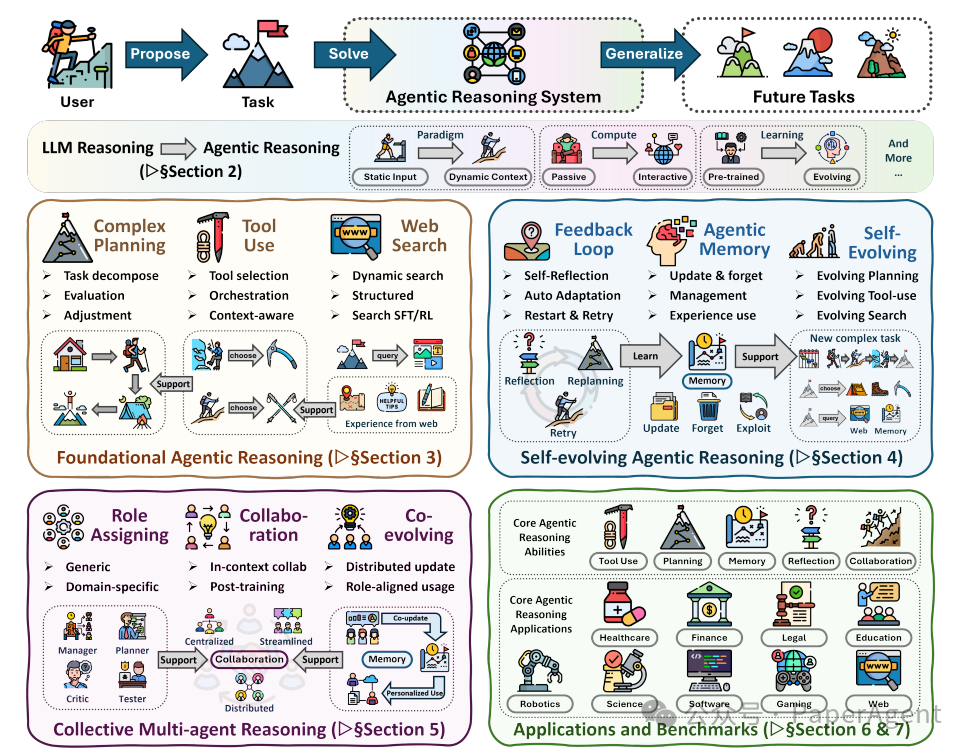
近年来,大语言模型(LLM)的能力边界不断拓展,但面对开放、动态的现实世界任务时,其被动、静态的推理模式仍显不足。为此,由谷歌、Meta、亚马逊等多所顶尖机构的研究者联合发布了一篇题为《Agentic Reasoning for Large Language Models》的综述论文,系统性地提出了 Agentic Reasoning(智能体推理) 这一全新范式,旨在将LLM从被动的文本生成器转变为能够主动规划、行动、学习的自主智能体。

一、为何需要 Agentic Reasoning?
传统的大模型推理在封闭世界问题(如数学、代码生成)上表现出色,但在开放、动态的环境中,它缺乏行动、适应、改进的核心能力。Agentic Reasoning 将推理重新定位为智能体的核心机制,其定义涵盖:
Agentic Reasoning 将推理定位为智能体的核心机制,涵盖:
- 基础能力: 规划、工具使用、搜索
- 自我进化: 反馈驱动、记忆增强的持续适应
- 集体智能: 多智能体协作与协调
可通过上下文编排或后训练优化实现
论文通过一张对比表清晰地揭示了LLM推理与Agentic Reasoning的本质区别:

二、三维框架:从个体到集体,从静态到进化
论文的核心贡献是提出了一个层次化的三维架构:
- 基础能力层(Foundational)→ 自我进化层(Self-Evolving)→ 集体协作层(Collective)
