当数据的真实决策边界在输入空间中是非线性时,简单的线性模型往往表现不佳。核方法通过不显式构造高维特征映射,而是通过核函数 k(x, x') 直接计算特征空间中的内积,从而在隐式高维空间中实现线性分离。这样既避免了显式构造高维特征带来的计算成本,又能显著增强模型的表示能力。核技巧的精髓在于:如果算法中只需要用到内积 <Φ(x), Φ(x')>,那么可以直接用核函数 k(x, x') 替代,而无需显式计算映射 Φ。
多项式核是一类重要的核函数,具有较好的解释性与可控性。 它可以看作是对输入特征进行多项式扩展(包含交互项)之后使用线性模型的等价形式。在处理诸如XOR结构、环形边界或带交互效应的特征时,多项式核通常能显著提升模型表现。
多项式核的核心
多项式核的标准定义为:
K(x, z) = (γ * <x, z> + r)^d
其中:
x, z 为输入向量;γ 为缩放系数(有时记作 scale 或 gamma 等变体);r 通常称为偏移或常数项(Scikit-learn 中的参数名为 coef0);d 为多项式的阶数(degree)。
常见地分为两类:
- 同质多项式核:
K(x, z) = (γ * <x, z>)^d(即 r=0)。只包含恰好 d 阶的单项式;
- 非同质多项式核:
K(x, z) = (γ * <x, z> + r)^d(即 r ≠ 0)。包含从 0 到 d 阶的所有单项式项,能更灵活地描述带有偏置项的决策函数。
直观理解:
d 越大,表示模型可使用更高阶的多项式特征(包括交互项),因此更容易拟合复杂的非线性边界;γ 控制了输入特征与核值之间的尺度关系;尺度过大或过小都会导致模型出现偏差或者过拟合;r 的引入允许模型在特征空间中引入“偏置”,类似于显式特征扩展中加入常数项 1。
特征映射的明确形式与维度
核技巧的本质是:存在某个特征映射 Φ: X -> H,使得 k(x, x') = <Φ(x), Φ(x')>_H。
对于多项式核,这个特征映射可用单项式构造明确写出。为便于讨论,我们先考虑非同质版本:
K(x, z) = (γ * x^T z + r)^d
用二项式定理展开:
(γ * x^T z + r)^d = Σ_{k=0}^{d} C(d, k) * (γ * x^T z)^k * r^{d-k}
注意到 (x^T z)^k 可以用所有 k 阶的单项式之和表示。
用多重指数 α = (α_1, …, α_n),定义 |α| = Σ_i α_i,以及 x^α = x_1^{α_1} … x_n^{α_n}。那么
(x^T z)^k = Σ_{|α|=k} [C(k; α) * x^α * z^α]
其中多项式系数为多重组合数:C(k; α) = k! / (α_1! … α_n!)。
将其代回核函数展开:
K(x, z) = Σ_{k=0}^{d} Σ_{|α|=k} [C(d, k) * γ^k * r^{d-k} * C(k; α) * x^α * z^α]
因此我们可以构造如下的特征映射 Φ(非同质):
Φ(x) = ( √[C(d, k) * γ^k * r^{d-k} * C(k; α)] * x^α )_{ for all k=0..d, |α|=k }
使得:
<Φ(x), Φ(z)> = Σ_{k=0}^{d} Σ_{|α|=k} [C(d, k) * γ^k * r^{d-k} * C(k; α) * x^α * z^α] = K(x, z)
由此可见,多项式核对应的特征向量由所有不超过 d 阶的单项式构成,并带有适当的系数缩放,使得核值正好等于高维空间中的内积。其特征空间维度等于所有不超过 d 的单项式数目:
Dim = Σ_{k=0}^{d} C(n + k - 1, k)
其中 C(n + k - 1, k) 为 n 维空间中所有 k 阶单项式的计数(带重复组合)。该公式也是组合数学中经典的星与条(stars and bars)结果。
对于同质核(r=0)仅包含恰好 d 阶的项,维度为:
Dim = C(n + d - 1, d)
为了直观,我们给出 n=2, d=2 的非同质特征展开的一个例子(省略缩放系数的平方根项,仅列出单项式结构):
k=0:常数项 1;k=1:x_1, x_2;k=2:x_1^2, x_1 x_2, x_2^2。
总计 1+2+3=6 维。此实例显示了多项式核如何在特征空间中纳入有意义的交互项和高阶项。
正定性
核函数的核心性质是正定性,即对任意数据点集 {x_1, …, x_m},Gram 矩阵 K(其中 K_{ij} = k(x_i, x_j))必须是半正定的:∀ v ∈ R^m, v^T K v ≥ 0 成立。这保证了被定义的再生核 Hilbert 空间(RKHS)结构和诸多优化问题的良好性质。
