在AI辅助创作领域,构建一个高效、自动化的内容生成工作流,可以极大地提升从想法到成品的转化效率。本文将分享一个基于Google生态工具链实现的实战案例,涵盖从自动化文章写作到PPT解说视频生成的全流程,其核心工具包括Google Antigravity IDE、Google AI Studio、深度研究功能以及NotebookLM。
从原子技能到方法论:AI复刻个人工作流
我们大部分的自动化任务都可以通过构建“Skills技能包”或AI编程的方式来完成。这种方法并不要求你具备深厚的编程背景。特别是随着各类AI桌面端工具(如minMax、天工AI、阿里的Qoder、腾讯的CodeWork)的涌现,普通人利用AI提升效率的门槛正在迅速降低。
本文展示的工作流核心思路在于分层:梳理并定义清晰的原子技能,再基于此组合成上层的方法论技能。这样一来,AI首先能够复刻你已有的能力,进而面对复杂场景时,具备基于原子技能进行自我组装与进化的潜力。这一思路与当前火热的AI智能体(如OpenClaw)的核心逻辑是相通的。
实战一:自动化输出图文并茂的文章
以一篇题为《意识的本质》的文章为例,它完全通过一个自动化Skills工作流生成。该工作流可分为三个关键步骤:
- 数据采集:根据指定的主题与关键词,从互联网爬取相关文章并存储到本地。
- 内容归纳与创作:基于预设的写作要点和提纲,调用AI工具对采集的内容进行重新归纳与输出。
- 智能配图:调用Google相关的图像生成API(如Nano Banala),为文章自动生成配图。
在这个流程中,用户只需提供写作思路、目标网站和关键词,其余的数据采集、内容整合与配图任务均由AI自动执行。Skills技能包内不仅包含提示词和模板,更重要的是集成了执行具体任务(如网络请求、图像生成调用)的源代码片段。
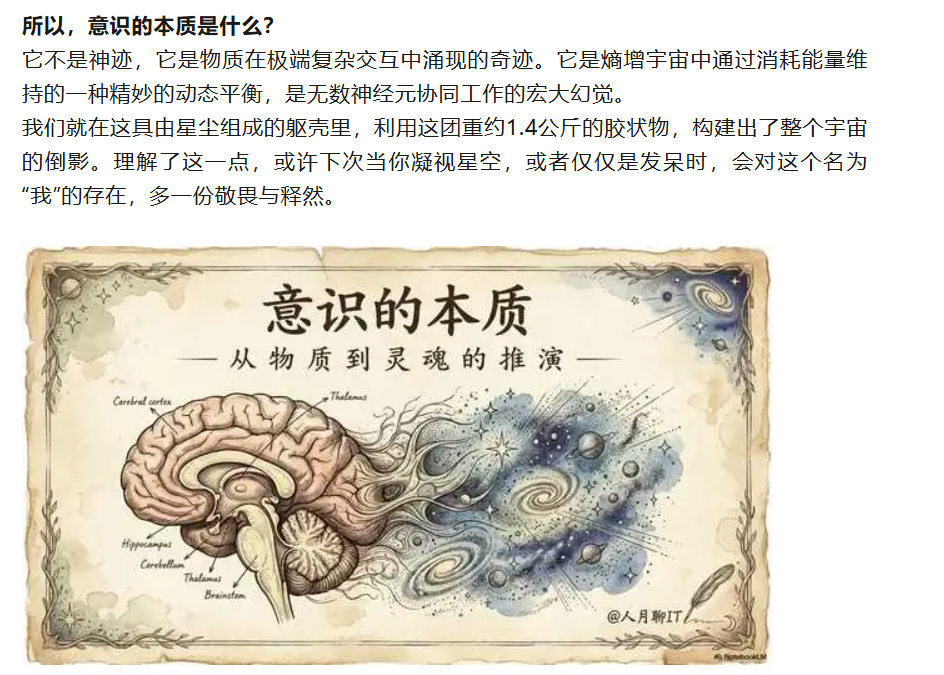
这种方法虽然不一定适用于每一篇个人化写作,但它成功验证了“原子技能+方法论技能”分层的可行性。对于个人AI辅助而言,关键在于系统地梳理自身的原子技能。
实战二:自动化生成PPT解说视频
第二个案例是生成《中国古代木质建筑框架研究》的解说视频。整个过程展示了如何将深度研究转化为多媒体内容。
第一步:生成深度研究报告
首先,利用Google的深度研究功能,输入详细的研究指令(例如,要求涵盖应县木塔、佛光寺、故宫太和殿等代表性建筑,并重点参考梁思成的《中国建筑史》),生成一篇约8000-10000字的深度研究报告。
第二步:分解报告为PPT与脚本
接着,指令Gemini基于这份报告:
- 生成一份35页PPT的绘制提示词。
- 输出与这35页内容逐页对应的语音播客讲解逐字稿。
第三步:整合内容生成视频
此时,我们得到了两个核心文件:PPT(PDF格式)和配套的逐字稿。接下来的目标是将它们合成为一个解说视频。通过Google AI Studio,我们可以用简单的提示词快速构建一个实现该功能的应用。
提示词示例:
我会提供两个文件给你,一个是有35页ppt的pdf文件,一个是按这个ppt顺序的语音播客文案,你是否可以基于这两个文件帮我生成一个完整的视频,视频就是讲解ppt的内容,同时讲解到某页的时候就显示该页的图片?
