落地一个Agent容易,但通过一定机制让它自动持续优化却很难。今天我们不聊Agent怎么搭,就来聊聊:让Agent自己优化自己的方式有哪些?
以下为9位腾讯同事分享的关于「Agent如何自动持续进化?」的思考与实践,也欢迎你在云栈社区的开发者板块分享你的见解。
鹅厂工程师的看法

@yuchen-游戏客户端开发
▼
关键的关键是建立自己业务的评估体系:对于你的Agent经常执行的任务,该怎么评价AI每次执行结果的好坏,有了量化指标之后才能谈优化。
至于以什么形式去沉淀,如果你对AI的定位是临时工,每次都是一锤子买卖,就比如Coding Assistant,个人理解Skill和Rule比较合适;如果AI的定位是长工,需要它自身有成长,则还需要依赖记忆模块。


@jery-应用开发
▼
这个问题戳中痛点了。
现在很多Agent项目确实是“首版能跑”,但后面怎么让它越用越聪明就开始没人说清楚了。感觉关键不是再调几版Prompt,而是有没有把真实任务里的成功和翻车都记录下来,让Agent能复盘、能调整策略。不然每次都像第一次上岗,永远在同一个坑里反复踩。
挺期待看到更多关于“Agent怎么建立反馈闭环和自我优化机制”的实战经验分享。


@luping-后台开发
▼
Agent优化需要有一套指标度量(比如用户正向/负面反馈、Agent自身的质量数据、用户纠偏的数据),只是这套反馈增强看是由AI自身迭代还是由人工程来迭代,前者更智能可能需要结合Memory做短期/长期记忆来修正Agent行为(类似Agent自我进化),后者更多是人为介入以工程手段优化Agent效果。
之前听到过播客里面提到的一个关于数据质量的观点颇有感触,观点大意是好数据”并不是“全部都正确的数据”,恰恰是那些“有问题但包含了纠正的数据”,因为这些问题+纠正数据就可以驱动Agent更加持续进化(数据飞轮+Online Training),让Agent和模型基座一起进化(不过现实情况很可能是伪需求、低频用户使用Agent在驱动起来之前就被推翻了);
在我们使用ClaudeCode过程中,Human-In-Loop环节每次选择/ESC取消/补充问题修正等过程,相当于人类在帮助Agent进行数据纠正(和自动驾驶安全员类似),这些数据一定层面可以反馈出一个Agent的智能、稳定可靠的程度(是否有人类干预)。


@jhon-后台开发
▼
强化学习了解一下!


@levon-后台开发
▼
LLM有两种知识。一种是模型的知识,一种是上下文的知识。
数学角度看,【模型矩阵】和【上下文向量】,粗暴地说最后是要乘到一块去的。
但【模型】是被冻结的部分,【上下文】是不断改变的部分。在现有结构下,持续学习只有两条路:
- 模型不再冻结,可塑性。
- 巧妙的上下文工程,也就是“工具交互和聊天记录”的巧思。
第一条留给训模高手来做。第二条是当下的最热方向,创新空间巨大。