- 并贯穿两种优化模式:上下文推理(In-Context)与后训练优化(Post-Training)。
2.1 第一层:基础智能体推理(Foundational)
这是单智能体在相对稳定环境中的核心能力三角:
| 能力 |
关键机制 |
代表性方法 |
| 规划(Planning) |
任务分解、树搜索、工作流设计 |
ReAct, ToT, GoT, ReWOO |
| 工具使用(Tool Use) |
API调用、代码执行、外部系统交互 |
Toolformer, Gorilla, HuggingGPT |
| 搜索(Search) |
动态检索、知识图谱遍历、网络浏览 |
Self-RAG, DeepRAG, WebGPT |
规划能力的演进
规划是智能体推理的基石。如下图所示,规划主要分为上下文规划与后训练规划两大类。
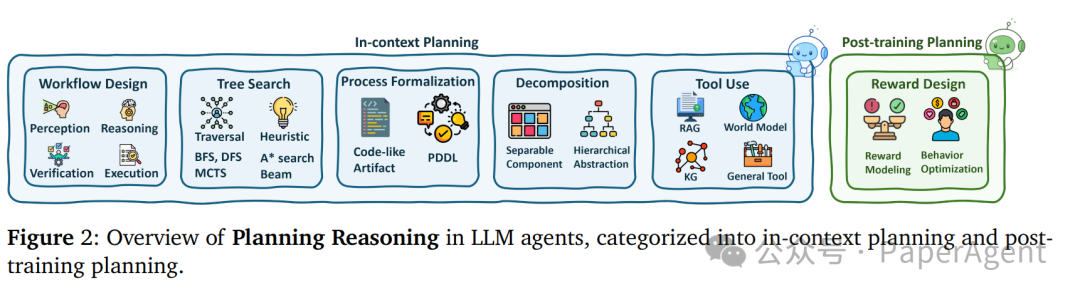
- 上下文规划(In-Context):通过提示工程让LLM在推理时生成计划。
- 工作流设计: 将任务分解为感知→推理→执行→验证的阶段。
- 树搜索: 模拟BFS/DFS/A*/MCTS等算法过程,探索不同的推理路径。
- 过程形式化: 使用PDDL(规划域定义语言)或代码来表示计划。
- 后训练规划(Post-Training):通过训练让模型内部学会规划。