基于这个指令,AI生成了一个可交互的应用程序界面。
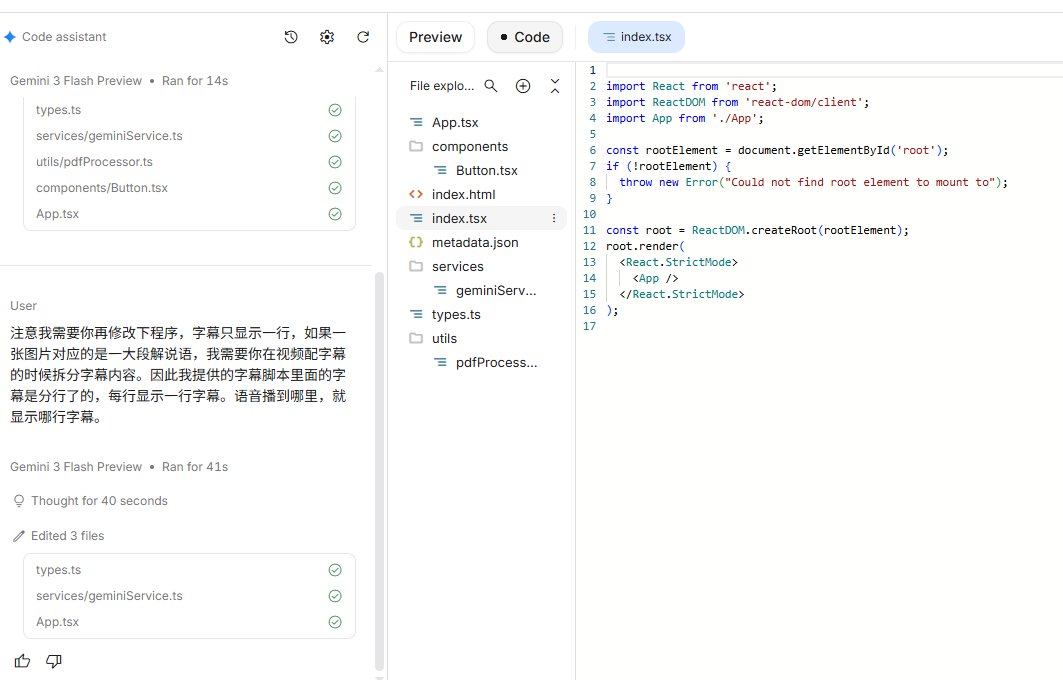
在这个界面中,用户只需上传PPT的PDF文件和对应的逐行解说文案,选择语音风格,即可启动视频合成流程。
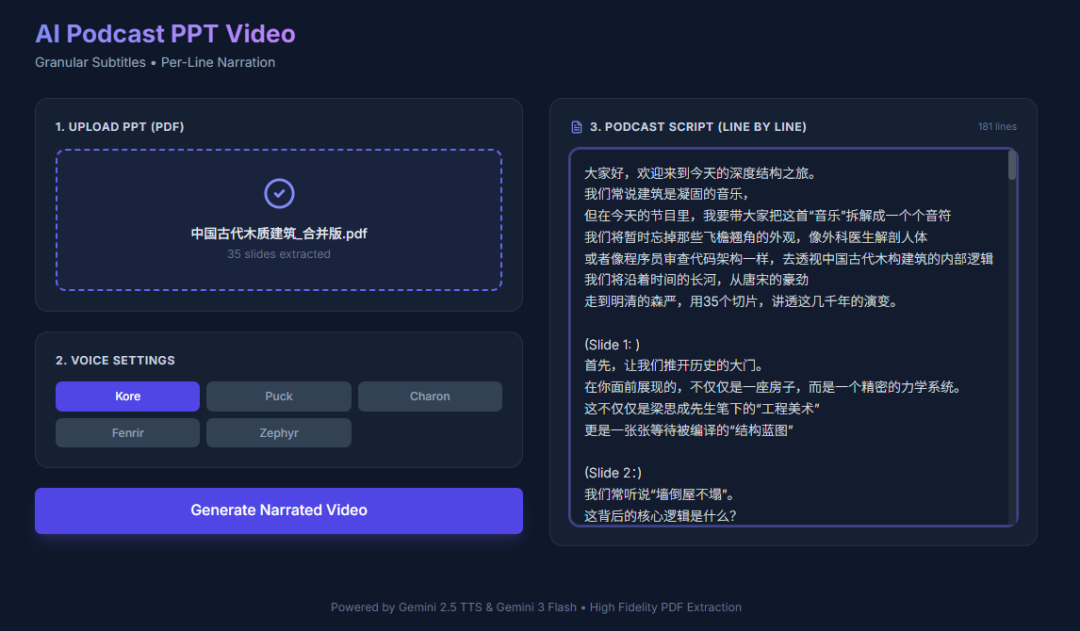
应用会逐行为文案生成音频,并最终合成带字幕和PPT画面的视频。
第四步:优化与本地化部署
由于直接调用云端API可能存在次数限制或成本考虑,可以进一步将应用源码下载到本地。借助AI辅助编程,能够轻松替换其中的TTS服务提供商,例如将Google TTS API替换为其他大模型(如GLM)的语音合成服务,从而实现更灵活、可控的部署。

总结与展望
尽管目前尚未实现从单一主题指令到最终视频的完全“一键自动化”,但上述流程清晰地证明了其技术可行性。这个案例为我们提供了一个可复现的自动化内容生产思路:
深度研究 → 结构化报告 → 分解为PPT与脚本 → 通过定制化应用合成视频。
整个工作流充分展现了现代AI工具如何将复杂的创作任务拆解、串联并自动化执行。对于开发者或内容创作者而言,在云栈社区这样的平台交流类似的技术实践,能够加速探索更高效、更智能的创作方法论。关键在于主动定义你的“原子技能”,并设计将它们串联起来的“方法论”,剩下的,可以交给AI来辅助实现。
 发表于 2026-2-9 03:44:30
|
查看: 194|
回复: 0
发表于 2026-2-9 03:44:30
|
查看: 194|
回复: 0
