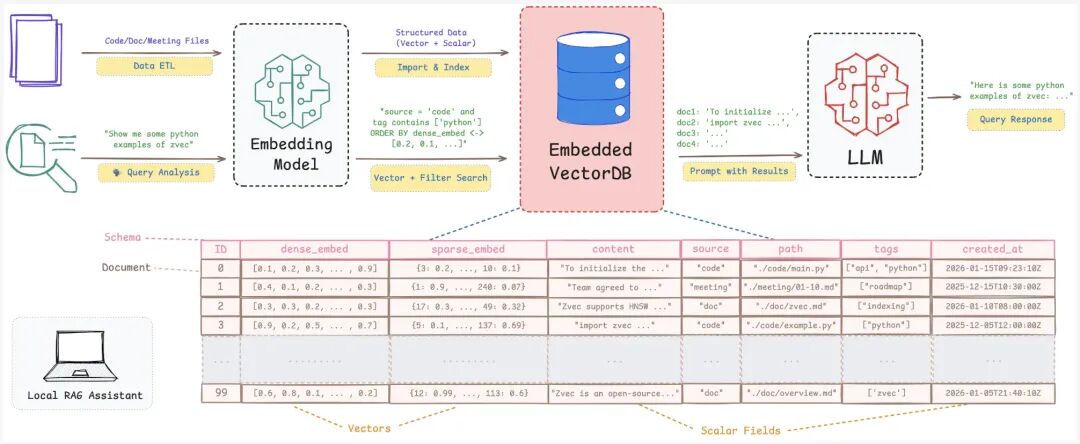
随着应用场景向设备端迁移,传统的云端向量数据库在隐私、成本和延迟方面面临挑战。有没有一款像 SQLite 一样轻便、高效的向量数据库,能在笔记本、移动设备等边缘环境中直接运行?阿里巴巴通义实验室给出的答案是 Zvec。
近日,该团队正式开源了进程内向量数据库 Zvec,它被广泛视为“向量数据库界的 SQLite”。其核心优势在于以库的形式直接嵌入应用程序内部,无需启动任何外部服务器,专为设备端 检索增强生成 等场景打造。
为什么需要嵌入式向量搜索?
在 RAG 和语义搜索的实际落地中,系统不仅需要高效的向量检索,还需同时处理标量字段,并支持完整的数据增删改查(CRUD)与可靠的持久化。本地知识库往往是动态变化的,传统的索引库(如 Faiss)缺乏对标量存储和一致性的原生支持,而服务型的向量数据库(如 Milvus)则因网络延迟和复杂部署,在端侧场景中显得过于笨重。
Zvec 正是为了填补这一空白而生。它提供了一个原生支持向量的嵌入式引擎,具备工业级的持久化能力,并以极简的 Python 库形式(pip install zvec)交付,让开发者能像使用本地文件一样轻松管理向量数据。
核心架构:进程内执行与向量原生存储
Zvec 的运行逻辑是完全嵌入式的。它在应用进程内直接执行,避免了 RPC 调用和跨进程通信的开销。其底层集成了阿里巴巴高性能矢量搜索引擎 Proxima 的核心能力,并进行了轻量化封装。
项目采用 Apache 2.0 协议开源,目前已全面适配 Linux (x86/ARM) 与 macOS (M系列芯片),支持 Python 3.10 及以上版本。核心设计目标明确:
- 进程内嵌入式执行:无服务端依赖,零运维部署。
- 向量原生索引和存储:深度优化,实现高效检索。
- 生产就绪的持久性和崩溃安全性:保障数据可靠性。
快速开始:从安装到检索
Zvec 的开发者体验非常简洁,大幅降低了构建本地 RAG 系统的门槛。以下是核心工作流示例:
- 安装:通过
pip install zvec 即可快速集成。
- 定义集合模式:灵活配置向量与标量字段。
- 创建集合:在本地路径建立持久化存储。
- 插入文档:将包含向量和元数据的文档加入集合。
- 执行查询:进行向量相似性搜索或混合搜索。
import zvec
# 1. 定义集合模式
schema = zvec.CollectionSchema(
name="example",
vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 4),
)
# 2. 创建并打开集合(持久化到磁盘)
collection = zvec.create_and_open(path="./zvec_example", schema=schema)
