无论是用OpenClaw,还是自己搭建各种自动化流程,只要重度使用AI Agent,就一定会面临API账单和任务成功率之间的艰难博弈:是拉满旗舰大模型保底成功,还是用便宜的小模型节省成本?
随着Agent对外部工具的使用越来越熟练,很多人开始倾向于后者。直觉上,如果4B模型知道如何调用计算器,似乎就没必要花大价钱让32B模型硬扛。Meta联合帝国理工、剑桥大学在最新论文《Scaling Small Agents Through Strategy Auctions》中对这个直觉进行了量化测试。结果很明确:小模型在处理简单任务时确实表现不俗,但在复杂的长流程任务中,其成功率会迅速崩盘。

为了在不牺牲性能的前提下显著降低API费用,研究团队设计了一个名为 Strategy Auctions (SALE) 的新框架。它摒弃了专门训练路由(Router)模型的传统路线,创造性地将任务分配做成了类似“自由职业市场”的外包竞标模式。每当新任务到来,大小各异的智能体先提交一份短小精悍的“战略计划”去竞标,系统评估性价比后择优派单。本文将为您深度拆解SALE框架背后的核心原理与运作机制。
小模型的幻觉与现实:复杂度是一道墙
在讨论具体解决方案之前,我们需要先量化问题的严重性。以往对智能体的评估往往基于Token数量或简单的任务分类,但这类维度往往失真。为了更科学地度量任务对智能体的挑战性,研究者提出了 HST-Bench (Human Solution Time Benchmark)。
这是一个极具洞察力的度量标准:用“人类专家解决该任务所需的平均时间”来定义任务复杂度。这自然地将推理深度、规划难度和执行繁琐度融合在一个统一的标尺上。基于这个标尺,研究者将任务分为了从 <6秒(极简)到60分钟(12.5-60分钟区间)(极难)的五个等级。
实验结果揭示了一道清晰的“性能断崖”:
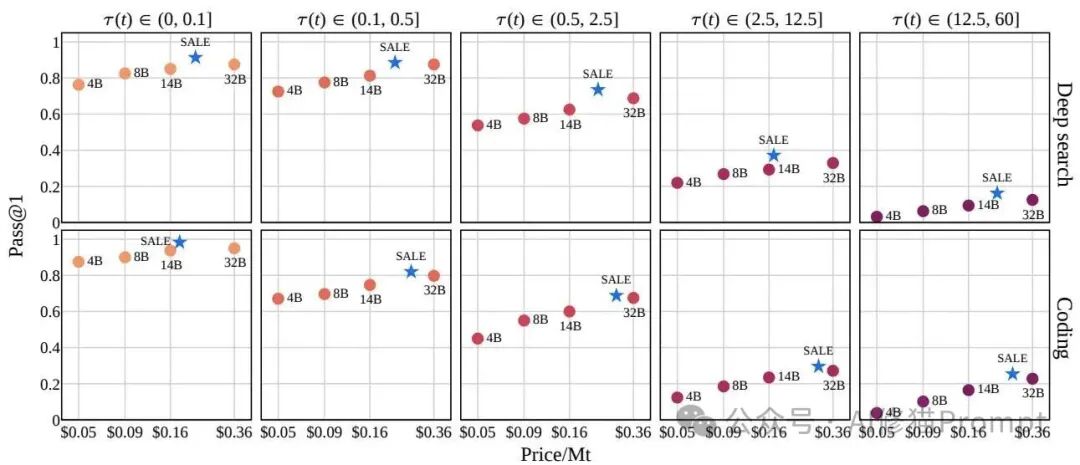
- 简单任务的“平替”假象:在人类能在6秒内解决的简单任务(如基础问答、简单代码填空)上,最小的4B模型表现惊人,达到了32B模型约 87% (Deep Search) 和 92% (Coding) 的Pass@1性能。这解释了为什么在很多Demo展示中,小模型看起来如此强大。
- 复杂任务的“崩盘”真相:一旦任务复杂度拉升到12.5分钟以上(需要多步推理、跨源信息整合或复杂调试),小模型的相对性能瞬间暴跌至大模型的 25% (Deep Search) 和 17% (Coding)。此时,模型参数量的差距暴露无遗。
