在深入ARIMA模型之前,让我们先理解时间序列数据的两个核心特征。
想象一下股票价格的走势。如果一只股票连续三天上涨,那第四天继续上涨的概率是不是会大一些?这就是惯性(Momentum)。股价有一种“记忆效应”,过去的走势会影响未来的表现。
但市场上还有另一种力量——冲击(Shock)。比如突然爆出的利好消息、重大政策变动,这些外部事件会给价格带来瞬间的冲击。这种冲击的影响会逐渐衰减,但在短期内会显著改变走势。
💡 核心洞察:
传统的移动平均(MA)模型只关注“冲击”——它把当前值看作是一系列外部冲击的累积效应。但这样做有个问题:它忽略了市场的“惯性”。这就是为什么我们需要自回归(AR)模型。
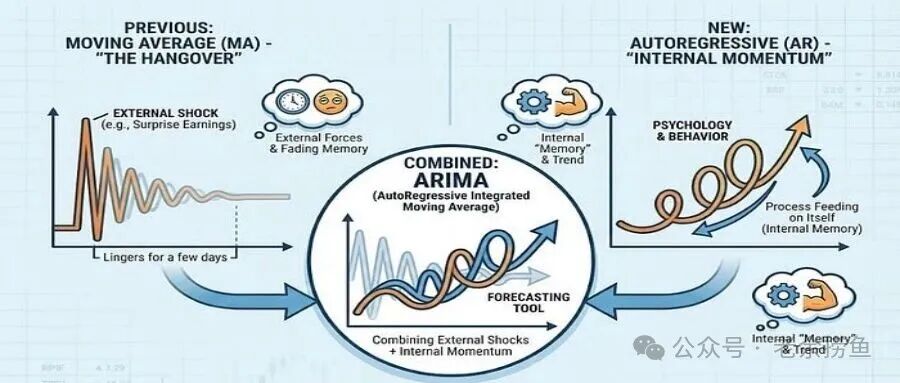
二、自回归模型(AR):捕捉市场的“记忆”
2.1 什么是自回归?
自回归的核心思想很简单:今天的价格,是昨天价格的延续。
今天的值 = 常数项 + 系数1 × 昨天的值 + 系数2 × 前天的值 + ... + 随机误差
这就是AR(p)模型,其中p表示我们要回溯多少天的历史数据。
2.2 AR模型:最简单的情况
让我们看最简单的AR(1)模型:
Y_t = φ₀ + φ₁ × Y_{t-1} + ε_t
其中:
Y_t 是今天的值φ₀ 是常数项(可以理解为基准线)φ₁ 是自回归系数(决定了“记忆”的强度)ε_t 是随机误差(白噪声)
2.3 关键参数φ₁的含义
| φ₁的值 |
含义 |
市场表现 |
| φ₁ = 0 |
完全没有记忆 |
纯随机游走,今天和昨天无关 |
| 0 < φ₁ < 1 |
正向记忆,但会衰减 |
涨了会继续涨,但力度逐渐减弱 |
| φ₁ = 1 |
完全记忆 |
随机游走,趋势会一直延续 |
| φ₁ > 1 |
记忆放大 |
爆炸式增长,不稳定 |
| φ₁ < 0 |
负向记忆 |
涨跌交替,震荡模式 |
⚠️ 平稳性条件:
要让AR(1)模型稳定可用,必须满足 |φ₁| < 1。如果φ₁ = 1,序列就变成了随机游走,无法预测;如果φ₁ > 1,序列会爆炸式增长,完全失控。
2.4 如何识别AR模型?
在实际应用中,我们通过两个工具来判断是否适合用AR模型:
1. 自相关函数(ACF)图
- ACF衡量的是当前值与过去各期值的相关性。
- 对于AR模型,ACF会呈现缓慢衰减的特征(拖尾)。
2. 偏自相关函数(PACF)图
- PACF衡量的是剔除中间影响后,当前值与过去某期值的直接相关性。
- 对于AR(p)模型,PACF会在第p阶后突然截断(截尾)。
| 模型类型 |
ACF特征 |
PACF特征 |
| AR(p) |
拖尾(缓慢衰减) |
p阶截尾 |
| MA(q) |
q阶截尾 |
拖尾(缓慢衰减) |
| ARMA(p,q) |
拖尾 |
拖尾 |
三、ARMA模型:惯性与冲击的完美结合
单纯的AR模型只考虑了“惯性”,单纯的MA模型只考虑了“冲击”。那能不能把两者结合起来呢?