# 3. 插入文档
collection.insert([
zvec.Doc(id="doc_1", vectors={"embedding": [0.1, 0.2, 0.3, 0.4]}),
zvec.Doc(id="doc_2", vectors={"embedding": [0.2, 0.3, 0.4, 0.1]}),
])
# 4. 执行向量相似性查询
results = collection.query(
zvec.VectorQuery("embedding", vector=[0.4, 0.3, 0.3, 0.1]),
topk=10
)
# 结果:按相关性排序的文档列表,包含ID和相似度分数
print(results)
查询返回的结果列表可直接作为上下文提供给大语言模型(LLM),完成 RAG 流程。
性能表现:专为现代CPU优化
Zvec 针对现代 CPU 架构进行了深度优化,包括多线程并行、缓存友好内存布局及 SIMD 指令集利用。在 VectorDBBench 的标准测试(基于 Cohere 10M 数据集)中,Zvec 展现了出色的性能。
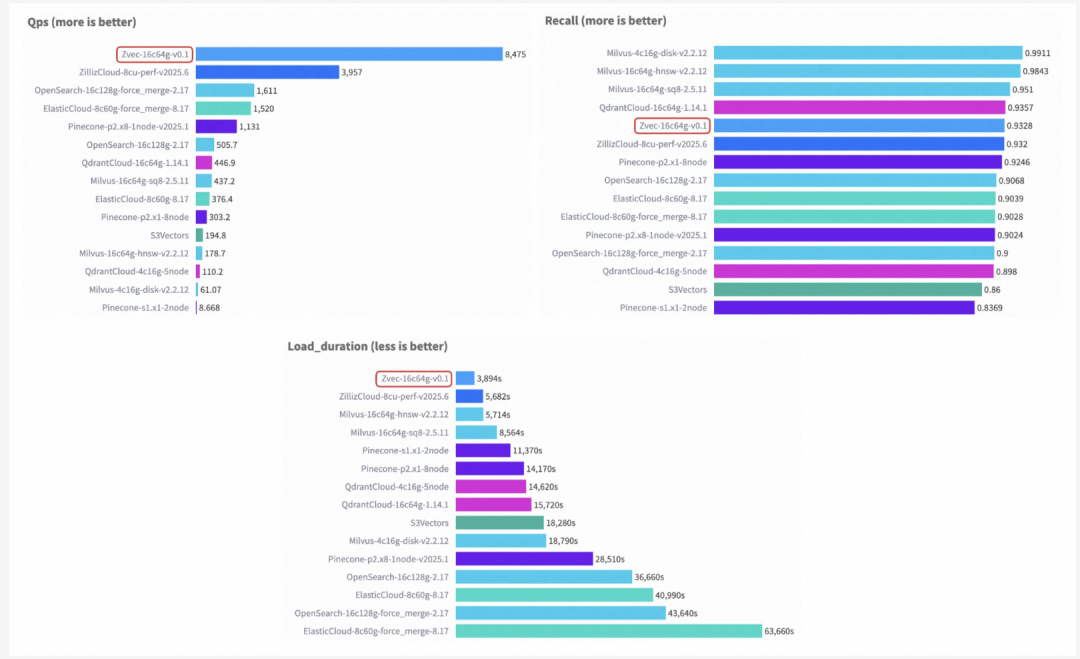
数据显示,Zvec 在查询吞吐量(QPS)上表现突出,同时在索引构建速度(Load_duration)上也极具优势,印证了其在边缘设备上高效运行的潜力。
进阶功能:为复杂智能体应用而生
为了满足更复杂的智能体(Agent)应用需求,Zvec 提供了丰富的增强功能:
- 混合搜索:支持在向量相似性搜索中无缝嵌入标量过滤条件(如
source='code' and tag contains ['python']),结合了语义检索和结构化查询的精准性。
- 排序融合:内置加权融合与 RRF(倒排秩融合)等算法,支持合并来自不同检索模型的多样化结果。
- 精细资源控制:支持设置内存使用上限(如
memory_limit_mb),确保在资源受限的边缘设备上稳定运行。
- 完整的 CRUD 操作:支持数据的实时增、删、改、查,适应动态变化的本地知识库。
总结
Zvec 作为一款开源的进程内 向量数据库,精准定位于边缘计算与设备端 AI 场景。它继承了 SQLite 的嵌入式哲学,为开发者提供了无需复杂运维、高性能、功能完备的向量数据管理方案。无论是构建本地化的知识库助手、离线语义搜索工具,还是为移动应用集成智能检索能力,Zvec 都提供了一个坚实且轻量的数据底座。对嵌入式AI和边缘RAG感兴趣的开发者,不妨到云栈社区的对应板块深入探讨其应用与实践。
 发表于 2026-2-12 11:35:12
|
查看: 306|
回复: 0
发表于 2026-2-12 11:35:12
|
查看: 306|
回复: 0