- 奖励设计: 通过强化学习(Reinforcement Learning) 优化智能体的长期行为。
- 最优控制: 利用轨迹优化与扩散模型等技术生成高质量规划序列。
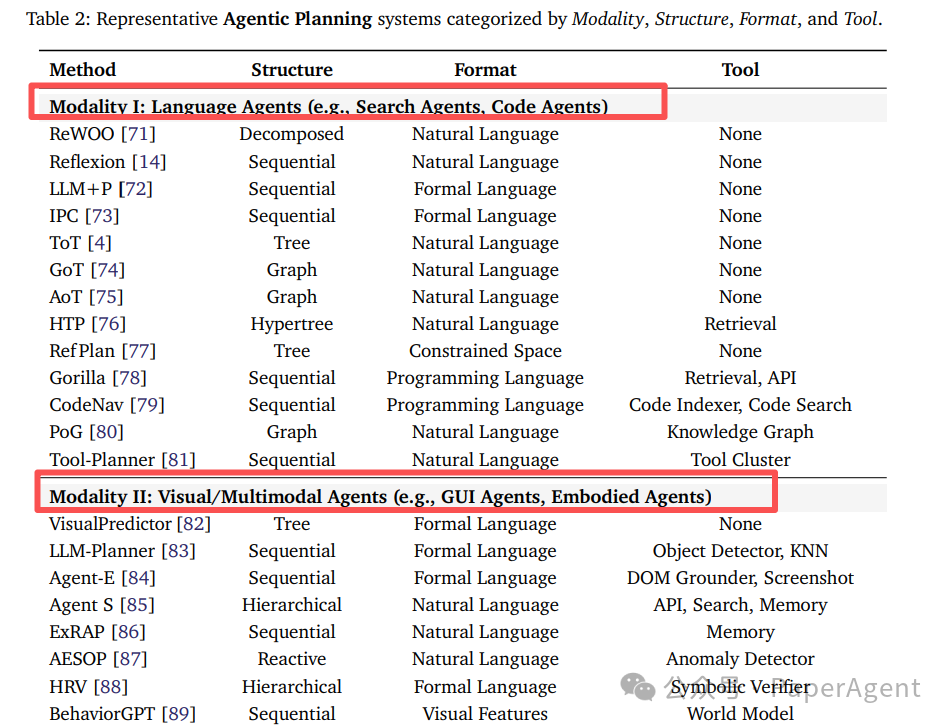
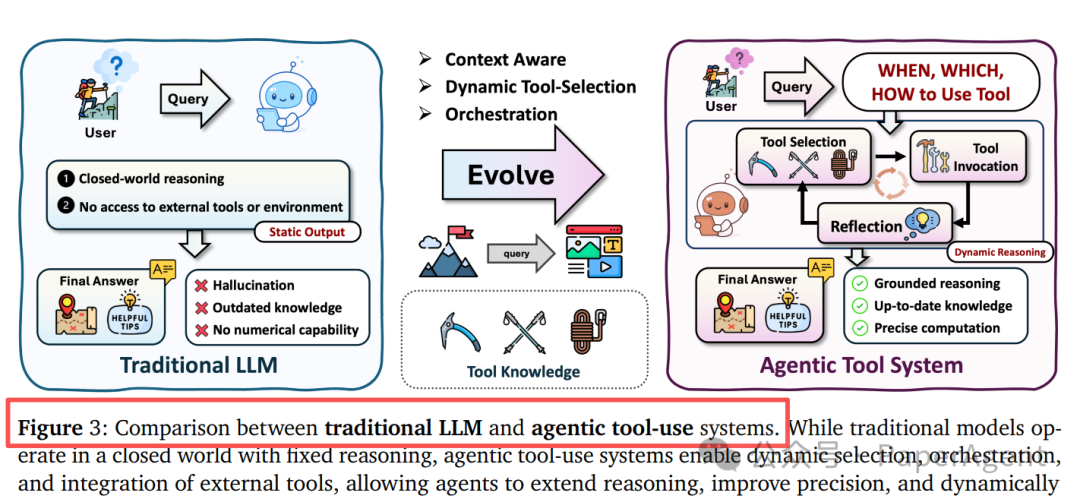
工具使用的三层架构
工具使用能力使智能体能够突破模型本身的限制。传统LLM与智能工具系统的对比如下:
| 集成方式 |
特点 |
代表工作 |
| 上下文集成 |
零样本提示、少样本示例 |
ReAct, ART, ChatCoT |
| 后训练集成 |
SFT/RL学习工具调用 |
Toolformer, ToolLLM, ToolRL |
| 编排式集成 |
多工具协调与依赖管理 |
HuggingGPT, OctoTools, ToolChain* |
Agentic搜索:从静态RAG到动态探索
传统的RAG(检索增强生成)依赖静态的向量数据库检索,而Agentic搜索引入了自主决策机制。
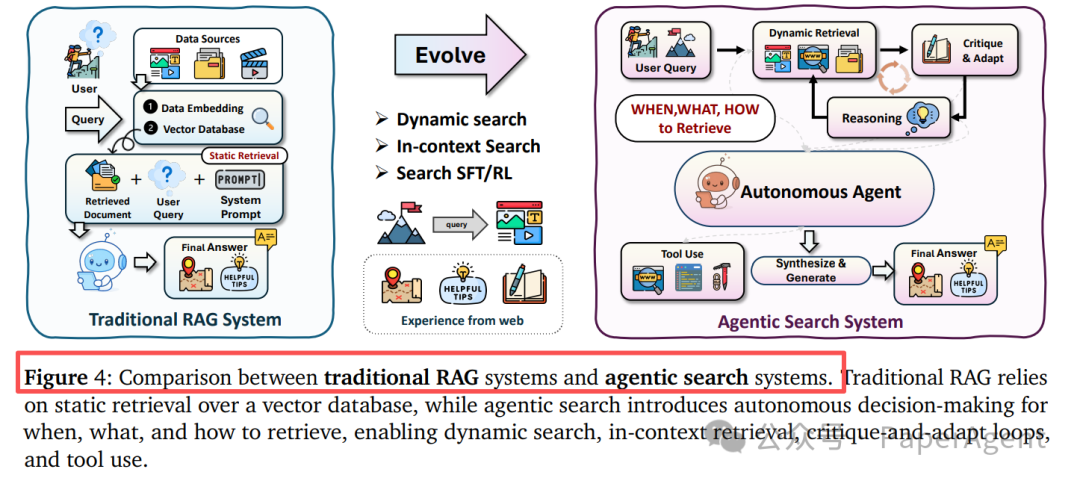
关键区别在于,智能体需要自主决定何时检索、检索什么、如何检索,并支持批判-适应循环,根据中间结果动态调整搜索策略,而非一次性检索后生成答案。
2.2 第二层:自我进化智能体推理(Self-Evolving)
这一层旨在解决核心问题:如何让智能体从经验中持续改进?
