今天我们来深入聊聊一个前沿的研究项目——ALMA。这个框架的全称是“为自主系统自动元学习的记忆设计”,听起来很学术,但其核心目标非常务实:如何让AI智能体像人类一样,从过往经验中持续学习,并不断变得更强。
传统上,为了让智能体拥有记忆能力,研究者们需要手动设计复杂的记忆系统,比如定义存储什么信息、如何检索、怎么更新。这个过程不仅耗时费力,而且设计出来的方案可能并不通用,换一个任务场景效果就大打折扣。ALMA则另辟蹊径,它试图将设计权交给一个更高级的“元智能体”,让这个元智能体自己去探索和发现最优的记忆设计方案。
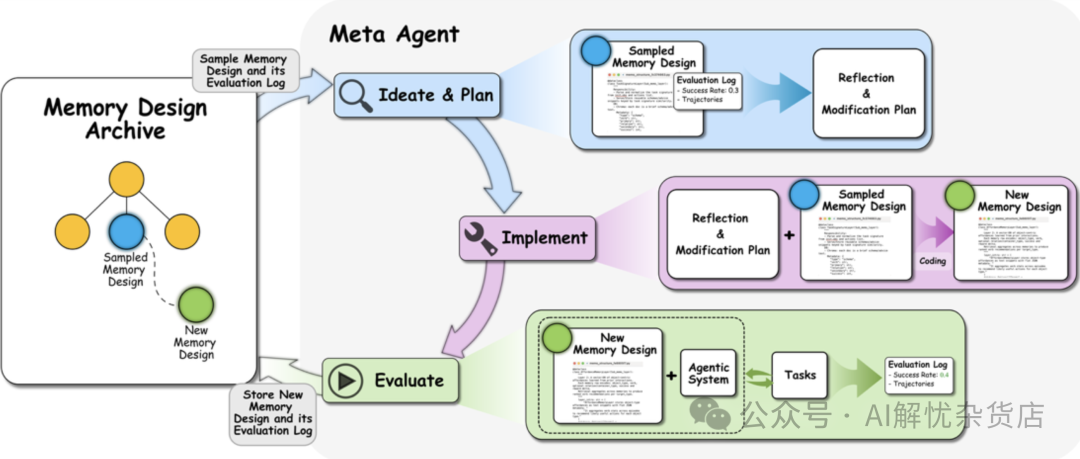
ALMA 元智能体的开放式探索流程:通过反思、计划、实现、评估的迭代循环,不断发现新的记忆设计。
上图的流程清晰地展示了ALMA的工作机制。整个过程可以看作一个自我迭代的优化循环:
- 采样与反思:元智能体从一个存档中,随机采样一些之前探索过的记忆设计方案及其评估日志。然后,它像一个经验丰富的架构师,开始分析这些设计的优劣,思考改进的可能。
- 计划与实现:基于反思,元智能体生成一份新的“改造计划”,并直接将这个计划转化为可执行的代码。这些代码就定义了一个全新的记忆系统。
- 验证与存档:新的记忆系统被加载到一个真实的智能体上,在特定任务中进行测试。测试结果(成功率、轨迹等)会形成新的评估日志。这个“新设计+新日志”的组合,将被存回档案库,成为未来探索的“养料”。
这种方法最大的优势在于开放性。它不预设记忆系统的形态,理论上可以探索出任意结构的设计,包括数据库模式、索引方式、检索和更新逻辑等。这为实现真正的持续学习铺平了道路。
学习过程是怎样的?
