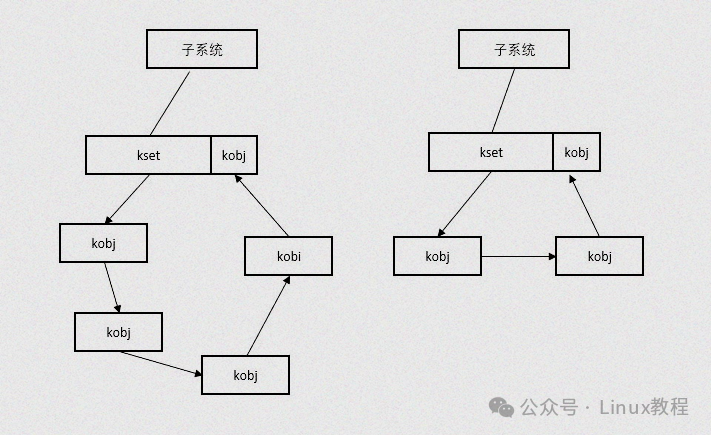
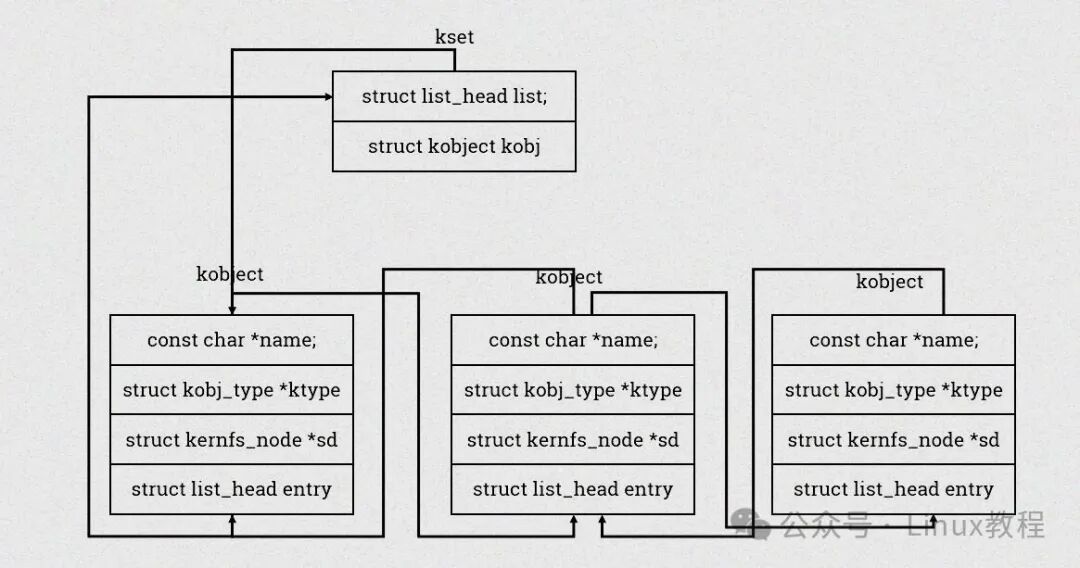
2.1.1 kobject:内核对象的基石
kobject 是 Linux 内核中一个极为重要的结构体,是内核对象的抽象表示——无论是设备(struct device)、驱动(struct device_driver),还是总线(struct bus_type),其内部都嵌入了 kobject 成员,这是它们能被 sysfs 管理的前提。
kobject 的定义(基于 Linux 5.10 内核,最常用版本)如下:
struct kobject {
const char *name;
struct list_head entry;
struct kobject *parent;
struct kset *kset;
struct kobj_type *ktype;
struct kernfs_node *sd;
struct kref kref;
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
};
- name:表示 kobject 的名称,这个名称会作为 sysfs 目录名,例如在
/sys/devices 目录下,每个子目录的名称就是对应 kobject 的 name。
- parent:是一个指向父对象的指针,通过这个指针,kobject 可以构建出层次结构,在 sysfs 中体现为目录的嵌套关系。例如,一个设备的 kobject 的 parent 可能指向其所属总线的 kobject,这样就形成了设备挂载在总线上的层次关系。
- kset:指向该 kobject 所属的对象集合,kset 是一组相关 kobject 的集合,通过 kset 可以方便地对同类 kobject 进行管理。例如,
/sys/bus 目录下的每个子目录就是一个 kset,其中包含了属于该总线的所有设备和驱动的 kobject。
- sd:指向 sysfs 目录项,它是连接 kobject 与 sysfs 文件系统的关键桥梁,通过 sd,kobject 能够在 sysfs 中呈现为一个目录。
kobject 在 sysfs 中起着核心桥梁的作用,它将内核中的对象与 sysfs 的目录结构紧密联系起来。通过 kobject 的层次结构,sysfs 能够清晰地展示内核对象之间的关系,为用户态提供了直观的访问接口。
2.1.2 kobj_type:对象类型的 “说明书”
kobj_type 结构体定义了 kobject 的属性操作规则,相当于 kobject 的“操作说明书”——它告诉 sysfs 如何读取、修改 kobject 的属性,不同类型的 kobject(如设备、驱动)必须绑定不同的 kobj_type,否则会出现属性读写异常。
基于 Linux 5.10 内核的 kobj_type 定义如下:
struct kobj_type {
void (*release)(struct kobject *kobj);
const struct sysfs_ops *sysfs_ops;
struct attribute **default_attrs;
const struct kobj_ns_type_operations *(*child_ns_type)(struct kobject *kobj);
const void *(*namespace)(struct kobject *kobj);
};
- release:是一个函数指针,当 kobject 的引用计数为 0 时,会调用这个函数来释放 kobject 及其相关资源,类似于面向对象编程中的析构函数。
- sysfs_ops:指向一个 sysfs_ops 结构体,其中包含了属性的读写操作函数,负责实现 sysfs 中属性文件的读写逻辑。例如,当用户态读取 sysfs 中的某个属性文件时,实际调用的就是 sysfs_ops 中的 show 函数。
- default_attrs:是一个属性数组,定义了 kobject 的默认属性,这些属性会在 sysfs 中以文件的形式呈现。
不同类型的内核对象需要绑定不同的 kobj_type,以确保属性操作的正确性和一致性。例如,设备对象和驱动对象的 kobj_type 就会有所不同,因为它们的属性和操作方式存在差异。kobj_type 是 sysfs 属性文件读写逻辑的 “总指挥”,它的存在使得 sysfs 能够灵活地支持各种内核对象的属性操作。
2.1.3 attribute:属性文件的载体
attribute 结构体是 sysfs 中属性文件的载体,每个 attribute 对应 sysfs 中的一个文件,通过 attribute 可以实现用户态与内核属性的双向交互。attribute 的定义如下:
struct attribute {
