在负载均衡体系中,健康检查是决定流量是否发往某个后端节点的关键环节。
在百万QPS规模下,绝大多数系统采用的二元健康模型工作良好:节点要么健康,要么不健康,负载均衡器据此做出非此即彼的路由决策。这个模型简单直观。
但当系统规模演进到千万QPS级别,二元模型的局限性便开始显著暴露。其核心矛盾在于:集群中任何一次批量摘除操作都意味着大规模流量重新分配,而这种流量突变本身就可能引发连锁问题。多级健康状态模型正是为了缓解这一矛盾而生,它让系统有能力表达“这个节点有点慢,但还能用”的中间状态,从而做出更平滑的流量调度决策。
二元健康模型:简单有效,但有边界
二元模型的核心逻辑简单直接:周期性地对后端节点发起探测(TCP连接、HTTP请求或自定义协议),根据探测结果将节点标记为健康或不健康。
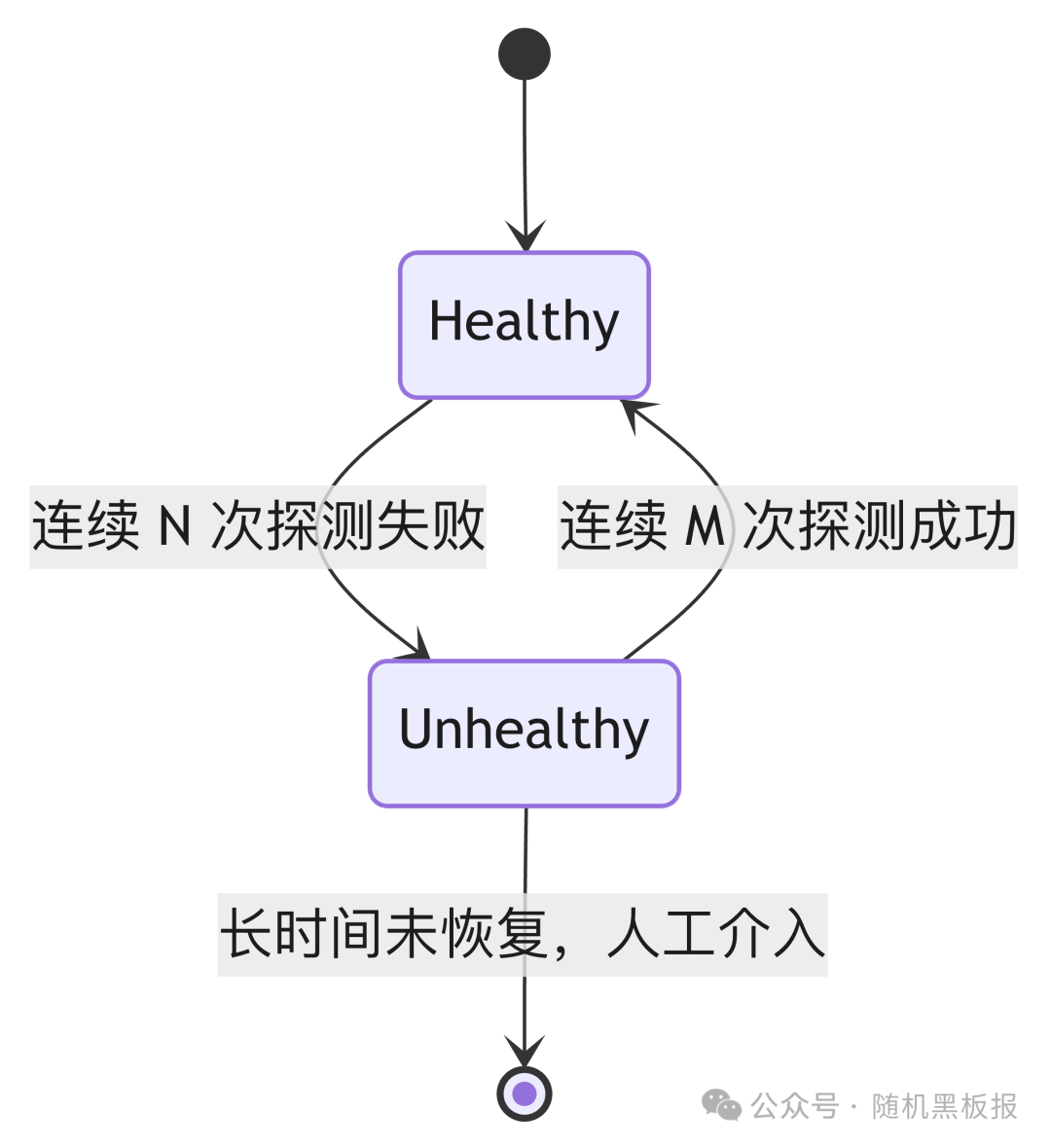
在百万QPS量级,一个典型的服务集群有几十到几百个后端节点,单节点承担数千到数万QPS。在这个规模下,二元模型的表现基本够用:
- 节点摘除的冲击可控。假设集群有100个节点,摘除1个节点意味着剩余99个节点各自多承担约1%的流量。这个增量通常在可消化范围内。
- 误判的代价有限。灰色状态(节点没挂但变慢了)在任何规模下都会出现。但在百万QPS下,即便误判导致一个半健康节点被完全摘除,对全局的冲击也就是那1%,系统能轻松吸收。
- 运维有时间窗口。单次故障的影响面相对较小,运维团队有足够的时间来人工介入处理异常节点。