为了让大家有更直观的感受,研究团队展示了在游戏《Baba Is AI》中,ALMA发现前六种记忆设计的探索过程。
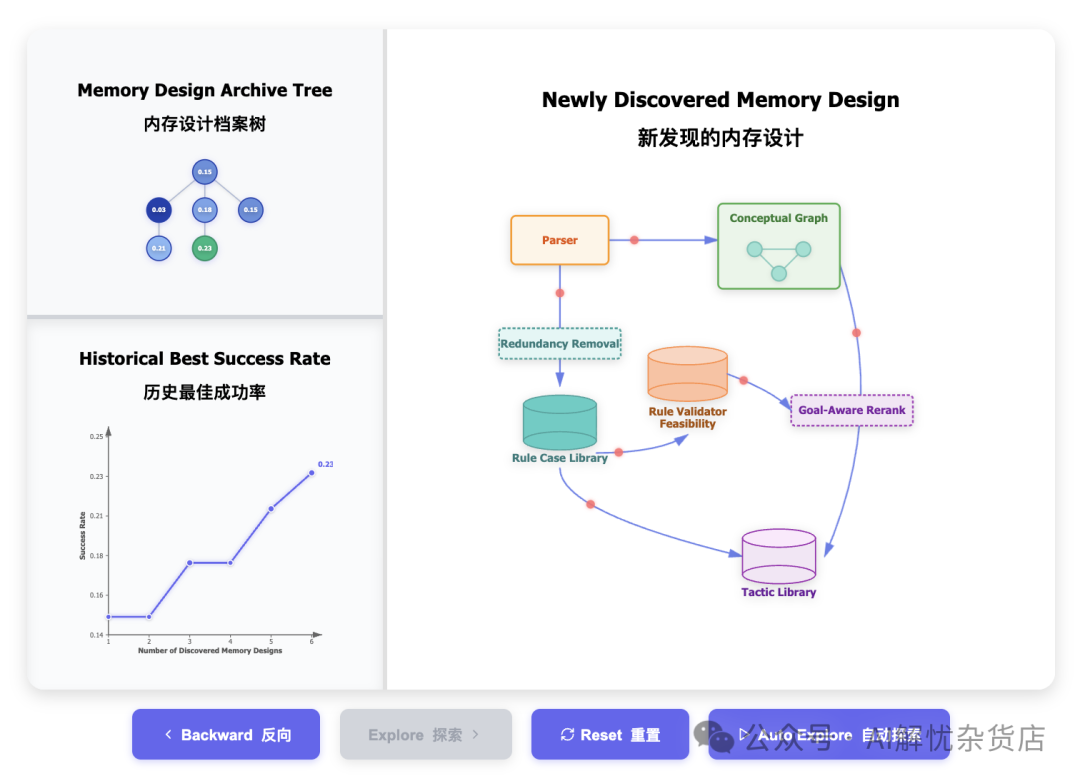
记忆设计档案树展示了已发现设计的结构;历史最佳成功率展示了性能提升趋势;右侧是新发现设计的工作流程。
图中左侧的“记忆设计档案树”形象地展示了探索的路径与结构,就像一个不断分叉生长的知识树。你可以看到,ALMA并非随机乱撞,而是在一个基于过往发现的结构化档案中,进行有导向的探索,逐步发现更优的设计。完整的学习过程细节可以在他们的论文中找到:https://arxiv.org/abs/2407.13729
实际效果如何?数据说了算
理论研究再精妙,最终还是要看实际表现。研究团队在多个主流的强化学习与决策环境(如Alfworld, Textworld, BabaisAI, Minihack)中进行了测试,并将ALMA学习到的记忆设计与当前最先进的手工设计基线进行了对比。
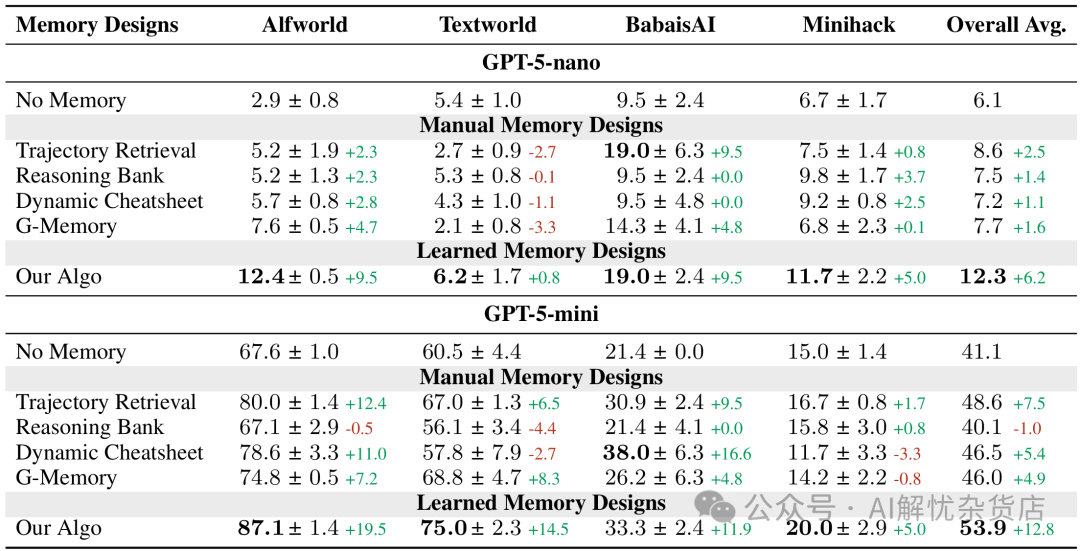
实验结果表明,ALMA学习到的记忆设计在不同模型(GPT-5-nano和GPT-5-mini)和不同任务上均显著优于所有人工基线。
结果非常振奋人心。从上表可以清晰地看到,无论是在小模型(GPT-5-nano)还是稍大模型(GPT-5-mini)驱动的智能体上,ALMA学习到的记忆设计(Our Algo)在几乎所有的任务上都取得了最高的成功率,并且平均提升幅度巨大。
这说明了两点重要结论:
- 有效性:ALMA发现的记忆设计确实能更高效地存储和重用历史经验,从而更好地辅助智能体在新任务中做出决策。
- 泛化性:这种优势并非针对特定模型,随着基础模型能力的增强(从nano到mini),性能提升更加显著,证明了方法的可扩展性。
学习到了什么样的记忆结构?
