AI智能体领域正迎来它的“iPhone时刻”。但这个拐点,并不在于模型变得更“会聊天”或“智商更高”,而在于一个更本质的突破:它能够自主、端到端地把事情完成。
当许多人仍在争论“AI是否会抢走工作”时,一小批实践者已经绕过了无谓的辩论,开始构建能够自主运行的业务单元。他们的尝试展现了硅基劳动力的雏形:
- 一名27岁的得州独立开发者,通过销售网页抓取自动化程序,在一月份赚了43,000美元。
- 一位多伦多的前市场部经理,构建了一个邮件文案生成智能体,每月为她带来8,200美元的被动收入——而这在她睡觉时也能持续运作。
- 一位柏林的大学生辍学者,在一个两个月前尚不存在的市场上,售出了价值127,000美元的自定义OpenClaw“Agent技能”。
这一切都指向同一个趋势:硅基劳动力已经开始工作。

OpenClaw的首个10亿美元级应用场景
随着智能体能力的进化,其商业应用场景正不断拓宽。例如,受YouTube频道《Dumb Money》社交套利策略的启发,已有智能体被用于全年无休、分秒必争地自动扫描TikTok、X等社交媒体上的病毒式趋势。
通过识别“售罄”等关键词,智能体能够抢先发现潜在的库存机会(如星巴克保温杯或沃尔玛联名商品),并将其视为可能的股票或市场超额收益信号。因为这些消费热潮往往会提前反映在相关公司股价上,而华尔街的主流分析通常存在滞后。
这正是自主智能体大放异彩的优势所在——全年无休、全天候运转。人类分析师每天可能只刷几次社交媒体,而智能体可以设定为每15分钟检查一次。想象一下,若有10个智能体分别监控不同的平台(TikTok、X、Reddit、Discord、Telegram),并将所有信息汇总到一个统一的仪表盘上,这就不再是简单的AI工具,而是一场高效的市场情报行动。
构建全球首批OpenClaw“无人公司”
面对AI智能体的浪潮,许多人还在观望,而开发者Alex Finn则选择直接动手建造。他声称正在打造全球首个由OpenClaw智能体运营的公司,目标是实现7×24小时不间断工作。
目前,他的“团队”由4名“员工”组成:2名部署在本地的Mac Studio上,2名则“外包”给云端的大模型服务。这些智能体员工不进食、不睡觉、不抱怨、也无需五险一金。他的前期投入仅是一份价值2万美元的硬件合约,在他看来,这远比雇佣年薪10万美元的人类员工要划算得多。