const char *name;
umode_t mode;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
bool ignore_lockdep:1;
struct lock_class_key *key;
struct lock_class_key skey;
#endif
};
- name:表示属性文件名,在 sysfs 中,这个名称就是属性文件的文件名。
- mode:定义了文件的权限,例如 0444 表示只读权限,0644 表示读写权限。
每个 attribute 都会绑定到 kobj_type 的 sysfs_ops 中的读函数和写函数,当用户态对 sysfs 中的属性文件进行读写操作时,就会调用这些函数来实现内核属性与用户态数据的交互。例如,通过修改 /sys/class/leds/led0/brightness 文件(对应一个 attribute),就可以调整 LED 灯的亮度,这背后就是通过 attribute 绑定的读写函数来实现的。
2.2 sysfs 内核挂载流程:从 start_kernel 到 sysfs_init
sysfs 的初始化挂载过程是一个复杂而有序的过程,它涉及到多个内核函数的调用和数据结构的初始化。
在 Linux 内核启动时,start_kernel 函数会被调用,这是内核启动的入口函数。在 start_kernel 函数中,会调用一系列的初始化函数,其中就包括 sysfs_init 函数,用于初始化 sysfs 文件系统。sysfs_init 函数的主要逻辑如下:
int __init sysfs_init(void) {
int err = -ENOMEM;
// 创建一个分配sysfs_dirent的cache
sysfs_dir_cachep = kmem_cache_create("sysfs_dir_cache", sizeof(struct sysfs_dirent), 0, 0, NULL);
if (!sysfs_dir_cachep)
goto out;
err = sysfs_inode_init();
if (err)
goto out_err;
// 注册sysfs文件系统类型
err = register_filesystem(&sysfs_fs_type);
if (!err) {
// 挂载sysfs文件系统
sysfs_mount = kern_mount(&sysfs_fs_type);
if (IS_ERR(sysfs_mount)) {
printk(KERN_ERR "sysfs: could not mount!\n");
err = PTR_ERR(sysfs_mount);
sysfs_mount = NULL;
unregister_filesystem(&sysfs_fs_type);
goto out_err;
}
} else
goto out_err;
out:
return err;
out_err:
kmem_cache_destroy(sysfs_dir_cachep);
sysfs_dir_cachep = NULL;
goto out;
}
- 创建 sysfs_dirent 缓存:通过
kmem_cache_create 函数创建一个用于分配 sysfs_dirent 的缓存,sysfs_dirent 是 sysfs 中用于管理目录项的结构体,通过缓存可以提高内存分配的效率。
- 初始化 sysfs inode:调用
sysfs_inode_init 函数初始化 sysfs 的 inode,inode 是文件系统中用于描述文件或目录的元数据结构,初始化 inode 为后续的文件操作做好准备。
- 注册 sysfs 文件系统类型:使用
register_filesystem 函数注册 sysfs 文件系统类型,将 sysfs 文件系统注册到内核的文件系统管理模块中,使得内核能够识别和管理 sysfs 文件系统。
- 挂载 sysfs 文件系统:通过
kern_mount 函数挂载 sysfs 文件系统,该函数会创建一个 vfsmount 结构体来表示已挂载的文件系统,并将 sysfs 文件系统挂载到指定的目录(通常是 /sys)。
在这个过程中,register_filesystem 和 kern_mount 是两个关键的函数。register_filesystem 函数会将 sysfs 文件系统类型添加到内核的文件系统类型链表中,而 kern_mount 函数则会创建一个新的 vfsmount 结构体,并调用 sysfs 文件系统的 get_sb 函数来获取超级块(super_block),从而完成文件系统的挂载。通过这一系列的操作,sysfs 文件系统成功地挂载到了内核中,为用户态提供了访问内核对象的接口。
2.3 内核对象如何进入 sysfs?