当然可以!这就是ARMA模型。
3.1 ARMA模型的数学表达
Y_t = φ₀ + φ₁Y_{t-1} + ... + φ_pY_{t-p} + ε_t + θ₁ε_{t-1} + ... + θ_qε_{t-q}
简单来说:
- 前半部分(φ项)是AR部分,捕捉“惯性”。
- 后半部分(θ项)是MA部分,捕捉“冲击”。
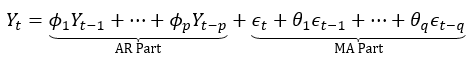
3.2 为什么需要ARMA?
在真实的金融市场中,价格走势既受历史价格影响(惯性),也受突发事件影响(冲击),单一模型往往无法完整描述这种复杂性。
✅ ARMA模型的优势:
- 更灵活:可以同时捕捉两种模式。
- 更精确:减少了单一模型的系统性偏差。
- 更稳健:在不同市场环境下都有较好表现。
四、ARIMA模型:处理非平稳数据的利器
4.1 什么是平稳性?
在时间序列分析中,平稳性是一个核心概念。一个平稳的时间序列需要满足:
- 均值恒定:不随时间变化。
- 方差恒定:波动幅度稳定。
- 自协方差恒定:不同时期之间的相关性只与时间间隔有关。
但现实中的金融数据,比如股价、GDP、销售额,往往都是非平稳的——它们有明显的上升或下降趋势。
4.2 差分:让数据变平稳的魔法
ARIMA中的“I”代表Integrated(差分整合)。差分是一种简单但有效的方法,可以把非平稳序列转化为平稳序列。
一阶差分:
ΔY_t = Y_t - Y_{t-1}
这相当于计算每天的涨跌幅,而不是看绝对价格。
二阶差分:
Δ²Y_t = ΔY_t - ΔY_{t-1}
这相当于计算涨跌幅的变化率。
💡 金融应用技巧:
在金融领域,我们常用的对数收益率其实就是一种差分:
Log_Return_t = log(P_t) - log(P_{t-1}) = log(P_t / P_{t-1})
4.3 ARIMA(p,d,q)模型
ARIMA模型有三个核心参数:
- p:自回归阶数(AR部分,看多少天的历史)。
- d:差分次数(让数据变平稳)。
- q:移动平均阶数(MA部分,看多少期的冲击)。
⚠️ 参数选择的一般规律:
- d通常取0、1或2,很少超过2。
- p和q通常在0-3之间。
- 参数越大,模型越复杂,但不一定越好。
五、Box-Jenkins方法论:构建ARIMA模型的标准流程
Box和Jenkins提出了一套系统的建模流程,这套方法论至今仍是时间序列分析的金标准。
5.1 第一步:识别 (Identification)
5.1.1 平稳性检验
最常用的是ADF检验 (Augmented Dickey-Fuller Test):
- 原假设H₀:序列非平稳(存在单位根)。
- 备择假设H₁:序列平稳。
- 如果p值 < 0.05:拒绝原假设,认为序列平稳。
5.1.2 确定差分次数d
观察ACF图:
- 如果ACF在10阶以上都显著,说明需要差分;
- 如果ACF在1阶就截尾,说明差分过度了;
- 最佳状态是ACF先拖尾几阶,然后截尾。
5.1.3 确定p和q
通过ACF和PACF图来判断:
- PACF在p阶截尾 → AR(p)模型;
- ACF在q阶截尾 → MA(q)模型;
- 两者都拖尾 → ARMA(p,q)模型。
5.2 第二步:估计与选择 (Estimation & Selection)
5.2.1 参数估计
使用最大似然估计(MLE)方法来计算模型参数。这个过程通常由软件自动完成。
5.2.2 模型选择
当有多个候选模型时,如何选择最优模型?主要看两个指标:
AIC(赤池信息准则):
AIC = -2×log(似然函数) + 2×参数个数
BIC(贝叶斯信息准则):
BIC = -2×log(似然函数) + log(样本量)×参数个数
💡 选择原则:
- AIC和BIC越小越好;
- BIC对复杂模型的惩罚更严格;
- 遵循简约原则:在效果相近的情况下,选择参数更少的模型。
5.3 第三步:诊断检验 (Diagnostic Checking)
模型建好后,还要检验是否真的可靠。
5.3.1 残差分析
好的模型,残差应该是白噪声(完全随机,无规律):
5.3.2 Ljung-Box检验
这是检验残差是否为白噪声的统计检验:
- 原假设H₀:残差序列各期之间相互独立(是白噪声);
- 如果p值 > 0.05,说明模型拟合良好。
六、Python实战:手把手教你构建ARIMA模型
理论讲完了,现在进入实战环节。我会用Google股票数据作为案例,带你一步步构建ARIMA模型。
6.1 环境准备与数据加载
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.stats.diagnostic import acorr_ljungbox
import warnings
