在Linux系统中,广为流传着“一切皆文件”(Everything is a file)的理念。无论是普通文本、硬件设备,还是网络套接字、管道通信,统统都被抽象成了“文件”。而我们与这些“文件”打交道的钥匙,就是文件描述符(File Descriptor,简称fd)。
这个打交道的钥匙,文件描述符,用操作系统的术语来说,常被简化为“打开文件的句柄”。
它看似只是一个简单的非负整数,从内核视角看,文件描述符是进程与内核I/O子系统交互的核心接口,涉及进程管理、虚拟文件系统、内存管理、设备驱动等多个内核子系统。
一、文件描述符的本质:不只是整数
你可以把文件描述符简单理解为一个进程级别的“资源句柄”。它本身只是一个数字(比如0、1、3、4…),但通过这个数字,你的进程就能找到内核中那个真正代表“打开文件”的复杂数据结构。
fd不仅用于常规文件,还用于:
- 套接字(网络通信)
- 管道和FIFO(进程间通信)
- 设备文件(硬件抽象)
- 事件通知机制(eventfd、timerfd、signalfd)
这个设计非常巧妙:
- 对用户透明: 你不需要知道文件在磁盘的哪个磁道,inode结构具体在哪,只需要拿着这个“号码牌”(fd)去读写即可。
- 统一抽象: 无论是读写一个log.txt普通文件,还是通过网络发送数据(socket),甚至是进程间通信(pipe),操作方式都是
read(fd, ...)和write(fd, ...)。这种统一性是POSIX标准的核心,也是Linux强大生命力的体现。
核心要点: 文件描述符不是文件本身,它更像是一张“入场券”,是进程访问内核管理的I/O资源的桥梁。
内核视角的定义:
文件描述符是进程文件描述符表的索引,该表项指向内核文件表中的struct file对象,进而关联到VFS inode和具体文件系统实现。
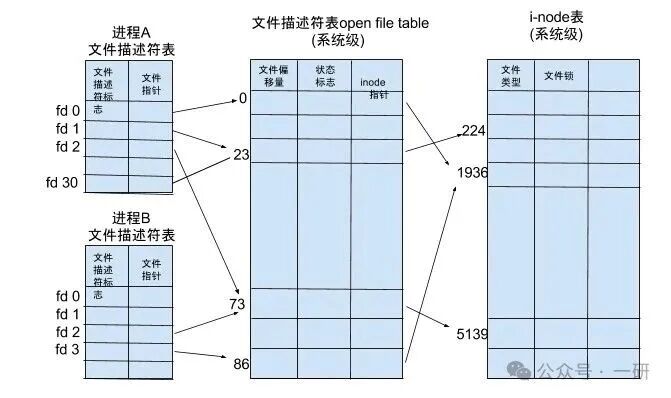
一个文件描述符从创建到使用,背后是内核三大表紧密协作的结果。理解了它们,你就看懂了文件I/O的“底层原理”。
进程级文件描述符表(Per-process File Descriptor Table)
- 位置: 每个进程的
task_struct结构体中(具体是 files 成员)。
- 作用: 这是进程私有的“目录”。它是一个数组,数组的下标就是我们看到的文件描述符(fd)。数组的每个元素是一个指针,指向系统级的“打开文件表”。
- 特点: 不同进程的同一个fd(比如都是3),通常指向完全不同的文件。
系统级打开文件表(System-wide Open File Table)
- 位置: 内核全局维护。
- 作用: 这是一个全局的“登记处”。表中的每一项(
struct file )记录了打开文件的状态信息,比如当前的文件读写位置( f_pos )、访问模式(只读/写/读写)、文件操作函数指针( f_op )等。
- 特点: 多个文件描述符(即使是不同进程的)可以指向同一个“打开文件表项”。这在
fork() 子进程继承或dup() 复制fd时非常常见。
文件系统的i-node表(i-node Table)
- 位置: 存储在磁盘上,加载到内存中管理。
- 作用: 这是文件在物理存储上的“身份证”。它存储了文件的元信息(metadata),如文件大小、权限、所有者、时间戳以及最重要的——指向文件数据块在磁盘上位置的指针。
- 特点: 一个“打开文件表项”会指向一个i-node。硬链接之所以能存在,就是因为多个目录项(文件名)指向了同一个i-node。
进程A [fd 3] ---> 打开文件表项A ---> i-node (磁盘文件)
进程A [fd 4] ---> 打开文件表项B ---|
进程B [fd 3] ---------------------> i-node (磁盘文件)
关键点说明:文件描述符是进程局部的,不同进程中相同的fd值可能指向不同文件。
//内核中task_struct与文件描述符的关联
struct task_struct {
// ...
struct files_struct *files; //进程打开文件表
// ...