内核对象要在 sysfs 中显示,核心是通过 kset_create_and_add() 函数完成“创建 kset → 关联 kobject → 生成 sysfs 目录”的流程。
kset 是同类 kobject 的集合,总线、设备、驱动都有对应的 kset,这里以总线对象(最典型场景)为例,拆解 kset_create_and_add() 的调用链路与源码逻辑,帮大家理解内核对象如何“落地”到 sysfs。
在 Linux 内核中,当创建一个 bus 对象时,会调用 kset_create_and_add 函数来创建对应的 sysfs 目录。kset_create_and_add 函数的调用链路如下:
// 创建一个kset对象,并将其添加到sysfs中
kset_create_and_add(const char *name, const struct kset_uevent_ops *uevent_ops, struct kobject *parent) {
struct kset *kset;
kset = kset_create(name, uevent_ops, parent);
if (!kset)
return NULL;
if (kobject_add(&kset->kobj, parent, "%s", name)) {
kset_unregister(kset);
return NULL;
}
return kset;
}
- 创建 kset 对象:kset_create() 函数会初始化 kset 结构体,包括其内部的 kobject、uevent 操作函数等。例如创建 USB 总线 kset 时,会指定 uevent 操作函数,用于处理 USB 设备热插拔事件。若创建失败,返回 NULL,需及时处理错误。
- 添加 kset 对象到 sysfs:kobject_add() 是核心步骤,会将 kset 内部的 kobject 添加到内核,同时根据 parent 指针确定其在 sysfs 中的父目录,最终创建对应的目录。例如 USB 总线 kset 的 parent 是内核顶层 kobject,因此会在 /sys/bus/ 目录下生成 usb 子目录。
kobject_add 函数的源码逻辑如下:
int kobject_add(struct kobject *kobj, struct kobject *parent, const char *fmt, ...) {
va_list args;
int error = -ENOENT;
if (!kobj)
return -EINVAL;
if (!kobj->name && fmt) {
va_start(args, fmt);
error = vsnprintf(kobj->name, KOBJ_NAME_LEN, fmt, args);
va_end(args);
if (error < 0 || error >= KOBJ_NAME_LEN)
return -ENOENT;
}
kobj->parent = parent;
if (parent)
kobj->kset = parent->kset;
error = kobject_add_internal(kobj);
if (!error)
kobject_uevent(kobj, KOBJ_ADD);
return error;
}
- 确定父目录:parent 指针非空时,kobject 目录嵌套在父 kobject 目录下;parent 为空时,目录直接创建在 /sys 顶层(不推荐,会导致目录结构混乱)。例如设备 kobject 的 parent 指向总线 kobject,因此设备目录会在 /sys/bus/[总线名]/devices/ 下。
- 创建 kernfs 节点:kobject_add_internal() 会调用 kernfs_create_dir() 创建 kernfs 节点(sysfs 底层节点),并将其添加到父节点的子链表中。同时会初始化 kobject 的 sd 成员,关联该 kernfs 节点——这是 kobject 与 sysfs 绑定的关键一步。
- 关联 kobject 与 kernfs 节点:kernfs 节点会记录对应的 kobject 指针,后续用户态操作 sysfs 目录时,内核可通过 kernfs 节点快速找到对应的 kobject,进而执行属性读写操作。
通过 kset_create_and_add 函数的调用链路和 kobject_add 函数的源码逻辑,可以看到内核对象是如何一步步进入 sysfs,并在 sysfs 中生成对应的目录结构的。这个过程实现了内核对象到用户态目录的映射,使得用户态能够通过 sysfs 方便地访问和管理内核对象。
三、实战:从零编写 sysfs 模块,实现属性读写
3.1 核心步骤 1:创建 kobject 与 sysfs 目录
在编写 sysfs 模块时,创建 kobject 与对应的 sysfs 目录是第一步,也是至关重要的一步。在 Linux 内核中,使用 kobject_create_and_add 函数来完成这一操作。该函数的原型如下:
struct kobject *kobject_create_and_add(const char *name, struct kobject *parent);
name:表示要创建的目录名,这个名称将直接显示在 sysfs 文件系统中,例如可以将其设置为 "my_custom_sysfs",那么在 /sys 目录下就会创建一个名为 my_custom_sysfs 的子目录。parent:是指向父 kobject 的指针,如果设置为 NULL,则表示创建的 kobject 位于 sysfs 的顶层目录;如果指定了一个已存在的 kobject 作为 parent,那么新创建的 kobject 将作为该 parent 的子目录。例如,可以将 kernel_kobj 作为 parent,这样创建的目录就会位于 /sys/kernel 目录下。
使用 kobject_create_and_add() 时,错误处理是重中之重——内核开发中,内存分配、资源创建失败是常见场景,若未处理,会导致内存泄漏或系统不稳定。以下是贴合实操的代码示例,包含完整的错误处理逻辑,同时补充常见问题排查技巧:
struct kobject *my_kobj;
my_kobj = kobject_create_and_add("my_custom_sysfs", kernel_kobj);
if (!my_kobj) {
printk(KERN_ERR "Failed to create kobject\n");
return -ENOMEM;
}
上述代码中,若 kobject_create_and_add() 返回 NULL,大概率是内存不足,需打印错误日志并返回对应错误码(-ENOMEM),避免后续操作访问空指针。此外,若父 kobject 不存在(如错误指定 parent 为未创建的对象),也会导致目录创建失败,可通过 dmesg 查看“kobject: parent (xxx) is not defined”类错误日志。
当 kobject 不再需要时,必须调用 kobject_put() 释放资源——该函数会减少 kobject 的引用计数,当计数为 0 时,自动调用 kobj_type 的 release 函数,释放 kobject 及关联的 sysfs 目录。需注意“创建-释放”配对原则,常见场景如下:
kobject_put(my_kobj);
在模块卸载函数中,通常会调用 kobject_put 函数来释放创建的 kobject,确保资源的正确回收。通过正确使用 kobject_create_and_add 和 kobject_put 函数,可以在 sysfs 中成功创建和管理 kobject 及其对应的目录。
3.2 核心步骤 2:创建属性文件(两种方式)
在 sysfs 中创建属性文件有两种常见的方式,分别是手动定义和使用 __ATTR 宏简化开发。
3.2.1 手动定义:sysfs_ops + attribute
