当整个领域都在钻研如何为扩散模型“减肥”,减少其繁重的推理步数时,何恺明团队选择了一个完全不同的方向。他们提出了一个更根本的问题:为什么生成模型非得在推理时迭代不可?
主流的 Diffusion 和 Flow Matching 模型遵循同一套规则:在推理时通过一步步迭代去噪,将随机噪声转化为图像。这个过程需要几十甚至上百次网络前向传播,计算成本巨大。于是,蒸馏、高级求解器、步数压缩等加速技术应运而生,但它们本质上仍在原有的框架内进行优化。
而来自 MIT 的这篇论文,直接打破了这个框架。
他们提出的 Drifting Models,将关键的“迭代”过程从推理阶段转移到了训练阶段。模型在训练中学习分布的动态“漂移”,从而使得在最终推理时,仅需一次网络前向传播,就能生成高质量图像。
效果如何?在 ImageNet 256×256 基准测试中,他们的单步生成器在潜空间达到了 FID 1.54,在像素空间达到了 FID 1.61,刷新了单步生成的SOTA记录,其表现甚至超越了许多需要多步推理的 Diffusion 模型。
这并非一次渐进式的改良,更像是一次生成范式的转变。
从 Pushforward 说起:生成模型的本质
要理解 Drifting Models,我们得先回到生成模型的数学本质。其核心任务是学习一个映射函数 ( T ),将先验分布 ( pz )(例如高斯噪声)变换为数据分布 ( p{data} )。用数学语言描述,即学习一个 Pushforward 分布:
( pT = T* p_z ),目标是让 ( pT ≈ p{data} )。
直观地说,函数 ( T ) 把一种分布“推”成了另一种分布。
那么,Diffusion 模型是怎么做的? 它们在推理时迭代地执行 Pushforward。每一步,模型都将“稍微嘈杂”的样本映射为“稍微干净”的样本,逐步将噪声分布演变成数据分布。这相当于把一个复杂的变换分解成多个简单步骤,在推理时串联执行。
Drifting Models 的洞察又是什么? 既然神经网络训练本身就是迭代的(SGD、Adam),那么训练过程自然就会产生一系列模型参数 ( θi ),对应一系列的 Pushforward 分布 ( p{θ_i} )。
为什么不让分布在训练时就演化到目标状态,从而使推理一步到位呢? 这正是 Drifting Models 的核心思想。
漂移场:驱动分布演化的引擎
Drifting Models 的关键机制是 漂移场。
当网络参数从 ( θ ) 更新到 ( θ' ) 时,对于同一个噪声输入 ( z ),输出会从 ( x = Tθ(z) ) 变为 ( x' = T{θ'}(z) )。这个变化可以写作:
[
Δx = x' - x
]
其中 ( Δx ) 就是样本的“漂移”。Drifting Models 引入一个漂移场来显式地控制这个漂移:
[
Δx = V(p_{data}, p_θ; x)
]
这个漂移场 ( V ) 依赖于两个分布:目标数据分布 ( p_{data} ) 和当前的生成分布 ( p_θ )。
关键性质:反对称性
论文证明了一个优雅的性质:如果漂移场满足反对称性:
[
V(p, q; x) = -V(q, p; x)
]
那么当 ( pθ = p{data} )(分布匹配)时,必然有 ( V = 0 )(漂移为零)。直觉上,反对称性意味着交换两个分布只会翻转漂移方向。当两个分布相同时,漂移必须为零——系统达到了平衡态。这个性质给出了一个自然的训练目标:最小化漂移场的范数。当 ( V → 0 ) 时,生成分布便趋近于数据分布。
吸引与排斥:漂移场的具体设计
如何设计一个满足反对称性的漂移场?作者借鉴了经典的 Mean-Shift 方法,提出了基于“吸引-排斥”机制的设计。
核心思想:
- 正样本(来自数据分布 ( p_{data} ))对生成样本产生吸引力。
- 负样本(来自生成分布 ( p_θ ))对生成样本产生排斥力。
具体地,定义两个向量场:
[
A(x) = \mathbb{E}{y \sim p{data}} [k(x, y) \cdot (y - x)] / ZA
]
[
R(x) = \mathbb{E}{y \sim p_θ} [k(x, y) \cdot (y - x)] / Z_R
]
其中 ( k(\cdot, \cdot) ) 是一个核函数(论文使用指数核),( Z ) 是归一化因子。最终的漂移场定义为两者之差:
[
V(x) = A(x) - R(x)
]
直观解释:
- ( A(x) ) 是数据分布的“引力”,将生成样本拉向真实数据密集的区域。
- ( R(x) ) 是生成分布的“斥力”,防止生成样本过于聚集,从而避免模式坍塌。
- 两者相减,当 ( pθ = p{data} ) 时,吸引力和排斥力完美抵消,( V(x) = 0 )。
这个设计优雅地满足了反对称性:( V(p, q; x) = A_p(x) - R_q(x) = -(A_q(x) - R_p(x)) = -V(q, p; x) )。
训练目标:固定点迭代
有了漂移场,如何设计训练目标?作者将问题转化为一个固定点迭代。在平衡态时:
[
x = x + V(p_{data}, p_θ; x) \quad \text{(因为 } V = 0 \text{)}
]
训练时,我们希望通过逐步逼近这个平衡态。这导出了以下损失函数:
[
\mathcal{L} = \mathbb{E}_{z \sim p_z} | T_θ(z) - (Tθ(z) + \text{stopgrad}(V(p{data}, p_θ; T_θ(z)))) |^2
]
请注意这里的 stopgrad 操作:目标是“冻结”的,来自上一次迭代的状态。这个技巧借鉴了 SimSiam、Consistency Models 等工作,避免了直接对分布求导的数学困难。
其核心伪代码非常简洁:
# f: generator
# y_pos: [N_pos, D], data samples
z = randn([N, C]) # noise
x = f(z) # [N, D], generated samples
y_neg = x # reuse x as negatives
V = compute_V(x, y_pos, y_neg)
x_drifted = stopgrad(x + V)
loss = mse_loss(x - x_drifted)
这种简洁性是 Drifting Models 的一大优势——不需要复杂的 ODE/SDE 求解器,也不需要蒸馏一个预训练模型。它展现了一种构建生成模型的清新思路,相关代码和讨论也适合在 开源实战 板块进行深入交流。
特征空间中的漂移:为什么需要特征提取器?
在高维图像空间中,直接计算像素层面上的样本相似度(核函数 ( k(\cdot, \cdot) ))会遭遇“维度灾难”——所有样本彼此间的距离看起来都差不多。
作者的解决方案是在特征空间中计算漂移:
[
k(x, y) = \exp(-|\phi(x) - \phi(y)|_2^2 / \tau)
]
其中 ( \phi ) 是一个预训练的特征提取器(如 SimCLR、MoCo 或作者定制的 latent-MAE)。
为什么特征空间更有效? 自监督学习的目标正是让语义相似的样本在特征空间中彼此靠近。这与 Drifting Models 的需求高度一致——我们需要核函数能够有效度量样本的“语义相似度”,而非表面的像素差异。
一个重要发现是:实验表明,没有特征提取器,该方法在 ImageNet 上完全无法工作。特征空间的质量直接决定了生成质量——更强的特征编码器(更宽的网络、更长的预训练)能带来更好的生成效果。