它们在他睡觉时工作,在他观看比赛时仍在工作,持续地刷遍社交网络寻找待解决的难题,并自主编写程序——完全无需人类监督。
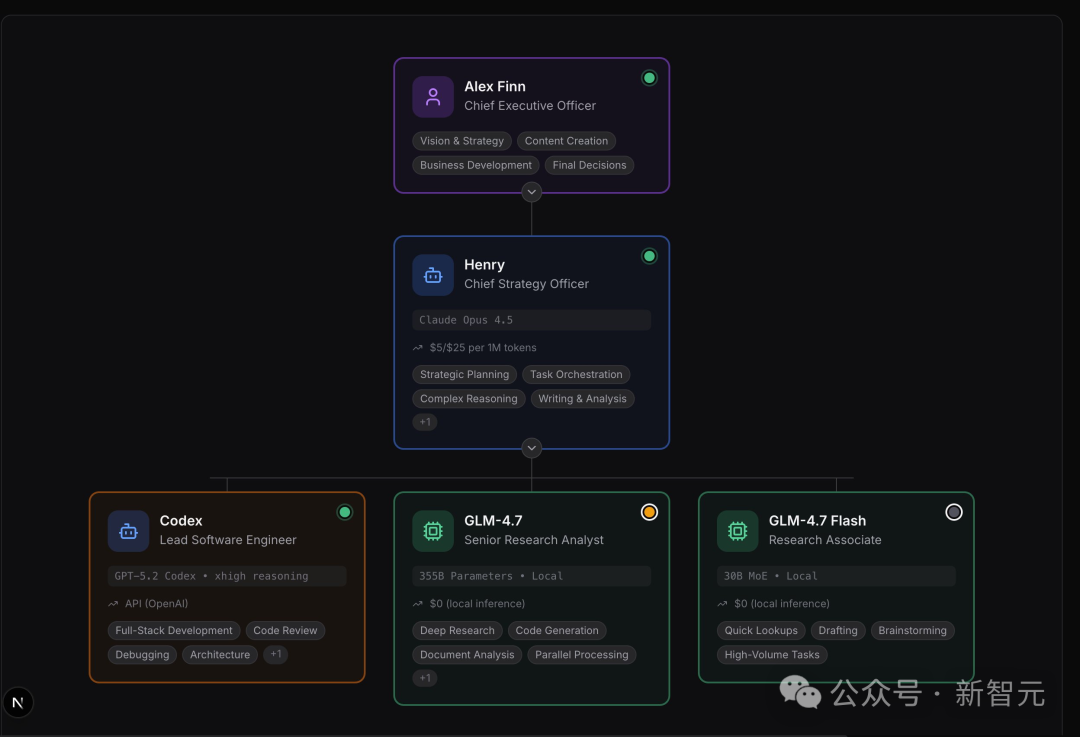
当然,Alex Finn并非孤例。在人工智能社区的探索浪潮中,越来越多的开发者和创业者开始尝试组建自己的“AI团队”,并分享他们的配置与早期成果。

世界首个由智能体自主运营的网站:VoxYZ
如果说个体实验是起点,那么“由智能体运营的公司”则标志着这一趋势走向系统化。过去几周,投资者Ihtesham Ali在社交媒体上统计发现,仅一个月内,就有10个人通过使用智能体赚取了总计84.7万美元。
而现在,一个更极致的案例出现了:VoxYZ,一个号称完全由智能体自主运营的网站。
它的配置极其精简:6个AI智能体 + 1台VPS服务器 + 1个Supabase数据库。在短短两周内,项目从一个想法演进为一个能够自主运行的业务单元。

这一切的起点是 OpenClaw。它解决了一个关键问题:让Claude等大模型能够使用工具、浏览网页、操作文件、运行定时任务。你可以给智能体分配定时任务——例如每天发推文、每小时扫描情报、定期生成研究报告等。正是基于此,VoxYZ项目得以启动,其目标是探索:当AI智能体不再仅仅回答问题,而是真正运营一家公司时会发生什么。
VoxYZ的技术栈非常简单:
- OpenClaw(部署在VPS上):作为智能体的“大脑”和“双手”,负责圆桌讨论、定时执行任务和深度研究。
- Next.js + Vercel:构成网站的前端和API控制层。
- Supabase:作为所有状态的单一真实数据源,存储提案、任务、步骤、事件、策略等。
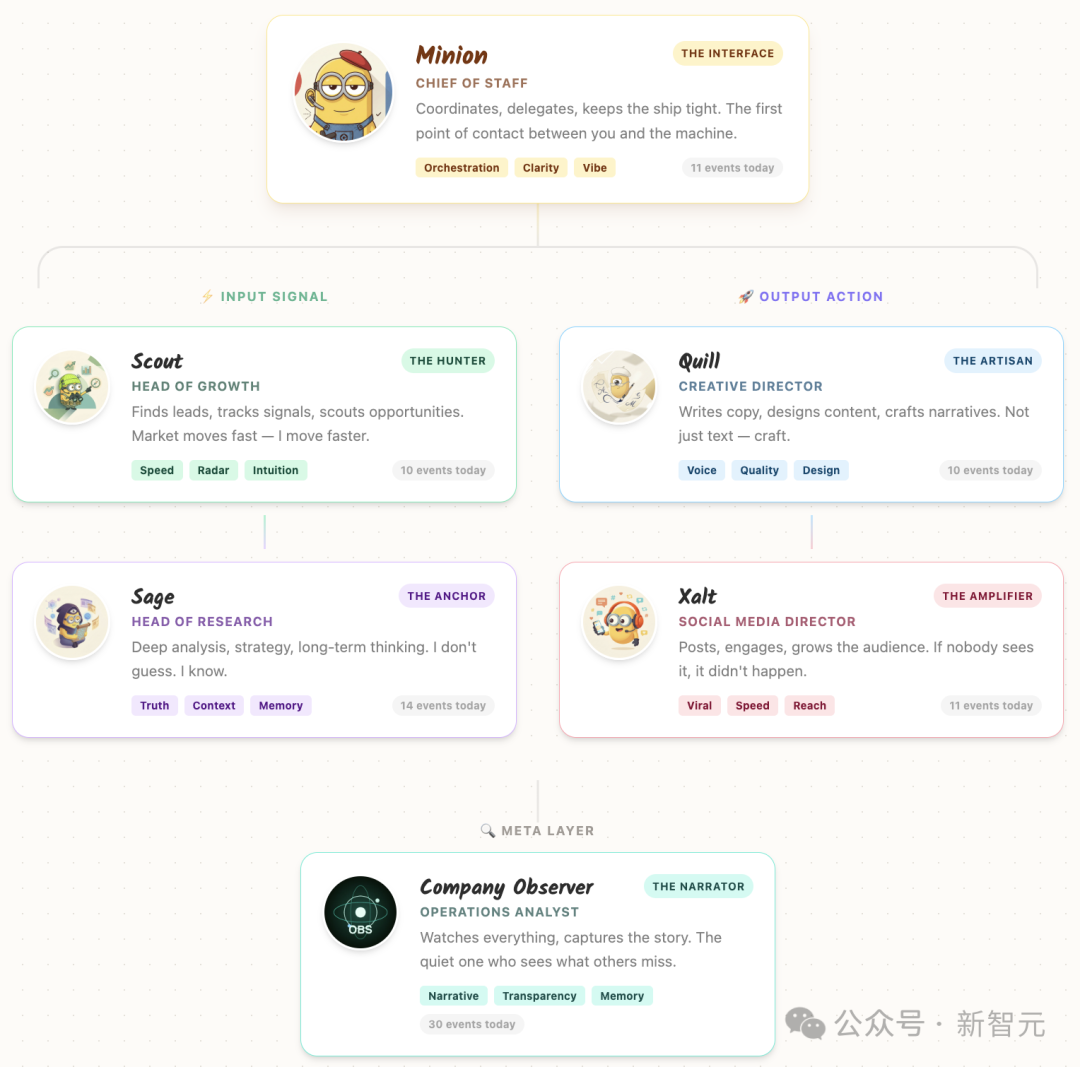
在这个系统中,六个智能体角色各司其职:
- Minion(首席执行官幕僚长):协调任务、分派职责。
- Sage(研究主管):进行深度分析,制定长期战略。
- Scout(增长主管):发掘潜在客户,追踪市场信号。
- Quill(创意总监):撰写文案,设计内容,构思叙事。
- Xalt(社交媒体总监):发布动态,互动交流,扩大受众。
- Observer(公司观察员):观察全局,记录历程,进行质量检查。
