在宠物健康类小程序的后端开发中,一个核心需求是理解用户的真实意图,从而进行精准分流或智能导诊。本文将详细分享一个基于 Python 与大模型的用户意图识别及智能分诊模块的开发实战过程,涵盖接口设计、代码优化、问题排查以及数据持久化等关键环节。
一、用户意图识别模块开发
1. 需求与设计
我们需要对用户输入的问题进行意图识别,将其归类到预定义的几个业务方向中。识别的分类包括:疾病问诊、疫苗接种、用药咨询、在线复诊、驱虫选药、科学养宠、行为异常、检测报告。对应的后端处理函数设计如下:
def user_intension_congnition(conversation_id:str,question:str):
"""
用户意图识别
返回:以下分类的一种
"""
疾病问诊
疫苗接种
用药咨询
在线复诊
驱虫选药
科学养宠
行为异常
检测报告
"""
question = user_intension_reconition_prompt.format(input_text=question)
return chat(conversation_id, question, stream=False)
2. 接口测试与问题排查
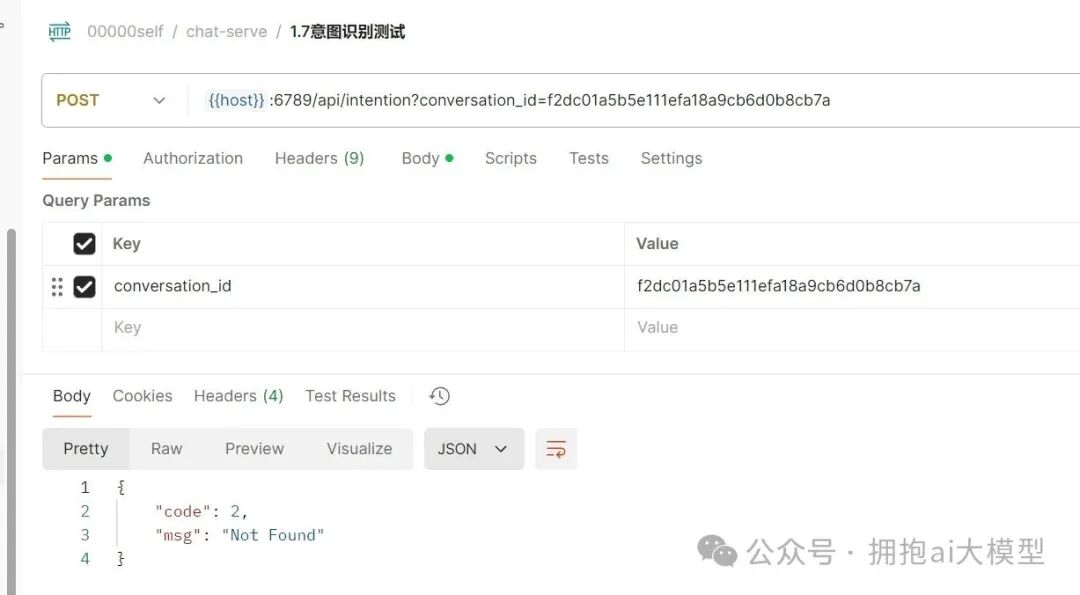
