小米近日正式对外发布了其首个开源的视觉语言动作(VLA)大模型——Xiaomi-Robotics-0。该模型拥有高达47亿参数,集成了强大的视觉语言理解与高性能实时动作执行能力,并在多个权威评测中刷新了当前最优(SOTA)成绩。

更令人印象深刻的是,在真实的机器人任务中,它展现了出色的物理智能泛化能力:动作连贯、反应灵敏。尤为关键的是,其推理效率极高,能够在消费级显卡上实现实时推理,这为实际部署和应用降低了门槛。
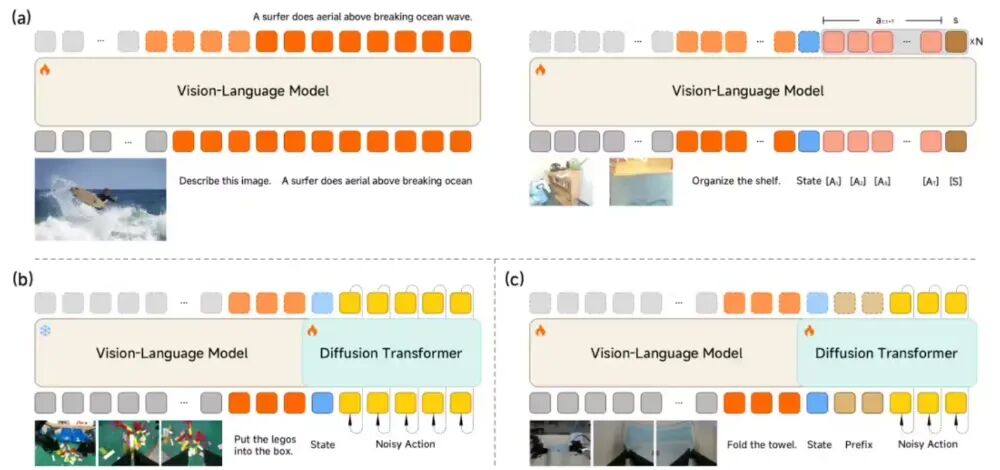
根据官方解读,物理智能的核心在于“感知-决策-执行”这一闭环的质量。为了兼顾通用的场景理解与精细的运动控制,Xiaomi-Robotics-0 采用了目前主流且高效的 Mixture-of-Transformers (MoT) 混合架构。
- 视觉语言大脑(VLM): 团队选用了一个多模态 视觉语言模型 作为基座。它的职责是理解人类自然、有时甚至模糊的指令(例如“请把毛巾叠好”),并能够从高清的视觉输入中精准地捕捉物体间的空间关系。
- 动作执行小脑(Action Expert): 为了生成高频且平滑的机械臂动作,团队嵌入了一个多层的 扩散变换器 。它的输出并非单一动作点,而是一个包含连续动作的“动作块”,并借助流匹配技术来确保动作轨迹的精准度。
攻克核心挑战:如何让模型既“聪明”又“灵巧”?
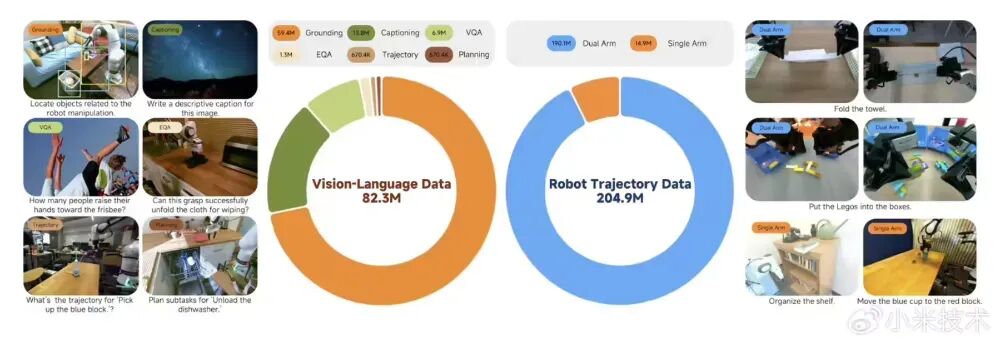
在机器人模型训练中存在一个普遍难题:大部分VLA模型在学习精细动作控制时,往往会牺牲掉一部分原有的通用视觉理解能力,也就是常说的“变笨”了。针对此问题,小米研发团队通过多模态数据与动作数据的混合训练策略,让模型在掌握复杂操作技能的同时,依然保持了强大的物体检测、视觉问答和逻辑推理能力。
具体训练分为两个关键阶段:
- VLM 协同训练: 首先引入了 Action Proposal 机制。这一机制强迫VLM模型在理解图像内容的同时,去预测多种可能的动作分布。这一步的核心目的是让VLM的“思维”特征空间与后续要执行的“动作”空间提前对齐,避免了模型停留在“纸上谈兵”的阶段。
- DiT 专项训练: 随后冻结VLM部分的参数,专注于训练DiT模块,让其学习如何从噪声中逐步恢复出精确、平滑的动作序列。在这一阶段,团队移除了VLM输出的离散Token,完全依赖其生成的KV(Key-Value)特征作为条件来引导DiT生成动作。通过这种专项训练,模型最终能够输出高质量、低抖动的动作轨迹。