};
struct files_struct {
struct file __rcu * fd_array[NR_OPEN_DEFAULT]; //文件指针数组
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
struct rcu_head rcu;
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
// ...
};
二、完整的内核数据结构链
四层关联架构:
进程描述符(task_struct)
↓
进程打开文件表(files_struct)
↓通过fd索引
内核文件对象(struct file) ←→ 文件状态标志、当前偏移量
↓
VFS inode(struct inode) ←→ 文件元数据、权限、引用计数
↓
具体文件系统inode←→ 磁盘上的实际数据位置
关键数据结构详解
//struct file 核心字段
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path; // 文件路径信息
struct inode *f_inode; //关联的inode
const struct file_operations *f_op; // 操作函数集
atomic_long_t f_count; // 引用计数
unsigned int f_flags; // 打开标志(O_RDONLY等)
fmode_t f_mode; // 文件模式
loff_t f_pos; // 文件偏移(重要!)
struct fown_struct f_owner; // 异步I/O所有权
// ...
};
//文件操作函数集(VFS接口层)
struct file_operations {
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
// ... 其他20+个操作函数
};
三、文件描述符分配算法与内核机制
一次 open 操作的内核之旅
当你在程序中调用int fd = open("data.txt", O_RDONLY);时,内核默默为你做了以下工作:
- 路径解析: 根据
"data.txt" 找到对应的i-node。
- 分配
struct file: 在系统级“打开文件表”中创建一个新条目,初始化文件模式、读写位置等。
- 分配文件描述符: 在当前进程的“文件描述符表”中,找到一个最小的、可用的空槽位(比如3),并将它指向刚刚创建的
struct file。
- 返回句柄: 将这个槽位编号(3)返回给用户程序。从此,你的程序就用这个
fd=3来操作文件了。
有趣的现象: 为什么新打开的文件描述符总是从3开始?
因为0、1、2被系统预留了!它们分别是标准输入(stdin)、标准输出(stdout)和标准错误(stderr)。这也是为什么你可以直接用 read(0, ...) 从键盘读取,用 write(1, ...) 向屏幕打印。
分配策略与实现
//内核分配文件描述符的核心逻辑
int __alloc_fd(struct files_struct *files,
unsigned start, unsigned end, unsigned flags)
{
unsigned int fd;
int error;
struct fdtable *fdt;
//自旋锁保护
spin_lock(&files->file_lock);
//查找空闲描述符(位图算法)
fd = find_next_fd(fdt, start);
//如果需要,扩展文件描述符表
if (fd >= fdt->max_fds) {
error = expand_files(files, fd);
if (error < 0)
goto out;
}
//设置fd对应的位图
__set_open_fd(fd, fdt);
spin_unlock(&files->file_lock);
return fd;
}
内核的三种分配模式
- 默认分配:从0开始查找第一个空闲fd。
- 指定分配:通过
dup2()或fcntl(F_DUPFD_CLOEXEC)。
- 原子分配:
open()系统调用中的O_CLOEXEC标志。
四、高级特性深度解析
文件描述符与进程间共享机制
//通过UNIX域socket传递文件描述符
// 发送端
struct msghdr msg = {0};
struct cmsghdr *cmsg;
char buf[CMSG_SPACE(sizeof(int))];
int fd_to_send = /*要传递的文件描述符*/;
msg.msg_control = buf;
msg.msg_controllen = sizeof(buf);
cmsg = CMSG_FIRSTHDR(&msg);
cmsg->cmsg_level = SOL_SOCKET;
cmsg->cmsg_type = SCM_RIGHTS;
cmsg->cmsg_len = CMSG_LEN(sizeof(int));
*(int *)CMSG_DATA(cmsg) = fd_to_send;
//接收端获得新的fd,但指向同一个内核file对象
close-on-exec机制深入
//内核实现close_on_exec位图
struct files_struct {
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
// ...