二元模型的真正边界,不在于它不够精细,而在于当集群规模足够大时,摘除操作本身的副作用开始超过它试图解决的问题。
千万 QPS 下,摘除本身成为风险源
当系统规模到达千万QPS,二元模型面临的核心困境可以归结为一个问题:摘除操作引发的流量突变,可能比它试图隔离的故障更危险。
2.1 级联摘除:正反馈循环
假设一个承载1000万QPS的服务部署了500个节点,单节点承载约2万QPS。某个机房的网络抖动导致同一机房的50个节点同时被判定为不健康,10%的流量(100万QPS)需要瞬间重新分配到剩余450个节点上,每个节点突增约2200QPS(增幅超过11%)。
如果部分节点本身已经接近容量上限,这次突增可能使它们也出现超时,进而也被判定为不健康,这就形成了级联摘除的正反馈循环。

问题的本质是:二元模型只有“全量保留”和“完全摘除”两个档位,在需要处理批量节点异常时,只能做“跳崖式”的流量迁移。
2.2 灰色状态下的两难
千万QPS下,由于节点数量庞大、硬件环境复杂、依赖链路更长,各种灰色状态非常普遍:节点因GC导致P99延迟飙升但请求仍能返回,宿主机的邻居容器抢占CPU导致处理能力下降30%,下游某个依赖局部故障导致部分接口报错率升高……
这些场景下,节点并非不能工作,而是工作得不够好。二元模型只能在“继续满负荷发流量”和“完全摘除”之间二选一。前者可能让用户承受不必要的延迟,后者又回到了摘除引发流量突变的老问题。