从仿真到真机:确保动作连贯与快速响应
即便模型能力强大,在实际机器人部署时,推理延迟仍可能导致动作卡顿或不连贯。为解决这个“动作断层”问题,小米团队采用了创新的异步推理模式——让模型的推理计算与机器人的物理执行过程解耦,异步进行,从系统机制上保障了动作的流畅性。
为了进一步强化机器人对环境突发变化的快速响应能力和运行稳定性,模型中还引入了两项关键技术:
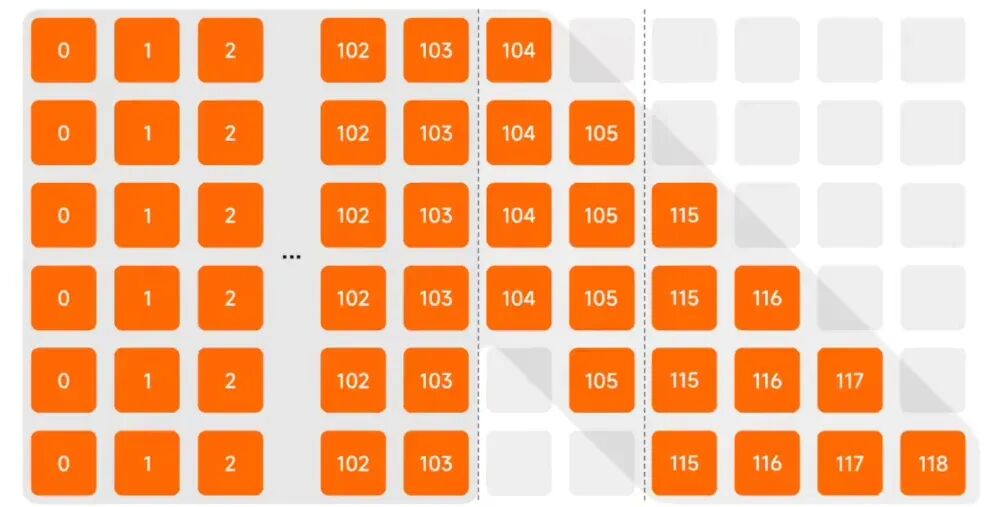
- Clean Action Prefix: 将前一时刻已经预测并执行的动作,作为当前时刻模型输入的一部分。这确保了机器人的动作轨迹在时间维度上高度连续,有效减少了抖动。
- Λ-shape Attention Mask: 通过一种特殊的注意力掩码,强制模型更多地关注最新的视觉传感器反馈,而不是过度依赖历史的动作惯性。这使得机器人在面对环境干扰或突发状况时,能够迅速调整,展现出“反应性”的物理智能。
性能表现:全面领先的实测数据
经过多维度的严格测试,Xiaomi-Robotics-0 展现出了全面而优异的性能:
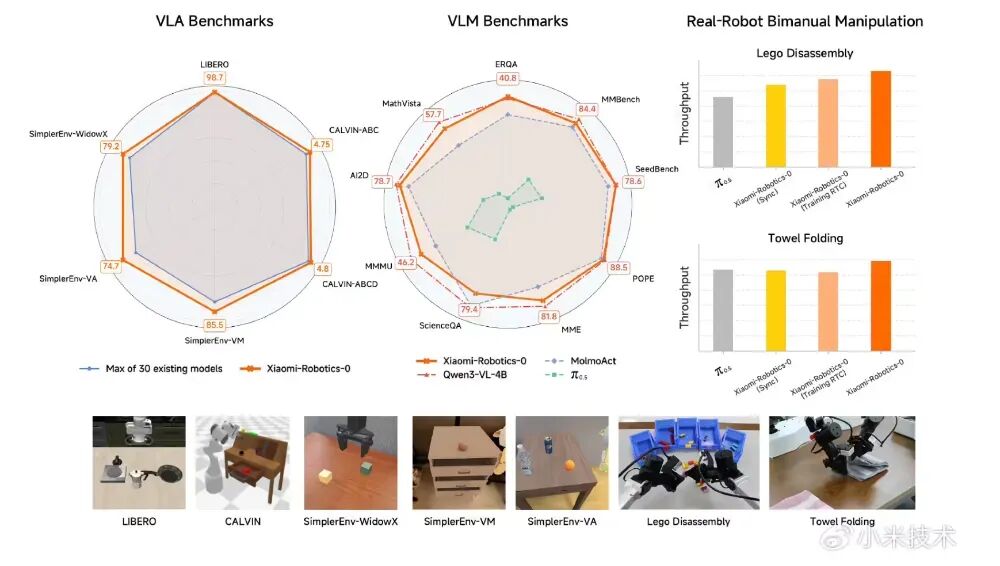
- 仿真环境标杆测试: 在 LIBERO、CALVIN 和 SimplerEnv 等一系列机器人仿真测试中,该模型在所有任务上与已有的约30种模型对比,均取得了当前最优的结果。
- 真实机器人挑战: 团队在真实的双臂机器人平台上部署了该模型,并与行业内的其他标杆模型进行了横向对比。在“积木拆解”和“叠毛巾”这类长周期、高难度的任务中,搭载Xiaomi-Robotics-0的机器人展现了极高的手眼协调性。无论是处理刚性的积木还是柔性的织物,都能胜任。
- 保留多模态理解优势: 得益于独特的训练方法,该模型完好地保留了底层VLM强大的多模态理解能力,尤其在具身智能相关的评测中表现突出,这是以往许多VLA模型所不具备的特性。
目前,小米已正式宣布将Xiaomi-Robotics-0模型在相关平台开源,供广大开发者、研究机构和机器人爱好者下载、研究与应用。这对于推动机器人大模型领域的开源生态和技术进步具有重要意义。如果你对机器人AI或大模型技术感兴趣,不妨到云栈社区的相关板块,与更多开发者一起交流探讨最新的技术动态与实践心得。

|  发表于 2026-2-13 01:37:27
|
查看: 259|
回复: 0
发表于 2026-2-13 01:37:27
|
查看: 259|
回复: 0