更有意思的是,ALMA发现的设计并非千篇一律,它会针对不同任务的特点,“定制化”地构建记忆系统。
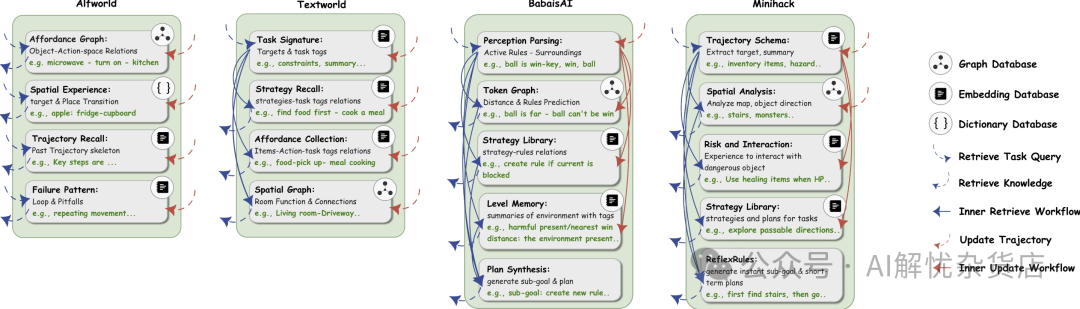
针对不同任务(如Alfworld, Textworld, BabaisAI, Minihack),ALMA学习到的记忆设计结构各异,反映了任务本身的需求。
通过观察上图,我们可以发现一些清晰的模式:
- 对于需要大量与物体交互的环境(如Alfworld, Textworld),ALMA学到的记忆系统倾向于存储细粒度的空间知识,比如物体的位置关系、房间的布局连接图。
- 对于需要复杂推理和策略规划的环境(如BabaisAI, Minihack),记忆系统则更侧重于抽象的策略库和计划合成模块。
这表明,ALMA能够自动理解不同领域的核心需求,并生成最适配的记忆架构。这恰恰是手工设计难以做到的“领域自适应”能力。
样本效率与适应能力
除了最终性能,学习的“效率”和面对变化的“鲁棒性”也同样关键。
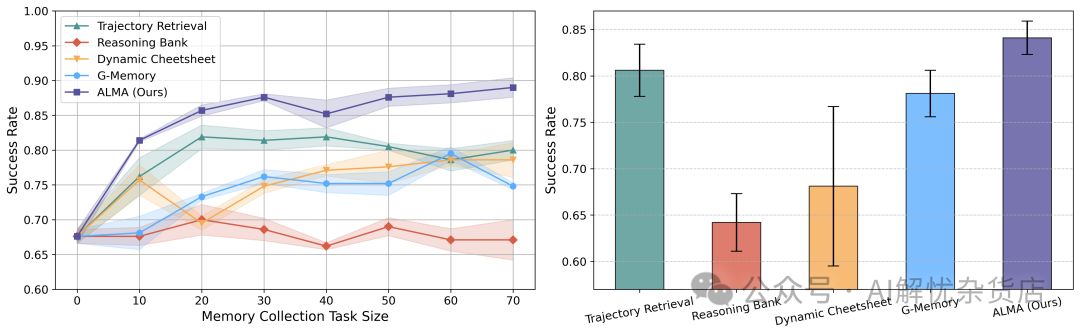
左图:在有限的经验数据下,ALMA能更快达到高性能。右图:当任务分布发生变化时,ALMA学到的设计展现出更强的适应能力。
上图的对比揭示了两大优势:
- 更高的样本效率:在经验数据(轨迹)有限的情况下(左图横轴左侧),ALMA方法(红色曲线)能比人工基线更快地提升成功率。
- 更强的适应能力:当任务的难度分布发生变化时(右图),ALMA学到的记忆设计表现更稳定,而一些手工设计(如Trajectory Retrieval)的性能则出现了明显波动。
总结与展望
ALMA的研究为人工智能领域,特别是智能体(Agent) 的长期演进,提供了一个极具潜力的新范式。它将记忆系统设计从一个依赖专家经验的“手艺活”,转变为一个可以自动优化、持续进化的“元问题”。
虽然这项技术目前主要应用于学术研究环境,但其背后“让系统学会如何学习”的思想,对未来构建能适应复杂、动态现实世界的自主系统具有深远意义。当智能体不再需要人类为它预先编写好所有规则和记忆模式,而是能自己总结经验、优化自身结构时,我们离真正的通用人工智能或许就更近了一步。
对技术细节和完整实验感兴趣的朋友,可以访问项目主页获取更多信息:https://yimingxiong.me/alma。如果你也对这些推动AI边界的前沿探索感兴趣,欢迎在云栈社区与更多开发者一起交流讨论。
 发表于 2026-2-13 07:50:21
|
查看: 268|
回复: 0
发表于 2026-2-13 07:50:21
|
查看: 268|
回复: 0