需要说明的是,灰色状态在百万QPS下同样存在,只是那时误判的代价较小,摘掉一个其实还能用的节点,不过多分摊1%的流量。而在千万QPS下,同样的误判可能意味着数万QPS的流量需要被其他节点吸收,代价量级完全不同。
2.3 主动探测的局限性
传统健康检查通过独立的探测请求来判断节点状态。这种旁路探测的问题在于:探测请求是轻量级的,无法反映真实请求涉及的复杂计算和多级依赖调用;探测频率通常为秒级,对快速变化的节点状态感知滞后。
简而言之,一个节点可能“活着”但已经“喘不上气”,主动探测往往无法区分“健康”和“带病运行”。
多级健康状态模型
多级健康状态的核心思想是:用一组离散的状态等级来描述节点的健康程度,并将每个等级映射到不同的流量权重,使流量调度从“开关式”变为“旋钮式”。
3.1 状态定义与流量策略
一个典型的多级健康状态模型包含以下几个层级:
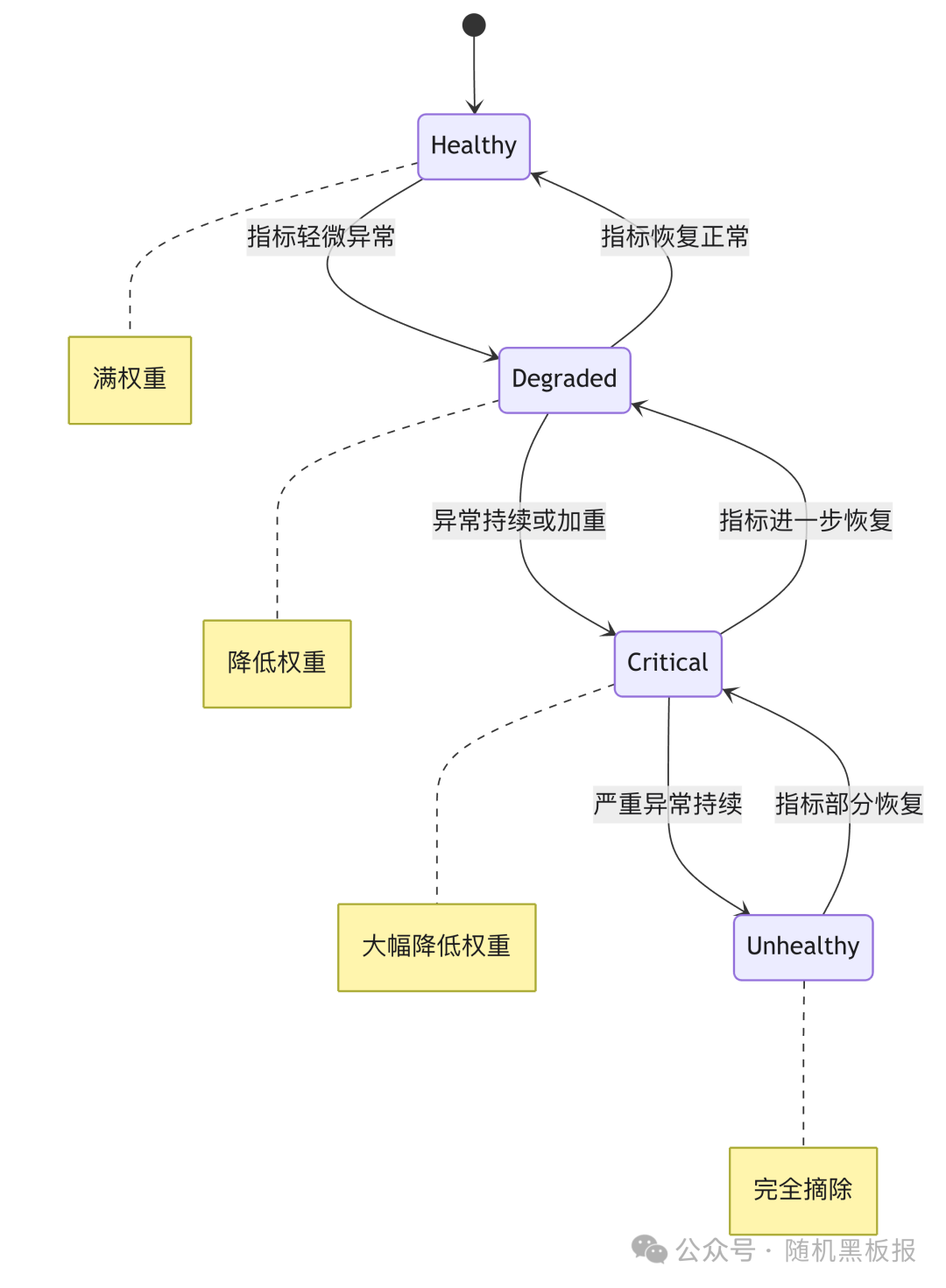
各状态的含义与对应策略如下:
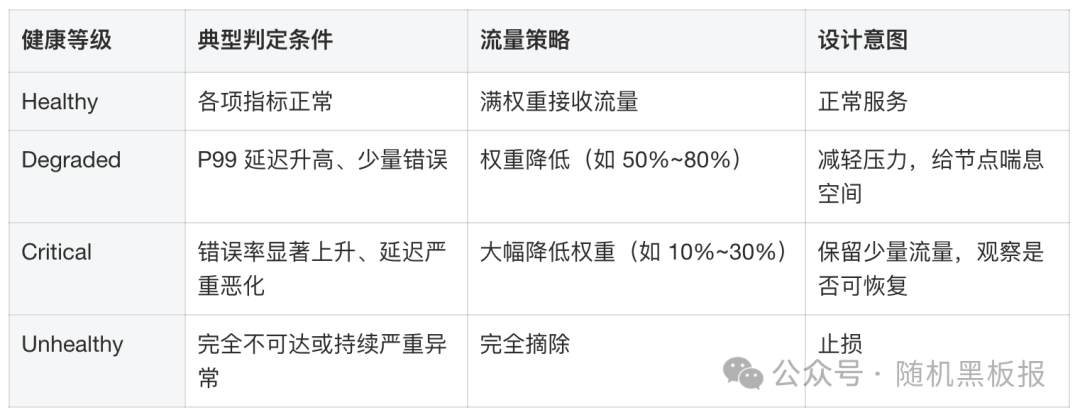
Degraded和Critical两个中间状态的存在,让系统可以渐进式地调整流量分配,而不是在“满负荷”和“完全摘除”之间跳崖式切换。需要指出的是,上表中的权重百分比是示意性的,实际生产中的合理阈值需要基于线上流量数据反复验证和调优,不同服务之间可能差异很大。
3.2 判定方式:引入被动观测