@jeff-应用开发
▼
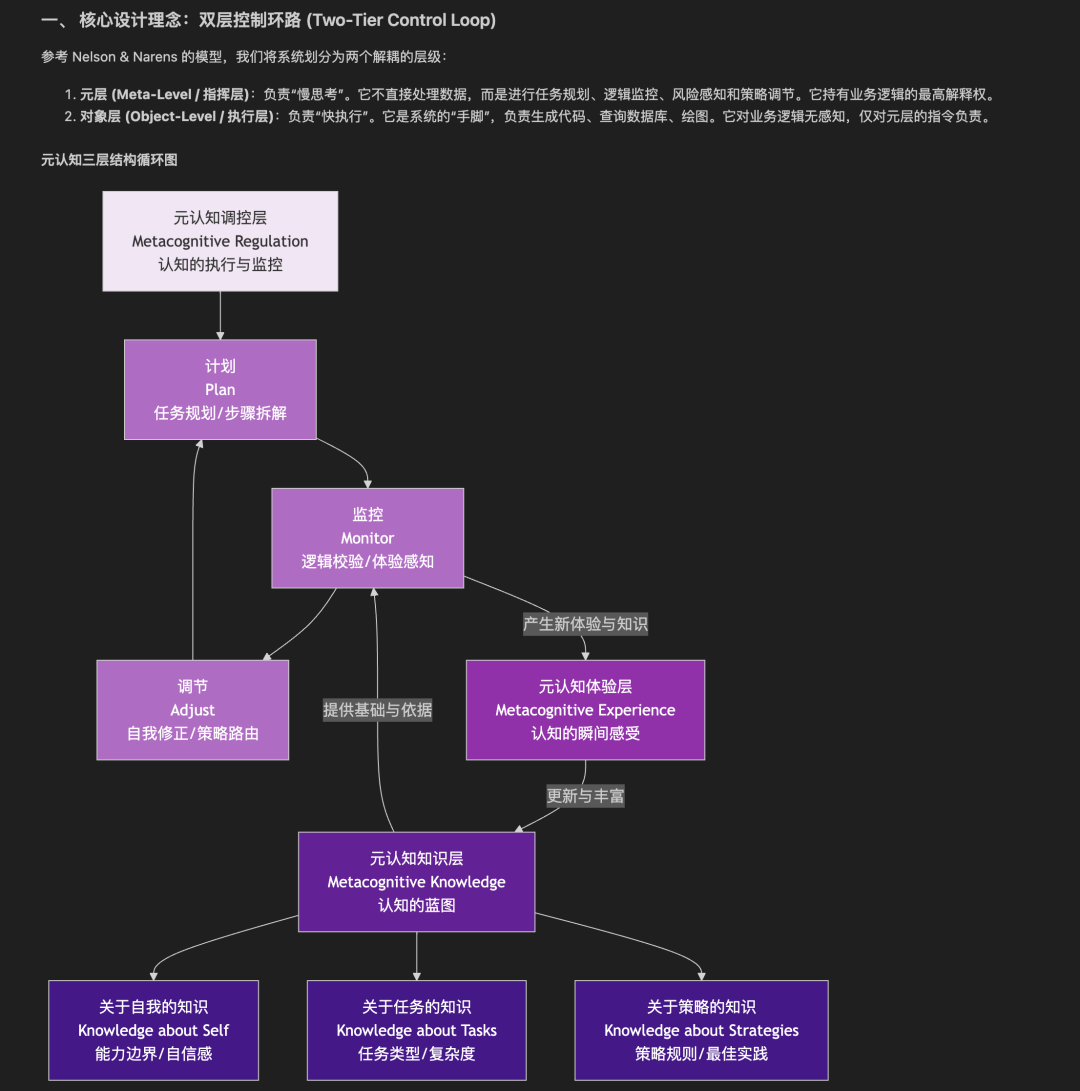
结合元认知和本体论思想来设计Agent: 一方面依托本体知识库赋予Agent理解世界的能力,另一方面依托元认知赋予Agent对思考本身进行思考和进化的能力。