};
//系统调用处理
SYSCALL_DEFINE1(close, unsigned int, fd)
{
return __close_fd(current->files, fd);
}
//execve()时清理close_on_exec标记的fd
static void do_close_on_exec(struct files_struct *files)
{
unsigned i;
struct fdtable *fdt;
fdt = files_fdtable(files);
for (i = 0; i < fdt->max_fds; i++) {
if (test_bit(i, fdt->close_on_exec))
__close_fd(files, i);
}
}
五、性能关键:文件描述符表扩展与锁竞争
动态扩展机制
//文件描述符表扩展(内核实现)
static int expand_files(struct files_struct *files, int nr)
{
struct fdtable *new_fdt, *cur_fdt;
spin_lock(&files->file_lock);
cur_fdt = files_fdtable(files);
// 检查是否需要扩展
if (nr >= cur_fdt->max_fds) {
//计算新的表大小(按指数增长)
new_fdt = alloc_fdtable(nr);
if (!new_fdt) {
spin_unlock(&files->file_lock);
return -ENOMEM;
}
//拷贝旧表内容
copy_fdtable(new_fdt, cur_fdt);
rcu_assign_pointer(files->fdt, new_fdt);
//延迟释放旧表(RCU机制)
if (cur_fdt != &files->fdtab)
call_rcu(&cur_fdt->rcu, free_fdtable_rcu);
}
spin_unlock(&files->file_lock);
return 0;
}
锁优化策略
- RCU(Read-Copy-Update):读多写少场景的优化。
- 文件描述符表分片锁:减少锁竞争。
- 无锁查找优化:对于只读操作使用RCU保护。
六、生产环境调优深度指南
资源管理:突破“Too Many Open Files”的限制
在高并发服务器(如Web服务器、数据库)开发中,你很可能遇到过Too many open files的错误。这正是文件描述符资源耗尽的信号。
Linux对fd的使用限制
-
硬件/内核限制(编译时确定)
cat /proc/sys/fs/nr_open #单个进程最大fd数(2^20)
-
系统级限制(System-wide Limit)
- 查看:
cat /proc/sys/fs/file-max或sysctl fs.file-max。
- 含义: 整个系统最多能打开多少文件。通常与内存大小相关(约内存的10%)。
- 修改: 临时用
sysctl -w fs.file-max=100000,永久修改需编辑/etc/sysctl.conf。掌握这些系统限制的查看和修改是运维/DevOps工程师的基础技能。
-
用户/进程级限制(Per-process Limit)
- 查看:
ulimit -n。
- 含义: 单个进程能打开的文件描述符上限。32位系统默认1024,64位系统通常更高。
- 修改: 临时用
ulimit -SHn 65535,永久修改需编辑/etc/security/limits.conf。
用户级限制(PAM模块控制)
ulimit -Hn # 硬限制
ulimit -Sn # 软限制
进程级限制(继承自用户限制,可通过setrlimit修改)
cat /proc/<pid>/limits | grep "Max open files"
性能优化提示: 对于Nginx、Redis等服务,适当调高 ulimit -n 是提升并发能力的常见手段。
系统级调优参数详解
#/proc/sys/fs/ 下的关键参数
#系统最大文件描述符数(内存限制相关)
#计算方式:通常为内存大小(KB) / 10
echo "fs.file-max = 2097152" >> /etc/sysctl.conf
#文件句柄使用情况监控
#已分配 已使用(打开文件数) 最大可用
cat /proc/sys/fs/file-nr
#每个inode的打开文件最大数(针对特定文件系统)
echo "fs.inotify.max_user_instances = 1024" >> /etc/sysctl.conf
echo "fs.inotify.max_user_watches = 524288" >> /etc/sysctl.conf
#epoll相关优化(高并发场景)
echo "fs.epoll.max_user_watches = 1048576" >> /etc/sysctl.conf
//C程序内动态调整
#include <sys/resource.h>
void increase_nofile_limit(rlim_t max_limit) {
struct rlimit rlim;
getrlimit(RLIMIT_NOFILE, &rlim);
rlim.rlim_cur = max_limit;
setrlimit(RLIMIT_NOFILE, &rlim);
}
七、故障排查与调试高级技巧
内核追踪技术
#使用ftrace追踪文件描述符相关系统调用
echo 1 > /sys/kernel/debug/tracing/events/syscalls/sys_enter_open/enable
echo 1 > /sys/kernel/debug/tracing/events/syscalls/sys_exit_open/enable
cat /sys/kernel/debug/tracing/trace_pipe
#使用perf分析文件描述符使用模式
perf record -e syscalls:sys_enter_open* -a -g -- sleep 10
perf report
#eBPF/BCC工具集
/usr/share/bcc/tools/filetop # 实时文件操作监控
/usr/share/bcc/tools/opensnoop # 跟踪所有open()调用
内存与性能分析
#检查文件描述符内存占用
cat /proc/slabinfo | grep -E "filp|files_cache"
# filp:struct file对象缓存
# files_cache:files_struct对象缓存
#监控文件描述符泄漏
# 使用valgrind的fdleak工具
valgrind --tool=exp-fdleak ./your_program
#或者使用自定义的LD_PRELOAD库
LD_PRELOAD=./libfdleak.so ./your_program
八、容器时代的文件描述符挑战
容器环境特殊性
#在容器中,每个层级都需要正确配置
# Docker容器配置
docker run --ulimit nofile=65535:65535 \
--sysctl fs.file-max=2097152 \
your_image
# Kubernetes Pod配置
apiVersion: v1
kind: Pod
spec:
containers:
- name: app
resources:
limits:
#注意:K8s目前不支持直接设置文件描述符限制
# 需要在容器镜像内配置
理解容器环境下的资源限制配置,对于构建健壮的云原生应用至关重要。
多租户环境隔离
//命名空间对文件描述符的影响
//每个命名空间有自己的文件描述符表
struct nsproxy {
// ...
