来源:DeepHub IMBA
RAG系统找到了看似完美的文档,精心设计的提示词也准备就绪,但大语言模型(LLM)仍在“一本正经地胡说八道”。更令人沮丧的是,有时添加的文档越多,回复质量反而越差。
问题的根源往往不在提示词,而在上下文。提示工程教导模型如何“说话”,而上下文工程(Context Engineering)则控制着模型在“说话时”能看到什么。这六种核心技术,正是区分原型演示与生产级系统的关键。
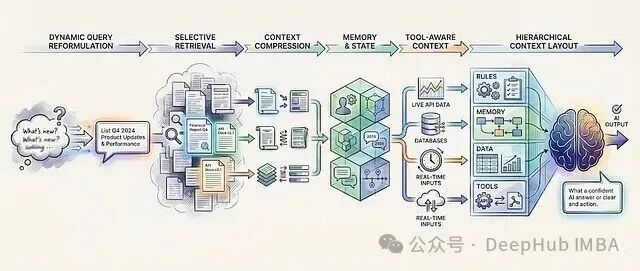
什么是 Context Engineering?
上下文工程是一种工程实践,其核心在于:在模型运行时,动态地决定让它看到什么信息、何时看到、以及以何种结构看到。
提示工程关注“如何提问”,而上下文工程关注“提供什么答案”。在实际系统中,LLM出错往往并非因为无法理解指令,而是因为它们被灌输了太多无关信息、相互矛盾的数据,或者缺失了关键事实。上下文工程将上下文视为一个动态处理管道,而不是一段静态文本,它专注于:
- 选择性检索:精心挑选文档,而非全量灌入。
- 内容压缩:将长文档提炼为面向特定任务的摘要。
- 查询优化:在检索前重新表述模糊的用户问题。
- 记忆整合:跨会话注入用户状态和历史记忆。
- 实时数据锚定:利用工具和API提供最新事实。
- 信息结构化:组织所有输入,引导模型关注重点。
简而言之,上下文工程是生产环境中控制模型注意力的关键手段。做得好,较小的模型也能表现出色;做得差,再强大的模型也难免产生幻觉。
1. 选择性检索:别再把什么都往里塞
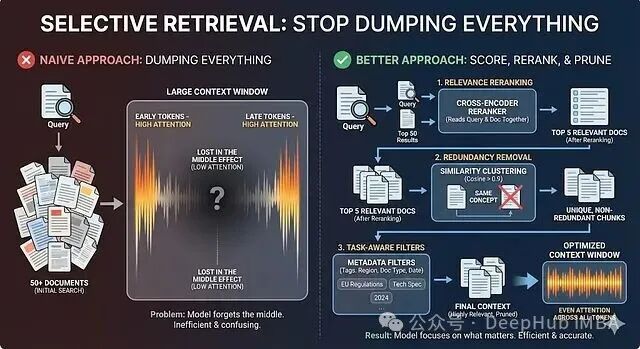
一种常见的误区是:将50个相关文档全部塞进上下文,指望模型自行筛选。即便上下文窗口足够大,模型的注意力分布也并非均匀。它会倾向于关注开头和结尾的Token,而忽略中间部分,这就是所谓的“中间丢失”(Lost-in-the-Middle)效应。
正确的做法是进行评分、重排与裁剪,只让最相关且不重复的内容进入上下文。这通常是一个三步走的逐层过滤流程:
- 相关性重排(Relevance Reranking):初始的向量相似度或关键词搜索可能返回前50个结果,但“相似”不等于“相关”。使用交叉编码器(Cross-Encoder),将查询和每个文档联合编码进行精细评分,重新排序。虽然速度较慢,但准确率显著提升,最终只保留排名最靠前的几个(例如前5个)。
- 冗余消除(Redundancy Removal):同一个事实可能在知识库中以不同形式出现多次。通过计算文本块嵌入(Embedding)的余弦相似度进行聚类,剔除高度重复(如相似度>0.9)的内容,确保模型不会看到同一事实的多个副本。
- 任务感知过滤(Task-aware Filtering):利用文档的元数据进行筛选。为文档打上标签(如文档类型、更新日期、产品版本、适用地区),在检索时根据查询上下文应用这些过滤器。
案例分析:用户查询“总结最新的退款政策变更”。
- 过滤前:向量搜索返回50个关于“退款”的文本块,其中混杂着2018年的旧政策、其他公司的文档、内部备忘录。LLM看到了相互矛盾的退款窗口期和排除条款,试图综合后,很可能幻觉出一条不存在的政策。
- 过滤后:应用