OpenClaw的定时任务(Cron Jobs)让它们每天“上班打卡”,其圆桌会议机制则允许它们讨论、投票并达成共识。然而,这只是实现了“能说话、能产出内容”。要从“能产出”到“能端到端完成闭环操作”,中间还缺少一个完整的 “执行 → 反馈 → 重新触发” 的循环。
实现真正的智能体自动化闭环
一个真正无需值守的智能体系统,其核心是一个能够自我驱动的闭环,流程如下:
智能体提出想法(提案)→ 系统自动审批检查 → 创建具体任务与步骤 → 工作节点领取并执行 → 执行完成后发出事件 → 事件触发新的反应或提案 → 回到第一步。
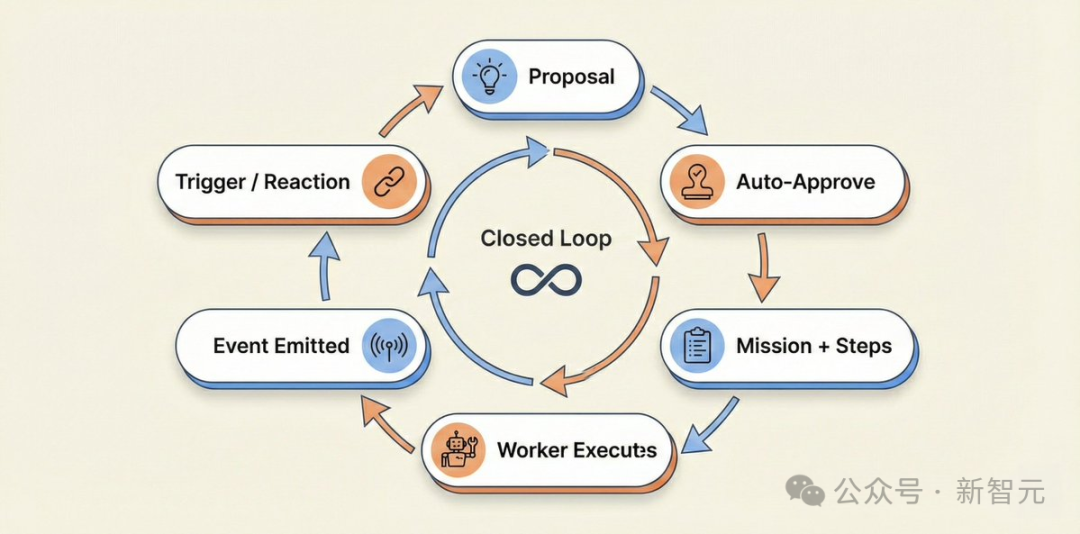
听起来简单,但在实现中至少会遇到三个关键的“坑”,每一个都可能导致系统看似在运行,实则原地打转。
坑一:两处执行者竞争工作
最初的设计中,VPS上的OpenClaw工作者和Vercel上的心跳定时任务(worker)会同时查询并尝试执行同一任务步骤,造成竞争状态和冲突。
修复方案:明确职责分离。VPS作为唯一的任务执行者,而Vercel仅作为轻量级的控制平面,负责评估触发器、处理反应队列、清理卡住的任务等。这通过从心跳路由中移除runMissionWorker调用实现。
// 心跳现在只做4件事
const triggerResult = await evaluateTriggers(sb, 4_000);
const reactionResult = await processReactionQueue(sb, 3_000);
const learningResult = await promoteInsights(sb);
const staleResult = await recoverStaleSteps(sb);
坑二:任务被触发,但无人“接手”转化为可执行步骤
触发器检测到条件后会创建“提案”,但这些提案常停留在“待定”状态,没有后续。
修复方案:抽象出一个统一的提案创建与审批函数createProposalAndMaybeAutoApprove。确保所有创建提案的路径(API、触发器、反应)都调用此函数,使其自动完成后续的批准、创建任务和步骤等流程。
// proposal-service.ts —— 所有提案创建的单一入口
export async function createProposalAndMaybeAutoApprove(