手动定义属性文件需要我们深入了解 sysfs 的底层原理,通过定义 sysfs_ops 和 attribute 结构体来实现。首先,需要定义读属性(show)和写属性(store)的函数。例如,定义一个简单的读函数 my_value_show 和写函数 my_value_store:
static ssize_t my_value_show(struct kobject *kobj, struct attribute *attr, char *buf){
int value = 42; // 假设这是我们要读取的内核属性值
return sprintf(buf, "%d\n", value);
}
static ssize_t my_value_store(struct kobject *kobj, struct attribute *attr, const char *buf, size_t count){
int new_value;
if (kstrtoint(buf, 10, &new_value) != 0) {
return -EINVAL;
}
// 这里可以对new_value进行处理,例如更新内核属性值
return count;
}
上述代码中,my_value_show() 函数的核心是将内核属性值写入 buf 缓冲区,供用户态读取——需注意 buf 缓冲区大小固定为 PAGE_SIZE(默认 4096 字节),因此写入的数据长度不能超过该值,否则会导致缓冲区越界。my_value_store() 函数则是读取用户态传入的 buf 数据,转换为整数后更新内核属性,这里用 kstrtoint() 函数(内核提供的安全转换函数)替代 atoi(),可避免非法输入导致的程序崩溃。
接下来,将这两个函数封装为 sysfs_ops 结构体:
static struct sysfs_ops my_sysfs_ops = {
.show = my_value_show,
.store = my_value_store,
};
然后,定义 attribute 结构体,指定属性文件名和权限:
static struct attribute my_attribute = {
.name = "my_attribute",
.mode = S_IRUGO | S_IWUSR,
};
在这个例子中,属性文件名为 my_attribute,权限设置为用户可读可写,组和其他用户可读。
最后,将 sysfs_ops 和 attribute 绑定,并关联到之前创建的 kobject 上:
static struct kobj_type my_ktype = {
.sysfs_ops = &my_sysfs_ops,
.default_attrs = &my_attribute,
};
my_kobj->ktype = &my_ktype;
手动定义方式的核心是“绑定三者关系”:kobject → kobj_type → sysfs_ops + attribute,需注意两个关键细节:一是 default_attrs 是属性数组,需以 NULL 结尾(否则会导致内核遍历属性时越界);二是 kobject 必须绑定 kobj_type,否则属性文件无法正常读写,会返回“Operation not permitted”错误。这种方式的优势是灵活,可自定义 sysfs_ops 的其他扩展操作,适合复杂场景。
3.2.2 快捷方式:使用__ATTR 宏简化开发
为了简化属性文件的创建过程,Linux 内核提供了 __ATTR 宏。__ATTR 宏可以直接封装属性名、权限、读写函数,生成 kobj_attribute 结构体,大大减少了手动编写的代码量。__ATTR 宏的定义如下:
#define __ATTR(_name, _mode, _show, _store) \
struct kobj_attribute kobj_attr_##_name = __ATTR_INITIALIZER(_name, _mode, _show, _store)
__ATTR 宏是内核提供的快捷工具,本质是自动生成 kobj_attribute 结构体(继承自 attribute 和 kobj_type 相关逻辑),无需手动定义 sysfs_ops 和 kobj_type,大幅减少冗余代码。其核心参数解读:_name(属性文件名)、_mode(文件权限)、_show(读函数,参数需为 struct kobj_attribute)、*_store(写函数,参数同上)。需注意,读函数和写函数的参数必须与 kobj_attribute 匹配,否则会出现编译错误。
static ssize_t my_value_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf){
int value = 42; // 假设这是我们要读取的内核属性值
return sprintf(buf, "%d\n", value);
}
static ssize_t my_value_store(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t count){
int new_value;
if (kstrtoint(buf, 10, &new_value) != 0) {
return -EINVAL;
}
// 这里可以对new_value进行处理,例如更新内核属性值
return count;
}
static struct kobj_attribute my_attribute = __ATTR(my_attribute, 0644, my_value_show, my_value_store);
在上述代码中,使用 __ATTR 宏创建了一个名为 my_attribute 的属性文件,权限为 0644,读函数为 my_value_show,写函数为 my_value_store。与手动定义方式相比,使用 __ATTR 宏的代码更加简洁明了,开发效率更高。然而,手动定义方式虽然代码量较多,但它提供了更大的灵活性,可以根据具体需求对 sysfs_ops 和 attribute 结构体进行更精细的控制。
3.3 完整模块示例:编译运行,验证 sysfs 读写
为了更好地理解 sysfs 模块的开发过程,我们来看一个完整的内核模块示例,该示例涵盖了模块的初始化和卸载函数,以及属性文件的创建和读写操作。
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/sysfs.h>
#include <linux/kobject.h>
#include <asm/atomic.h>
static struct kobject *my_kobj;
static atomic_t my_value = ATOMIC_INIT(0);
// 读属性函数
static ssize_t my_value_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf){
return sprintf(buf, "%d\n", atomic_read(&my_value));
}
// 写属性函数
static ssize_t my_value_store(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t count){
int new_value;
if (kstrtoint(buf, 10, &new_value) != 0) {
return -EINVAL;
}
atomic_set(&my_value, new_value);
return count;
}
// 使用__ATTR宏定义属性
static struct kobj_attribute my_attribute = __ATTR(my_value, 0664, my_value_show, my_value_store);
// 模块初始化函数
static int __init my_sysfs_init(void){
my_kobj = kobject_create_and_add("my_custom_sysfs", kernel_kobj);
