

在大型语言模型的推理过程中,如何从庞大的词表中挑选出下一个合适的词,是生成文本多样性与可控性的关键。这个过程的核心便是采样。本文将深入解析LLM推理中常见的采样机制,涵盖随机采样与确定性采样两大类别,并详细解读Temperature、Top-k、Top-p、惩罚以及Beam Search等核心概念与技术原理。
推理采样的基本概念
什么是采样?
当前,大语言模型生成文本的核心机制是自回归,即“词语接龙”。例如,输入提示词“我爱”,模型会预测后续可能出现的词,如“你”、“她”、“他”。模型在接收到输入序列后,经过主干网络和解码层处理,会输出一个与词表大小相等的概率数组。采样就是依据此概率分布,从词表中选取下一个词的过程。
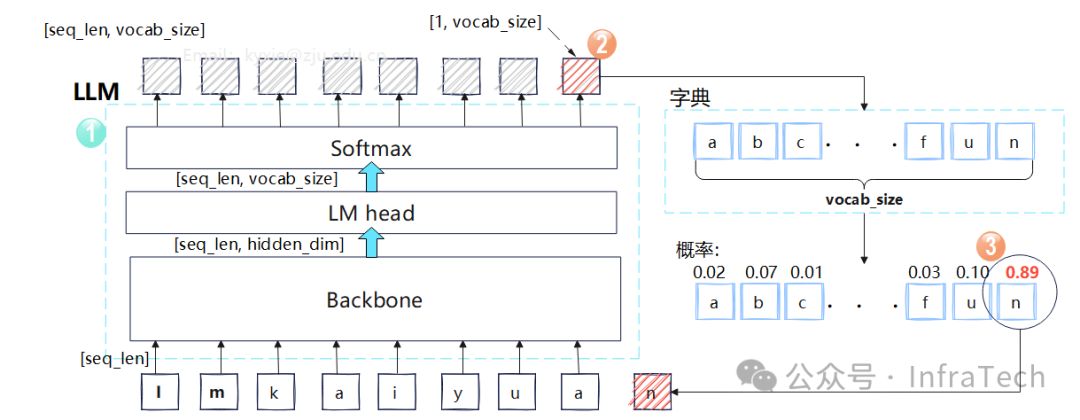
为何需要调整采样过程?
最直接的方式是每轮都选择概率最高的词,即贪心策略。但这会使模型输出缺乏多样性,变得千篇一律。因此,需要通过调整采样策略,在连贯性、准确性与创造性之间取得平衡。
常见的采样方式有哪些?
- 随机采样:在一定条件下筛选出高概率候选词,然后随机挑选一个作为输出。
- 贪心搜索:每轮都挑选概率最大值作为输出。
- 束搜索:每一步保留多个候选结果,多步后选择累积概率最大的一组序列。
- 结构化采样:按照预定的格式(如填空“周__”)限制输出范围。
随机采样详解
随机采样并非完全随机,而是有条件的随机,旨在避免因过度随机导致的输出混乱。常见做法是进行权重采样,将模型输出的logits分数作为权重。为了获得更合理、丰富的输出,通常会引入一系列操作来调整logits值。
温度 (Temperature)
温度参数用于调节logits概率分布的平滑度。它基于吉布斯分布,通过一个温度系数T来缩放softmax函数的输入。
标准softmax计算为:softmax(x_i) = exp(x_i) / Σ_j exp(x_j)
引入温度T后变为:softmax(x_i / T) = exp(x_i / T) / Σ_j exp(x_j / T)
- 低温 (0 < T < 1):概率分布变得“尖锐”,高概率与低概率之间的差距被拉大,输出更可预测、连贯,但也可能变得重复。
- 高温 (T > 1):概率分布变得“平缓”,差距缩小,输出更具多样性和创造性,但连贯性和事实准确性可能下降。
举例而言,给定词表 [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’] 和原始logits [2.0, 1.0, 0.5, 0.1, -1.0, -2.0],不同温度处理下的概率分布对比如下:
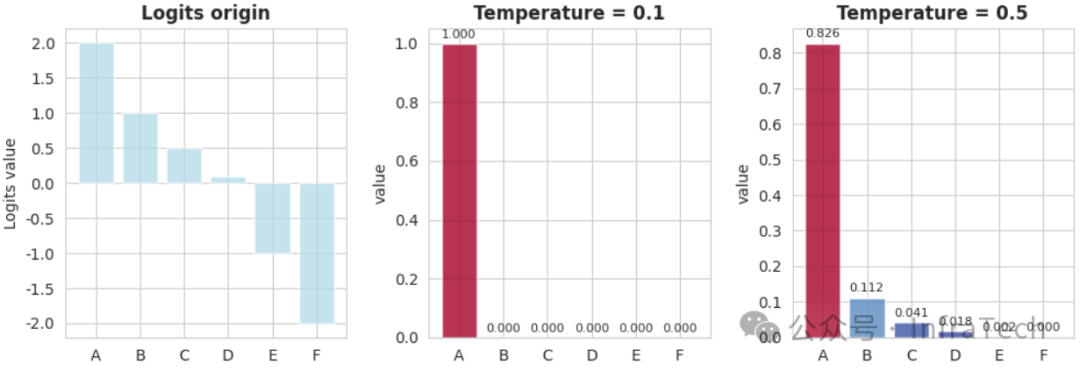 低温处理
低温处理
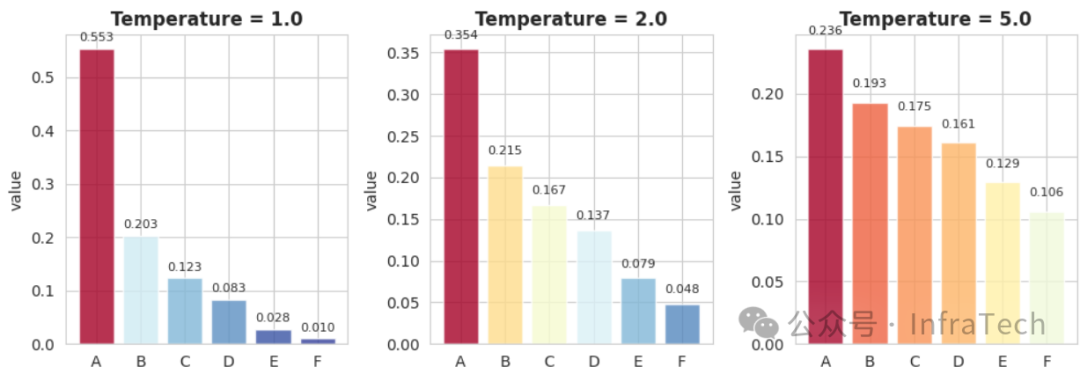 常温(T=1)与高温处理
常温(T=1)与高温处理
Top-k / Top-p / Min-p
为了缩小随机采样的范围、过滤掉低概率的“噪声”候选词,常采用以下过滤策略:
- Top-k:保留概率值最大的前k个候选词。
- Top-p (核采样):对概率从高到低排序并累加,保留累积概率达到p的最小候选词集合。
- Min-p:保留所有概率不低于最高概率一定比例(p倍)的候选词。
例如,词表为 [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’], logits为 [0.6, 0.3, 0.05, 0.03, 0.015, 0.005]:
- Top-k=4: 保留A, B, C, D →
[0.6, 0.3, 0.05, 0.03, 0, 0]
- Top-p=0.95: 累积概率达到0.95需A, B, C →
[0.6, 0.3, 0.05, 0, 0, 0]
- Min-p=0.5: 仅保留概率≥0.6*0.5=0.3的A和B →
[0.6, 0.3, 0, 0, 0, 0]
各自特点与局限:
- Top-k 可能包含概率绝对值仍很低的词。
- Top-p 在概率分布平缓时可能保留过多候选词。
- Min-p 在概率分布悬殊时可能过滤过严。
因此,在实际的LLM推理中,这些策略常常混合使用,以达到最佳效果。
惩罚 (Penalty)
惩罚机制通过对历史已生成词对应的logits值进行缩放,来抑制模型出现循环、重复、冗余等不良输出,是一种局部调整策略。
常见惩罚方式包括:
- 频率惩罚 (frequency penalty):根据词的出现频率降低其logits值,出现越频繁,惩罚越重。
- 存在惩罚 (presence penalty):对出现过的词,统一减去一个固定惩罚值,每个词仅惩罚一次。
- 重复惩罚 (repetition penalty):对重复出现的词进行衰减。
其计算方式通常如下(以第i个词为例,count为其出现次数):
logits[i] -= frequency_penalty × countlogits[i] -= presence_penalty- 当
logits[i] > 0: logits[i] /= (repetition_penalty ** (count - 1))