二元模型主要依赖主动探测来判断节点状态。而要支撑多级状态的精细判定,仅靠主动探测是不够的,需要引入被动观测,直接分析真实流量的处理结果(成功率、延迟分布等)来评估节点的实际服务能力。
被动观测相当于让真实流量本身充当探针。在千万QPS下,单节点每秒处理数万请求,几秒内就能积累统计意义上足够的样本。这使得系统可以在很短的时间窗口内,对节点状态做出比主动探测更精准、更及时的判断。
综合判定的整体思路是:将主动探测、被动观测、资源指标等多个维度的数据汇总评估,映射到对应的健康等级。
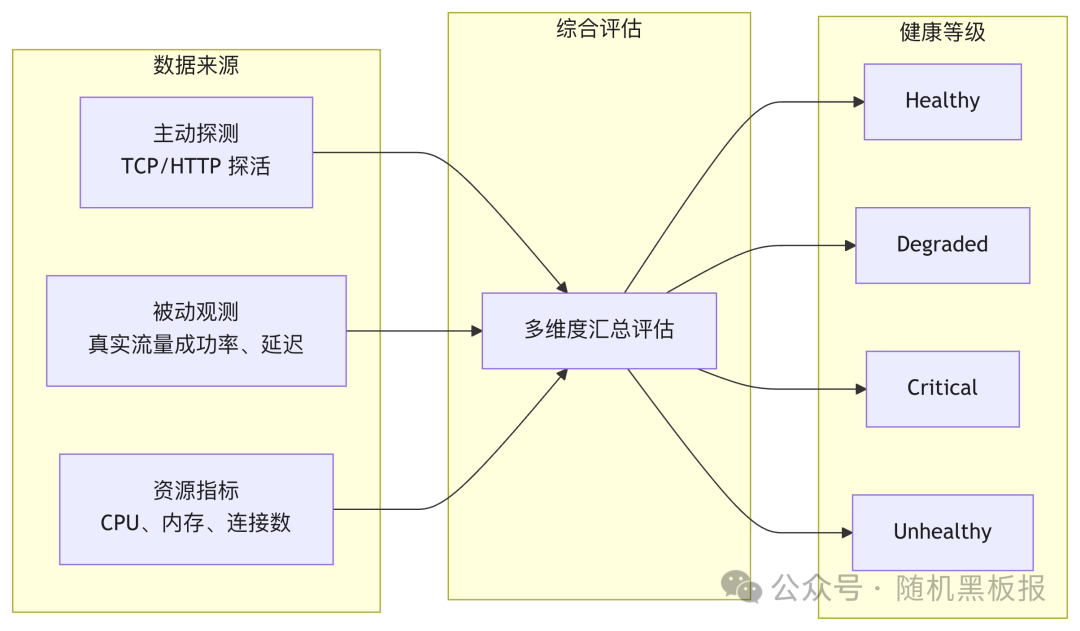
需要坦率地说,多维度综合评估听起来直观,但实际工程中如何为各维度设定合理的权重和阈值,是一个相当有挑战的问题。不同业务场景对延迟和错误率的敏感度差异很大,通常需要结合线上A/B实验和长期的数据积累来逐步调优,没有一劳永逸的通用方案。
3.3 防止振荡:状态迁移的阻尼设计
多级模型引入了更多状态,也意味着更多的状态转换路径。如果不加控制,节点可能在多个状态之间频繁跳转(尤其是在指标处于阈值边界时),流量分配因此不断变化,反而增加系统的不稳定性。
阻尼设计的核心策略是“恶化快响应,恢复慢回升”的非对称迁移。

- 恶化方向快速响应:当节点出现异常时,需要尽快减少其承担的流量,防止问题扩大。
- 恢复方向谨慎回升:节点恢复后不应立即满负荷接收流量,而是逐步增加,确认其稳定恢复后再提升等级。这也避免了刚恢复就被打满,然后又恶化的反复震荡。与之配套的是慢启动策略,节点恢复后的流量注入速率应该是渐进的,而不是等级一提升就瞬间按新权重灌入全量流量。