反馈机制的三重奏
反馈是智能体进化的燃料。论文总结了三种主要形式:
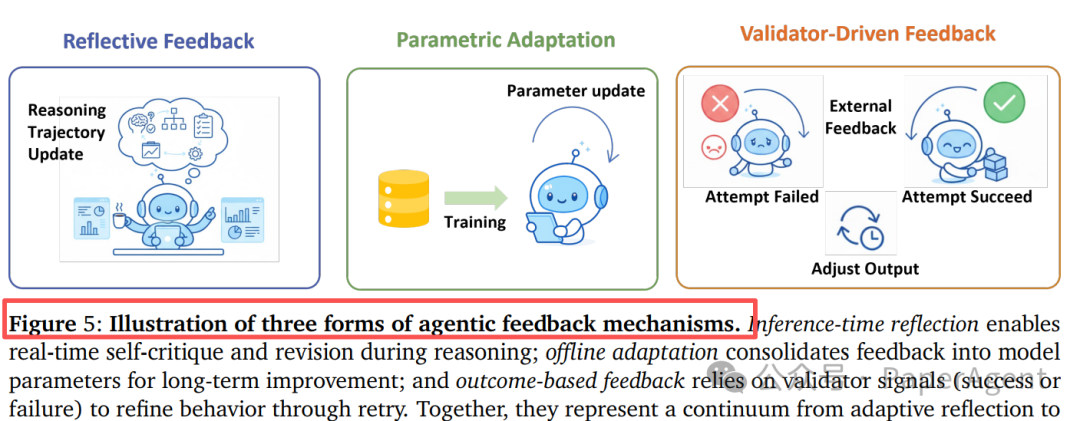
| 反馈类型 |
机制 |
更新目标 |
代表系统 |
| 反思性反馈 |
自批判+推理轨迹修正 |
推理路径 |
Reflexion, Self-Refine |
| 参数适应 |
训练数据整合 |
模型参数 |
AgentTuning, ReST, Distill-CoT |
| 验证器驱动 |
外部验证信号 |
输出选择 |
ReZero, CodeRL, SWE-bench |
智能体记忆:从存储到推理
记忆是智能体保持状态、积累经验的基础。Agentic Memory 的设计包含三个维度:
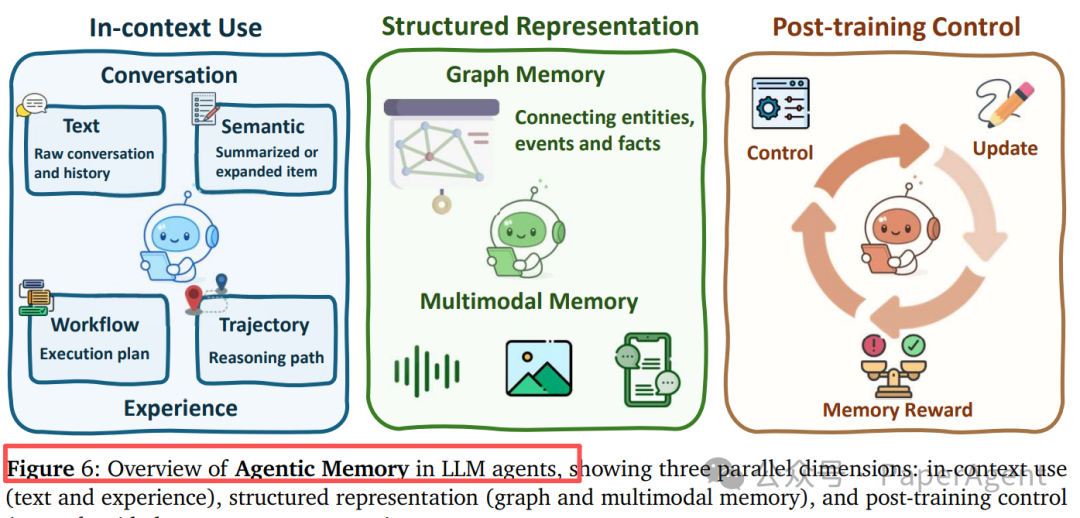
| 维度 |
形式 |
功能 |
| 上下文使用 |
对话历史、工作流、轨迹 |
即时上下文增强 |
| 结构化表示 |
知识图谱、多模态记忆 |
关系推理与跨模态关联 |
| 后训练控制 |
RL优化的记忆管理 |
动态更新与遗忘决策 |
该领域的关键进展包括:
- GraphRAG/MEM0: 利用图结构记忆实现复杂多跳推理。
- Memory-R1: 采用双智能体设计(记忆管理器+回答智能体)。
- Memory-as-Action: 将记忆的编辑与存储直接纳入智能体的行动策略。
进化中的基础能力
在反馈与记忆的驱动下,智能体的规划、工具使用和搜索等基础能力也能不断进化。
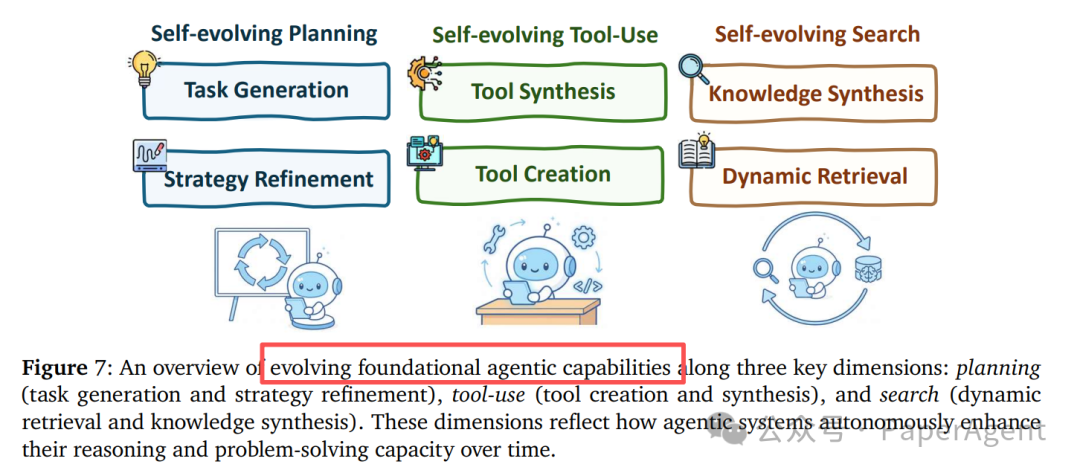
| 能力 |
进化形式 |
| 规划进化 |