开发完成后,我们通过 API 接口进行测试。
第一步:测试报错
首次测试时,接口返回了 “code”: 2, “msg”: “Not Found” 的错误。
经排查,发现是服务 chat_sev 没有重启,导致新代码未生效。重启后出现了新的错误:“endswith first arg must be str or a tuple of str, not bytes”。
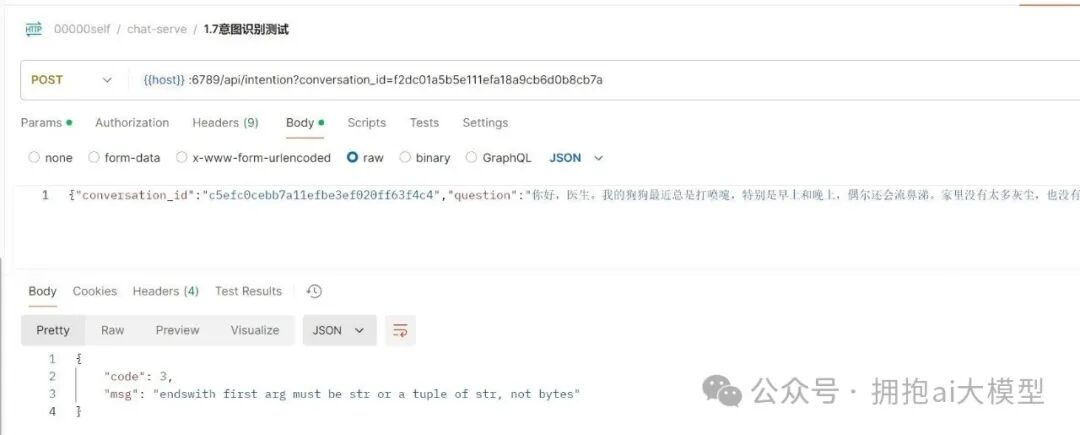
这个问题源于对字符串的循环处理逻辑有误。在 Python 中处理字节(bytes)和字符串(str)时需要格外注意类型转换。修复后,我们遇到了下一个问题:要求大模型(ragflow)接口非流式返回,但实际仍以流式返回。
第二步:实现非流式返回
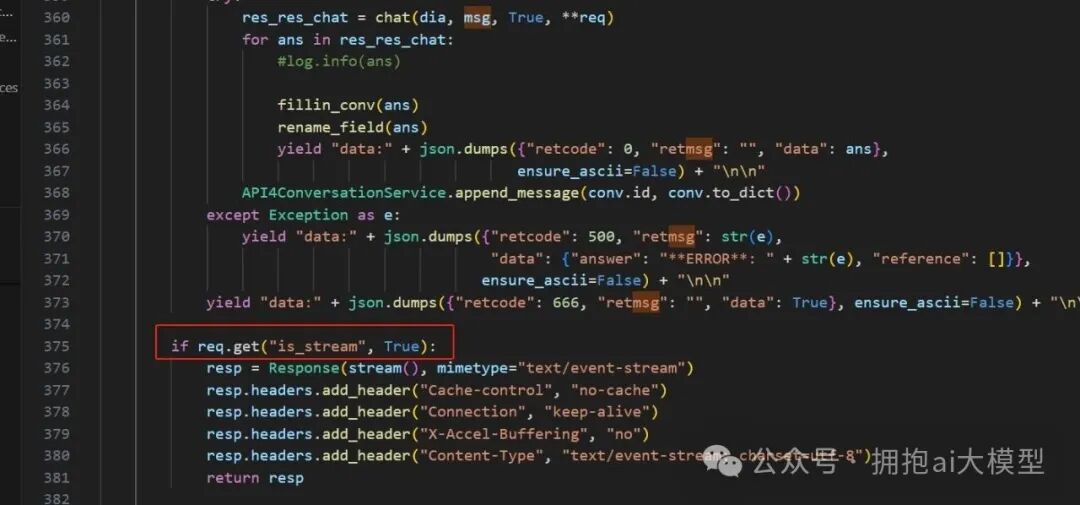
为了解决流式返回的问题,我们需要追踪并修改代码。首先在调用端(chat_sev)将参数名统一为 is_stream 以避免冲突。
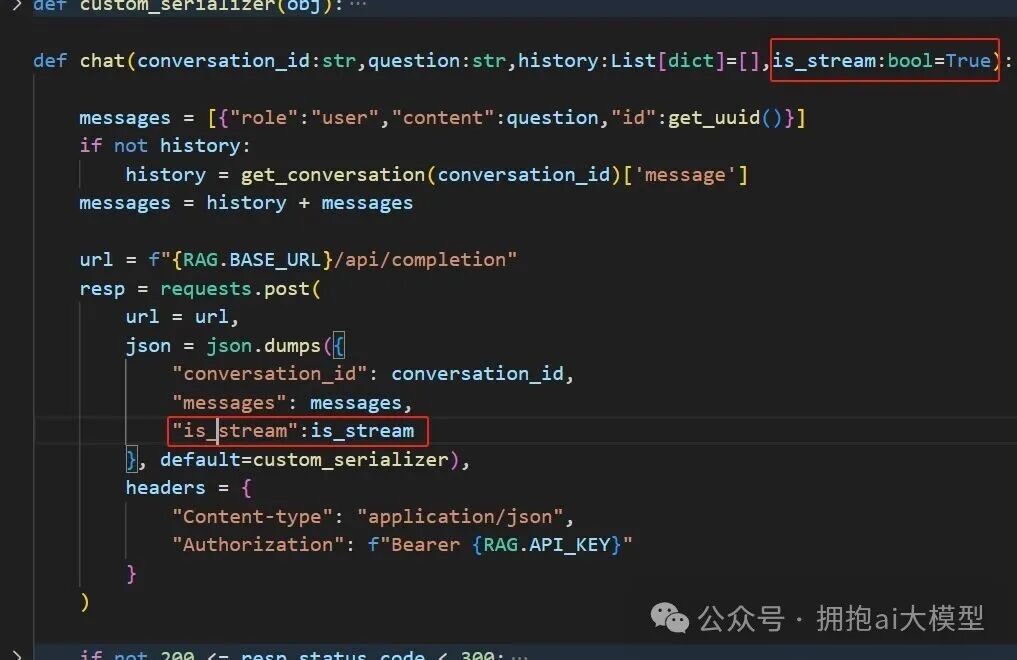
接着,在服务端(ragflow)的响应逻辑中,正确读取 is_stream 参数,并据此决定返回流式(text/event-stream)还是非流式响应。