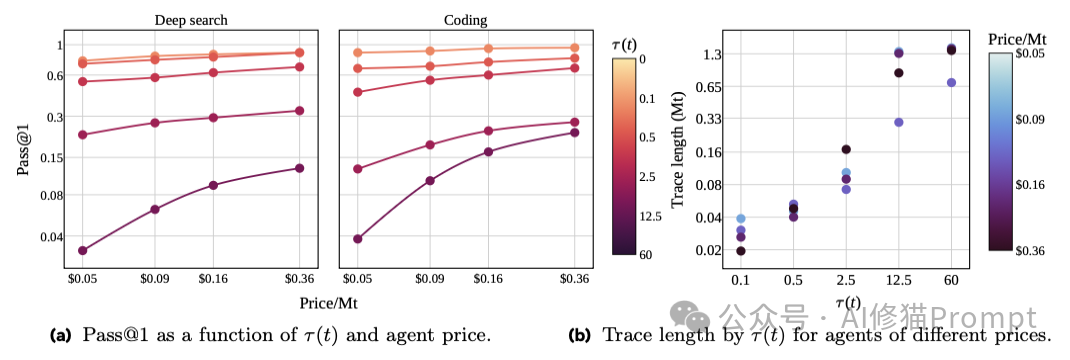
更有趣的是关于“成本”的反直觉发现。你可能会认为,大模型虽然单价贵,但或许更聪明,能用更少的步骤解决问题,从而在总成本上“回本”。但数据无情地否定了这一点:在复杂任务中,大模型的Token消耗量并没有显著低于小模型。这意味着,大模型是实打实的“贵”,并没有带来Token效率(Token Efficiency)的红利。
结论很明确:盲目全用小模型是处理不了复杂任务的“自杀行为”,而盲目全用大模型则是处理简单任务的“资源浪费”。我们需要的是一种动态的、基于任务实时复杂度的智能分配机制。
SALE:把任务交给“出价”最合适的人
传统的解决方法是训练一个路由器(Router)模型,预测哪个智能体能搞定当前任务。但这种“预测型路由器”有两个致命弱点:一是训练昂贵且难以泛化(来一个新模型就得重新训练),二是它们通常是静态的,无法在运行时适应任务或环境的变化。
Meta提出的SALE框架,选择了一条完全不同的路:不预测,让智能体自己“抢单”。
只竞标,不执行 (Bid with Plans)
在一个典型的智能体任务流中,执行阶段(调用工具、阅读文档、生成代码)往往消耗了绝大多数Token(数万甚至数百万)。相比之下,生成一个“解决思路”或“战略计划”(Strategic Plan)通常只需要几百个Token。
SALE框架巧妙地利用了这一点。当一个任务到来时,系统中的所有智能体(例如4B, 8B, 14B, 32B)并不直接去干活,而是每人先写一份“计划书”。这份计划书就是它们参与竞争的“标书”。
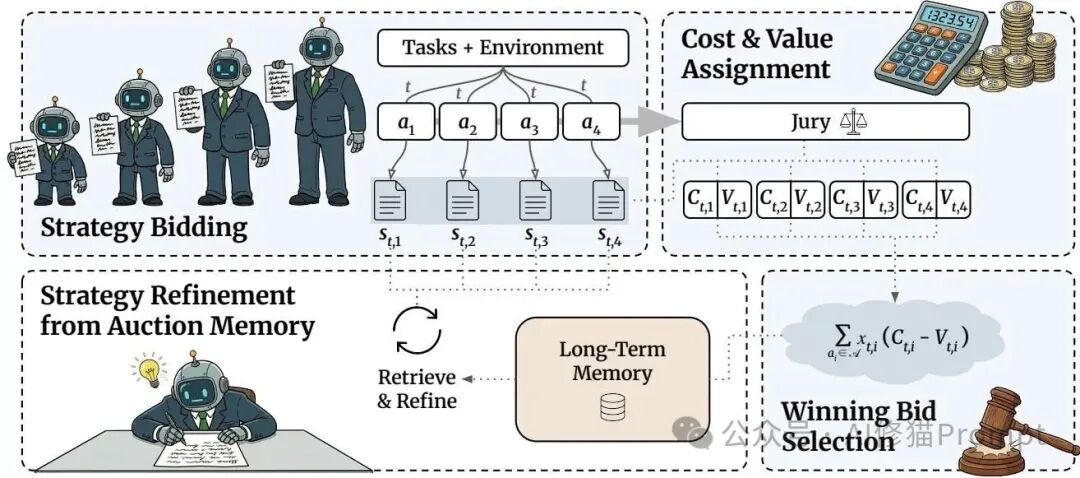
成本-价值的博弈方程
系统作为“雇主”,需要从这些标书中挑出一个赢家。评价标准不是简单的“谁绝对能力最强”,而是“谁的性价比最高”。在原论文中,系统旨在寻找一个最优的分配对象 î(t),其核心目标是最小化“成本减去价值(Cost-minus-value)”的差值。
î(t) = { arg min (C_t,i - V_t,i) if any refined bid satisfies C_t,i - V_t,i < C_t,î(t) - V_t,î(t),
i: π(a_i) < π(a_î(t))
î(t) otherwise.
我们需要深入拆解 C 和 V 这两项,因为它们蕴含了该框架设计的核心智慧。
成本项 (Cost)