任务自动生成、策略精炼(SCA, Self-Rewarding, RAGEN) |
| 工具进化 |
工具合成与创造(LATM, CRAFT, ToolMaker) |
| 搜索进化 |
知识合成、动态检索策略(Reflexion, MemOS) |
2.3 第三层:集体多智能体推理(Collective)
这一层将智能从个体扩展到协作系统,通过多智能体的分工与协作解决更复杂的问题。
角色分类学
多智能体系统中的角色可以大致分为通用角色和领域特定角色。
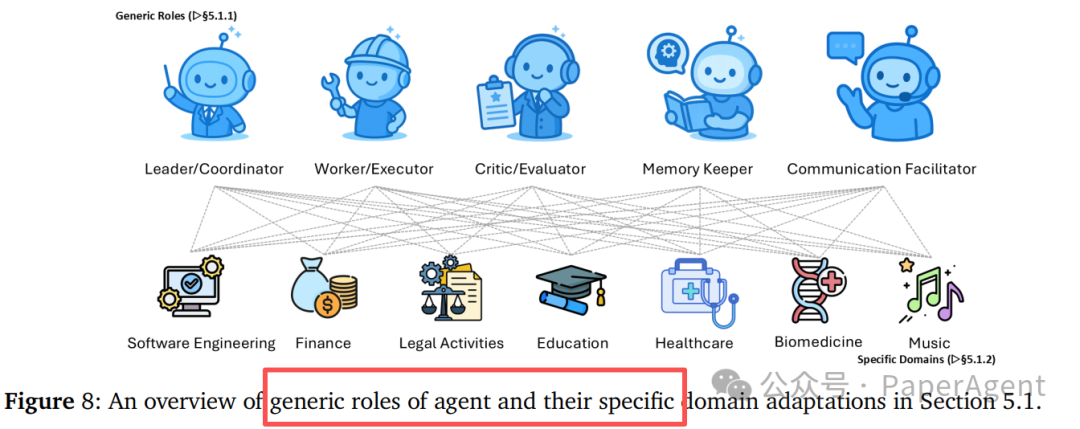
- 通用角色:
- Leader/Coordinator: 负责全局目标分解与冲突仲裁。
- Worker/Executor: 负责具体行动执行。
- Critic/Evaluator: 负责质量保障与风险识别。
- Memory Keeper: 负责长期知识维护。
- Communication Facilitator: 负责通信协议管理。
- 领域特定角色:在软件工程、金融、法律、医疗、教育、生物医学、音乐等领域有具体化身。
协作与分工
多智能体如何协作?主要分为上下文协作和后训练协作两种模式。
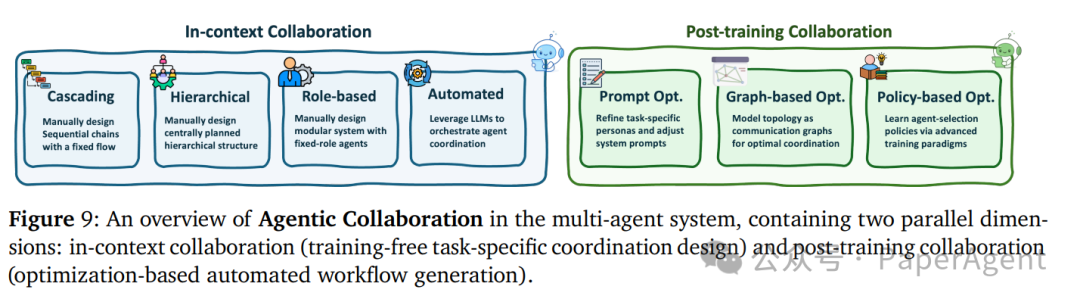
| 协作模式 |
方法 |
特点 |
| 手动设计流水线 |
级联、层次、基于角色 |
可解释但缺乏灵活性 |
| LLM驱动编排 |
AutoGen, Magentic-One, MAS-GPT |
动态适应任务需求 |
| 图拓扑优化 |
GommFormer, AgentPrune, AFlow |
学习最优通信结构 |
| 策略式训练 |
MAGRPO, MHGPO, COPY |