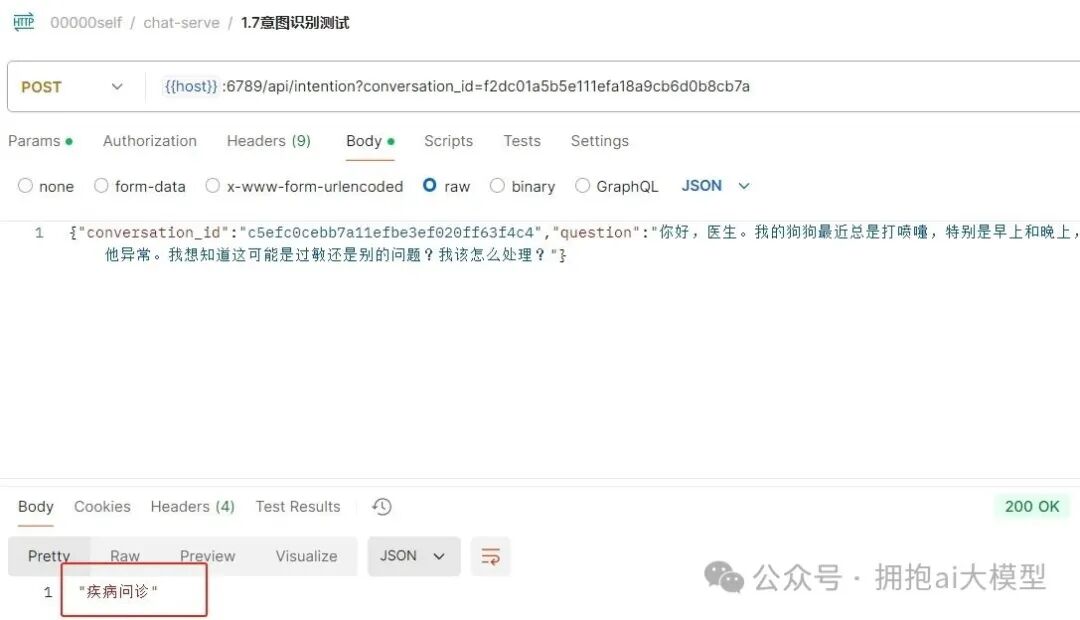
修改后重新测试,接口成功返回了正确的意图识别结果 “疾病问诊”。
3. 数据存储与前端展示优化
识别结果直接写入对话记录后,前端会将其作为一条普通消息展示给用户,这显然不合理。
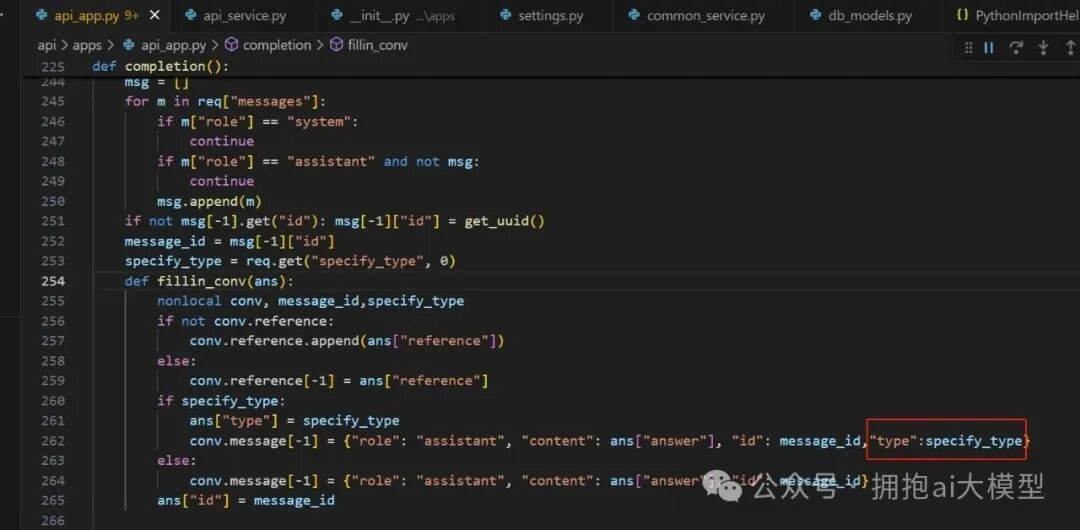
第三步:为消息添加类型标识
为了解决这个问题,我们决定为消息增加一个 type 字段。例如,将意图识别类消息的 type 设置为一个特殊值(如 100),前端根据此类型决定是否渲染显示。
首先修改了助手(assistant)消息的保存逻辑,为其添加 type 字段。
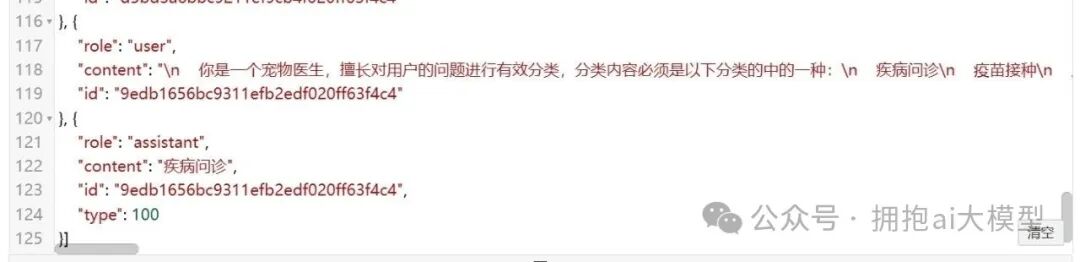
修改后,保存在数据库中的消息结构如下所示:
第四步:为用户消息同步添加类型
为了保证对话上下文的完整性,调用大模型时发送的用户(user)消息也需要携带相同的 type。我们在 chat_sev 调用大模型的代码中进行了相应修改。
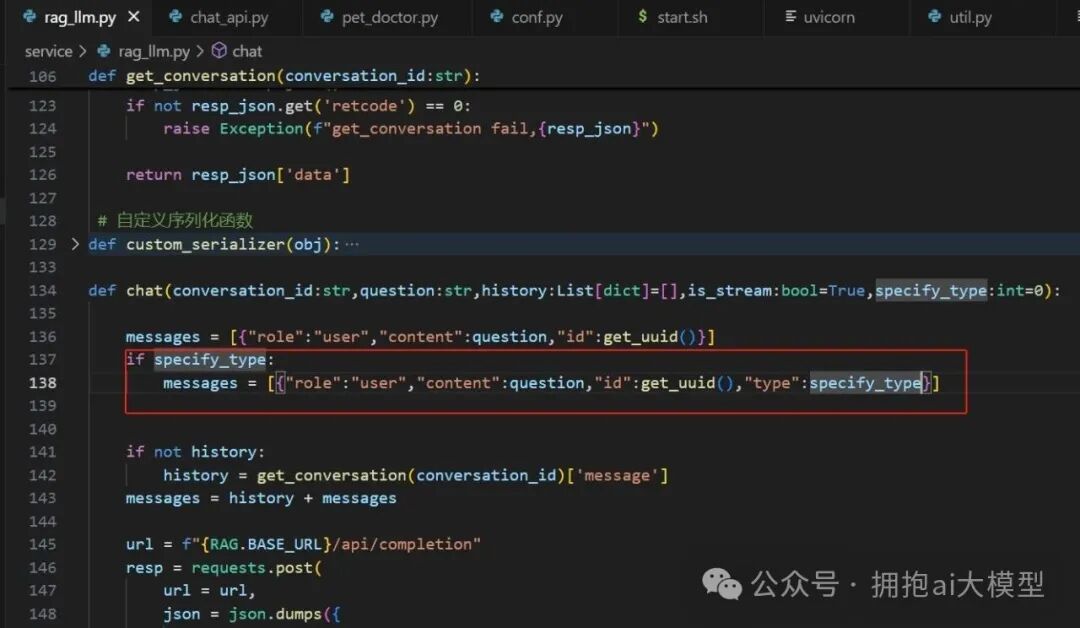
第五步:服务部署上线
代码修改完成后,通过 git 操作将代码更新至服务器并重启服务。