对多项式核的正定性存在经典结果:当 γ > 0 且 r ≥ 0 并且 d ∈ N 时,K(x, z) = (γ * x^T z + r)^d 为 PSD 核。
证明可从特征映射入手,或通过组合乘积核的稳定性来说明:
方法一(显式特征映射):上一节给出了确切的 Φ 使得 k(x, z) = <Φ(x), Φ(z)>。显然,对于任何集合 {x_i},Gram 矩阵可写成 K = Φ(X) Φ(X)^T(Φ(X) 为将所有 Φ(x_i) 按行堆叠的矩阵)。因此 K 是半正定的。
方法二(核稳定性与多项式的非负系数组合):注意到 x^T z 本身是核(对应于线性核),γ 是非负权重,C(d, k) r^{d-k} 是非负的组合系数,且 (a+b)^d = Σ_{k=0}^d C(d, k) a^k b^{d-k}。核的非负线性组合仍是核。因此
K(x, z) = Σ_{k=0}^{d} C(d, k) (γ x^T z)^k r^{d-k}
是核函数。如果 γ < 0 或 r < 0 一般会破坏 PSD 性质(或至少不保证),因此实践中通常取 γ > 0, r ≥ 0。
核技巧下的 SVM:从原始到对偶
以软间隔二分类支持向量机(SVM)为例,在线性可分情形下,原始优化问题是:
min_{w, b, ξ} 1/2 ||w||^2 + C Σ_i ξ_i
s.t. y_i (w^T x_i + b) ≥ 1 - ξ_i, ξ_i ≥ 0
其中 w, b 为超平面参数,ξ_i 为松弛变量,C 为正则化系数或惩罚系数。
令 x → Φ(x) 通过特征映射 Φ 进入高维空间,则原始问题替换为:
min_{w, b, ξ} 1/2 ||w||_H^2 + C Σ_i ξ_i
s.t. y_i (<w, Φ(x_i)>_H + b) ≥ 1 - ξ_i, ξ_i ≥ 0
构造拉格朗日函数并消去 w, ξ 得到对偶形式:
max_{α} Σ_i α_i - 1/2 Σ_i Σ_j α_i α_j y_i y_j K(x_i, x_j)
s.t. 0 ≤ α_i ≤ C, Σ_i α_i y_i = 0
对偶解得出后,决策函数为:
f(x) = sign( Σ_i α_i y_i K(x_i, x) + b )
这里 K 可能是多项式核,从而避免了显式计算 Φ。支持向量对应于 α_i > 0 的样本点,它们决定了最终的超平面。
KKT 条件提供了对支持向量的判定与间隔的分析;最终的间隔与 w 的范数相关,而 w 可通过表示定理写为 w = Σ_i α_i y_i Φ(x_i)。
核岭回归
多项式核不仅用于分类,也可用于回归。核岭回归是在 RKHS 中进行的带范数约束的最小二乘:
min_{f ∈ H} Σ_i (y_i - f(x_i))^2 + λ ||f||_H^2
解的形式由表示定理给出:
f(x) = Σ_i c_i K(x_i, x)
并且系数 c 由线性方程组
(K + λ I) c = y
确定,K 是 Gram 矩阵,y 是标签向量(实值),λ 为正则化系数。对于多项式核,K_{ij} 由 K(x_i, x_j) 给出。
完整案例
这里,咱们使用一个非线性二分类数据集(基于“月亮形”结构加上额外非线性扰动与少量离群点),用多项式核 支持向量机 进行训练与分析。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
rng = np.random.RandomState(42)
# 1) 数据集:非线性+扰动+离群点
X, y = make_moons(n_samples=800, noise=0.30, random_state=42)
# 增加非线性扰动,让边界更复杂
X[:, 0] += 0.30 * np.sin(3 * X[:, 1])
X[:, 1] += 0.20 * np.cos(4 * X[:, 0])
# 加入少量离群点,提升鲁棒性分析难度
num_outliers = 20
outlier_indices = rng.choice(len(X), size=num_outliers, replace=False)
X[outlier_indices] += rng.normal(loc=0.0, scale=3.0, size=(num_outliers, 2))
# 2) 训练/测试划分
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