此外,实际系统中通常还会引入时间窗口平滑,不以瞬时指标值决定状态,而是基于一段时间窗口内的统计值(如最近30秒的P99延迟均值)来做判定,进一步降低噪声干扰。
同一场景,两种应对
为了更直观地理解多级模型的价值,我们用同一个故障场景来对比两种模型的应对过程。
场景:500节点集群承载1000万QPS,某机房50个节点因网络抖动出现P99延迟升高(但请求仍能返回)。
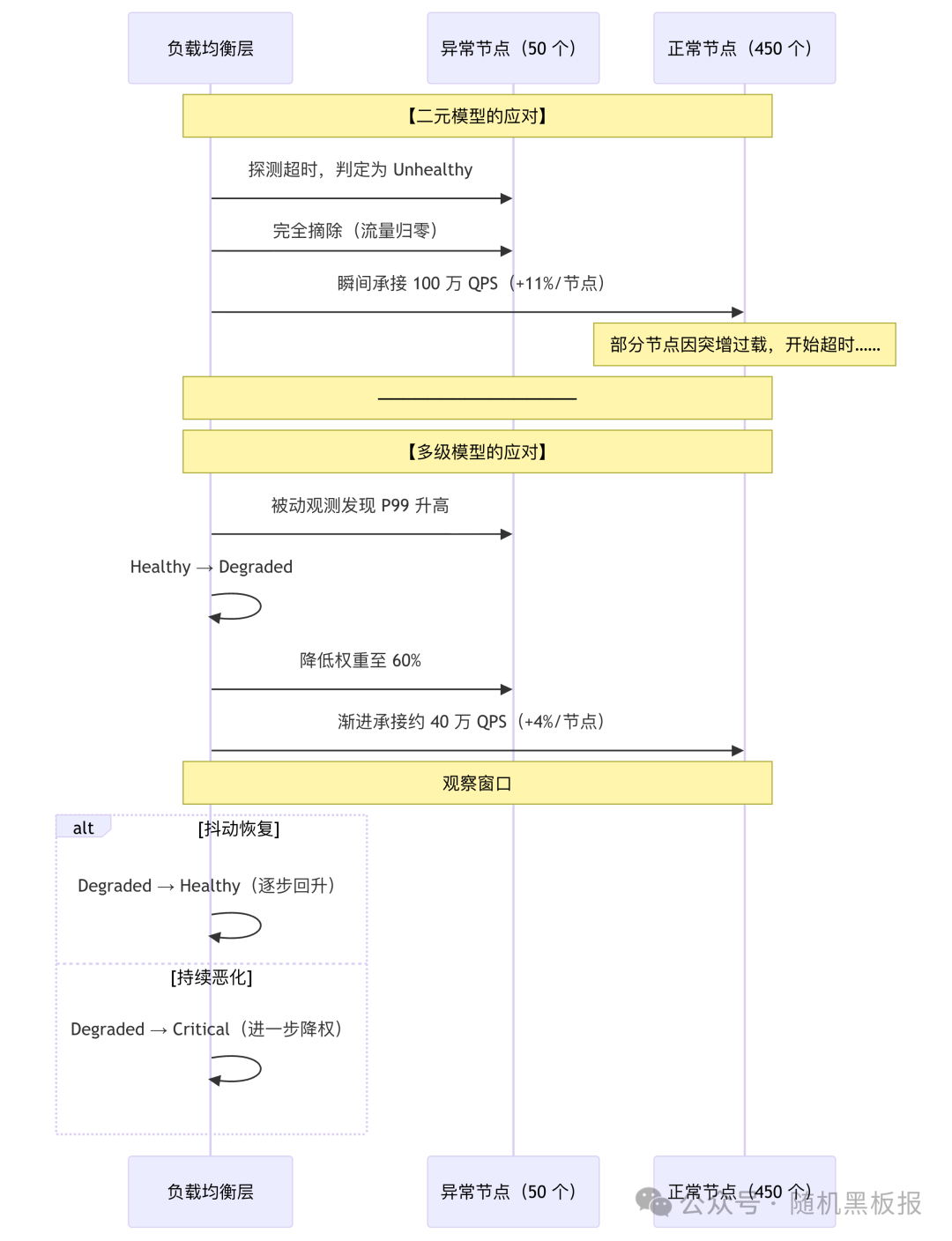
关键指标的对比如下:
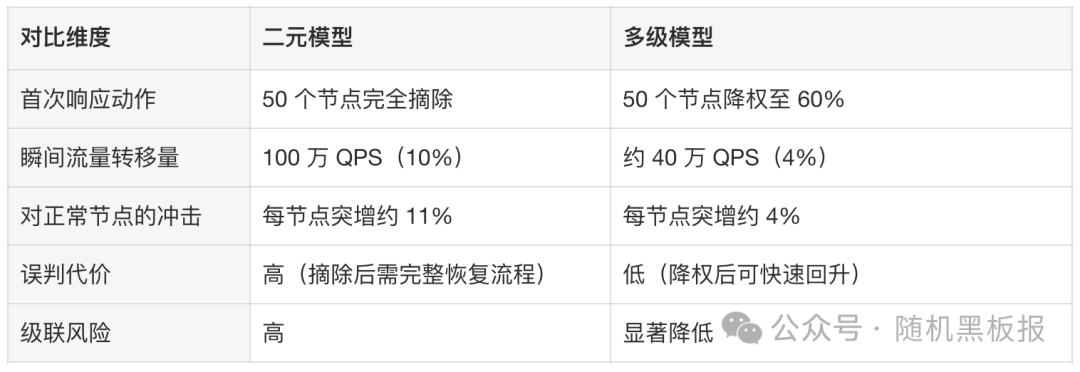
核心差异在于:多级模型通过先降权、再观察、必要时才摘除的策略,将每一步的流量变化控制在系统可吸收的范围内。如果抖动只是暂时的(实际中大多数抖动都是暂时的),系统甚至不需要经历完全摘除就能自行恢复。
配套机制:最大摘除比例
多级健康状态是精细化的流量调度手段,但它并非防止级联故障的唯一机制。在实际工程中,一个更简单直接的保护措施经常与之配合使用:最大摘除比例。
最大摘除比例的逻辑很朴素:无论健康检查的结果如何,在任意时刻,被标记为Unhealthy并完全摘除的节点数量不得超过集群总数的某个比例(如30%)。超出这个比例时,即使节点确实不健康,系统也宁可“带病服务”而不是继续摘除,因为全摘除带来的流量突变风险更大。