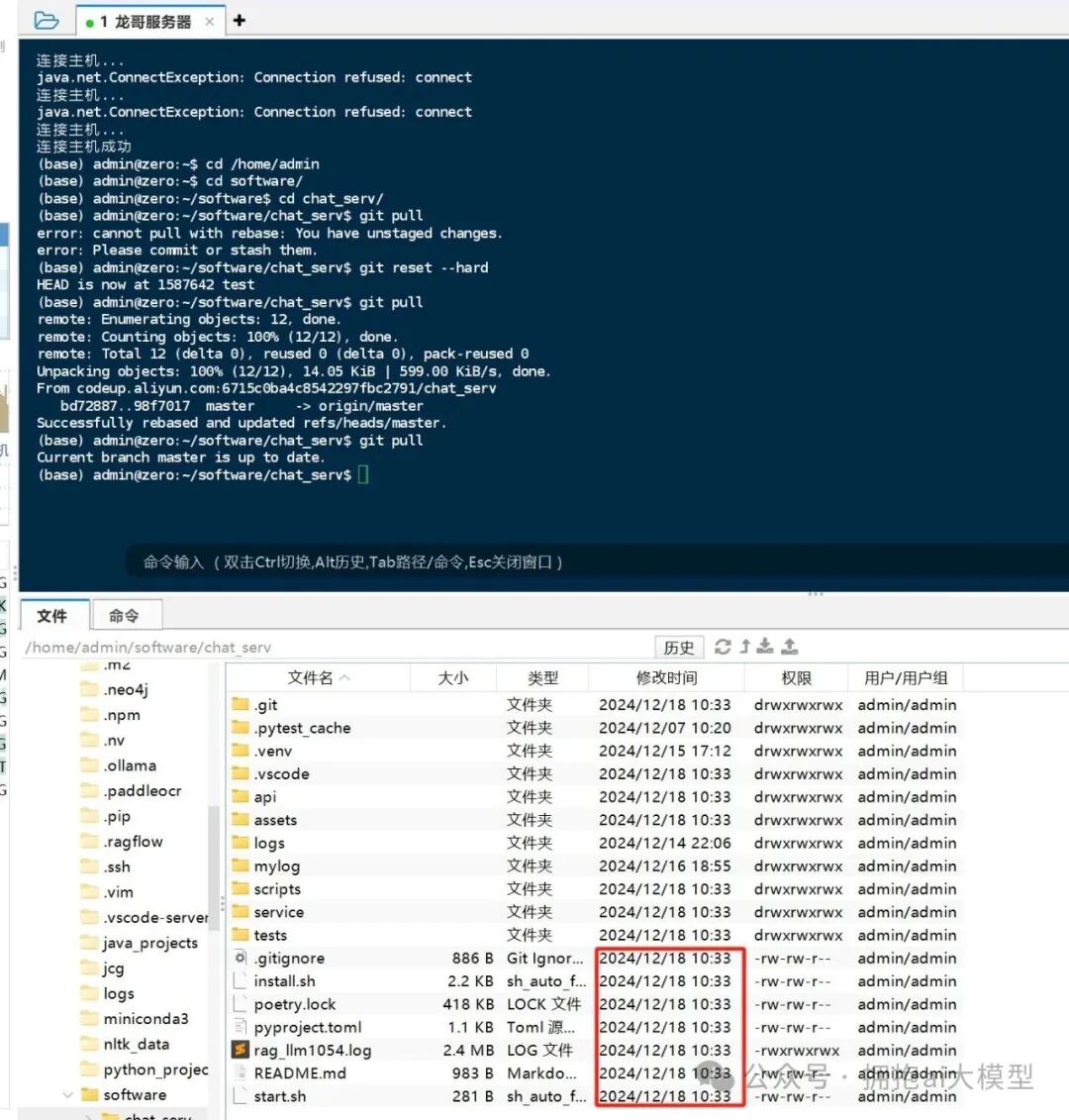
这里需要注意,像 poetry.lock 这类依赖管理文件通常不需要频繁更新,可以将其加入到 .gitignore 中以避免不必要的环境重装。
第六步:持久化意图识别状态
为了避免对同一会话重复进行意图识别,我们将识别结果持久化到数据库的 conversation 表中。优化后的识别函数逻辑如下:
def user_intension_congnition(conversation_id:str,question:str):
###先查下是否进行过意图识别
e,res_conversation = ConversationService.get_by_id(conversation_id)
if not e:
return error('1003',"未找到会话")
res_conversation = res_conversation.to_dict()
if res_conversation['intention']:
return res_conversation['intention']
"""
用户意图识别
返回:以下分类的一种
疾病问诊
疫苗接种
用药咨询
在线复诊
驱虫选药
科学养宠
行为异常
检测报告
"""