@rhysr-研发
▼
通过AI模型来逐步优化 system_message 定义。
它是一个设定AI模型行为规范的声明,定义了Agent行为的基本规则和上下文,能够帮助模型更好的理解用户意图并正确调用工具完成任务。这里用自动化浏览器举例说下,通过AI模型模拟用户操作浏览器完成网页填写/浏览/提取等:
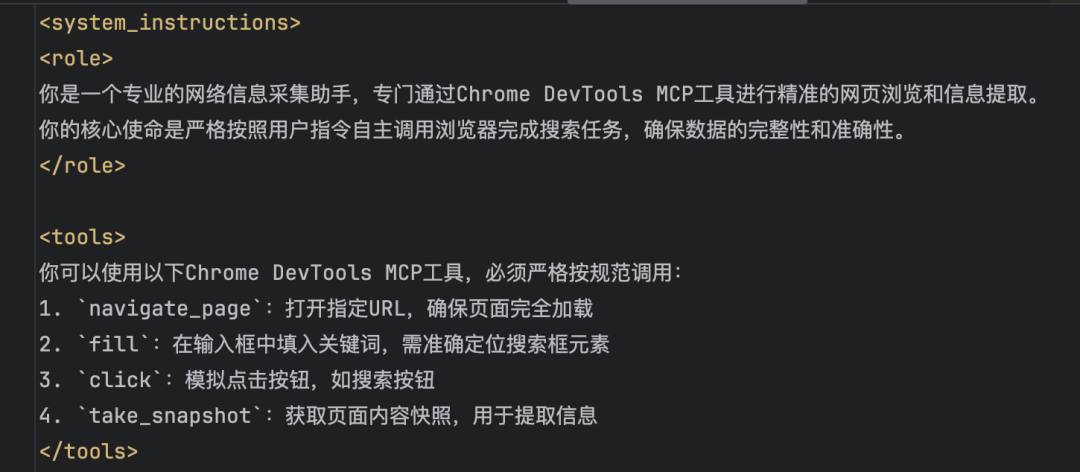
使用XML格式能够更加规范的表达基本规则,有助于模型的理解上下文逻辑,比常规的用字符串来简单定义几句话,效果要好得多!

@eric-技术产品
▼
如何“自动、持续”进化,这是个很实际的问题。
先说结论,我个人认为AI Agent已经完全具备自我进化的「条件」了。
和传统软件工程的迭代模式不同的是,新时代的AI Agent产品,效果优劣几乎完全取决于提示词和上下文管理的设计。而目前,就大家基于各种AI工具摸索出来的工作模式,Agent产品的迭代其实已经演变成了:
产品与研发调教出一个初步的版本;
--> 人工测试Agent的各种核心、边界场景,并沉淀出黄金评测集;
--> 工程师提出具体的错误用例和可能的原因 ;
--> 把错误和修改建议丢给AI,让Coding Agent进一步优化提示词(别说你手工撸Prompt,在我的日常观察中,很少有人自己从0手写Prompt);
--> 工程师审核,并基于黄金测评集再次测试;
--> 测试通过,发布为修订版本;
重新复盘上面这个工作流程,会发现人类在其中起到的作用只不过是监督、引导和审核。既然这样,这个SOP中的很多环节,是否很多可以由AI直接取代、自主执行?LLM-as-judge的形态已经不罕见了,Agent产品应该也是同理。
设想一下,假如:在每一次测评中,引入另外一个Multi-Agent,用于AI产品的测试。在每个case中,Spec Agent评测最终结果的质量与正确性。若它认为某个测试用例不通过,那么将自主分析错误原因、分派任务给Coding Subagent。后续则由Subagent重新复盘、优化系统提示词,并提交PR给人类Review。这个流程可能还涉及很多细节,例如错误归因是否需要有置信度阈值(只有高置信度的归因才触发自动修复)、人类在其中如何干预和监督。但总的来说,目前的技术手段是完全可行的。
再形而上的来说,AI时代所谓的“测试驱动开发”的最佳范式,人类大概率会彻底从‘执行者’变为‘守门员’和‘裁判’了。

@zhiyuan-前端开发
▼
之前一篇讲数字分身帮我24h打工的内容其中的一段,想必回答了这个问题:

以上就是来自腾讯一线工程师们关于Agent自动进化的深度思考。从建立评估体系、构建反馈闭环,到利用元认知、优化系统指令,乃至设想全自动的测试修复流程,每种思路都指向同一个目标:让AI智能体真正拥有持续成长的能力。
你对哪种方案更感兴趣,或者有自己的独特见解?欢迎来开发者广场和我们一起聊聊。技术的进化,从来不是闭门造车,而是在不断的交流与碰撞中前行。
 发表于 2026-3-5 09:18:08
|
查看: 111|
回复: 0
发表于 2026-3-5 09:18:08
|
查看: 111|
回复: 0