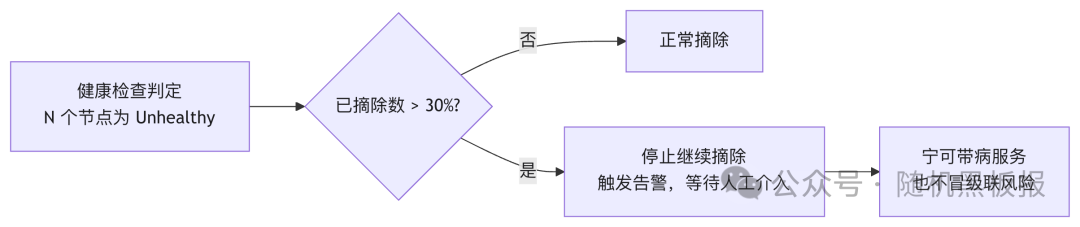
多级健康状态和最大摘除比例是互补的:前者通过渐进降权减少走到摘除这一步的概率,后者在万一大面积异常时提供最后的兜底保护。两者配合使用,构成千万QPS下健康检查体系的基本防线。
代价与权衡
任何架构选择都有代价,多级健康状态也不例外。在决定是否引入之前,需要清醒地认识以下几个问题:
- 调试和排查复杂度上升。二元模型下,排查问题时只需要关注节点什么时候被摘除、什么时候恢复。多级模型下,节点在多个状态间的迁移链条更长,需要更完善的日志和监控来追踪状态变迁过程,否则出了问题很难定位根因。
- 阈值调优是持续工程。各健康等级的判定阈值不是一次设定就能一劳永逸的。业务变更、流量模式变化、硬件升级都可能导致原本合理的阈值变得不再适用。这要求团队建立持续的阈值校准机制。
- 中间状态的沉淀问题。如果大量节点长期驻留在
Degraded状态,它们各自只承担部分流量,表面上看系统运行正常,但实际上已经出现了隐性的容量浪费。需要设置中间状态的最大驻留时间,超时未恢复的节点应最终被摘除或触发运维告警,而不是无限期地带病运行。
这些代价并不是否定多级模型的理由,而是提醒我们:它是一种用复杂度换取平滑性的权衡选择,适用于摘除操作本身的副作用已经大到不可忽视的场景。
从十万到百万到千万:健康检查的演进脉络
最后,从整体视角回顾健康检查机制随系统规模演进的路径。