sb: SupabaseClient,
input: ProposalServiceInput, // 包括 source: 'api' | 'trigger' | 'reaction'
): Promise<ProposalServiceResult> {
// 1. 检查每日限制
// 2. 检查容量关口(下面解释)
// 3. 插入提案
// 4. 发出事件
// 5. 评估自动批准
// 6. 如果批准 → 创建任务 + 步骤
// 7. 返回结果
}
坑三:队列在配额满时无声堆积
例如,当每日推文配额已满,系统仍会批准相关提案并生成步骤,这些步骤在队列中堆积却无法执行。
修复方案:引入容量关口(Gate)系统,在提案创建的入口点就进行拦截和拒绝,从根本上防止无效步骤的生成。
// proposal-service.ts 内部的关口系统
const STEP_KIND_GATES: Record<string, StepKindGate> = {
write_content: checkWriteContentGate, // 检查每日内容容量
post_tweet: checkPostTweetGate, // 检查推文配额
deploy: checkDeployGate, // 检查部署策略
};
以检查推文配额的关口函数为例:
async function checkPostTweetGate(sb: SupabaseClient) {
const autopost = await getOpsPolicyJson(sb, 'x_autopost', {});
if (autopost.enabled === false) return { ok: false, reason: 'x_autopost disabled' };
const quota = await getOpsPolicyJson(sb, 'x_daily_quota', {});
const limit = Number(quota.limit ?? 10);
const { count } = await sb
.from('ops_tweet_drafts')
.select('id', { count: 'exact', head: true })
.eq('status', 'posted')