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct nsproxy *nsproxy;
// ...
};
//跨命名空间的fd传递需要特殊处理
九、最佳实践与架构建议
工程实战:你必须知道的一些技巧
- 查看进程的fd:
利用
/proc 文件系统ll /proc/$PID/fd可以直观看到某个进程打开了哪些文件。你会发现Vim编辑文件时,fd可能不是3,这与它的备份机制有关。
- 文件描述符复制:
dup() 和 dup2() 系统调用可以复制fd。这在实现Shell重定向(如 > 、 | )时至关重要。
- I/O多路复用:
select、poll、epoll等机制允许单个线程同时监控成百上千个fd的读写状态,是构建高性能网络服务器(如Netty、Nginx)的基石,深刻理解它们对掌握网络/系统编程非常关键。
- 非阻塞I/O: 通过
fcntl(fd, F_SETFL, O_NONBLOCK)设置fd为非阻塞模式,避免 read / write 操作无限期等待,提升程序响应性。
应用程序设计原则
- 尽早释放:使用
O_CLOEXEC标志避免fd泄漏到子进程。
- 资源池化:对频繁打开关闭的文件使用fd池。
- 异步安全:在多线程环境中正确处理fd的共享与同步。
- 优雅降级:当达到fd限制时,应有降级策略而非直接崩溃。
文件描述符监控告警体系
#系统级别监控
SYSTEM_FD_USAGE=$(cat /proc/sys/fs/file-nr | awk '{print $2}')
SYSTEM_FD_MAX=$(cat /proc/sys/fs/file-max)
SYSTEM_USAGE_RATIO=$((SYSTEM_FD_USAGE * 100 / SYSTEM_FD_MAX))
#进程级别监控
for pid in $(ps -eo pid=); do
FD_COUNT=$(ls /proc/$pid/fd 2>/dev/null | wc -l)
FD_LIMIT=$(grep "Max open files" /proc/$pid/limits 2>/dev/null | awk '{print $4}')
if [ $FD_COUNT -gt $((FD_LIMIT * 80 / 100)) ]; then
echo "警告: PID $pid 文件描述符使用率过高: $FD_COUNT/$FD_LIMIT"
fi
done
#使用Prometheus metrics暴露
echo "node_fd_allocated $(cat /proc/sys/fs/file-nr | awk '{print $1}')"
echo "node_fd_used $(cat /proc/sys/fs/file-nr | awk '{print $2}')"
echo "node_fd_maximum $(cat /proc/sys/fs/file-max)"
总结
文件描述符是Linux I/O模型的基石。它通过一个简单的整数,向上为应用程序提供了统一、简洁的接口,向下则串联起了进程管理、内存管理和文件系统等复杂的内核机制。
从0/1/2 的标准流,到/proc/$PID/fd的窥探,再到epoll的高并发,文件描述符贯穿了Linux开发的方方面面。深刻理解它的原理,不仅能帮你写出更健壮的代码,更能让你在面对棘手的I/O问题时,拥有“内核级”的洞察力。
下次当你再敲下open()或socket()时,不妨想一想背后那几张由内核精心维护的“表”,感受一下Linux设计的精妙之处吧。
深入思考:随着io_uring等异步I/O新机制的出现,文件描述符的管理和使用模式正在发生怎样的变化?这对我们设计下一代高性能服务器架构有何启示?

 发表于 2025-12-5 14:14:47
|
查看: 218|
回复: 0
发表于 2025-12-5 14:14:47
|
查看: 218|
回复: 0