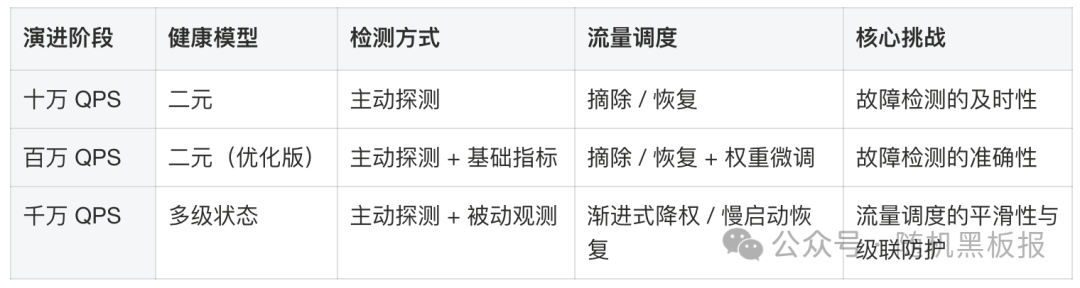
演进的主线是清晰的:随着规模增长,健康检查从判断节点“能不能用”演变为评估节点“能用到什么程度”,流量调度也从“开关式”演变为“旋钮式”。这不是技术复杂度的简单叠加,而是问题的本质发生了变化——当单次误判的代价足够大时,系统必须具备更精细的感知和更平滑的调控能力。
总结
多级健康状态模型的本质,是用更细粒度的状态表达换取更平滑的流量调度。它解决的核心问题是:在千万QPS规模下,二元的“摘除/恢复”操作本身带来的流量突变,可能比它试图解决的故障更危险。
这并不意味着每个系统都需要实现复杂的多级健康模型。对于大多数百万QPS及以下的系统,经过优化的二元模型配合合理的容量冗余,完全能够满足需求。但当系统规模跨过某个临界点,单次批量节点摘除引起的流量重分配已经足以对集群产生可感知的冲击时,多级健康状态配合最大摘除比例保护,就不再是锦上添花,而是必要的架构演进。
当然,这种演进伴随着更高的系统复杂度和持续的调优投入。选择引入它的前提是:你的系统确实到了“摘除操作本身就是风险”的规模。
在实际的系统稳定性保障,尤其是进行灰度发布等变更时,一个精细、平滑的健康检查机制是至关重要的基石。对于更多系统设计、高可用架构的深度探讨,欢迎在云栈社区交流分享。
 发表于 2026-2-11 11:35:48
|
查看: 246|
回复: 0
发表于 2026-2-11 11:35:48
|
查看: 246|
回复: 0