# 设置中文显示和样式
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
sns.set(style="whitegrid")
warnings.filterwarnings("ignore")
# 加载数据
df = pd.read_csv('google_stock.csv')
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
# 查看数据
print(df.head())
print(f"数据形状: {df.shape}")
6.2 数据预处理:计算对数收益率
在金融领域,我们通常不直接对价格建模,而是对对数收益率建模。原因有两个:
- 对数收益率更接近平稳序列;
- 对数收益率具有可加性,便于计算累积收益。
# 计算对数收益率(相当于一阶差分)
df['Log_Return'] = np.log(df['Close']).diff().dropna()
# 可视化
fig, axes = plt.subplots(2, 1, figsize=(14, 8))
# 原始价格
axes[0].plot(df.index, df['Close'], color='blue', linewidth=1.5)
axes[0].set_title('Google股票收盘价', fontsize=14, fontweight='bold')
axes[0].set_ylabel('价格($)', fontsize=12)
axes[0].grid(True, alpha=0.3)
# 对数收益率
axes[1].plot(df.index, df['Log_Return'], color='green', linewidth=1)
axes[1].set_title('Google股票对数收益率', fontsize=14, fontweight='bold')
axes[1].set_ylabel('收益率', fontsize=12)
axes[1].axhline(y=0, color='red', linestyle='--', alpha=0.5)
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
6.3 平稳性检验:ADF检验
def adf_test(series, name=''):
"""
执行ADF检验并输出结果
"""
result = adfuller(series.dropna())
print(f'\n=== {name} 的ADF检验结果 ===')
print(f'ADF统计量: {result[0]:.6f}')
print(f'p值: {result[1]:.6f}')
print(f'使用的滞后阶数: {result[2]}')
print(f'观测值数量: {result[3]}')
print('临界值:')
for key, value in result[4].items():
print(f' {key}: {value:.3f}')
# 判断结果
if result[1] < 0.05:
print(f'\n结论: p值 < 0.05,拒绝原假设,序列是平稳的 ✓')
else:
print(f'\n结论: p值 >= 0.05,无法拒绝原假设,序列非平稳 ✗')
return result
# 对对数收益率进行ADF检验
adf_result = adf_test(df['Log_Return'], 'Google对数收益率')
6.4 ACF和PACF分析:确定p和q
# 绘制ACF和PACF图
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(14, 10))
# ACF图
plot_acf(df['Log_Return'].dropna(), lags=30, ax=ax1,
title='自相关函数(ACF) - Google对数收益率')
ax1.set_xlabel('滞后阶数', fontsize=12)
ax1.set_ylabel('相关系数', fontsize=12)
# PACF图
plot_pacf(df['Log_Return'].dropna(), lags=30, ax=ax2,
title='偏自相关函数(PACF) - Google对数收益率')
ax2.set_xlabel('滞后阶数', fontsize=12)
ax2.set_ylabel('相关系数', fontsize=12)
plt.tight_layout()
plt.show()
💡 如何解读ACF和PACF图?