if (!my_kobj) {
printk(KERN_ERR "Failed to create kobject\n");
return -ENOMEM;
}
// 在kobject对应的sysfs目录下创建属性文件
if (sysfs_create_file(my_kobj, &my_attribute.attr)) {
kobject_put(my_kobj);
printk(KERN_ERR "Failed to create sysfs file\n");
return -EIO;
}
printk(KERN_INFO "Sysfs module loaded successfully\n");
return 0;
}
// 模块卸载函数
static void __exit my_sysfs_exit(void){
sysfs_remove_file(my_kobj, &my_attribute.attr);
kobject_put(my_kobj);
printk(KERN_INFO "Sysfs module unloaded successfully\n");
}
module_init(my_sysfs_init);
module_exit(my_sysfs_exit);
MODULE_LICENSE("GPL");
在上述代码中,my_sysfs_init 函数负责模块的初始化工作,首先创建一个 kobject,并在 /sys/kernel 目录下创建一个名为 my_custom_sysfs 的子目录。然后使用 sysfs_create_file 函数在该目录下创建一个名为 my_value 的属性文件,该文件的读写操作由 my_value_show 和 my_value_store 函数实现。my_sysfs_exit 函数则负责在模块卸载时,移除属性文件并释放 kobject。
接下来,需要编写 Makefile 来编译这个内核模块。Makefile 的内容如下:
obj-m += my_sysfs_module.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
在这个 Makefile 中,obj-m 指定了要编译的模块对象,all 目标表示编译模块,clean 目标表示清理编译生成的文件。-C 选项指定了内核源码的路径,M=$(PWD) 表示模块源码所在的当前目录。
编译完成后,可以使用 insmod 命令加载模块,使用 rmmod 命令卸载模块。加载模块后,可以通过 cat 命令读取属性文件的值,通过 echo 命令写入属性文件的值,例如:
# 加载模块
sudo insmod my_sysfs_module.ko
# 读取属性文件
cat /sys/kernel/my_custom_sysfs/my_value
# 写入属性文件
echo 100 | sudo tee /sys/kernel/my_custom_sysfs/my_value
通过以上操作,我们可以验证 sysfs 模块的读写功能是否正常。在实际开发中,可以根据具体需求对属性文件的读写逻辑进行扩展和优化,以实现更复杂的内核与用户态交互功能。
四、进阶与最佳实践
4.1 进阶技巧:属性组与二进制属性
4.1.1 属性组:批量管理多个属性
在实际开发中,一个内核对象往往有多个关联属性(如音频设备有音量、声道、采样率等),若逐个创建属性文件,会导致代码冗余、目录结构混乱。属性组(attribute_group)可解决这个问题——将多个属性打包成组,创建时会自动生成一个子目录,所有属性文件都放在该子目录下,既便于管理,也能提升代码可读性。
在 Linux 内核中,属性组通过 struct attribute_group 结构体来实现。该结构体的定义如下:
struct attribute_group {
const char *name;
struct attribute **attrs;
const struct attribute_group_ops *ops;
const void *ns;
};
name:表示属性组的名称,这个名称将作为 sysfs 中的子目录名。attrs:是一个指向属性数组的指针,该数组包含了属于这个属性组的所有属性。
我们可以通过 sysfs_create_group 函数来创建属性组,该函数的原型为:
int sysfs_create_group(struct kobject *kobj, const struct attribute_group *grp);
其中,kobj 是指向父 kobject 的指针,grp 是指向 struct attribute_group 结构体的指针。
假设正在开发一个音频设备驱动,该设备有音量、声道、采样率等多个属性。如果不使用属性组,就需要为每个属性分别创建文件,这样会导致 sysfs 目录结构比较混乱。而使用属性组,可以将这些属性组织在一起,使 sysfs 目录更加清晰。以下是一个简单的代码示例:
// 定义音量属性的读写函数
static ssize_t volume_show(struct kobject *kobj, struct attribute *attr, char *buf){
int volume = get_volume(); // 获取当前音量
return sprintf(buf, "%d\n", volume);
}
static ssize_t volume_store(struct kobject *kobj, struct attribute *attr, const char *buf, size_t count){
int new_volume;
if (kstrtoint(buf, 10, &new_volume) != 0) {
return -EINVAL;
}
set_volume(new_volume); // 设置新的音量
return count;
}
// 定义声道属性的读写函数
static ssize_t channels_show(struct kobject *kobj, struct attribute *attr, char *buf){
int channels = get_channels(); // 获取当前声道数
return sprintf(buf, "%d\n", channels);
}
static ssize_t channels_store(struct kobject *kobj, struct attribute *attr, const char *buf, size_t count){
int new_channels;
if (kstrtoint(buf, 10, &new_channels) != 0) {
return -EINVAL;
}
set_channels(new_channels); // 设置新的声道数
return count;
}
// 定义属性
static struct attribute volume_attr = {
.name = "volume",
.mode = S_IRUGO | S_IWUSR,
};
static struct attribute channels_attr = {
.name = "channels",
.mode = S_IRUGO | S_IWUSR,
};
// 定义属性数组
static struct attribute *audio_attrs[] = {
&volume_attr,
&channels_attr,
NULL,
};
// 定义属性组
static struct attribute_group audio_group = {
.name = "audio_settings",
.attrs = audio_attrs,
};
// 创建属性组
sysfs_create_group(my_kobj, &audio_group);