question = user_intension_reconition_prompt.format(input_text=question)
specify_type = 100 #指定类型,这个类型表示意图识别,主要为了前端不显示
res_chat = chat(conversation_id, question,[],False,specify_type)
if res_chat:
ConversationService.save(id=conversation_id,intention=res_chat,is_intent=1)
return res_chat
该逻辑首先查询会话是否已有意图记录,若有则直接返回,否则调用 大模型 进行识别并将结果存入数据库。测试成功后,数据库记录如下:

二、智能分诊模块开发
当意图识别结果为“疾病问诊”时,系统需要进一步进行智能分诊,将问题引导至具体的科室,如消化道、呼吸道、皮肤科等。
1. 分诊流程与接口设计
根据产品设计,分诊是多轮对话问诊流程的起点。
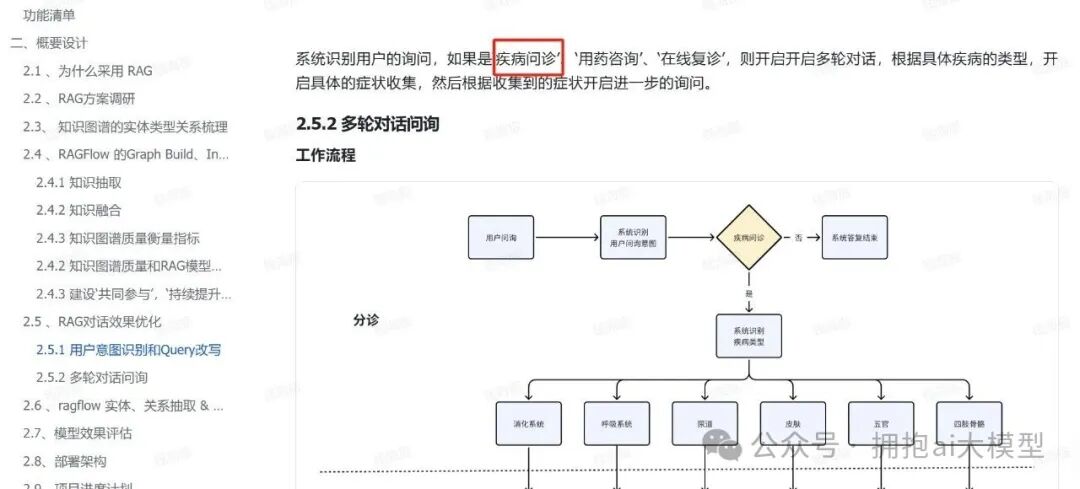
我们基于已有的代码框架,开发了分诊接口。首先定义分诊请求的处理函数:
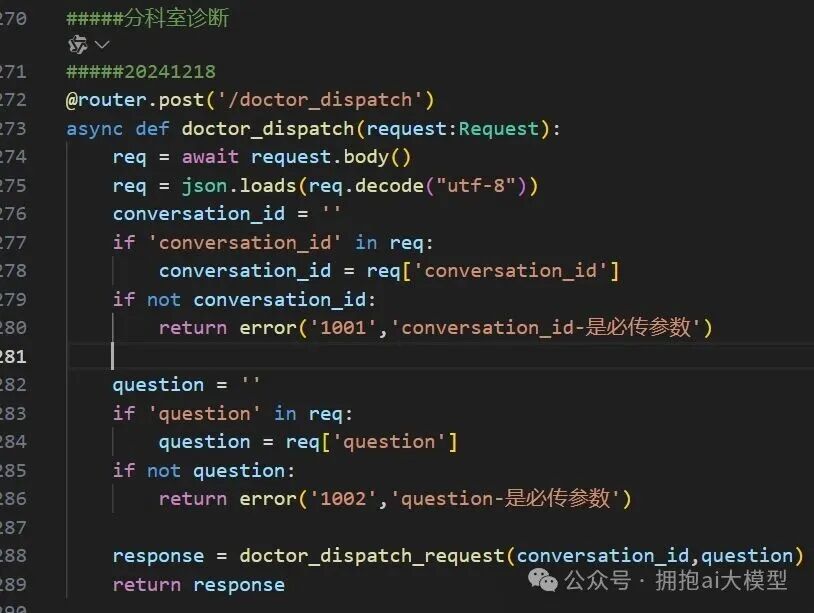