# 3) 建立两个SVM多项式核模型:degree=2与degree=5(均使用标准化)
pipe_deg2 = Pipeline([
('scaler', StandardScaler()),
('svc', SVC(kernel='poly', degree=2, gamma='scale', coef0=1.0, C=1.0, probability=False))
])
pipe_deg5 = Pipeline([
('scaler', StandardScaler()),
('svc', SVC(kernel='poly', degree=5, gamma='scale', coef0=1.0, C=1.0, probability=False))
])
# 4) 训练
pipe_deg2.fit(X_train, y_train)
pipe_deg5.fit(X_train, y_train)
# 5) 评估
acc_deg2_train = pipe_deg2.score(X_train, y_train)
acc_deg2_test = pipe_deg2.score(X_test, y_test)
acc_deg5_train = pipe_deg5.score(X_train, y_train)
acc_deg5_test = pipe_deg5.score(X_test, y_test)
print(f"Degree=2 -> Train Acc: {acc_deg2_train:.3f}, Test Acc: {acc_deg2_test:.3f}")
print(f"Degree=5 -> Train Acc: {acc_deg5_train:.3f}, Test Acc: {acc_deg5_test:.3f}")
# 6) 决策边界+支持向量
def plot_decision_boundary(ax, pipeline, X, y, title, cmap='Spectral'):
# 网格边界
x_min, x_max = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
y_min, y_max = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0
xx, yy = np.meshgrid(
np.linspace(x_min, x_max, 400),
np.linspace(y_min, y_max, 400)
)
grid = np.c_[xx.ravel(), yy.ravel()]
# decision_function值用于等高线绘制
Z = pipeline.decision_function(grid)
Z = Z.reshape(xx.shape)
# 背景等高线
cf = ax.contourf(xx, yy, Z, levels=30, cmap=cmap, alpha=0.9)
# 决策边界(0等值曲线)
cs = ax.contour(xx, yy, Z, levels=[0], colors=['black'], linewidths=2)
# 训练样本点
colors = np.array(['#E91E63', '#00BCD4'])
ax.scatter(X[:, 0], X[:, 1], c=colors[y], s=18, edgecolor='white', linewidth=0.5)
# 支持向量(从SVC中提取,但坐标是标准化空间,需要逆变换回原始空间)
scaler = pipeline.named_steps['scaler']
svc = pipeline.named_steps['svc']
sv_scaled = svc.support_vectors_
sv = scaler.inverse_transform(sv_scaled)
ax.scatter(sv[:, 0], sv[:, 1], s=50, facecolors='none', edgecolors='#FFEB3B', linewidths=1.5, label='Support Vectors')
ax.set_title(title, fontsize=12, color='#1A237E')
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.legend(loc='upper right', frameon=True)