上述代码,创建属性组后,会在 my_kobj 对应的 /sys/kernel/my_custom_sysfs/ 目录下生成 audio_settings 子目录,里面包含 volume 和 channels 两个属性文件。此外,属性组还支持批量删除(sysfs_remove_group()),卸载模块时只需调用一次该函数,即可删除所有组内属性文件,无需逐个删除,大幅简化代码。需注意,属性数组必须以 NULL 结尾,否则内核会遍历到非法内存地址,导致系统崩溃。
4.1.2 二进制属性:传输大块数据
普通文本属性适合传输少量字符数据(如数值、字符串),但在传输大块数据(如设备固件、图像数据、日志文件)时,效率极低,且容易出现数据截断。二进制属性(bin_attribute)专为大块数据传输设计,支持任意格式的二进制数据,传输大小可通过 size 成员灵活配置,是内核与用户态传输大块数据的首选方式。
在 Linux 内核中,二进制属性通过 struct bin_attribute 结构体来实现。该结构体的定义如下:
struct bin_attribute {
struct attribute attr;
size_t size;
ssize_t (*read)(struct kobject *kobj, char *buffer, loff_t pos, size_t size);
ssize_t (*write)(struct kobject *kobj, char *buffer, loff_t pos, size_t size);
};
attr:是一个普通的 struct attribute 结构体,用于指定属性的名称、权限等基本信息。size:指定了二进制数据的最大大小,如果设置为 0,则表示没有大小限制。read 和 write:是两个函数指针,分别用于实现二进制数据的读取和写入操作。
二进制属性的 read/write 函数与普通属性的 show/store 函数核心区别:支持偏移量 pos,可实现断点续传(如传输大固件时,中断后可从指定 pos 继续传输)。以下是固件传输的实操示例,模拟内核向用户态传输固件数据:
static ssize_t firmware_read(struct kobject *kobj, char *buffer, loff_t pos, size_t size){
// 假设firmware_data是内核中存储固件数据的缓冲区
char *firmware_data = get_firmware_data();
size_t available_size = get_firmware_size() - pos;
if (available_size < size) {
size = available_size;
}
memcpy(buffer, firmware_data + pos, size);
return size;
}
write 函数用于用户态向内核传输二进制数据(如更新设备固件),需注意边界校验——若 pos + size 超过固件缓冲区大小,直接返回错误,避免缓冲区越界。此外,二进制属性的权限建议设置为 0600(仅 root 可读写),防止普通用户非法传输恶意固件,保障设备安全。
static ssize_t firmware_write(struct kobject *kobj, char *buffer, loff_t pos, size_t size){
// 假设firmware_data是内核中存储固件数据的缓冲区
char *firmware_data = get_firmware_data();
if (pos + size > get_firmware_size()) {
return -EINVAL;
}
memcpy(firmware_data + pos, buffer, size);
return size;
}
在上述代码中,firmware_read 函数从内核中的固件数据缓冲区中读取数据,并将其复制到用户提供的缓冲区中;firmware_write 函数则将用户提供的缓冲区中的数据复制到内核中的固件数据缓冲区中。
可以通过 sysfs_create_bin_file 函数来创建二进制属性文件,该函数的原型为:
int sysfs_create_bin_file(struct kobject *kobj, struct bin_attribute *attr);
其中,kobj 是指向父 kobject 的指针,attr 是指向 struct bin_attribute 结构体的指针。通过创建二进制属性文件,可以方便地在用户态和内核态之间传输大块数据,满足一些特殊场景的需求。
4.2 最佳实践
4.2.1 权限设置:安全第一的配置原则
在 sysfs 中,正确设置属性的权限是保障系统安全的重要环节。不同类型的属性应该设置不同的权限,以确保只有授权的用户或进程能够访问和修改这些属性。一般来说,遵循以下权限配置规范:
- 只读属性:对于那些只需要被读取,而不允许被修改的属性,通常将其权限设置为
0444,即所有者、组和其他用户都具有读权限。例如,设备的硬件版本号、序列号等属性,这些信息只需要被查询,不需要被修改,因此可以设置为只读权限。
- 读写属性:对于那些需要被读写的属性,将其权限设置为
0644,即所有者具有读写权限,组和其他用户具有读权限。比如,设备的一些可配置参数,如音量、亮度等属性,所有者可以进行修改,而其他用户只能读取。
- 敏感操作属性:对于一些涉及敏感操作的属性,如设备的重置、格式化等操作,将其权限设置为
0200,即只有所有者(通常是 root 用户)具有写权限,其他用户没有任何权限。这样可以防止普通用户误操作或恶意操作,保障系统的安全性。
错误的权限配置不仅会导致功能异常,还可能引发安全漏洞,这里举两个真实开发中的反面案例:1. 某设备将“设备重置”属性权限设为 0644,普通用户可通过 echo 1 > reset 触发设备重置,导致服务中断;2. 某驱动将“硬件序列号”属性设为 0200,用户态无法读取,导致设备管理工具无法识别设备。因此,权限设置需严格遵循“最小权限原则”,无需写权限的属性坚决设为只读,敏感操作仅开放给 root 用户。
4.2.2 错误处理与资源释放:避免内存泄漏
在 sysfs 操作中,错误处理和资源释放是至关重要的环节。由于 sysfs 操作涉及到内核资源的分配和管理,如果不妥善处理错误和释放资源,可能会导致内存泄漏、系统不稳定等问题。
在进行 sysfs 操作时,必须检查所有函数的返回值,以判断操作是否成功。例如,在使用 sysfs_create_file 函数创建属性文件时,需要检查其返回值:
int ret = sysfs_create_file(my_kobj, &my_attribute.attr);
if (ret) {
printk(KERN_ERR "Failed to create sysfs file\n");
// 执行资源释放操作
kobject_put(my_kobj);
return -EIO;
}
在上述代码中,如果 sysfs_create_file 函数返回非零值,表示创建文件失败,此时需要打印错误信息,并执行资源释放操作,即调用 kobject_put 函数释放之前创建的 kobject,以避免内存泄漏。
sysfs 操作的错误处理需遵循“失败回滚”原则——只要某一步操作失败,就必须释放之前已经分配的所有资源,避免内存泄漏。
以下是创建 kobject 和属性文件的完整错误处理示例:
my_kobj = kobject_create_and_add("my_custom_sysfs", kernel_kobj);
if (!my_kobj) {
printk(KERN_ERR "Failed to create kobject\n");
return -ENOMEM;
}
// 创建属性组(假设使用属性组管理多个属性)
int ret = sysfs_create_group(my_kobj, &my_attr_group);
if (ret) {
printk(KERN_ERR "Failed to create attribute group\n");
kobject_put(my_kobj); // 回滚:释放已创建的kobject
return -EIO;
}
// 创建二进制属性(可选)
ret = sysfs_create_bin_file(my_kobj, &my_bin_attr);