RL优化协作策略 |
多智能体记忆管理
当多个智能体共同工作时,记忆的设计与管理变得更加复杂。论文提出了一个四维度框架:
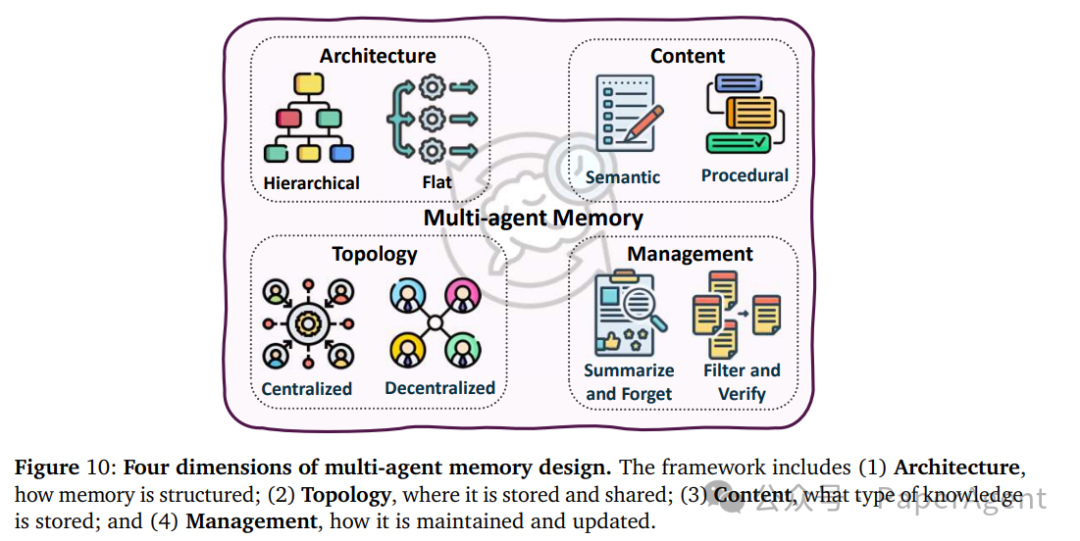
| 维度 |
关键设计 |
| 架构 |
层次化(G-Memory)vs 扁平化(Intrinsic Memory Agents) |
| 拓扑 |
集中式(SEDM)vs 分布式(Collaborative Memory)vs 共享池 |
| 内容 |
语义分解(MIRIX)vs 任务分解(LEGOMem)vs 认知阶段(MAPLE) |
| 管理 |
摘要-遗忘(Lyfe Agents)vs 过滤-验证(AGENT-KB) |
三、应用领域:从数学到现实世界
Agentic Reasoning 的能力正在多个前沿领域展现价值。
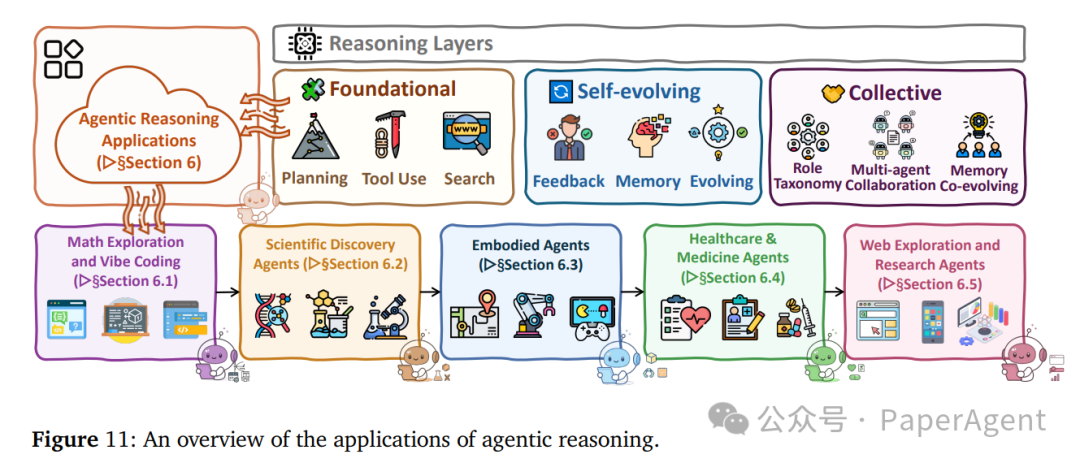
| 领域 |
核心挑战 |
关键能力/系统 |
| 数学探索与Vibe编码 |
竞赛级推理、复杂代码生成 |
AlphaEvolve, OpenHands, Cursor |
| 科学发现 |
假设生成、实验设计自动化 |
ChemCrow, Coscientist, The AI Scientist |
| 具身智能 |
长程规划、物理环境交互 |
Voyager, SayCan, CosmosReason1 |
| 医疗健康 |
安全约束、多模态证据整合 |
MedAgent-Pro, TxAgent, MDAgents |
| 自主网络探索 |
动态环境交互、信息合成 |
WebArena, Mind2Web, DeepResearcher |