# 7) 可视化分析:决策边界 + 间隔分布 + 超参数热力图
# 图1:degree=2 决策边界
fig1, ax1 = plt.subplots(figsize=(10, 8), dpi=140)
plot_decision_boundary(ax1, pipe_deg2, X_train, y_train,
title=f"多项式核 SVM (degree=2)\nTrain Acc={acc_deg2_train:.3f}, Test Acc={acc_deg2_test:.3f}",
cmap='Spectral')
plt.tight_layout()
plt.show()
# 图2:degree=5 决策边界
fig2, ax2 = plt.subplots(figsize=(10, 8), dpi=140)
plot_decision_boundary(ax2, pipe_deg5, X_train, y_train,
title=f"多项式核 SVM (degree=5)\nTrain Acc={acc_deg5_train:.3f}, Test Acc={acc_deg5_test:.3f}",
cmap='rainbow')
plt.tight_layout()
plt.show()
# 图3:间隔(decision_function)分布对比直方图(训练集)
plt.figure(figsize=(12, 6), dpi=140)
df_deg2 = pipe_deg2.decision_function(X_train)
df_deg5 = pipe_deg5.decision_function(X_train)
bins = np.linspace(min(df_deg2.min(), df_deg5.min()), max(df_deg2.max(), df_deg5.max()), 40)
plt.hist(df_deg2[y_train==0], bins=bins, color='#FFC107', alpha=0.6, label='degree=2, class 0', edgecolor='black', linewidth=0.5)
plt.hist(df_deg2[y_train==1], bins=bins, color='#8BC34A', alpha=0.6, label='degree=2, class 1', edgecolor='black', linewidth=0.5)
plt.hist(df_deg5[y_train==0], bins=bins, color='#F44336', alpha=0.5, label='degree=5, class 0', edgecolor='black', linewidth=0.5)
plt.hist(df_deg5[y_train==1], bins=bins, color='#03A9F4', alpha=0.5, label='degree=5, class 1', edgecolor='black', linewidth=0.5)
# 添加决策边界线
plt.axvline(0, color='red', linestyle='--', linewidth=2, label='决策边界 (f=0)', alpha=0.8)
plt.title("间隔分布对比:Decision Function 值分布(训练集)", fontsize=14, fontweight='bold', pad=15)
plt.xlabel("Decision Function 值", fontsize=12)
plt.ylabel("频数", fontsize=12)
plt.legend(loc='upper right', frameon=True, framealpha=0.9, fontsize=10)
plt.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.show()
# 图4:gamma × degree 超参数网格的交叉验证准确率热力图
plt.figure(figsize=(10, 8), dpi=140)
degrees = [2, 3, 4, 5, 6]
gammas = [0.05, 0.1, 0.2, 0.5, 1.0, 2.0]
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
acc_matrix = np.zeros((len(degrees), len(gammas)))
print("\n计算超参数网格的交叉验证准确率...")