region=’CN’ 和 updated_at >= ‘2025-01-01’ 条件,先排除40个不相关文本。剩余10个用交叉编码器重排,保留前5个,再通过去重最终剩下3个高相关、无冗余的最新政策文本。
LLM现在看到的是清晰、一致且最新的信息,幻觉自然消失。
效果与落地:移除噪声上下文后,准确率通常能提升15-30%,同时Token消耗降低20-40%。更重要的是,这带来了可追溯性——你知道模型看到了什么,调试才有依据。可以从最简单的为文档添加“最后更新日期”并依此过滤开始,逐步叠加重排和去重模块。
2. 上下文压缩:让每个 Token 都有价值
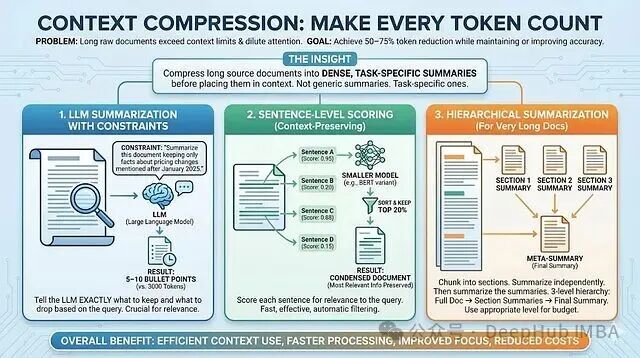
原始长文档不仅容易撑破上下文限制,还会稀释模型的注意力。研究表明,通过压缩,可以在保持甚至提升准确率的同时,减少50-75%的Token使用。
核心思路是:在将长文档放入上下文前,将其压缩成面向当前任务的密集摘要,而非通用摘要。
三种压缩策略:
- 带约束的LLM摘要:指令需具体,例如“总结此文档,仅保留2025年1月之后提及的定价变更事实”。这明确告诉LLM保留和丢弃什么。一个3000 Token的文档可被压缩为5-10个要点。
- 句子级评分(上下文保留压缩):使用较小的模型(如BERT变体)为文档中每个句子计算其与查询的相关性得分,仅保留得分最高的前20%。这种方法快速、自动化,能保留最相关的信息。
- 层次化摘要:适用于超长文档。先将文档分块,为每个块生成独立摘要,然后再对这些摘要进行归纳,形成最终的元摘要。形成了“完整文档 → 分块摘要 → 最终摘要”的三级结构。
案例分析:查询“比较API文档中Plan A与Plan B的速率限制”。
一份30页的API文档中,仅2页涉及速率限制。检索系统返回了3个相关章节(共30页)。LLM摘要器收到指令:“仅提取Plan A和Plan B的速率限制与配额的具体数字,忽略认证、示例等其他内容。”
- 章节1摘要:“Plan A:1000次请求/小时,10,000次/天。Plan B:5000次请求/小时,50,000次/天。两者均允许1分钟内20%的突发流量。”(约100 Token)
- 章节2摘要:“速率限制错误返回HTTP 429。Retry-After头部指示等待时间。限制在UTC午夜重置。”
- 章节3摘要:“企业版可定制速率限制。请联系销售。”
最终,模型看到的是总计约500 Token的聚焦信息,而非需要在30页中大海捞针。
权衡:压缩需要额外的LLM调用,会增加延迟。但当单个文档超过2000 Token时,在最终生成调用中节省的Token成本通常能覆盖这部分开销。
3. 层次化布局:结构本身就在传达重要性
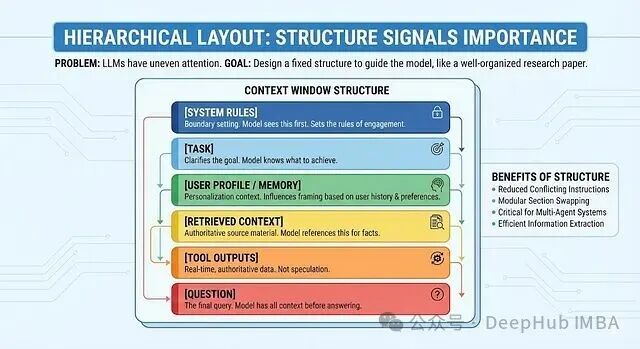
避免将所有信息混成一段“文字墙”。LLM对上下文不同位置的注意力分配不均,结构化的分区能帮助它清晰地区分指令、数据和问题。
想象一篇研究论文:摘要、引言、方法、讨论,结构清晰,易于理解。LLM同样受益于这种结构。我们可以设计一个固定的上下文布局:
[System Rules]
You are a precise financial research assistant.