四、评测基准:从机制到应用
为了系统评估Agentic Reasoning的能力,学界构建了丰富的评测基准,主要分为能力中心型和应用中心型。
| 机制 |
基准示例 |
评估重点 |
| 工具使用 |
ToolBench, APIBench, T-Eval |
单轮/多轮工具调用准确性 |
| 搜索 |
WebArena, Mind2Web, FinBrowseComp |
信息检索与整合能力 |
| 记忆与规划 |
LOCOMO, LongMemEval, ALFWorld |
长程记忆保持与规划一致性 |
| 多智能体 |
AgentBench, MultiAgentBench, MAgIC |
协作、竞争、社会推理 |
总结与资源
这篇综述为我们勾勒出大模型智能体推理清晰的发展蓝图:从静态、被动的LLM,到具备基础行动能力的智能体,再到能够自我进化、协同工作的智能体社会。其提出的三维框架(基础-自进化-集体)和两种实现路径(上下文-后训练),为后续的研究与实践提供了宝贵的结构化视角。
对Transformer架构为基础的现代大语言模型而言,融合Agentic Reasoning是通向更通用、更强大人工智能的关键一步。随着规划、工具使用、记忆、协作等能力的不断深化与融合,我们有望看到AI在科研、医疗、教育等复杂现实任务中发挥更大作用。
如果你对构建或研究智能体系统感兴趣,这篇论文及相关资源是绝佳的起点。欢迎在云栈社区的人工智能板块与其他开发者交流探讨。
论文与资源链接:
 发表于 2026-2-12 12:53:40
|
查看: 313|
回复: 0
发表于 2026-2-12 12:53:40
|
查看: 313|
回复: 0