for i, d in enumerate(degrees):
for j, g in enumerate(gammas):
pipe = Pipeline([
('scaler', StandardScaler()),
('svc', SVC(kernel='poly', degree=d, gamma=g, coef0=1.0, C=1.0))
])
scores = cross_val_score(pipe, X_train, y_train, cv=cv, scoring='accuracy')
acc_matrix[i, j] = scores.mean()
print(f" degree={d}, gamma={g}: CV Acc={scores.mean():.4f}")
im = plt.imshow(acc_matrix, interpolation='nearest', cmap='magma', aspect='auto')
plt.title("交叉验证准确率热力图:degree × gamma", fontsize=14, fontweight='bold', pad=15)
plt.xlabel("gamma", fontsize=12)
plt.ylabel("degree", fontsize=12)
plt.xticks(range(len(gammas)), [str(g) for g in gammas])
plt.yticks(range(len(degrees)), [str(d) for d in degrees])
# 数值标注
for i in range(len(degrees)):
for j in range(len(gammas)):
text_color = 'white' if acc_matrix[i, j] < acc_matrix.max() * 0.7 else 'black'
plt.text(j, i, f"{acc_matrix[i, j]:.3f}",
ha='center', va='center', color=text_color, fontsize=10, fontweight='bold')
# 标记最佳参数
best_i, best_j = np.unravel_index(acc_matrix.argmax(), acc_matrix.shape)
plt.scatter(best_j, best_i, s=300, facecolors='none', edgecolors='lime', linewidths=3,
label=f'最佳: degree={degrees[best_i]}, gamma={gammas[best_j]}')
cbar = plt.colorbar(im, fraction=0.046, pad=0.04)
cbar.set_label('交叉验证准确率', rotation=270, labelpad=20, fontsize=11)
plt.legend(loc='upper left', fontsize=10, framealpha=0.9)
plt.tight_layout()
plt.show()
print(f"\n最佳超参数组合: degree={degrees[best_i]}, gamma={gammas[best_j]}, CV Acc={acc_matrix[best_i, best_j]:.4f}")
degree=2 决策边界:
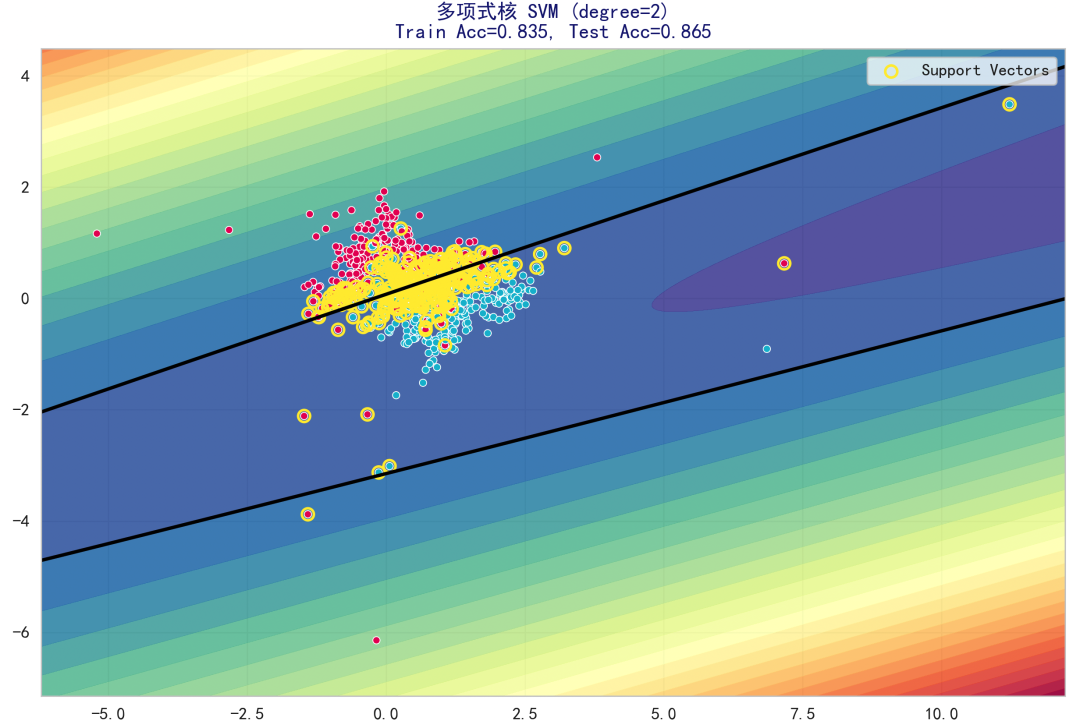
展示二次多项式核的决策边界形状与支持向量位置。二次核一般能处理 XOR 型结构与轻度非线性,支持向量分布体现了模型对不同区域样本的“支撑”。这张图说明:二次核已能生成非线性边界,但可能无法捕捉更复杂的波动区域。
degree=5 决策边界:
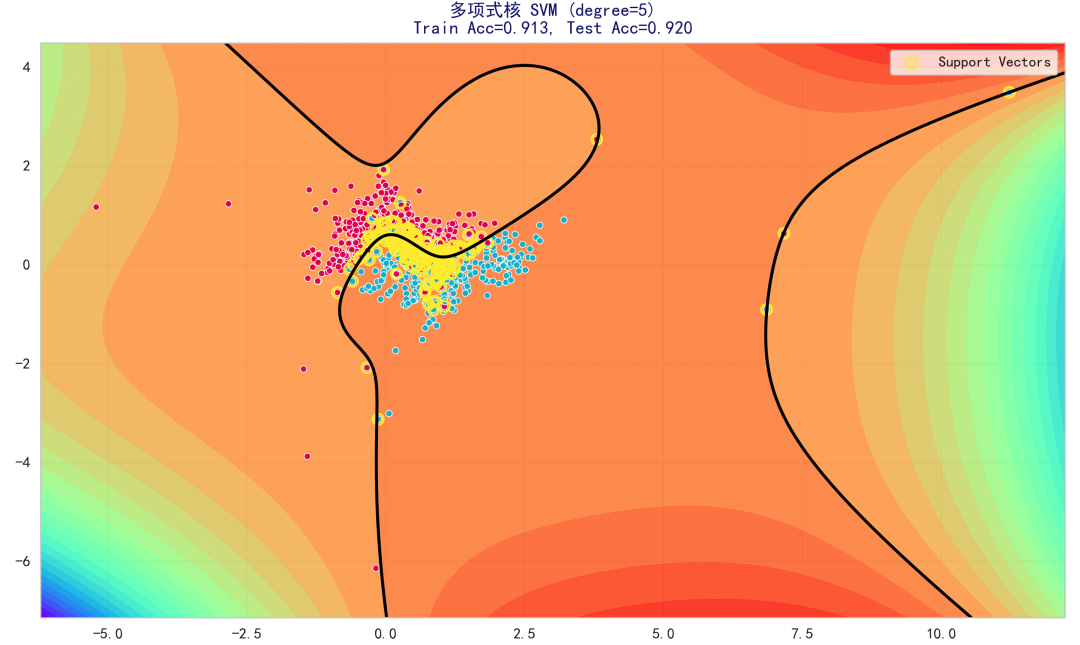
展示更高阶多项式核对非线性边界的拟合能力,支持向量数量变化也说明了模型复杂度与数据支持点之间的关系。这张图说明:提高 degree 可以显著增强表示能力,但也可能在噪声区域过拟合(边界扭曲)。
间隔分布直方图:
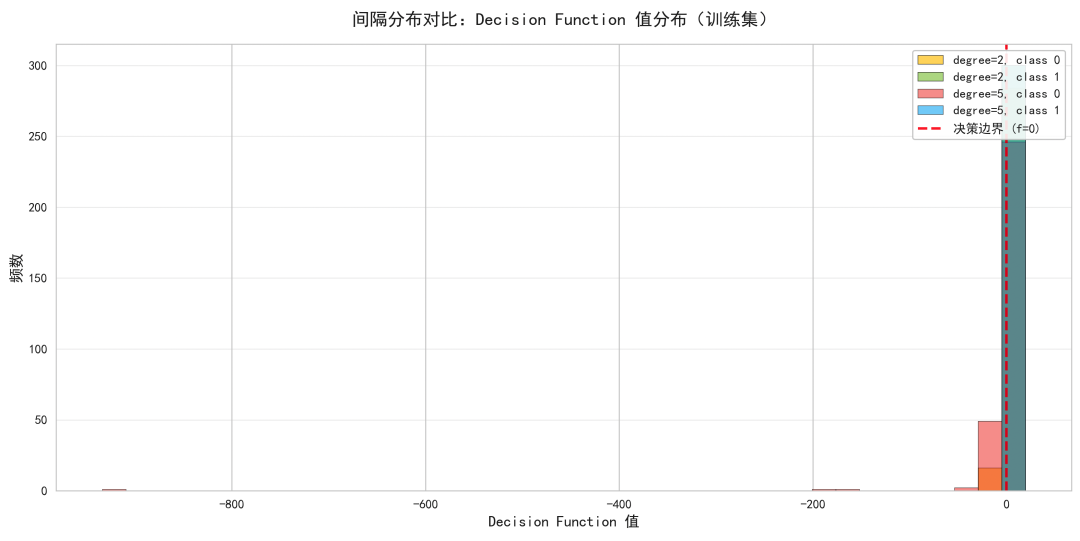