if (ret) {
printk(KERN_ERR "Failed to create binary attribute\n");
sysfs_remove_group(my_kobj, &my_attr_group); // 回滚:移除属性组
kobject_put(my_kobj); // 回滚:释放kobject
return -EIO;
}
在这个例子中,如果 sysfs_create_file 函数失败,调用 kobject_put 函数释放之前创建的 kobject,确保资源被正确回收。
如果不进行错误处理和资源释放,可能会导致严重的后果。例如,在一个循环中不断创建 kobject 和属性文件,但不处理创建失败的情况,也不释放资源,随着时间的推移,系统内存会被逐渐耗尽,最终导致系统崩溃。因此,在编写 sysfs 代码时,必须高度重视错误处理和资源释放,确保代码的健壮性和稳定性。
4.2.3 并发控制与内存安全:数据一致性保障
sysfs 的属性读写操作可能被多个线程、进程同时调用(如多个用户同时读取设备状态、修改配置参数),若未做并发控制,会导致数据竞争(如一个线程写入、一个线程读取,出现脏数据),甚至系统崩溃。因此,必须针对共享数据添加并发控制机制,根据场景选择合适的控制方式。
对于多线程访问的 sysfs 属性,可以使用自旋锁(spinlock)或互斥锁(mutex)来实现并发控制。自旋锁适用于锁的持有时间较短的场景,它通过不断循环等待锁的释放,避免线程上下文切换的开销;而互斥锁则适用于锁的持有时间较长的场景,当一个线程获取不到锁时,它会进入睡眠状态,直到锁被释放。
例如,使用互斥锁来保护一个共享的 sysfs 属性:
static DEFINE_MUTEX(my_mutex);
static ssize_t my_value_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf){
mutex_lock(&my_mutex);
int value = get_shared_value(); // 获取共享值
mutex_unlock(&my_mutex);
return sprintf(buf, "%d\n", value);
}
static ssize_t my_value_store(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t count){
mutex_lock(&my_mutex);
int new_value;
if (kstrtoint(buf, 10, &new_value) != 0) {
mutex_unlock(&my_mutex);
return -EINVAL;
}
set_shared_value(new_value); // 设置共享值
mutex_unlock(&my_mutex);
return count;
}
上述代码中,使用互斥锁(mutex)保护共享值的读写——互斥锁适合锁持有时间较长的场景(如属性读写需执行复杂逻辑),当一个线程持有锁时,其他线程会进入睡眠状态,避免 CPU 空转。需注意,锁的获取与释放必须配对,若在 store 函数中获取锁后,因错误返回未释放锁,会导致死锁(其他线程无法获取锁,一直阻塞)。
对于一些简单的计数场景,可以使用 atomic 变量来实现并发控制。atomic 变量提供了原子操作,能够保证在多线程环境下的操作是原子的,不会被其他线程打断。例如:
static atomic_t my_counter = ATOMIC_INIT(0);
static ssize_t my_counter_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf){
return sprintf(buf, "%d\n", atomic_read(&my_counter));
}
static ssize_t my_counter_store(struct kobject *kobj, struct kobj_attribute *attr, const char *buf, size_t count){
int new_count;
if (kstrtoint(buf, 10, &new_count) != 0) {
return -EINVAL;
}
atomic_set(&my_counter, new_count);
return count;
}
atomic 变量适合简单计数、状态标记等场景,内核提供了一系列原子操作函数(atomic_read、atomic_set、atomic_inc、atomic_dec 等),无需手动加锁,即可保证操作的原子性,避免数据竞争。例如,用 atomic 变量记录设备的读写次数,无需互斥锁,代码更简洁,效率也更高。需注意,atomic 变量仅支持整数操作,复杂数据类型(如字符串、结构体)仍需使用互斥锁或自旋锁。
在实现 show 和 store 函数时,必须严格限制缓冲区的大小,避免缓冲区越界访问。例如,在 show 函数中,需要确保写入缓冲区的数据不会超过缓冲区的大小:
static ssize_t my_value_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf){
int value = get_value();
return snprintf(buf, PAGE_SIZE, "%d\n", value);
}
在上述代码中,使用 snprintf 函数代替 sprintf 函数,snprintf 函数会限制写入缓冲区的字符数,避免缓冲区越界。在 store 函数中,同样需要检查用户输入的数据长度,确保不会超过缓冲区的大小,以保障内存安全。通过合理的并发控制和内存安全措施,可以确保 sysfs 在多线程环境下的稳定运行,保障数据的一致性和完整性。
五、sysfs 开发的常见问题
5.1 调试三板斧:快速定位问题
5.1.1 查看 sysfs 结构:tree 命令直观展示
tree 命令可直观展示 sysfs 目录的层级结构,是验证 kobject 和属性是否创建成功的首选工具。需注意,默认系统可能未安装 tree 命令,需执行 sudo apt install tree(Ubuntu)或 yum install tree(CentOS)安装。除了查看结构,还可结合 ls 命令查看目录下的属性文件,快速定位问题。
例如,当我们在 /sys/kernel 目录下创建了一个名为 my_custom_sysfs 的 kobject,并在其中添加了属性文件时,可以使用以下命令查看其结构:
tree /sys/kernel/my_custom_sysfs
如果一切正常,会看到类似以下的输出:
/sys/kernel/my_custom_sysfs
└── my_attribute
若 tree 命令提示“No such file or directory”,说明 kobject 未创建成功,需检查 kobject_create_and_add() 的返回值处理、parent 指针是否有效;若目录存在但无属性文件,需检查属性创建函数(sysfs_create_file/sysfs_create_group)是否调用成功,以及 kobj_type 是否绑定正确。此外,还可通过 ls -la 查看目录权限,若权限不足,也可能导致属性文件无法正常显示。
5.1.2 检查权限与内核日志:ls -l + dmesg
在 sysfs 开发中,权限设置和内核日志是排查问题的重要线索。通过 ls -l 命令,可以检查属性文件的权限是否符合预期。例如,我们创建了一个属性文件,期望其权限为 0644,即所有者具有读写权限,组和其他用户具有读权限。可以使用以下命令检查权限:
ls -l /sys/kernel/my_custom_sysfs/my_attribute
ls -l 命令的输出格式中,第一位是文件类型(- 表示普通文件,d 表示目录),后续 9 位分为三组(所有者、组、其他用户),每组 r(读)、w(写)、x(执行)三个权限位。例如,-rw-r--r-- 对应 0644 权限,-r--r--r-- 对应 0444 权限,-w------- 对应 0200 权限。若属性文件权限与预期不符,需修改 attribute 结构体的 mode 成员,重新编译模块。