C_t,i = w_c · π(a_i) · |s_t,i|
其中 π(a_i) 是智能体的单位价格(显然4B比32B便宜),而 |s_t,i| 是它提交的“计划书”长度。为什么要惩罚“长计划”?研究者发现了一个很强的相关性:计划越长,最终执行的轨迹通常也越长。这意味着长计划预示着更高的执行成本和更高的出错概率(每多一步就多一份风险)。因此,SALE倾向于选择那些能用最简洁方案解决问题的智能体。
价值项 (Value)
V_t,i = w_h · H(s_t,i) + Σ w_j · γ_j(s_t,i), a_j ∈ A
价值由两部分组成:
- 熵 (Entropy, H): 这里指的是生成计划时的Token平均熵。在信息论视角下,较高的熵往往意味着生成的内容包含更多信息量,而非简单的重复或套话。实验表明,高熵的计划往往对应着更好的推理质量。
- 陪审团打分 (Jury Score, γ): 这是最精彩的部分。系统会让所有智能体(包括竞标者自己)组成一个“评审团”,对所有提交的计划书进行0-5分的打分。这相当于让一群同行互评方案。即便是一个4B的小模型,虽然它自己可能写不出完美的复杂代码,但它往往能识别出什么是“好的思路”。这种“群体智能”(Collective Intelligence)被证明比单一的强力打分器更准确、更鲁棒。
系统通过学习权重 w,在“省钱”和“保质量”之间寻找最佳平衡点,最终选出那个 C - V 最小(即性价比最高)的智能体去真正执行任务。
进化的秘密:记忆驱动的策略精炼
如果SALE仅仅停留在上述的“静态竞标”,它充其量只是一个更复杂的路由器。但它真正的杀手锏在于 动态进化。
想象一下,一个初级程序员(4B Agent)和一个资深架构师(32B Agent)同时竞标。初级程序员的方案很粗糙,输了。但在SALE系统中,这次失败不会被浪费。系统维护了一个 Auction Memory(拍卖记忆库),存储了过去所有任务的获胜计划和失败计划。
当一个新的任务到来,如果4B智能体提交的初稿在竞标中输给了更贵的32B智能体(即发生了“更贵模型暂时胜出”的情况),系统会给4B智能体一个“补考”的机会:
- 检索 (Retrieval): 系统从记忆库中找出几个和当前任务相似的历史任务。
- 对比 (Contrast): 把这些历史任务中的“获胜计划”(往往出自32B之手)和“失败计划”一起展示给4B智能体看。
- 精炼 (Refinement): 4B智能体收到提示:“看,这是之前高手赢的方案,那是输掉的方案。你参考一下,把你的方案改一改。”