比较 degree=2 与 degree=5 模型在训练集上的 decision_function 值分布。值越大代表分类越“自信”,值接近 0 意味着样本靠近决策边界。通过对两个类别的柱状图叠加可观察模型对不同类别的间隔分配情况。若 degree=5 的分布在两端更集中且尖锐,可能暗示更强的拟合,但也可能说明对训练数据过拟合;若出现大量靠近 0 的样本,说明边界仍然存在混淆区域。
超参数热力图:
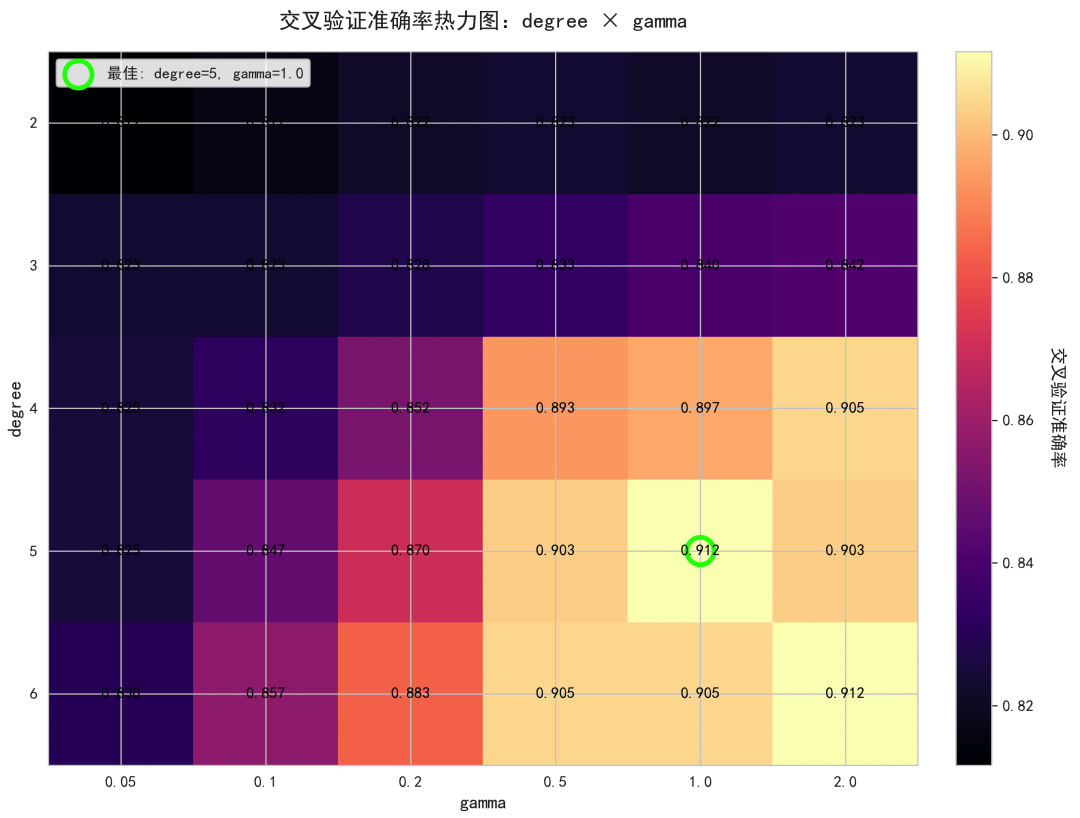
在 degree 与 gamma 二维网格上绘制交叉验证准确率,明确展示超参数敏感性与相互作用。gamma 过大或过小都可能使准确率下降,degree 过高在某些 gamma 下会过拟合。该图强调:应通过系统化的网格搜索或 Bayesian 优化来选择超参数;不同数据集的最佳组合可能截然不同。
优化项
这里给出大家实践中常见的优化方向与可能的坑点,帮助在真实项目里稳定使用多项式核。
优化项:
- 特征缩放:配合
StandardScaler 或 MinMaxScaler,使 γ 的效果更稳定;避免某些特征的量纲支配核值。
- 选择适度的 degree:从
2 或 3 开始,逐步提高;若测试表现不升反降,考虑降低 degree 或提高正则化(调小 C 或增加惩罚)。
- γ 与 r(coef0)的联合调优:适当增大
r 可提升低阶项影响,有助于当数据具有明显类中心差异时的表现;γ 决定核值随输入的响应程度,需要配合数据尺度调整。
- 交叉验证与早停策略:在大数据时可采样子集进行初步调参,再扩展到全量;也可通过折中指标选择较稳健的参数,而非过度追求训练分数。
- 近似方法:当训练集规模巨大时考虑 Nystrom 或随机特征近似,从而在计算资源有限的条件下获得可接受的效果。
- 简化特征:如果维度高且含有冗余特征,先用 PCA/ICA 或特征选择缩减维度,再应用多项式核,可提高训练速度与泛化表现。
注意点:
- 正定性条件:确保
γ > 0、r ≥ 0、d ∈ N。负的参数组合可能破坏 PSD 性质。
- 过拟合风险:高阶