观察图中的蓝色阴影区域(置信区间):
- 如果柱子超出阴影区域,说明该阶数显著;
- ACF在某阶后都在阴影内 → 该阶截尾;
- ACF缓慢衰减 → 拖尾。
6.5 网格搜索:寻找最优参数
与其手动判断p和q,不如让程序自动搜索所有可能的组合,找出AIC最小的模型。
# 定义参数范围
p_values = range(0, 3) # AR阶数
d_values = [0] # 对数收益率已经是差分后的,所以d=0
q_values = range(0, 3) # MA阶数
best_aic = float("inf")
best_order = None
best_model = None
print("开始网格搜索,寻找最优ARIMA模型...\n")
print("模型\t\tAIC值")
print("-" * 40)
# 遍历所有参数组合
for p in p_values:
for d in d_values:
for q in q_values:
try:
# 拟合模型
model = ARIMA(df['Log_Return'].dropna(), order=(p, d, q))
results = model.fit()
# 输出结果
print(f"ARIMA({p},{d},{q})\t{results.aic:.2f}")
# 更新最优模型
if results.aic < best_aic:
best_aic = results.aic
best_order = (p, d, q)
best_model = results
except:
continue
print("\n" + "=" * 40)
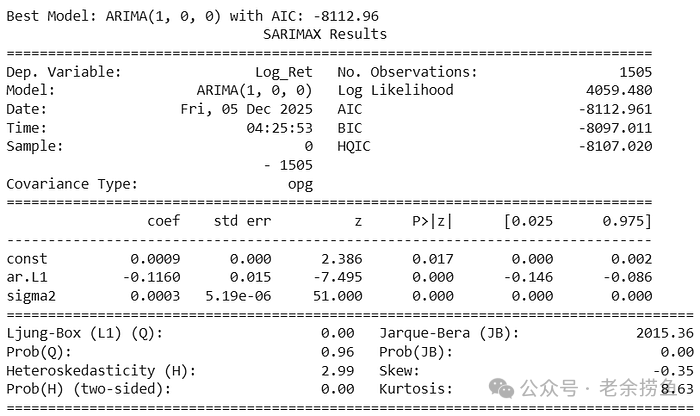
print(f"最优模型: ARIMA{best_order}")
print(f"最小AIC值: {best_aic:.2f}")
print("=" * 40)
# 输出最优模型的详细信息
print("\n最优模型摘要:")
print(best_model.summary())
6.6 模型诊断:残差检验
# 提取残差
residuals = best_model.resid
# 1. 残差可视化
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 残差时序图
axes[0, 0].plot(residuals, color='blue', linewidth=1)
axes[0, 0].axhline(y=0, color='red', linestyle='--')
axes[0, 0].set_title('残差时序图', fontsize=12, fontweight='bold')
axes[0, 0].set_ylabel('残差', fontsize=10)
# 残差直方图
axes[0, 1].hist(residuals, bins=30, color='green', alpha=0.7, edgecolor='black')
axes[0, 1].set_title('残差分布直方图', fontsize=12, fontweight='bold')
axes[0, 1].set_xlabel('残差值', fontsize=10)
axes[0, 1].set_ylabel('频数', fontsize=10)
# 残差ACF图
plot_acf(residuals, lags=20, ax=axes[1, 0])
axes[1, 0].set_title('残差ACF图', fontsize=12, fontweight='bold')
# 残差Q-Q图
from scipy import stats
stats.probplot(residuals, dist="norm", plot=axes[1, 1])
axes[1, 1].set_title('残差Q-Q图', fontsize=12, fontweight='bold')
plt.tight_layout()
plt.show()
# 2. Ljung-Box检验
lb_test = acorr_ljungbox(residuals, lags=[10], return_df=True)
print("\n=== Ljung-Box检验结果 ===")
print(lb_test)
print("\n解读:")
if lb_test['lb_pvalue'].values[0] > 0.05:
print("p值 > 0.05,残差为白噪声,模型拟合良好 ✓")
else:
print("p值 <= 0.05,残差存在自相关,模型需要改进 ✗")
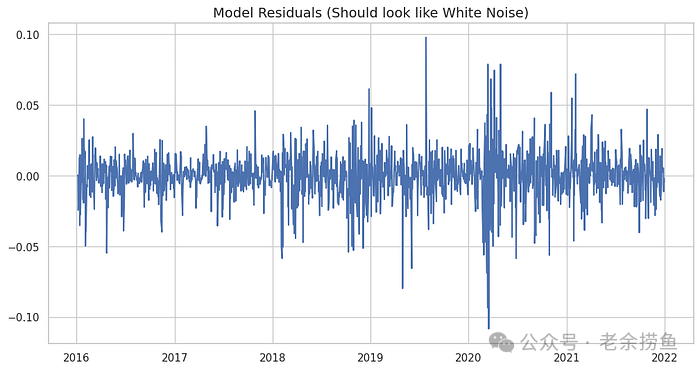
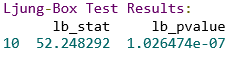
现在可以查看“lb_pvalue”。
- 如果 p 值 > 0.05:成功。我们接受原假设 H0(残差为白噪声)。模型有效。
- 如果 p 值 < 0.05:失败。残差仍然存在模式。我们需要一个更好的模型(或许可以增加 p 值或 q 值)。