- 当
logits[i] < 0: logits[i] *= (repetition_penalty ** (count - 1))
操作顺序
除了温度与惩罚,还有偏置(bias)、掩膜(mask)等操作可以修改logits。这些操作的执行顺序会直接影响最终采样结果。通常,温度缩放应在softmax之前进行,而Top-k、Top-p、Min-p等过滤操作的顺序则可调整。一个典型的、用PyTorch风格伪代码表示的采样处理流程如下:
# 伪代码,供参考:
# 1. 惩罚处理
penalizer(logits)
# 2. 添加偏置值
logits.add_(self.logit_bias)
# 3. 温度处理
logits.div_(temperature)
# 4. softmax 计算,得到概率分布
probs = torch.softmax(logits, dim=-1)
# 5. 对概率进行排序和累积
probs_sort, probs_idx = probs.sort(dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
# 6. Top-k 过滤
probs_sort[torch.arange(0, probs.shape[-1]).view(1, -1) >= top_k.view(-1, 1)] = 0.0
# 7. Top-p 过滤
probs_sort[(probs_sum - probs_sort) > top_p.view(-1, 1)] = 0.0
# 8. Min-p 过滤
min_p_thresholds = probs_sort[:, 0] * min_p
probs_sort[probs_sort < min_p_thresholds.view(-1, 1)] = 0.0
# 9. 权重采样(多项式采样)
sampled_index = torch.multinomial(probs_sort, num_samples=1)
开发者常使用Python及其深度学习框架来实现此类复杂的采样逻辑。
确定性采样详解
与追求多样性的随机采样相对,在机器翻译、摘要生成等追求准确性的场景中,更需要确定性采样,其目标是找到全局概率最大的输出序列。
贪心搜索
贪心搜索是最简单的确定性采样,每一步都选择当前概率最高的词。但它只能保证单步最优,无法保证多步的累积概率最大。
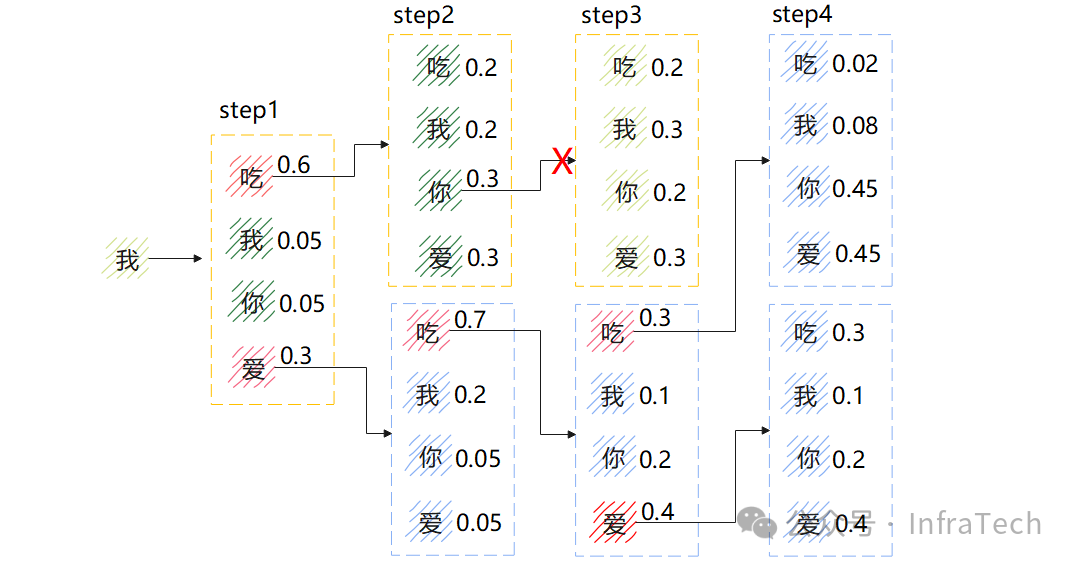