d、较大的 γ 与不恰当的 C 容易导致过拟合。通过交叉验证与学习曲线进行监控。
- 类不平衡:在类别极不平衡时,准确率不适合作为唯一指标;需考虑 F1、ROC-AUC、Precision-Recall 等,并可使用
class_weight 进行惩罚均衡。
- 支持向量数量与训练耗时:更复杂的核函数通常会增加支持向量与训练时间。量化监控支持向量数量以把握模型复杂度。
- 数值稳定:由于多项式核的高阶运算可能引发数值问题,建议配合标准化、适度的参数范围与合适的数据类型(float64)。
- 可解释性限制:虽然多项式核具有一定的可解释性(对应多项式特征),但隐式映射仍不如显式构造直观。若需要解释模型决策过程,可考虑抽取支持向量、检视 margin、局部可解释方法(LIME/SHAP)等。
常见问题
为什么 degree 提高后测试准确率反而下降?
- 可能过拟合:边界过度贴合训练噪声;建议降低
degree、减小 γ、增加正则化(减小 C 或增大误差容忍)。
gamma 选择有什么规则?
- 常与特征标准化配合;可以从较小值开始如
0.01、0.1 再逐步测试到 1、10;也可以用经验公式或自动化调参工具进行探索。
coef0 的作用?
- 提升低阶项影响,非同质核允许更强的偏置效应。当数据呈现类中心差异时有帮助;一般从
0.0 或 1.0 起步调参。
SVM 的 C 如何调?
- 较小的
C 更平滑、泛化更强,较大的 C 更贴合训练数据、在复杂数据上易过拟合。依赖交叉验证选择。
总结
多项式核是核方法中既经典又实用的一种核函数。它在理论上具有明确的特征映射与正定性保证,在实践中则通过隐式地纳入多项式交互项和高阶项来增强模型拟合能力。通过对 degree、gamma、coef0、C 等超参数的联合调优,以及对特征尺度的注意与合适的交叉验证策略,能够平衡模型的表达能力与泛化性能。对于更深入的理论探讨或实践中的问题,欢迎到技术社区如 云栈社区 进行交流。
 发表于 2026-2-12 17:45:56
|
查看: 194|
回复: 0
发表于 2026-2-12 17:45:56
|
查看: 194|
回复: 0