@router.post('/doctor_dispatch')
async def doctor_dispatch(request:Request):
req = await request.body()
req = json.loads(req.decode("utf-8"))
conversation_id = ''
if 'conversation_id' in req:
conversation_id = req['conversation_id']
if not conversation_id:
return error('1001','conversation_id-是必传参数')
question = ''
if 'question' in req:
question = req['question']
if not question:
return error('1002','question-是必传参数')
response = doctor_dispatch_request(conversation_id,question)
return response
2. 分诊核心逻辑与状态保存
分诊的核心逻辑与意图识别类似,也是通过构造提示词调用大模型获取分类结果。
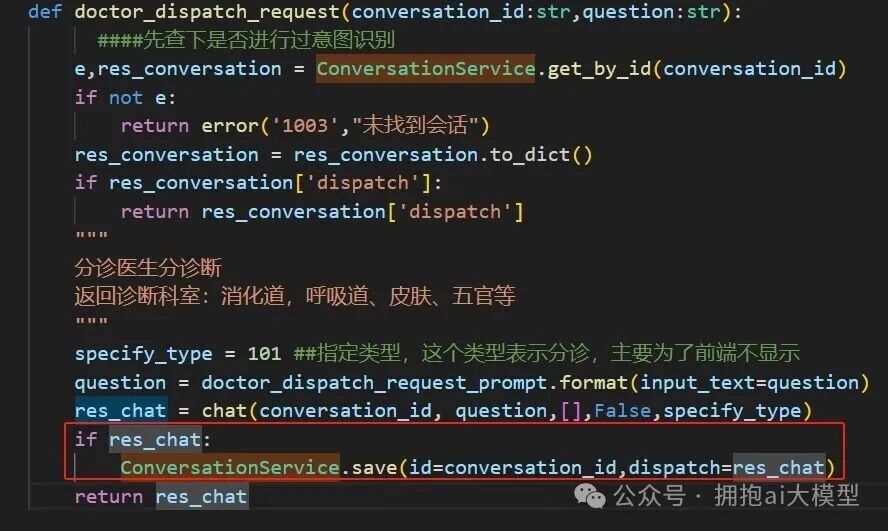
def doctor_dispatch_request(conversation_id:str,question:str):
####先查下是否进行过意图识别
e,res_conversation = ConversationService.get_by_id(conversation_id)
if not e:
return error('1003','未找到会话')
res_conversation = res_conversation.to_dict()
if res_conversation['dispatch']:
return res_conversation['dispatch']
"""
分诊医生分诊断
返回诊断科室: 消化道、呼吸道、皮肤、五官等
"""
specify_type = 101 ##指定类型,这个类型表示分诊,主要为了前端不显示
question = doctor_dispatch_request_prompt.format(input_text=question)
res_chat = chat(conversation_id, question, [], False, specify_type)
if res_chat:
ConversationService.save(id=conversation_id, dispatch=res_chat)
return res_chat
为了持久化分诊结果,我们在 conversation 表中新增了 dispatch 字段:
ALTER TABLE `chat_sev`.`conversation`
ADD COLUMN `dispatch` varchar(50) NULL COMMENT '对用户进行分科室诊断' AFTER `intention`
函数逻辑同样遵循“先查后算”的原则,避免重复调用,并将最终结果保存至数据库,完成了整个 后端 分诊状态的闭环管理。
总结
本次开发实践详细记录了在宠物健康小程序中,利用 Python 与大模型技术栈构建用户意图识别与智能分诊后端模块的过程。从接口调试、流式控制优化、数据持久化到最终的逻辑闭环,每一个步骤都遇到了具体的问题并通过编码解决。这种将 AI 能力嵌入到具体业务流中的模式,是当前很多智能化应用的典型实现方式,希望对您的项目开发有所启发。更多技术讨论与资源共享,欢迎访问 云栈社区。
 发表于 2026-2-13 04:58:21
|
查看: 445|
回复: 0
发表于 2026-2-13 04:58:21
|
查看: 445|
回复: 0