Answer only from provided context.
If information is missing, say "I don‘t have that information."
Never make assumptions about numerical data.
[Task]
Goal: Answer user question using context below.
Output format: Start with direct answer, then provide supporting details.
[User Profile / Memory]
- Risk tolerance: Low
- Investment horizon: 5-10 years
- Region: India
- Previous sessions: Asked about HDFC Bank 3 times, showed interest in banking sector
- Preferences: Conservative investments, dividend-paying stocks
[Retrieved Context]
DOC 1: HDFC Bank Q4 2024 earnings report
- Revenue: ₹45,000 crores (up 15% YoY)
- Net profit: ₹12,000 crores (up 18% YoY)
- NPA ratio: 1.2% (improved from 1.5%)
DOC 2: Competitor analysis Q4 2024
- ICICI Bank revenue growth: 12% YoY
- SBI profit growth: 10% YoY
- HDFC Bank leading in digital banking adoption
[Tool Outputs]
- live_price("HDFCBANK"): ₹1,842.50 (updated 2 minutes ago)
- news_summary("HDFCBANK"): "Announced dividend of ₹19 per share for FY2024. Ex-dividend date March 15, 2025."
- sector_analysis("Banking"): "Banking sector up 8% this month due to positive earnings"
[Question]
User: What‘s the latest on HDFC Bank?
布局解析:
- 系统规则 置顶,设定行为边界。
- 任务说明 紧随其后,明确目标。
- 用户档案/记忆 提供个性化背景。
- 检索上下文 标记为权威来源。
- 工具输出 标记为实时、权威数据。
- 问题 放在最后,模型在知晓所有背景后才看到它。
优势:角色清晰,减少指令冲突,各部分可模块化替换。实验表明,相比非结构化上下文,这种分层布局在多数任务上能带来10-20%的准确率提升,因为它顺应了模型“关注开头和结尾”的注意力模式。
4. 动态查询重构:修复模糊问题
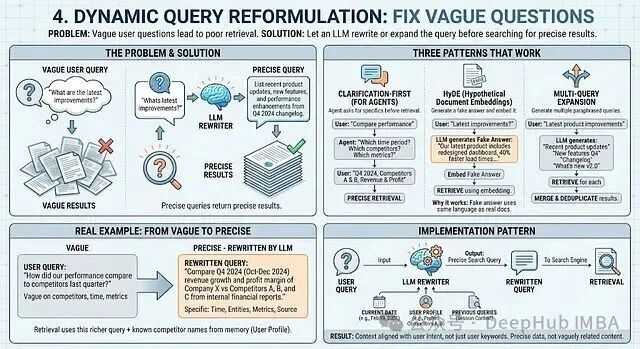
用户的提问往往是模糊的,缺少关键实体、时间范围或指标。直接使用原始查询进行检索,效果通常不佳。解决方案是:在检索前,先用一个LLM对查询进行重写或扩展。
核心逻辑很简单:模糊的查询返回模糊的结果,精确的查询返回精确的结果。
三种有效模式:
- 澄清优先(适用于智能体):对于多轮对话场景,智能体可以直接询问缺失信息(如“您想比较哪个时间段的业绩?哪些竞争对手?”)。用户通常愿意回答以换取更准确的答案。
- 假设文档嵌入(HyDE):让LLM根据原始查询生成一段“假设的”答案(例如,对于“最新改进”,生成“包括仪表板重设计、加载速度提升40%…”),然后将这段假答案进行向量化用于检索。因为假答案的语言风格与真实文档更接近,从而能检索到更相关的内容。
- 多查询扩展:将原始查询扩展为3-5个语义相近的变体(如“最新改进”扩展为“近期产品更新”、“新功能发布”、“版本变更日志”),分别检索后合并去重,以覆盖不同的表述方式。
案例分析:用户问“我们上季度表现和竞争对手比怎么样?”