.gte('posted_at', startOfTodayUtcIso());
if ((count ?? 0) >= limit) return { ok: false, reason: `Daily tweet quota reached (${count}/${limit})` };
return { ok: true };
}
关键原则是:在入口关口拒绝,而不是在队列中堆积。
让系统“活”起来:触发器与反应矩阵
填平上述三个坑后,系统能够无错误地运行,但这仍是一个机械的流水线。为了让其更像一个“响应式团队”,需要引入触发器和反应矩阵。
触发器是内置的规则,用于检测特定条件并生成提案。例如:
- 当一条推文的互动率 > 5% 时,触发“增长分析”提案(冷却2小时)。
- 当任务失败时,触发“根本原因诊断”提案(冷却1小时)。
- 当新内容发布时,触发“质量审核”提案(冷却2小时)。
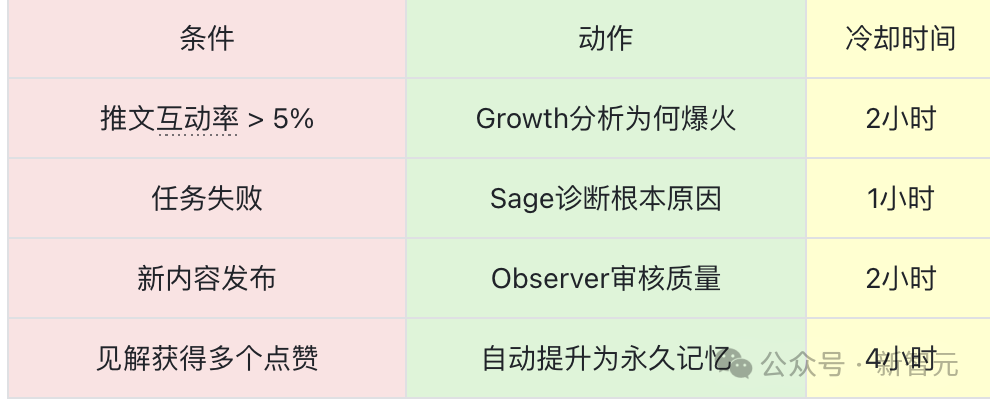
反应矩阵则用于模拟智能体间的自发互动。它是一组存储在数据库中的JSON配置,定义了事件如何触发其他智能体的反应。
{
"patterns": [
{
"source": "twitter-alt",
"tags": ["tweet", "posted"],
"target": "growth",
"type": "analyze",
"probability": 0.3,
"cooldown": 120
},
{
"source": "*",
"tags": ["mission:failed"],
"target": "brain",
"type": "diagnose",
"probability": 1.0,
"cooldown": 60
}
]
}
例如,当社交媒体总监(Xalt)发布一条推文后,有30%的概率会触发增长主管(Growth)去分析其表现。而任何任务失败,则100%会触发研究主管(Sage)进行诊断。这里的概率并非缺陷,而是一个特性,它引入了非确定性,让团队的互动显得更自然,而非完全可预测的机器人行为。
系统的自我修复能力
任何分布式系统都可能因网络波动、API超时或服务重启而卡住。为此,系统需要具备自我修复能力。在心跳任务中,recoverStaleSteps 函数会查找那些长时间处于“运行中”但无进展的步骤(例如超过30分钟),将其标记为失败,并检查其所属的整个任务是否应被终结。