如图所示,第一步选择“吃”(0.6),第二步选择“你”(0.3),累积概率为0.18。而如果第一步选择“爱”(0.3),第二步选择“吃”(0.7),累积概率可达0.21,优于贪心搜索结果。
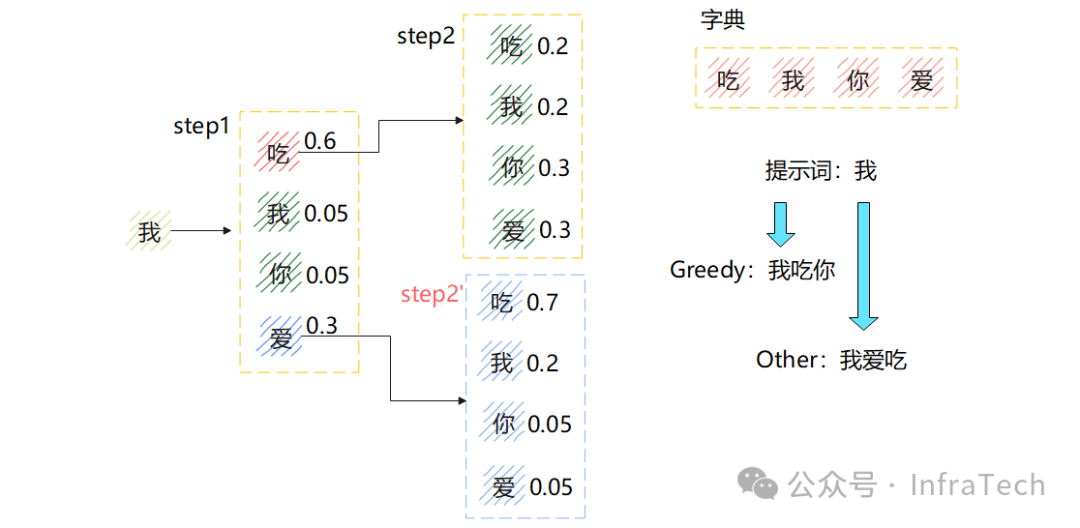
问题建模与束搜索
寻找全局最优序列是一个在巨大搜索空间中(词表大小n,生成长度k,路径数为n^k)寻找最优路径的问题。暴力搜索不可行,因此需要对搜索空间进行压缩。
- 将每一步的候选路径数
n_i压缩为1,即为贪心搜索。
- 将每一步的候选路径数
n_i压缩为一个固定值k,即为束搜索。
束搜索结合了Top-k和剪枝思想,其基本步骤为:
- 初始化:对首词输出进行Top-k排序,保留前k个候选(束宽为k)。
- 扩展:基于上一轮的k个候选序列,分别生成下一个词的Top-k候选,得到k*k个新序列,计算其累积概率。
- 剪枝:从所有候选序列中,选择累积概率最高的k个保留。
- 终止:重复步骤2-3,直到所有k个序列都遇到终止符,最终选择累积概率最高的序列作为输出。
束搜索的不足与改进:
由于概率值小于1,序列越长,累积概率乘积通常越小,导致束搜索倾向于生成更短的序列。为解决此问题,引入了长度惩罚:
调整后分数 = 累积对数概率 / (序列长度 ** length_penalty)
当length_penalty < 1时,会对短序列进行更强的惩罚,从而鼓励生成长度更合理的输出。此外,还可通过min_new_tokens、max_new_tokens等参数直接控制生成长度。
总结
本文系统梳理了LLM推理中的核心采样技术,回答了以下关键问题:
- 采样的本质是什么?—— 基于概率分布选择下一个词的自回归过程。
- 为何要调整采样?—— 平衡输出的确定性、多样性与创造性。
- 随机采样有哪些关键参数?—— Temperature调节平滑度,Top-k/p/Min-p用于过滤,Penalty抑制重复。
- 确定性采样如何工作?—— 贪心搜索单步最优,束搜索通过束宽k在计算成本与结果质量间折中,并通过长度惩罚改善短序列偏好问题。
理解这些基础采样机制,是有效使用和调优大语言模型的必经之路。对于希望深入AI和LLM领域的技术人员而言,掌握从Temperature到Beam Search的这些核心概念,是构建更可控、高质量文本生成应用的基础。
 发表于 2025-12-5 16:22:19
|
查看: 175|
回复: 0
发表于 2025-12-5 16:22:19
|
查看: 175|
回复: 0