这个问题缺失了关键信息:哪些竞争对手?哪个年度/季度?比较什么指标?
LLM重写器将其重构为:“比较公司X与竞争对手A、B、C在2024年第四季度(2024年10-12月)于内部财务报告中的收入增长和利润率。” 这个精确的查询,结合用户档案中已知的竞争对手偏好,能检索到高度相关的文档。
实现模式:
User query
↓
LLM rewriter: "Expand this into a precise search query. Add time ranges, entity names, and specific metrics."
↓
Rewritten query
↓
Retrieval
重写器需要访问当前日期、用户档案等信息来完成精确化。
5. 记忆与状态:保留的是关系,不只是事实
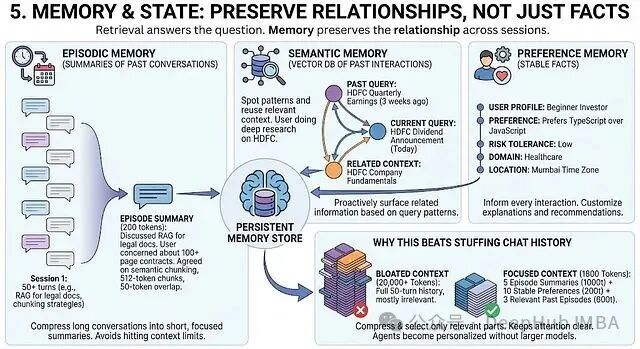
检索(Retrieval) 回答当前问题;记忆(Memory) 维系与用户的关系。检索是每次独立的,而记忆是跨会话持续的。
正确的做法是为智能体配备持久化记忆存储,在每轮对话中重新注入相关的记忆摘要,而不是不断增长、最终冗长不堪的聊天历史。
三种记忆类型:
- 情景记忆:过去对话的压缩摘要。例如:“上次会话讨论了为法律文档构建RAG,用户关心如何处理百页合同,最终决定采用512 Token分块和50 Token重叠策略。”(约200 Token)
- 语义记忆:存储在向量数据库中的过去交互。当新查询“HDFC股息公告”到来时,能关联起3周前的查询“HDFC季度收益”,从而主动提供相关背景。
- 偏好记忆:稳定的用户事实,如“初学者投资者”、“偏好TypeScript”、“低风险承受”、“在医疗行业工作”。这些信息持续影响每次交互的风格和建议。
为何优于完整聊天历史?