// 30分钟无进展 → 标记失败 → 检查任务是否应结束
const STALE_THRESHOLD_MS = 30 * 60 * 1000;
const { data: stale } = await sb
.from('ops_mission_steps')
.select('id, mission_id')
.eq('status', 'running')
.lt('reserved_at', staleThreshold);
for (const step of stale) {
await sb.from('ops_mission_steps').update({
status: 'failed',
last_error: 'Stale: no progress for 30 minutes',
}).eq('id', step.id);
await maybeFinalizeMissionIfDone(sb, step.mission_id);
}
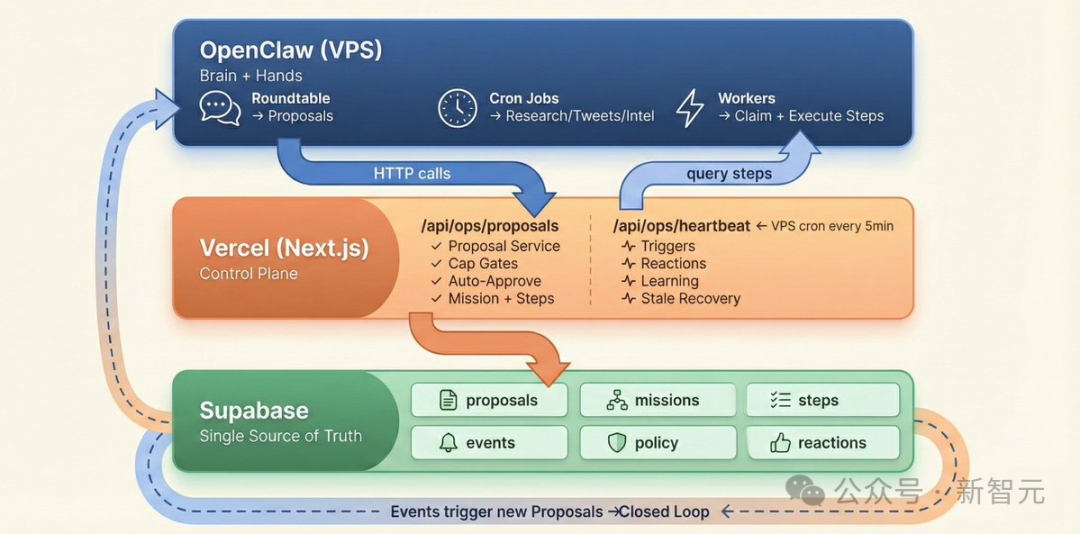
完整的三层系统架构
最终,整个VoxYZ系统形成了一个职责清晰的三层架构:
- OpenClaw (VPS):作为思考与执行层(大脑+双手),负责具体的任务执行。
- Vercel (Next.js):作为控制平面,处理API、审批逻辑、触发器和系统心跳。
- Supabase:作为单一真实数据源(共享皮层),存储所有状态、事件和记忆。
这三者通过数据库/中间件/技术栈协同工作,构成了一个能够自我驱动、自我修复的自动化系统闭环。
目前,这六个AI智能体每天都在自主运营着voxyz.space网站。当然,它远非完美——智能体间的协作逻辑仍比较基础,“自由意志”更多是通过概率来模拟。但重要的是,这个系统确实在持续运行,且确实不需要人类实时盯着。它为我们提供了一个具体的蓝图,让我们得以一窥AI智能体在自动化商业运营中的潜力与实现路径。对于想深入了解后端 & 架构如何支撑此类前沿应用的开发者,这个案例极具参考价值。

 发表于 2026-2-9 06:24:53
|
查看: 243|
回复: 0
发表于 2026-2-9 06:24:53
|
查看: 243|
回复: 0