实验结果:一步生成的新 SOTA
Drifting Models 在 ImageNet 256×256 数据集上取得了令人印象深刻的结果。
潜空间生成(标准设定)
| 方法 |
NFE |
FID ↓ |
| DiT-XL/2 |
250×2 |
2.27 |
| SiT-XL/2 |
250×2 |
2.06 |
| iCT-XL/2(单步) |
1 |
34.24 |
| Shortcut-XL/2(单步) |
1 |
10.60 |
| MeanFlow-XL/2(单步) |
1 |
3.43 |
| iMeanFlow-XL/2(单步) |
1 |
1.72 |
| Drifting Model, L/2(单步) |
1 |
1.54 |
关键观察:
- 单步生成刷新SOTA:FID 1.54 是目前单步生成的最佳结果,甚至优于许多多步 Diffusion 模型。
- 小模型,大效果:Base 模型(1.33亿参数)就能达到 FID 1.75,与参数规模大得多的 XL 模型(6.75亿参数)竞争。
- 无需CFG即最优:当分类器无关引导(CFG)的 scale 为 1.0(即无引导)时效果最好,说明模型自身已学到了足够好的数据分布。
像素空间生成(更有挑战性)
不使用 VAE 编码器,直接在 256×256×3 的像素空间生成:
| 方法 |
NFE |
FID ↓ |
| ADM-G |
250×2 |
4.59 |
| VDM++ |
256×2 |
2.12 |
| StyleGAN-XL |
1 |
2.30 |
| Drifting Model, L/16 |
1 |
1.61 |
在像素空间,Drifting Models 同样取得了 SOTA 结果,并且只需 87G FLOPs,远低于 StyleGAN-XL 的 1574G FLOPs。

为什么不会模式坍塌?
GAN 广为人知的问题是模式坍塌——生成器只学会生成数据分布中的一小部分模式。Drifting Models 如何避免?
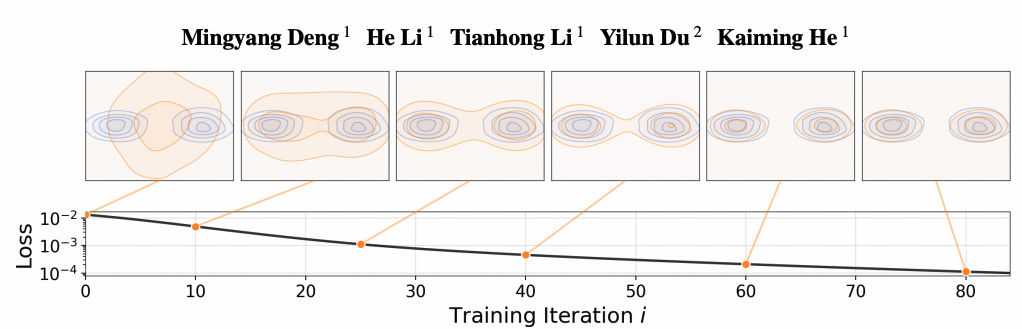
作者通过 2D 玩具实验给出了直观解释:假设生成分布 ( p_θ ) 坍塌到了目标双峰分布中的一个峰上。此时,来自另一个峰的真实数据会对生成样本产生“吸引力”,促使它们向那个未被覆盖的峰移动。只要还存在未被覆盖的数据模式,漂移场就不会为零,分布就会继续演化。
这种“自纠正”机制是反对称设计的自然结果——吸引力和排斥力的动态平衡确保了所有数据模式都会被逐渐探索和覆盖。
反对称性的重要性:破坏实验
论文通过精心设计的消融实验,验证了反对称性的关键作用。
| 设置 |
漂移场 V |
FID |
| 反对称(默认) |
( A - R ) |
8.46 |
| 1.5× 吸引 |
( 1.5A - R ) |
41.05 |
| 1.5× 排斥 |
( A - 1.5R ) |
46.28 |
| 2.0× 吸引 |
( 2A - R ) |
86.16 |
| 2.0× 排斥 |
( A - 2R ) |
112.84 |
| 仅吸引 |
( A ) |
177.14 |
结果非常清晰:一旦打破反对称性,生成性能便会灾难性下降。直觉上,对于一个样本 ( x ),我们需要来自 ( p_{data} ) 的吸引力和来自 ( pθ ) 的排斥力在 ( p{data} = p_θ ) 时完美抵消。任何不平衡都会导致模型无法收敛到真正的平衡态。
正负样本数量的影响
Drifting Models 的训练依赖于从数据分布采样正样本、从生成分布采样负样本来估计漂移场 ( V )。样本数量如何影响性能?