dmesg 命令则用于查看内核日志,内核日志中记录了模块加载、函数调用等关键信息,对于排查问题至关重要。当在加载 sysfs 模块时遇到问题,比如模块加载失败、属性文件创建失败等,可以使用 dmesg 命令查看内核日志,从中寻找线索。例如,当模块加载失败时,dmesg 命令可能会输出类似以下的信息:
[ 123.456] my_sysfs_module: Error creating kobject
这表明在创建 kobject 时出现了错误,可以根据这个提示进一步检查代码,找出问题所在。
pr_debug 宏用于输出调试信息,默认不显示,需开启内核调试模式(启动内核时添加 debug 参数),或通过 echo 8 > /proc/sys/kernel/printk 调整日志级别,才能在 dmesg 中看到。此外,也可使用 pr_info、pr_err 等宏(无需开启调试模式),分别用于输出普通信息、错误信息,方便不同场景下的调试。
#include <linux/printk.h>
#define pr_fmt(fmt) KBUILD_MODNAME ": " fmt
pr_debug("Entering my_function\n");
在上述代码中,使用 pr_debug 宏输出了一条调试信息,表明进入了 my_function 函数。通过 dmesg 命令查看内核日志时,可以看到这条调试信息,从而辅助我们定位代码逻辑中的问题。通过 ls -l 和 dmesg 命令的配合使用,可以有效地排查 sysfs 开发中的权限问题和代码逻辑问题。
5.2 常见坑点与避坑方案
5.2.1 资源未释放:kobject_put 的重要性
忘记调用 kobject_put() 是 sysfs 开发中最常见的内存泄漏原因——尤其是在模块卸载时,若未释放 kobject,会导致 kobject 及其关联的 sysfs 目录、属性文件占用的内存无法回收,多次加载/卸载模块后,内存泄漏会越来越严重,最终导致系统 OOM(内存溢出)。以下是错误示例与修正方案:
my_kobj = kobject_create_and_add("my_custom_sysfs", kernel_kobj);
if (!my_kobj) {
printk(KERN_ERR "Failed to create kobject\n");
return -ENOMEM;
}
// 这里忘记调用kobject_put释放my_kobj
如果在模块卸载时没有调用 kobject_put 释放 my_kobj,那么 my_kobj 所占用的内存将不会被释放,随着模块的多次加载和卸载,会导致内存泄漏,影响系统性能。为了避免这种情况,必须严格遵循 “创建 - 释放” 配对原则,在模块卸载函数中调用 kobject_put 函数释放创建的 kobject。例如:
// 错误示例:未移除属性文件,直接释放kobject
static void __exit my_sysfs_exit(void) {
kobject_put(my_kobj); // 仅释放kobject,属性文件未移除
printk(KERN_INFO "Sysfs module unloaded successfully\n");
}
// 正确示例:先移除属性文件,再释放kobject
static void __exit my_sysfs_exit(void) {
sysfs_remove_file(my_kobj, &my_attribute.attr); // 移除属性文件
kobject_put(my_kobj); // 释放kobject
printk(KERN_INFO "Sysfs module unloaded successfully\n");
}
通过在模块卸载函数中正确调用 kobject_put 函数,可以确保资源被及时释放,避免内存泄漏问题。
5.2.2 权限设置错误:对照规范避免用户态读写失败
权限设置错误是 sysfs 开发中常见的问题之一。如果权限设置不正确,可能会导致用户态无法读写属性文件。例如,将一个需要读写的属性文件权限设置为 0444,即只读权限,那么用户态将无法写入数据。为了避免权限设置错误,需要仔细对照权限配置规范,根据属性的实际需求设置正确的权限。对于只读属性,设置为 0444;对于读写属性,设置为 0644;对于敏感操作属性,设置为 0200。同时,在创建属性文件时,要确保 attribute 结构体中的 mode 字段设置正确。例如:
static struct attribute my_attribute = {
.name = "my_attribute",
.mode = S_IRUGO | S_IWUSR, // 设置为读写权限
};
权限设置错误除了导致读写失败,还可能引发安全风险,这里补充两个常见的权限配置误区及修正方案:1. 误区:所有属性都设为 0644,方便调试;修正:敏感操作属性设为 0200,只读属性设为 0444,遵循最小权限原则。2. 误区:使用 S_IRWXU(0700)权限,开放执行权限;修正:sysfs 属性文件无需执行权限,执行权限无意义,反而增加安全风险。
5.2.3 缓冲区越界:show/store 函数的潜在风险
在实现 show 和 store 函数时,缓冲区越界是一个容易被忽视但又非常危险的问题。如果在 show 函数中向缓冲区写入的数据超过了缓冲区的大小,或者在 store 函数中读取用户输入的数据时超出了缓冲区的容量,就会导致缓冲区越界,可能引发内存错误甚至系统崩溃。例如,在以下 show 函数中:
static ssize_t my_value_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf){
char large_string[1024];
// 假设这里生成一个很长的字符串
for (int i = 0; i < 1024; i++) {
large_string[i] = 'a';
}
strcpy(buf, large_string); // 可能导致缓冲区越界
return strlen(large_string);
}
缓冲区越界是 sysfs 开发中另一个高频坑点,尤其在 show 函数中,若写入的数据长度超过 PAGE_SIZE(默认 4096 字节),会覆盖内核其他内存的数据,导致系统崩溃。除了用 snprintf 替代 sprintf,还需注意以下两点:1. 避免在 buf 中存储超长字符串,若需传输大量数据,改用二进制属性;2. 在 store 函数中,检查用户输入的数据长度,避免超过内核缓冲区大小。
static ssize_t my_value_show(struct kobject *kobj, struct kobj_attribute *attr, char *buf){
char large_string[1024];
// 假设这里生成一个很长的字符串
for (int i = 0; i < 1024; i++) {
large_string[i] = 'a';
}
strcpy(buf, large_string); // 可能导致缓冲区越界
return strlen(large_string);
}
在这个修改后的代码中,snprintf 函数会限制写入 buf 的字符数,确保不会超过 buf 的大小,从而避免了缓冲区越界的风险。在 store 函数中,同样需要检查用户输入的数据长度,确保不会超过缓冲区的大小。通过这些措施,可以有效地避免缓冲区越界问题,提高代码的稳定性和安全性。
通过掌握这些原理、实践与避坑指南,你就能在 Linux内核 的 设备驱动模型 开发中灵活运用 sysfs,构建高效可靠的内核-用户空间通信接口。如果你想与更多开发者交流此类底层技术,欢迎访问云栈社区,这里汇聚了大量热衷于系统编程和内核探索的极客。
 发表于 2026-2-8 05:12:30
|
查看: 185|
回复: 0
发表于 2026-2-8 05:12:30
|
查看: 185|
回复: 0