6.7 模型预测
# 进行预测(预测未来5期)
forecast_steps = 5
forecast = best_model.forecast(steps=forecast_steps)
print(f"\n未来{forecast_steps}期的预测值:")
print(forecast)
# 可视化预测结果
fig, ax = plt.subplots(figsize=(14, 6))
# 绘制历史数据(最后100个点)
historical = df['Log_Return'].dropna()[-100:]
ax.plot(historical.index, historical.values,
label='历史数据', color='blue', linewidth=1.5)
# 绘制预测值
forecast_index = pd.date_range(start=historical.index[-1],
periods=forecast_steps+1, freq='D')[1:]
ax.plot(forecast_index, forecast,
label='预测值', color='red', linewidth=2, marker='o')
ax.set_title(f'ARIMA{best_order}模型预测结果', fontsize=14, fontweight='bold')
ax.set_xlabel('日期', fontsize=12)
ax.set_ylabel('对数收益率', fontsize=12)
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
七、ARIMA模型的局限性与改进方向
虽然ARIMA模型强大,但它也有明显的局限性:
7.1 无法捕捉波动率聚集
在金融市场中,有一个著名的现象叫波动率聚集 (Volatility Clustering):
- 大波动后面往往跟着大波动。
- 小波动后面往往跟着小波动。
ARIMA模型假设误差项的方差是恒定的,无法捕捉这种特征。
✅ 解决方案: 使用ARCH/GARCH模型来建模波动率。
7.2 只能处理单变量
ARIMA是单变量模型,只能根据自身历史来预测。但现实中,股价会受到多种因素影响(成交量、利率、汇率等)。
✅ 解决方案:
- ARIMAX模型:加入外生变量。
- VAR模型:多变量时间序列模型。
7.3 对长期预测效果不佳
ARIMA模型的预测精度会随着预测期数的增加而快速下降。通常只适合短期预测(1-10期)。
✅ 解决方案:
- 结合基本面分析。
- 使用机器学习模型(LSTM、Prophet等)。
八、实战建议与注意事项
基于多年的实战经验,给大家几点建议:
8.1 数据预处理是关键
- 处理缺失值:金融数据常有停牌、节假日等导致的缺失。
- 异常值处理:极端行情会严重影响模型。
- 数据频率选择:日度、周度、月度数据特性不同。
8.2 不要过度拟合
- 参数不是越多越好,要遵循简约原则。
- 样本内拟合好不代表样本外预测好。
- 一定要做回测验证。
8.3 结合领域知识
- 模型只是工具,不能替代思考。
- 重大事件(财报、政策)会打破历史规律。
- 要有风险意识,设置止损。
8.4 持续监控与更新
- 市场环境会变化,模型需要定期重新训练。
- 建立模型监控机制,及时发现失效。
- 保持学习,不断优化策略。
九、观点总结
ARIMA模型是时间序列分析的基石,掌握它相当于拿到了量化分析的入场券。本文系统介绍了ARIMA模型的理论基础、建模流程和Python实战方法,帮助读者掌握从数据预处理、平稳性检验、参数选择到模型诊断的完整技能链条。虽然ARIMA模型存在无法捕捉波动率聚集等局限性,但它仍然是金融预测、经济分析等领域不可或缺的基础工具。
✅ 核心要点回顾:
- AR模型捕捉惯性,MA模型捕捉冲击,ARMA模型两者结合。
- 差分是处理非平稳数据的利器,但不要过度差分。
- Box-Jenkins方法论提供了系统的建模流程:识别→估计→诊断。
- ADF检验判断平稳性,ACF/PACF图确定参数,AIC/BIC选择模型。
- 残差检验是模型诊断的关键,残差必须是白噪声。
- ARIMA有局限性,需要结合GARCH、ARIMAX等模型来改进。
💡 下一步学习方向:
- ARCH/GARCH模型:建模波动率;
- SARIMA模型:处理季节性数据;
- VAR模型:多变量时间序列;
- 机器学习方法:LSTM、Prophet、XGBoost等。
时间序列分析是一个庞大的领域,ARIMA只是开始。但只要你掌握了这篇文章的内容,就已经超越了90%的初学者。
记住:模型是工具,思维是核心。不要迷信任何模型,要理解其背后的逻辑,才能在实战中游刃有余。
希望这篇关于ARIMA算法的深度解析能对你有所帮助。如果你想进一步讨论时间序列预测或其他数据科学话题,欢迎到云栈社区与更多开发者交流。
 发表于 2026-2-11 10:02:17
|
查看: 294|
回复: 0
发表于 2026-2-11 10:02:17
|
查看: 294|
回复: 0