这是一种在测试时自我改进(Test-time Self-improvement)的机制,或者说是在线上下文学习(In-context Learning)的高级应用。小模型在推理阶段,通过“观摩学习”大模型的历史优胜方案,实时地重写了自己的标书。如果重写后的方案质量(价值 V)大幅提升,甚至超过了32B智能体的方案(考虑到4B的成本优势,只要质量接近,C - V 值就能反超),那么4B就会成功“抢单”。
这改变了一切。 随着系统运行时间的增长,记忆库越来越丰富,小模型见过的“世面”越来越多。数据显示,在运行初期,4B智能体的抢单成功率很低;但随着时间推移,它的累积被选中率呈现出一条漂亮的昂扬曲线,增长了 3-4倍。
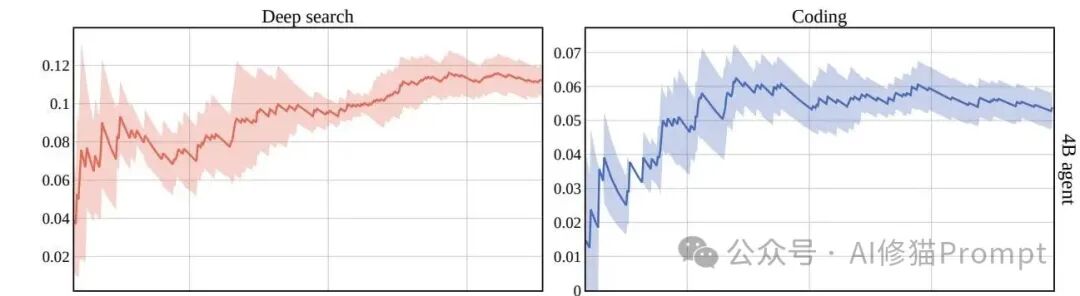
这意味着,系统在 不更新任何模型参数 的情况下,随着处理任务的增多,变得越来越聪明,越来越省钱。这不仅是动态路由,更是一种进化。
实战效果:打破Pareto边界
一切理论终究要靠数据说话。在Deep Search和Coding两大领域的全量测试中,SALE交出了一份令人满意的答卷。我们通常用帕累托前沿(Pareto Frontier)来衡量性能与成本的权衡。理想的系统应该在同一成本下性能最高,或在同一性能下成本最低。
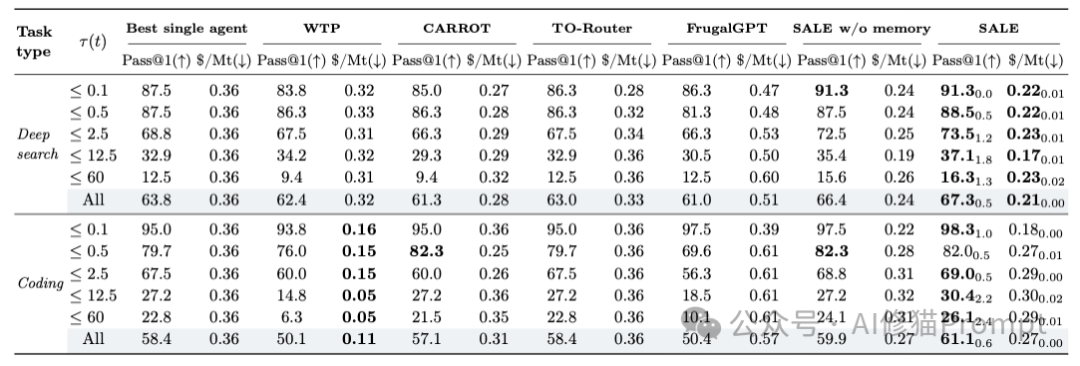
实验结果显示,SALE彻底突破了单一模型的帕累托边界:
- Deep Search: 相比最强的单一智能体(32B),SALE将总成本降低了 42%,并且这不是通过牺牲性能换来的,因为Pass@1准确率还提升了 3.5%。在低复杂度区间,它更是实现了 39% 的降本和 3.8% 的提效。
- Coding: 在代码任务上,大模型的优势通常难以撼动,但SALE依然减少了 25% 的成本,并将Pass@1提升了 2.7%。
更深入的夏普利值(Shapley Value)分析揭示了一个反直觉的结论:32B模型最大的贡献往往不是“干活”,而是“当评委”。分析显示,即使在不直接执行任务时,32B模型对系统的边际贡献依然最高。为什么?因为它在陪审团(Jury)里的打分最准。系统利用32B的高智商来精准鉴别策略的好坏,然后放心地把执行任务派给性价比更高的小模型。这意味着,大模型在生态中扮演了“架构师”或“代码审查员”的关键角色,而不仅仅是执行者。