| N_pos |
N_neg |
FID |
| 1 |
64 |
20.43 |
| 16 |
64 |
10.39 |
| 32 |
64 |
8.97 |
| 64 |
64 |
8.46 |
结论:更多的正负样本会带来更好的性能。这与对比学习的经验一致——更大的样本集能提供更准确的分布估计,从而计算出更精确的漂移方向。
超越图像生成:机器人控制
为了验证方法的通用性,作者将 Drifting Models 应用到了机器人控制领域。
实验设计:将 Diffusion Policy 中的多步扩散生成器替换为单步的 Drifting Model(称为“Drifting Policy”)。
| 任务 |
Diffusion Policy (100 NFE) |
Drifting Policy (1 NFE) |
| Lift(视觉) |
1.00 |
1.00 |
| Can(视觉) |
0.97 |
0.99 |
| PushT(视觉) |
0.84 |
0.86 |
| BlockPush Phase 2 |
0.11 |
0.16 |
| Kitchen Phase 4 |
0.99 |
0.96 |
单步的 Drifting Policy 在大多数任务上匹配甚至超越了需要100步的 Diffusion Policy。这表明 Drifting Models 不仅仅是图像生成的专用工具,而是一种具有广泛应用潜力的通用生成模型范式,其思想在 人工智能 的多个子领域都值得关注。
与其他方法的对比:概念上的差异
Drifting Models 与现有方法存在根本性的概念区别:
vs. Diffusion/Flow Models
- Diffusion/Flow:推理时迭代,训练单步去噪/配准。
- Drifting:训练时迭代演化分布,推理单步。
vs. GANs
- 共同点:都是单步生成器。
- 差异:GAN 依赖对抗训练和判别器;Drifting 是非对抗的,通过漂移场驱动。
vs. Consistency Models
- Consistency Models:通过蒸馏或自一致性约束来逼近 Diffusion ODE 的轨迹。
- Drifting:完全不依赖 SDE/ODE 形式主义,是一种全新的建模范式。
vs. Moment Matching (MMD)
- MMD:直接最小化分布间的距离。
- Drifting:通过漂移场间接地演化分布,训练通常更稳定。
局限性与开放问题
作者也坦诚地讨论了当前方法的一些局限和未解决的问题:
- 理论保证的缺失:虽然证明了 ( V=0 ) 时 ( pθ = p{data} ),但逆向的保证(( pθ = p{data} ) 时 ( V=0 ))在理论上并不严格成立。实践中模型表现良好,但缺乏严格的收敛性证明。
- 必须使用特征提取器:在 ImageNet 等复杂数据集上,不使用特征编码器则方法失效。这是一个重要的外部依赖,也是未来改进的方向。
- 设计选择的优化空间:漂移场的设计、核函数的选择、特征编码器的架构与训练方式等,都还有广阔的探索空间。
论文信息
- 标题:Generative Modeling via Drifting
- 作者:Mingyang Deng, He Li, Tianhong Li, Yilun Du, Kaiming He
- 机构:MIT
何恺明团队的这项研究为生成式模型开辟了一条令人兴奋的新路径。它挑战了“推理必须迭代”的固有认知,用简洁优雅的“漂移”机制实现了高质量的单步生成。尽管仍有理论和技术细节有待完善,但 Drifting Models 无疑为下一代高效生成模型的设计提供了宝贵的灵感。对这类前沿 Transformer 架构下的生成模型进展感兴趣的朋友,可以持续关注云栈社区的技术动态与深度解读。
 发表于 2026-2-11 22:01:50
|
查看: 353|
回复: 0
发表于 2026-2-11 22:01:50
|
查看: 353|
回复: 0