一场50轮的对话历史可能超过20,000 Token,且大部分无关当前问题。将其压缩为5个情景摘要(1000 Token)+ 10个稳定偏好(200 Token)+ 3个相关历史片段(600 Token),总计约1800 Token。信息密度更高,注意力更集中,智能体无需更大模型也能实现个性化。
落地步骤:
- 每轮对话后,生成LLM摘要并存入向量库。
- 每轮对话前,用当前查询在记忆摘要库中进行向量检索,取回最相关的几条。
- 从固定表中加载用户偏好。
- 将所有记忆内容插入层次化布局的
[User Profile / Memory] 区块。
6. 工具感知上下文:把答案锚定在现实中
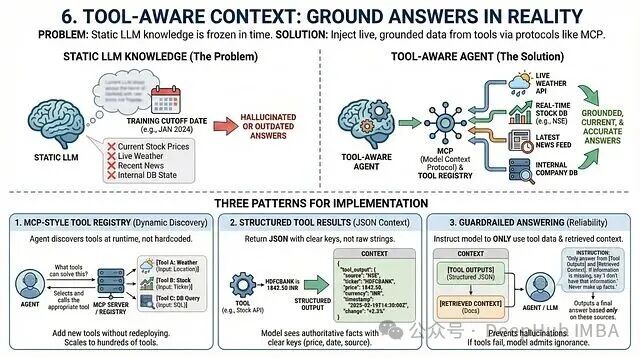
静态LLM的知识存在截止日期。通过 Model Context Protocol (MCP) 等协议和函数调用,可以将来自工具、API和数据库的实时、结构化数据注入上下文,从而大幅降低幻觉,保障答案的时效性。
关键模式:
- MCP风格工具注册:智能体在运行时动态发现可用工具(如天气API、股票查询),而非硬编码。新增工具时,只需在MCP服务器注册,无需重新部署智能体,易于扩展。
- 结构化工具结果:工具返回JSON格式的结构化数据,而非原始字符串。例如:
{"symbol": "AAPL", "price": 150.23, "timestamp": "2024-06-15T10:00:00Z"}。这被作为 [Tool Outputs] 区块插入上下文,模型将其视作权威事实。
- 带护栏的回答:在系统指令中明确要求:“仅基于
[Tool Outputs] 和 [Retrieved Context] 回答。若信息缺失,则说明‘当前数据中无此信息’。” 这防止了模型在工具调用失败时进行猜测。
案例分析:查询“HDFCBANK的最新股价和今日新闻”。
智能体通过MCP调用 get_live_price 和 get_news 工具,获得结构化响应:
{
"get_live_price": {
"symbol": "HDFCBANK",
"price": 1842.50,
"currency": "INR",
"timestamp": "2025-02-19T14:30:00Z",
"change": "+2.3%"
},
"get_news": {
"articles": [
{
"headline": "HDFC Bank Announces ₹19 Dividend",
"summary": "Board approves dividend of ₹19 per share for FY2024",
"date": "2025-02-19",
"source": "Economic Times"
}
]
}
}
这些数据被放入上下文,模型生成的答案基于这些确切数字,如“当前股价₹1,842.50,今日上涨2.3%。银行宣布FY2024每股派息₹19。”,无误且有时效性。
关键启示:模型表现优异,得益于工程化的、结构化的运行时上下文,而非一段完美的提示词。
决策框架:何时使用哪种技术?
- 选择性检索:当文档库庞大(>1000)、返回结果过多(>20)、上下文接近上限或需控制成本时使用。
- 上下文压缩:当单个文档很长(>5000 Token)、所需信息深埋其中、或按Token计费需优化成本时使用。短文档则可能不划算。
- 层次化布局:适用于多智能体系统、多种上下文来源并存、或需要分段调试时。单一来源的单轮问答可能不需要。
- 查询重构:适用于用户查询普遍模糊、存在专业术语鸿沟、或查询与文档用词差异大的场景。
- 记忆:适用于对话式智能体、跨会话回访、需要个性化、或对话轮数多导致历史溢出的场景。
- 工具感知上下文:当答案依赖实时数据、构建的是能采取行动的智能体、准确性取决于信息时效、或需极力降低幻觉时使用。
总结
每种技术都有其代价:重排消耗算力,压缩增加LLM调用,记忆需要存储,工具调用涉及API成本。工程师需要在收益与复杂度之间做出权衡。一个稍简单但成本可控的管道,有时比一个复杂10倍、昂贵10倍但仅有微弱优势的管道更为合适。
真正的智能,不仅源于模型的能力,更源于我们如何为它塑造所见的“世界”。上下文工程,正是塑造这个世界的关键手艺。在实践中,你可以从最简单的元数据过滤开始,逐步叠加这些技术,持续观察和优化你的RAG系统。
本文探讨的RAG与LLM优化是当前人工智能领域的热点,涉及Transformer架构、NLP等多个子方向。如果你在构建类似系统时遇到了其他挑战,欢迎到云栈社区与更多开发者交流探讨。
 发表于 2026-3-9 04:37:40
|
查看: 224|
回复: 0
发表于 2026-3-9 04:37:40
|
查看: 224|
回复: 0