还有,对路由决策的诊断分析揭示了SALE的 极度“保守”偏好。系统几乎从不犯“降级错误”(即把大模型能做对的题错误地交给做不对的小模型),绝大多数错误是“过度升级”(即杀鸡用了牛刀)。这种“宁可多花钱也不让任务失败”的特质,对于追求高可靠性的工程落地来说,是一个极大的安全优势。
大模型的傲慢与小模型的务实
为什么SALE能在某些任务上胜过单纯使用32B模型?难道4B比32B还强?定性分析揭示了有趣的现象。大模型有时会表现出一种“傲慢”:

- 过度设计 (Over-engineering): 把简单问题复杂化。比如一个简单的字符串元组转换任务,32B可能会规划一个复杂的嵌套递归转换,结果反而引入了Bug。
- 幻觉依赖: 在需要搜索时,大模型有时会过于自信地依赖其参数化知识(Parametric Knowledge),导致引用了过时或错误的信息,而不是老老实实调用搜索工具。
相比之下,小模型往往更加“务实”和“听话”。它们倾向于老老实实地调用工具,一步一步执行。这种“性格差异”导致了失败模式(Failure Modes)的互补性。SALE的拍卖机制,实际上是在利用这种互补性,当大模型试图“炫技”而导致计划过于复杂(成本 C 变高)时,小模型朴实无华的短计划往往能以更高的性价比胜出。
结语
《Scaling Small Agents Through Strategy Auctions》这篇论文给我们的启示远不止于一个具体的算法。它向我们展示了AI Agent未来的一个可能图景:并不是所有的智能都要来自于单一的超级模型。
通过引入市场机制(拍卖)、博弈论(成本价值博弈)和群体进化(记忆驱动的精炼),我们可以构建一个 异构的、自我调节的智能体生态系统。在这个生态中,大模型不再是垄断者,而是成为了教导者(通过记忆库)和最后防线;小模型也不再是鸡肋,而是通过持续学习和协作,成为了处理海量中低难度任务的中坚力量。
如果你正在构建需要Transformer架构驱动的AI应用,这或许是一个比“微调一个巨型模型”更具可行性和经济性的探索方向:搭建一个包含大、中、小模型的“混合舰队”,并建立一套基于实时反馈的动态路由协议,让你的系统在每一次任务执行中都能自我进化。在这个智能体的自由职业市场里,没有永远的赢家,只有当时当下最适合的解决方案。更多关于人工智能和成本优化的前沿讨论,欢迎在云栈社区继续交流。
 发表于 2026-2-12 08:56:13
|
查看: 164|
回复: 0
发表于 2026-2-12 08:56:13
|
查看: 164|
回复: 0
